예제: 폴리오미노
문제
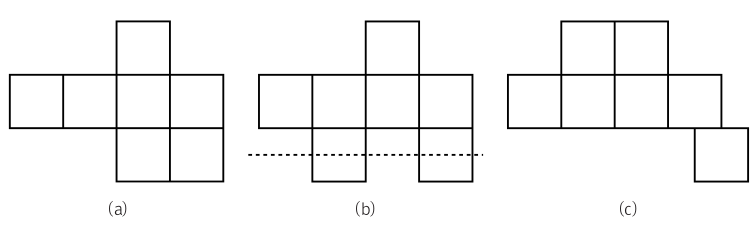
정사각형들의 변들을 서로 완전하게 붙여 만든 도형들을 폴리오미노(Polyomino)라고 부릅니다. n개의 정사각형으로 구성된 폴리오미노들을 만들려고하는데, 이 중 세로로 단조(monotone)인 폴리오미노의 수가 몇 개나 되는지 세고 싶습니다. 세로로 단조라는 말은 어떤 가로줄도 폴리오미노를 두 번 이상 교차하지 않는다는 뜻입니다.
예를 들어 그림 (a)는 정상적인 세로 단조 폴리오미노입니다. 그러나 (b)는 점선이 폴리오미노를 두 번 교차하기 때문에 세로 단조 폴리오미노가 아닙니다. (c)는 맨 오른쪽 아래 있는 정사각형이 다른 정사각형과 변을 완전히 맞대고 있지 않기 때문에 폴리오미노가 아닙니다.
n개의 정사각형으로 구성된 세로 단조 폴리오미노의 개수를 세는 프로그램을 작성하세요.입력
입력의 첫 줄에는 테스트 케이스의 수 C (1≤C≤50)가 주어집니다. 그 후 각 줄에 폴리오미노를 구성할 정사각형의 수 n (1≤n≤100)이 주어집니다.출력
각 테스트 케이스마다, n개의 정사각형으로 구성된 세로 단조 폴리오미노의 수를 출력합니다. 폴리오미노의 수가 10,000,000 이상일 경우 10,000,000으로 나눈 나머지를 출력합니다.예제 입력
3
2
4
92예제 출력
2
19
4841817
풀이
이 문제는 소스코드 자체가 어렵다기 보다는 문제로부터 수학식을 세우는게 어려운 문제였다. 알고리즘을 풀다보니, 수학적 또는 이론적인 식을 먼저 만들어야 문제 풀기 훨씬 쉽고 틀릴 확률도 적다는것이 새삼스레 느껴진다.
각설하고, 문제를 자세히 보면 세로로 단조라는 말은 즉, 정사각형들이 가로로 붙어있다는 것을 의미한다. 사각형을 맨 위에서부터 아래로 쌓아나간다고 가정한다면, 우리는 맨 위에서부터 한 가로줄에 놓일 사각형의 개수를 정하면 된다.
예를 들면,
4개의 정사각형을 가지고 첫째줄에 4개의 사각형의을 놓는다고 하면 아래와 같다.
ㅁㅁㅁㅁ
반면, 4개의 정사각형을 가지고 첫째줄에 3개의 사각형을 놓는다고 하면 아래와 같이 세 가지 경우가 있을 것이다(... 은 무시하자).
ㅁㅁㅁ
ㅁ
ㅁㅁㅁ
.. ㅁ
ㅁㅁㅁ
..... ㅁ
poly(n, first)를 n개의 정사각형을 가지고 첫번째 줄에 first의 개수를 놓았을 때의 폴리오미노의 개수라고 한다면, 다음과 같은 식이 성립한다.
poly(n, first) = poly(n - first, 1) + poly(n - first, 2) + ... + poly(n - first, n - first)
이 식을 간단히 하면 다음과 같다.
poly(n, first) = sum(poly(n - first, second)) (second: 1 ~ n - first)
여기까지 오면 재귀함수를 쓸 수 있을 것 같다는 느낌이 뿜뿜 온다.
하지만 여기서 놓쳐선 안될 것이 있다.
아래 그림과 같이 5개의 정사각형을 가지고 첫번째 줄에 2개의 정사각형을 놓을 경우, 두번째 줄에 3개의 정사가형이 놓여진다면 개수는 아래와 같이 5개가 된다.
..... ㅁㅁ
ㅁㅁㅁ
.. ㅁㅁ
ㅁㅁㅁ
ㅁㅁ
ㅁㅁㅁ
ㅁㅁ
.. ㅁㅁㅁ
ㅁㅁ
ㅁㅁㅁ
즉 두번째 줄에 놓이는 정사각형의 개수가 second 개라고 한다면, 첫번째 줄의 정사각형의 개수가 first 일 때 (first + second - 1)의 경우의 수가 생기게 된다.
따라서, poly(n, first) = poly(n - first, 1) + poly(n - first, 2) + ... + poly(n - first, n - first) 식은
poly(n, first) = (first + 1 - 1) * poly(n - first, 1) + (first + 1 - 2) * poly(n - first, 2) + ... + (n - 1) * poly(n - first, n - first)
와 같이 확장된다.
이를 간단히 표현하면
poly(n, first) = sum((first + second - 1) * poly(n - first, second)) (second: 1 ~ n - first)
식만 있다면, 이를 재귀함수로 변경하는것은 크게 어렵지 않다.
int poly(int n, int first) {
if (n == first) return 1;
int& res = cache[n][first];
if (res != -1) return res;
res = 0;
for (int second = 1; second <= n - first; second++) {
res += ((first + second - 1) * poly(n - first, second)) % MOD;
res %= MOD;
}
return res;
}10,000,000 이상일 경우 10,000,000으로 나눈 나머지를 출력하라고 한 만큼 MOD연산에 주의해야겠다.
마지막으로 한가지 더 주의할 점은, 이 poly함수를 호출하는 부분이다.
맨 윗줄은 (first + second - 1)와 같은 식을 곱해줄 필요가 없음으로, 아래와 같이 맨 윗줄에서 second의 개수를 바꿔주며 호출한 값을 더해주어야 한다.
int sum = 0;
for (int i = 1; i <= N; i++) {
sum += poly(N, i);
sum %= MOD;
}이를 poly함수 안에서 깔끔하게 표현하려고 고민하다 결국 main 함수 쪽으로 빼버리고 말았다.
여기서도 역시 MOD 연산에 주의하여야 한다.
소스 코드
#include<iostream>
#include<cstring>
using namespace std;
const int MOD = 10000000;
int N;
int cache[101][101];
int poly(int n, int first) {
if (n == first) return 1;
int& res = cache[n][first];
if (res != -1) return res;
res = 0;
for (int second = 1; second <= n - first; second++) {
res += ((first + second - 1) * poly(n - first, second)) % MOD;
res %= MOD;
}
return res;
}
int main() {
int testCase;
cin >> testCase;
for (int tc = 0; tc < testCase; tc++) {
memset(cache, -1, sizeof(cache));
cin >> N;
int sum = 0;
for (int i = 1; i <= N; i++) {
sum += poly(N, i);
sum %= MOD;
}
cout << sum << endl;
}
return 0;
}풀이 후기
아아.. 아직 중급 난이도는 무리인 것인가..
논리적인 식을 세우기가 어려워서 서적을 참고하였다.
역시 수학이든 알고리즘이든 빅데이터든 수학적 모델링이 중요한 것 같다.
조금만 더 생각했으면 서적을 안보고도 풀었을텐데, 뭔가 몇프로식 모자란것 같다.
계속 뇌를 굴리다보면 언젠가 경지에 이를 것이다. 열심히 하자.
오늘도 역시나 mod 연산이 들어있었다. 다 풀어놓고도 mod연산에서 삐끗하면 답 전체가 틀려버린다. 주의하자.
