💊
https://developer.apple.com/videos/play/wwdc2023/10101/
이 글은 위 WWDC23에서 소개된 기기 내 음성인식 기능을 커스텀하는 방법에 대한 영상을 정리한 것입니다.
직접 번역하고 정리한 내용이니, 사용하실 때에는 출처를 밝혀주세요:)
번역 참고
📄 transcript, transcription : 자막 으로 통일했어요!
📄 custom == 사용자 정의
Overview 개요
추가적인 어휘들로 기존 모델을 커스텀하여 앱에서 기기 내 음성 인식을 개선할 수 있는 방법을 알아보세요.
디바이스에서 음성 인식이 작동하는 방식을 공유하고, 보다 예측 가능한 자막(transcription)을 위해 특정 단어와 구문을 강화하는 방법을 보여 드리겠습니다.
단어에 대한 특정 발음을 제공하고, 템플릿 지원을 사용하여, 전체 커스텀 문구 세트(phrase set)를 런타임에 빠르게 생성하는 방법을 알아보세요.
음성 프레임워크에 대한 자세한 내용은 WWDC19의 "음성 인식의 발전"을 확인하세요.
Content 내용
1. Introduction

Ethan from Siri Understanding Team이 음성 인식 분야의 몇 가지 흥미로운 발전에 대해 이야기해준다.
iOS10에서는 음성 프레임워크를 도입했다. 그래서 Siri, 키보드 받아쓰기를 지원하는 기술을 활용해서 간단하고, 직관적인 인터페이스를 사용하여 음성 지원 앱을 만들 수 있었다. 그러나 기본적으로 음성인식기 클래스는 모든 앱에 적합하지 않는다.
이 이유는 음성 인식이 어떻게 작동하는지에 대해 알아야 하는데,
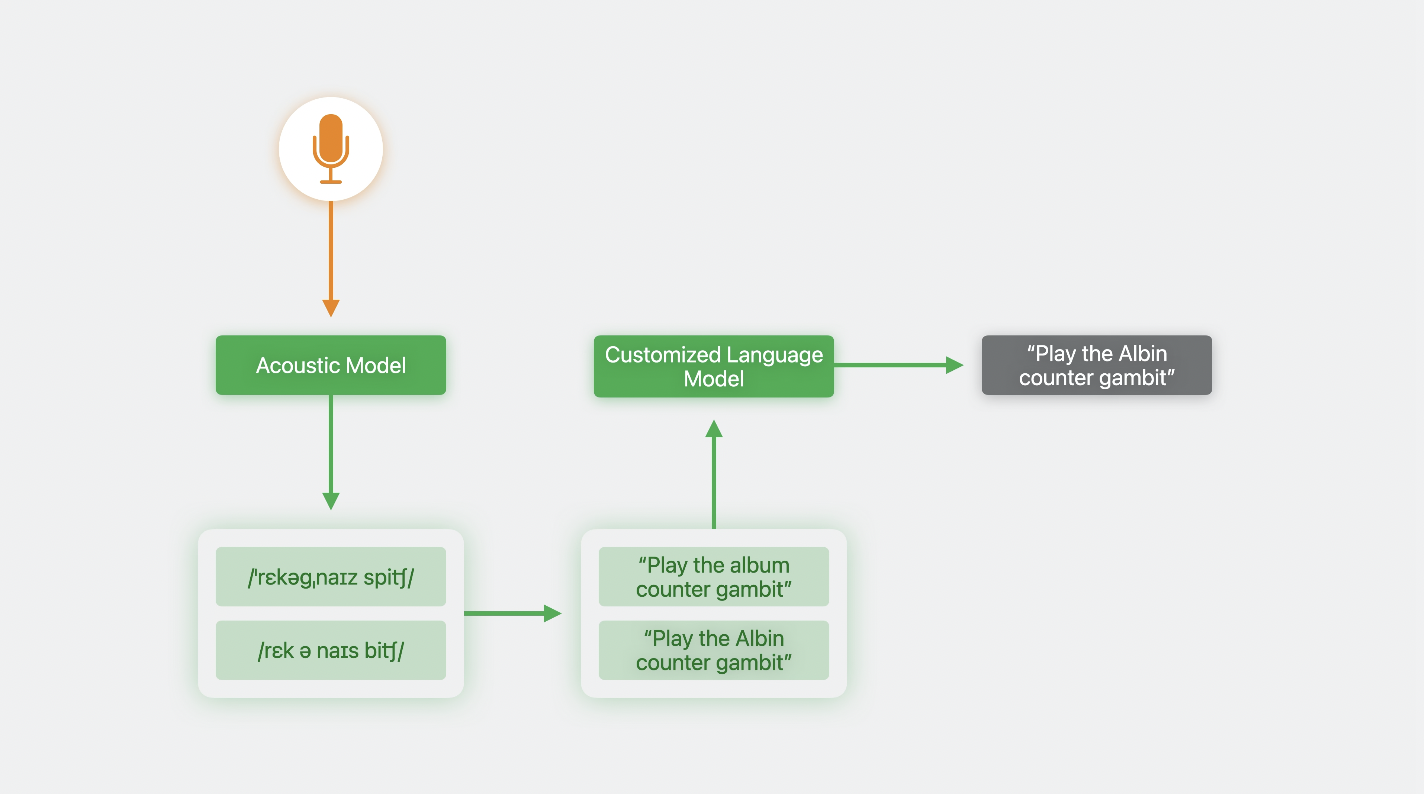
음성 인식 시스템
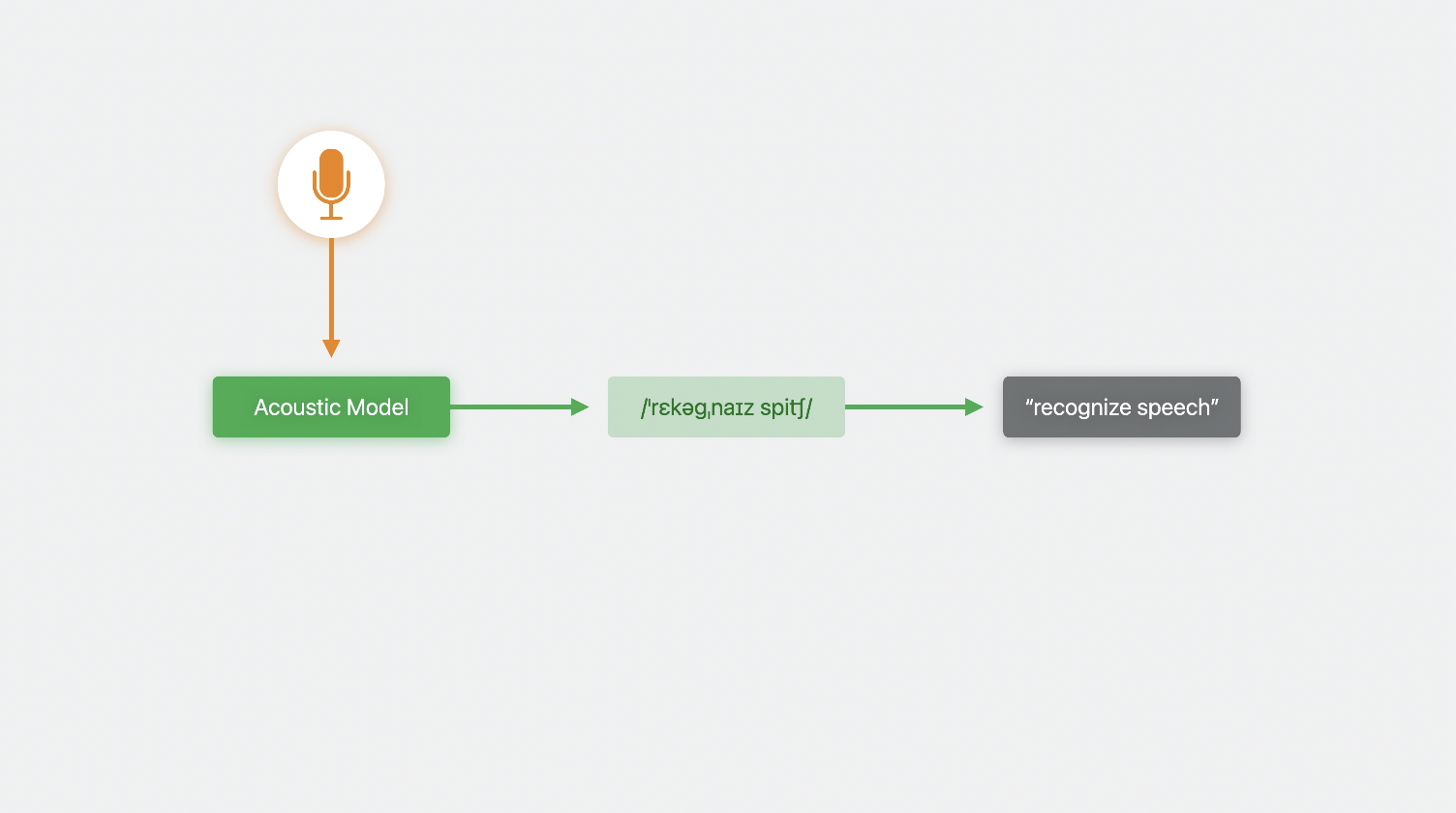
먼저 음성 표현을 생성하는 음향 모델에 오디오 데이터를 준다.

-> 음성 표현이 문자 형식 or 자막으로 변환된다.
경우에 따라 여러 음성 표현이 오디오 데이터에 적합하거나, 단일 음성 표현이 여러 텍스트 변환에 해당될 수 있다.(1:1이 아님)
-> 이럴때는 여러 후보 자막본이 생성되므로, 명확하게 할 수 있는 방법이 필요함!
-> 그래서 사용하는 것이 언어 모델.
언어 모델

여러 개의 단어(문장)에서 특정 단어가 다음에 올 가능성을 예측한다.
이걸 전체 문장에 적용하면, 문장이 말이 되는지 안되는지를 알 수 있다.
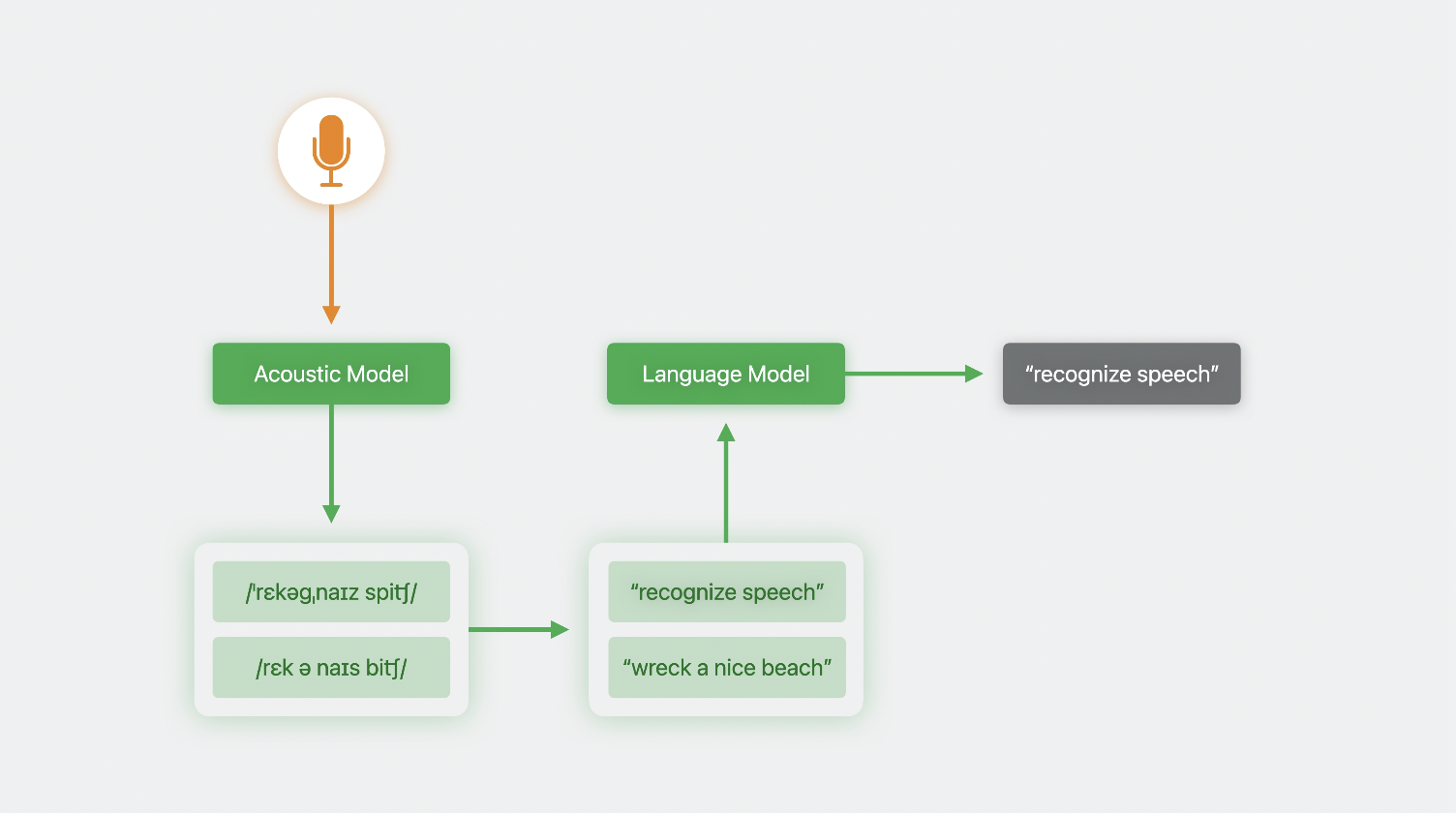
언어 모델은 훈련 중에 모델이 노출된 사용 패턴을 기반으로, 가능성이 낮은 후보를 거부하는 데에 도움이 된다.

iOS10부터 음성 프레임워크는, 사용하기 쉬운 인터페이스를 제공하기 위해 이 전체 프로세스를 캡슐화했다.

ex) 나는 체스를 좋아해. 그래서 사용자가 개별 동작도 하고, 체스에서 시작과 방어를 지시할 수 있는 체스 앱을 만들었어.
근데 내 상대방이 Queen's Gambit을 플레이하네?? 그래서 내가 다시 지시해
"Play the Albin counter Gambit"
오잉 근데 음성 인식기가 내 체스 수를 음악을 재생해달라는 요청으로 잘못 인식한다.
Play가 게임을 하는 것, 음악을 재생하는 것 등등..으로 해석될 수 있기 때문
이런 식으로, 음성 인식기가 사용하는 언어 모델은, 훈련 과정에서 많은 음악 재생 요청에 노출되러서, "앨범 재생 = PLAY"과 같은 쿼리와 앨범 이름이 뒤따르는 쿼리에 대응하는거다.

반대로, 내가 선호하는 자막을 본 적이 없을 수도 있다.
언어 모델의 동작을 추상화함으로써, 음성 프레임워크는 다른 도메인에서 다른 동작을 요구하더라도, 모든 앱이 동일한 모델을 사용하도록 강제한다.
iOS17부터 SFSpeechRecognizer의 언어 모델 동작을 커스텀할 수 있다.
분야에 맞게 조정하고, 정확도를 향상시켜라!
2. Custom Language Model
1) Train Data Collection
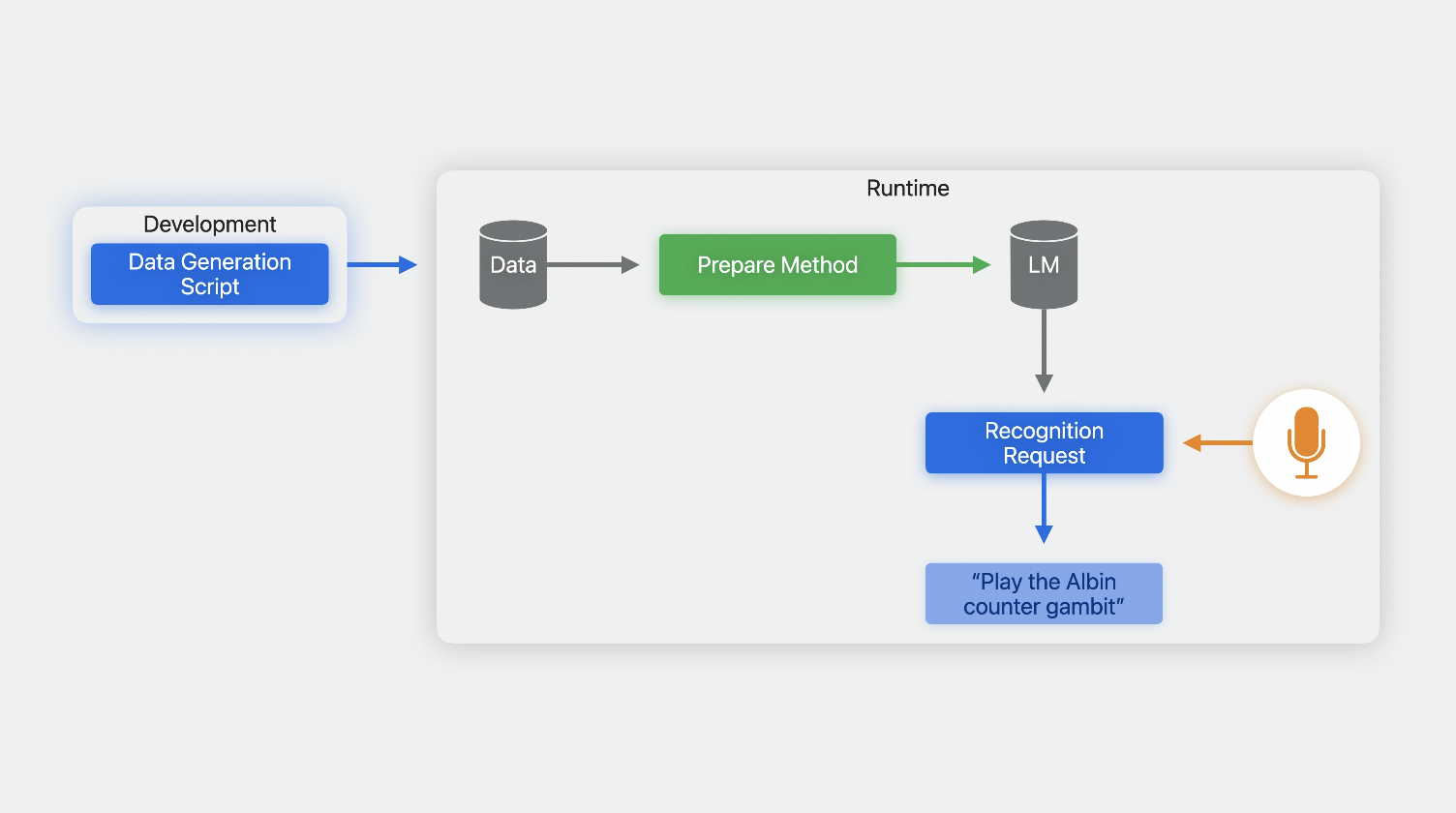
언어 모델 커스텀을 시작하려면, 먼저 훈련 데이터 컬렉션을 만들어라.
개발과정 중에 할 수 있다.
그 다음에 앱에서 데이터를 준비하고, 인식 요청을 만들고 실행한다.

그러면 훈련할 데이터 컬렉션은 어떻게 구축하냐?
높은 수준에서 훈련된 데이터는 앱 사용자가 말할 가능성이 있는 문구를 나타내는 text bit로 구성된다.
이를 통해, 모델이 해당 문구를 예상하도록 학습하고, 해당 문구가 올바르게 인식될 확률을 높인다.
음성 인식기가 얼마나 능력이 있는지,
그리고 시간이 지남에 따라 얼마나 향상되는지 봐라!
잘 되니깐 자주 해봐랑
2) 코드를 보아요

Speech Framework에는 훈련 데이터의 container 역할을 하는 새로운 클래스가 도입되었다.
이건 result builder DSL을 사용해서 구축되었는데, 코드에 표시된 object로
✅ PhraseCount:
- 정확한 문구, 문구의 일부를 제공할 수 있다.
- 샘플이 최종 데이터셋에 표시되어야 하는 횟수(특정 문구에 다른 문구보다 더 큰 가중치를 두어야 할 때 사용할 수 있다)
-> 시스템에서 허용할 수 있는 데이터의 양은 한정되어있다. <전체 훈련 데이터 예산>과 <문구를 강화해야 하는 필요성>의 균형을 맞춰라!

또, 템흘릿을 활용하여, 일반적인 패턴에 맞는 다수의 샘플을 만들 수도 있다.
여기에서는 체스 동작을 구성하는 세 가지의 단어를 정의해놨다.
1. "piece": 이동할 조각, 내가 목표로 삼고 있는 파일의 2배가 되는(?)
2. "royal": 플레이할 보드의 어느쪽을 나타내는 왕실 조각,
3. "rank": 이동할 순위
-> 이걸 패턴으로 결합함으로써
"<piece> to <royal><piece><rank>"가능한 모든 움직임을 나타내는 데이터 샘플을 쉽게 만들 수 있다.
count: 10000여기서는 개수가 전체 템플릿에 적용되므로, 체스 동작을 나타내는 10,000개의 샘플을 모든 결과 데이터 샘플에 균등하게 나누어 얻는다.

데이터 객체 구축이 완료되면, 이를 파일로 내보내고, 다른 asset과 마찬가지로 내 앱에 넣는다.
3) 전문 분야일 경우 Custom Pronunciations

앱에서 전문적인 용어를 사용하는 경우,
해당 단어의 스펠링, 발음을 모두 정의하고, 단어의 사용법을 보여주는 예시 구문 수를 제공할 수 있다.
발음은 X-SAMPA 문자열 형식이 허용된다.
각 locale은 발음 기호의 고유한 하위 집합을 지원한다.
locale: 로케일은 사용자 인터페이스에서 사용되는 언어, 지역 설정, 출력 형식 등을 정의하는 문자열입니다. 유닉스Unix와 리눅스Linux와 같은 POSIX 기반의 시스템에서는 같은 형식을 공유하고 있습니다. 애플의 맥OS를 비롯한 Darwin 계열 운영체제들도 POSIX 호환이 되기 때문에 같은 형식의 로케일 문자열을 사용합니다.
(전체 locale 세트와 지원되는 발음 기호는 설명서를 참조해라)

내 앱의 경우, 음성 인식기가 프랑스 방어의 일반적인 변형인 "Winawer" 변형을 이해할 수 있는지 확인하고 싶다.

이 locale에서 지원되는 X-SAMPA기호의 하위집합을 사용해서 발음을 설명한다.
동일한 API를 사용해서 앱이 런타임에 액세스할 수 있는 데이터를 학습할 수 있습니다.
사용자가 배우려고 하는 체스 오프닝 및 방어에 중점을 두는 등 사용자별 사용 패턴을 지원하기 위해 이 작업을 수행할 수 있습니다.
명명된 entity에 대해 훈련할 수도 있습니다.
어쩌면 앱이 사용자의 연락처에 대한 네트워크 플레이를 지원할 수도 있습니다.
언제나 그렇듯, 사용자의 개인정보를 존중하는 것이 무엇보다 중요합니다.

예를들어, 통신 앱은 통화 기록에 해당 연락처가 나타나는 빈도에 따라 연락처에 전화하라는 명령을 강화할 수 있습니다. 이런 종류의 정보는 항상 기기에 남아있어야 합니다.
앞서 설명한 것처럼 앱 내에서 동일한 메서드를 호출하여 데이터 객체를 생성하고, 파일에 쓰고, 수집하기만 하면 됩니다.

훈련 데이터가 생성되면 단일 locale에 바인딩됩니다.
단일 스크립트 내에서 여러 locale을 지원하려는 경우, NSLocalizedString과 같은 표준 지역화 기능을 사용할 수 있습니다.

4. Depolying your model
이제 앱에 모델을 배포하는 방법에 대해 이야기하겠습니다.
먼저, 이전 단계에서 생성한 파일을 수락하고, 나중에 사용할 두 개의 새 파일을 생성하는 prepareCustomLanguageModel 이라는 새 메서드를 호출해야 합니다.

이 메서드 호출에는 많은 양의 관련 대기시간이 있을 수 있으므로, 기본 스레드(main 스레드)
에서 호출하고, 로딩화면과 같은 일부 UI 뒤에 대기 시간을 숨기는 것이 가장 좋습니다.

때로는 기기에 데이터를 보관해야 하는 경우가 있는데, 사용자의 개인 정보를 존중하기 위함이다.
LM 사용자 정의는 네트워크를 통해 사용자 정의 데이터를 전송하지 않음으로써 이를 지원합니다.
모든 맞춤형 요청은 장치에서만 엄격하게 처리됩니다.
앱이 음성 인식 요청을 생성할 때 먼저 장치에서 인식이 실행되도록 강제합니다.
그렇게 하지 않으면 요청이 사용자 정의 없이 처리됩니다.
그런 다음 요청 객체에 언어 모델을 연결합니다.

이제 내 앱에서 LM 사용자 정의를 켠 상태에서

"Play the Albin Counter Gambit"
내 사용자 정의 용어도 작동한다.
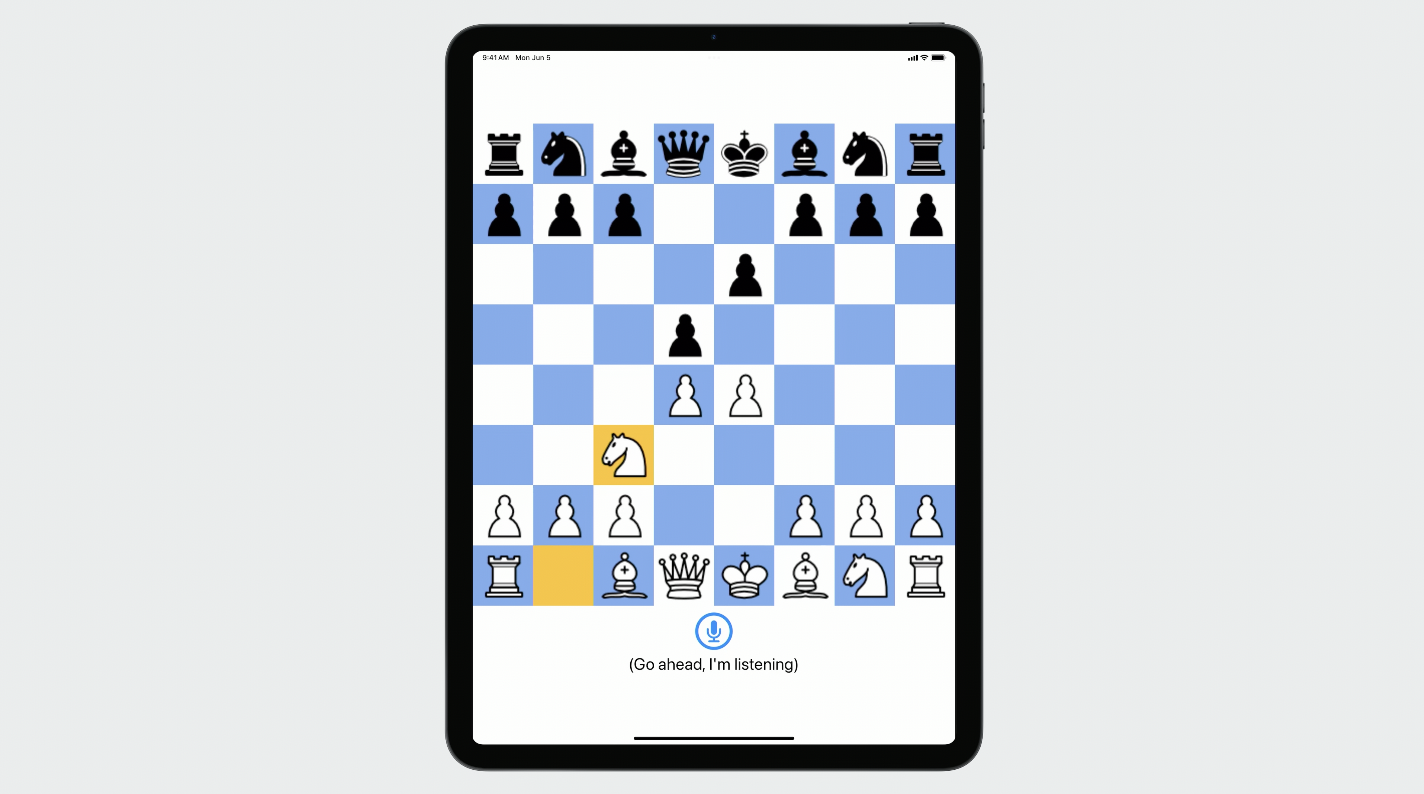
"Play the Winawer variation"

5. Conclusion
언어모델을 사용자 정의해서, 음성 인식기를 응용 프로그램의 도메인에 맞게 조정하고, 작동 방식을 어느 정도 제어할 수 있게 되었다.
가장 중요한건, 내 앱의 음성 인식 정확도가 향상되었다는 것이다.

이제 음성 프레임워크는 더 많은 앱과 더 많은 사용자에게 적용될 수 있으므로 더욱 강력해지고, 더 나은 환경을 만드는 데 사용될 수 있다.
언어 모델 사용자 정의는 음성 인식기를 향상하고, 앱에 맞게 사용자 정의하는 방법을 제공한다.

여러분이 이 앱을 통해 달성하게 될 놀라운 일들을 모두 보게 되어 매우 기쁩니다.
Thank you, and remember to play for the center. ♪ ♪

더 공부해야 할 레퍼런스
https://developer.apple.com/documentation/speech
https://developer.apple.com/documentation/speech/recognizing_speech_in_live_audio
