네이버 부스트코스 <딥러닝 기초다지기>를 참고하여 작성하였습니다.
<Deep Learning's Most Important Ideas - A Brief Historical Review> by Denny Britz
논문을 바탕으로 진행되는 강의이다.
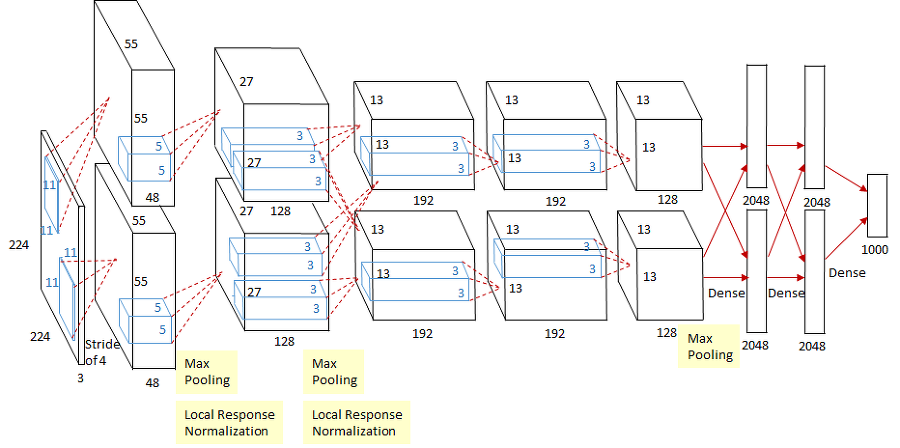
1. 2012 : AlexNet
컴퓨터 비전 분야의 ILSVRC라는 대회가 있다. 이 대회의 목표는 이미지 분류.
이전에는 소프트 벡터 머신SVM과 같은 고전적인 방법이 우승한 반면,
2012년은 AlexNet이 최초로 딥러닝, Convolutional Network을 이용해서 우승했다.
2012년 이후부터는 계속해서 딥러닝을 활용한 모델이 우승하고 있다.
역사적으로 딥러닝이 모든 컴퓨터 비전, 기계학습의 판도를 바꿔놓은 순간이다.
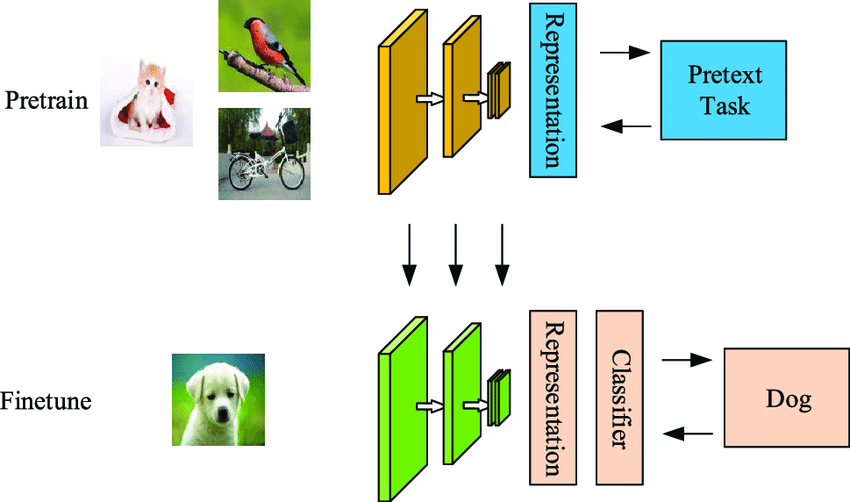
2. 2013 : DQN
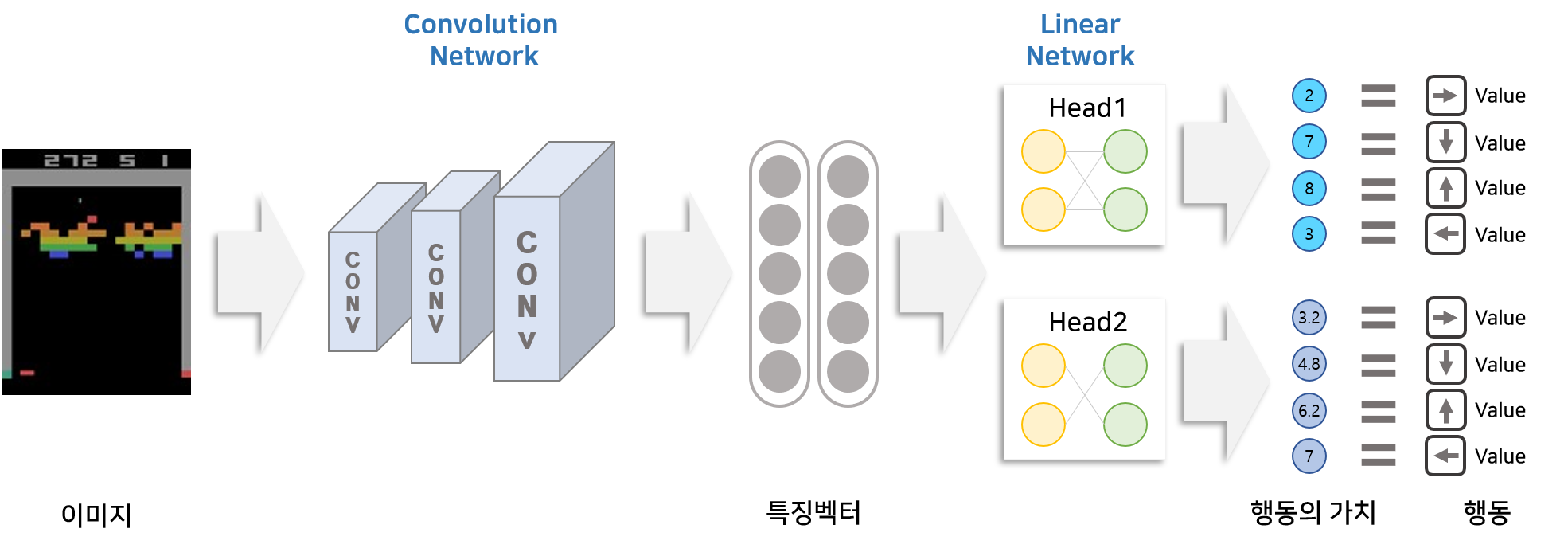
이때까지만해도 딥마인드DeepMind는 스타트업이었다. 그 이후 구글에 들어가며 지금의 Google DeepMind가 되었는데, 이 회사가 오늘날 이세돌을 이긴 인공지능 프로그램 알파고를 탄생시킨다.
DQN은 딥러닝과 강화학습을 결합하여 인간 수준의 높은 성능을 달성한 첫 알고리즘이다.
아래는 궁금해서 찾아본 DQN과 알파고 관련 기사이다.
https://www.hani.co.kr/arti/science/future/935551.html
인공지능 테스트의 기준이 된 아타리 비디오게임 57종을 모두 마스터한 인공지능이 등장했다.
알파고를 선보인 구글의 인공지능 자회사 딥마인드가 개발한 인공지능 ‘에이전트57’이 아타리 57개 게임 전종목에서 인간 최고수를 뛰어넘는 능력을 구현했다.
딥마인드가 2014년 처음 DQN의 강화학습 모델을 <네이처>에 공개했을 당시, DQN은 아타리 비디오게임 49개 종목을 대상으로 학습을 했다. DQN은 49개 게임 중에서 널리 알려진 벽돌깨기(Breakout)을 포함한 29개 게임에서 사람의 평균기록보다 높은 점수에 도달했다. 이번에 에이전트57은 아타리 비디오게임의 모든 종목을 사람 최고수 수준으로 마스터했지만, 여전히 범용 인공지능은 먼 목표다.
3. 2014 : Encoder, Decoder
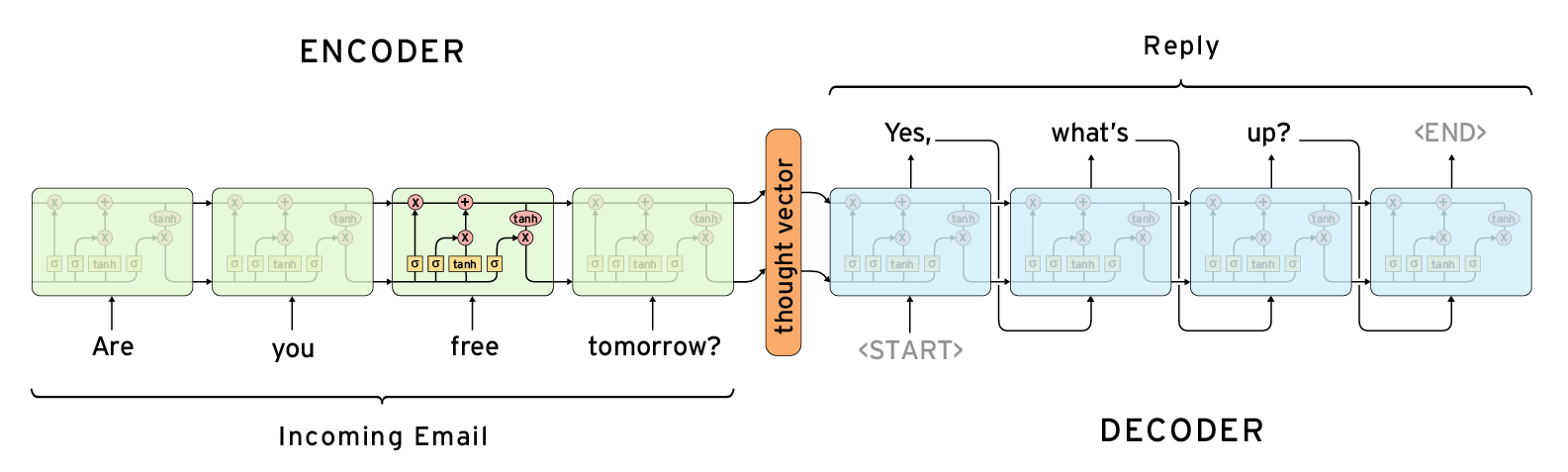
이는 NMT, Neural Machine Translation을 해결하기 위함이다.
구글 번역기도 NMT 알고리즘으로 작동하는데, 결국 해결하고자 하는 목표는 다음과 같다.
단어의 연속이 주어졌을 때, 그 단어를 다른 언어의 단어 연속으로 뱉어주는 것이다.
sequence-to-sequence 문제에 적용할 수 있다.
Encoding: 단어의 sequence가 주어졌을 때, vector값으로 변환한다.
복잡한 것을 단순한 것으로 표현할 수 있게 해준다.
이러한 인코더-디코더 구조는 주로 입력 문장과 출력 문장의 길이가 다를 경우에 사용하는데, 대표적인 분야가 번역기나 텍스트 요약과 같은 경우가 있습니다. 영어 문장을 한국어 문장으로 번역한다고 하였을 때, 입력 문장인 영어 문장과 번역된 결과인 한국어 문장의 길이는 똑같을 필요가 없습니다. 텍스트 요약의 경우에는 출력 문장이 요약된 문장이므로 입력 문장보다는 당연히 길이가 짧을 것입니다.
4. 2014 - Adam Optimizer
현재 가장 많이 사용되는 optimizer.
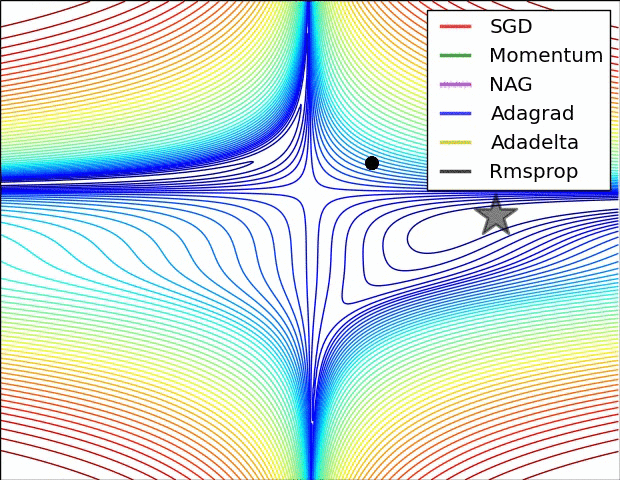
학습시키려는 모델이 있을 때, optimize하기 위한 방법은 여러가지가 있다. 딥러닝을 하다보면 Adam을 그냥 쓰는 경우가 많다. 왜냐하면 결과가 잘 나온다.
딥러닝 논문을 읽다보면, 희한한 짓을 많이 하는데, 학습이 절반정도 이루어졌을 때, learning rate를 1/10로 줄인다.
왜 학습률을 바꿀까? 그렇게 하지 않으면, 같은 결과가 복원되지 않고 안좋은 성능이 나온다.
딥러닝의 학습에서는 최대한 틀리지 않는 방향으로 학습해 나가야 한다.
여기서 얼마나 틀리는지(loss)를 알게 하는 함수가 loss function=손실함수이다.
loss function의 최소값을 찾는 것을 학습의 목표로 한다. 여기서 최소값을 찾아가는 것을 최적화=Optimization 이라고 하고 이를 수행하는 알고리즘이 최적화 알고리즘=Optimizer 이다.
optimizer의 종류는 다음과 같다.
https://dbstndi6316.tistory.com/297
5. 2015 : GAN, Generative Adversarial Network

이미지를 어떻게 만들어낼지, 텍스트를 어떻게 만들어낼지
네트워크가 Generator, Discriminator 두 가지로 나눠서 학습을 시키는 것이다.
6. 2015 - Residual Networks
이 연구 덕분에 딥러닝의 딥러닝이 가능해졌다.
이 연구 이전에는 네트워크를 너무 깊게 쌓으면 학습이 잘 안된다. 성능이 잘 나오지 않는다.
이 연구 이후에는 트렌드가 바뀌었다. 네트워크를 많이 쌓아도 성능이 좋게 만들어주었다.
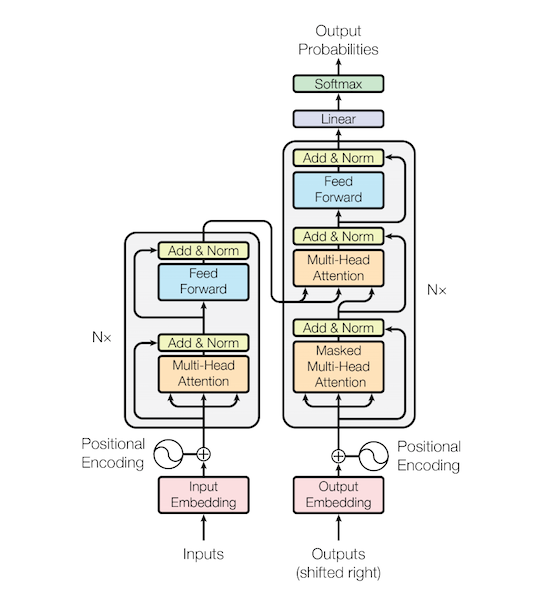
7. 2017 - Transformer
<"Attention is All You Need"> 논문
도전적인 제목이다. 풀고자하는 문제와 방법을 설명하는 제목인 것이 일반적인데, 마치 노래 제목과 같은 논문 제목이다.
오늘날 Attention, Transformer 모델이 왠만한 모델을 모두 대체했다.
8. 2018 : BERT
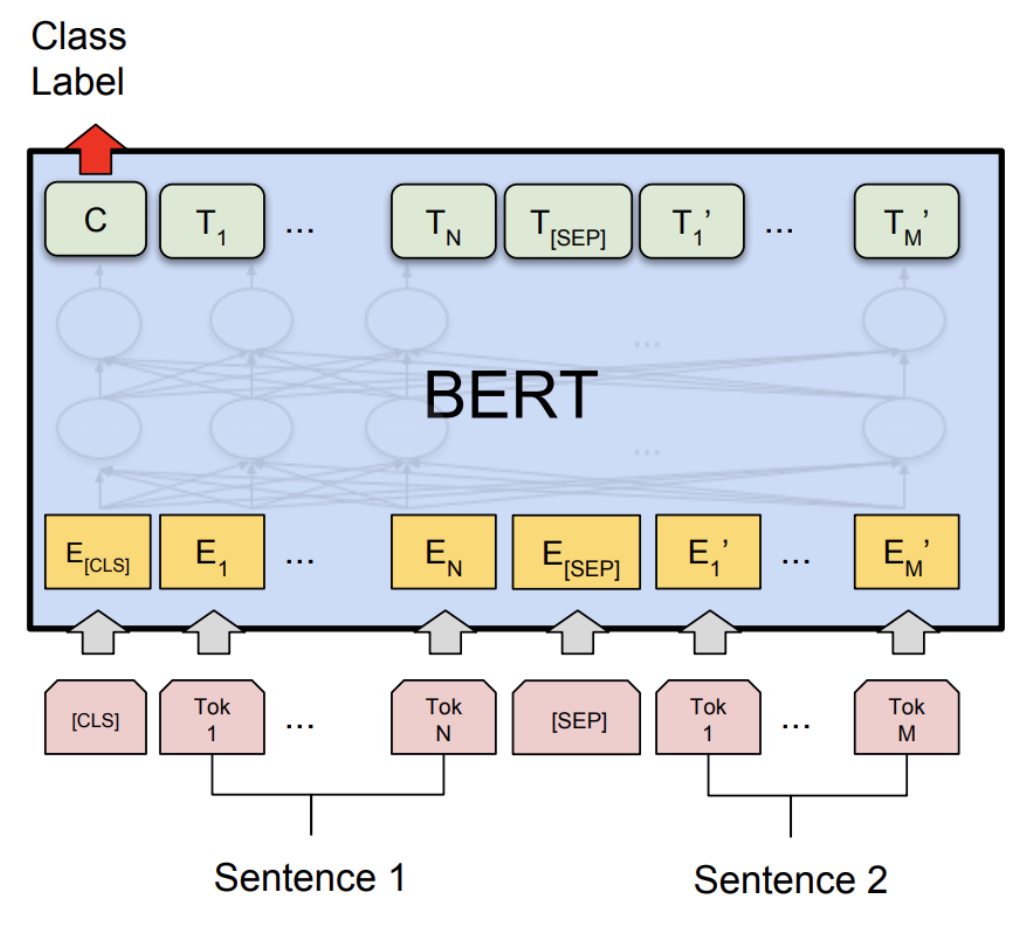
: Bidirectional Encoder Representations from Transformers
이 모델과 관련있는 fine-tuned NLP models을 이해하는 것이 중요하다.
자연어처리 문제는 보통 Language model을 학습한다.
이전에 어떤 단어 이후에 어떤 단어가 나올 지 예측하는 것인데, 이 것이 문장이 되고, 문단이 된다.
다양한 단어들, 큰 말뭉치를 통해 free training을 한 후에 fine tune하는 것이다.
BERT는 text classification, answering 등을 해결할 수 있는 모델이지만, 이보다는 Language Representation을 해결하기 위해 고안된 구조이다.
BERT는 양방향성을 포함하여 문맥을 더욱 자연스럽게 파악할 수 있다.
다음과 같은 문제에 적용할 수 있다.
Question and Answering
- 주어진 질문에 적합하게 대답해야하는 매우 대표적인 문제입니다.
- KoSQuAD, Visual QA etc.
Machine Translation - 구글 번역기, 네이버 파파고입니다.
문장 주제 찾기 또는 분류하기 - 역시나 기존 NLP에서도 해결할 수 있는 문제는 당연히 해결할 수 있습니다.
사람처럼 대화하기 - 이와 같은 주제에선 매우 강력함을 보여줍니다.
이외에도 직접 정의한 다양한 문제에도 적용 가능합니다. 물론 꼭 NLP task일 필요는 없습니다.
https://hwiyong.tistory.com/392
9. 2019 : BIG Language Model
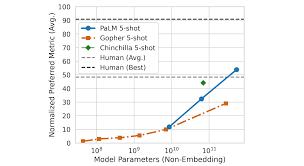
GPT-3, language model
fine tuning을 통해 다양한 문장, 텍스트, 표 등을 만든다.
1750억개의 파라미터로 구성되어 있음
2019년 오픈 AI가 발표한 논문, Language Models are Few-Shot Learners

https://news.sktelecom.com/178491
오픈AI는 이 논문에서 자사가 개발한 초대형 인공지능 기반의 언어 생성 모델 ‘GPT-3’를 공개했다. 이 언어 모델이 작성한 뉴스 기사는 인간이 쓴 것과 구별이 어려웠고, GPT-3로 구현한 챗봇과의 대화는 이전과 비교할 수없이 세련됐다.
2022년 5월, SK텔레콤은 GPT-3 기반으로 한 ‘성장형 AI 서비스, A.(에이닷)’을 공개해 고객들의 일상에 도움을 주겠다고 나섰다. GPT-3가 무엇이길래 관심을 받았는지, GPT-3의 현재진행형 ‘A.’이 나온 배경은 무엇인지, 꼬리에 꼬리를 무는 질문을 따라 살펴본다.
GPT-3는 오픈(Open)AI가 개발한 AI 언어 모델인 GPT의 3세대 모델로, 2020년에 공개되었다. AI 언어 모델은 쉽게 말해서 기계가 인간의 언어를 이해하고, 구사할 수 있도록 하는 기술이다. 실제화된 예로 자동번역, 챗봇이나 음성 비서를 생각하면 된다.
GPT를 직역하면 생성적 사전학습 트랜스포머(Generative Pre-trained Transformer)이다. 여기서 생성적은 변수들의 관계를 밝히는데 쓰이는 통계적 모델을 의미한다. 트랜스포머(변환기)는 구글에서 2018년 개발한 딥러닝 모델 중 하나로, 대량의 데이터를 학습하는데 유용하여 AI 언어 모델이나 AI 비전에서 근래에 활발하게 사용되고 있다.
GPT와 같은 AI 언어 모델들은 방대한 텍스트 데이터를 입력 받아, 문장 내 단어들 사이의 연관성을 스스로 찾는 비지도학습을 통해 좀 더 높은 언어 지능을 얻는 것을 목표로 한다. 이러한 AI 언어 모델의 출발은 컴퓨터가 자연어를 처리하는 기술(NLP, Natural Language Processing)이다. 초기에는 문법과 같은 언어 규칙을 기계가 잘 이해할 수 있는 형태로 만드는데 초점을 두었다. 그러다, 컴퓨터의 연산 속도와 디지털화된 데이터의 증가, 딥러닝 등이 AI 언어 모델에도 도입되면서 인간이 컴퓨터에게 언어 규칙을 알려주기보다는, 컴퓨터가 스스로 학습을 하게 되었다.
예를 들어, “한국의 수도는 어디인가?”를 묻는 질문에 답을 하는 경우를 생각해 보자. 초기의 자연어 처리를 이용한 전문가 시스템이라면, 문법 규칙을 정의한 컴퓨터 프로그램이 질문 문장을 분석하고, 지식 데이터 검색을 통해 ‘서울’이라는 후보 답안 찾고, 다시 문법 규칙에 맞추어 “한국의 수도는 서울입니다”라고 출력한다. 이에 비해 GPT-3와 같은 AI 언어 모델은 백과사전을 모두 입력하여, AI가 스스로 단어들 간의 연관성을 파악하도록 한다. 스스로 학습을 통해서, 한국, 미국, 서울, 제주, 수도, 도시 등에서 한국, 수도와는 서울이 가장 잘 연결된다는 것을 통계 확률적으로 계산해 내는 것이다.
10. 2020 : Self Supervised Learning
SimCLR : a simple framework for contrastive learning of visual representations
Self-supervised learning은 unlabelled dataset으로부터 좋은 representation을 얻고자하는 학습방식으로 representation learning의 일종이다. unsupervised learning이라고 볼수도 있지만 최근에는 self-supervised learning이라고 많이 부르고 있다.
그 이유는 label(y) 없이 input(x) 내에서 target으로 쓰일만 한 것을 정해서 즉 self로 task를 정해서 supervision방식으로 모델을 학습하기 때문이다. 그래서 self-supervised learning의 task를 pretext task(=일부러 어떤 구실을 만들어서 푸는 문제)라고 부른다. pretext task를 학습한 모델은 downstream task에 transfer하여 사용할 수 있다. self-supervised learning의 목적은 downstream task를 잘푸는 것이기 때문에 기존의 unsupervised learning과 다르게 downsream task의 성능으로 모델을 평가한다.