오늘은 'Amazon Neptune'을 키워드로 '나이키'의 사례와 'Homesite'의 사례를 살펴보겠습니다✨
1. Nike
소개
Nike ecosystem에서 social graph를 담당하고 있습니다. NRC, NTC와 같은 프론트엔드부터 Data Lake에서 일어나는 분석까지 넓은 범위의 나이키 애플리케이션을 가지고 있습니다. 사용자와 그들의 흥미간의 관계를 형성하는 데에 전권을 지니고 있습니다.
아키텍쳐 다이어그램
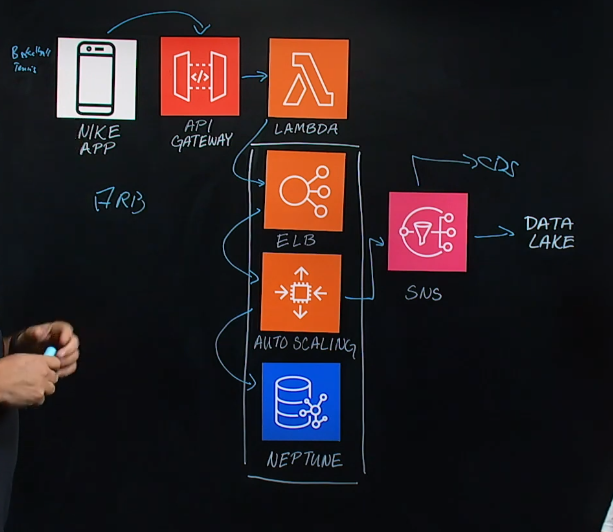
아키텍쳐 설명
-
먼저 app에서 고객은 그들이 흥미를 가지고 있는 스포츠중에 하나를 선택합니다. 그리고 나이키는 이러한 데이터들을 수집하여 API Gateway로 흘러갑니다. 그리고 그곳에서 데이터를 빼돌리기 위해 Lambda를 사용합니다. 해당 레이어에서는 다른 비즈니스 로직은 없고 단순히 깔때기의 역할입니다.
-
글로벌 브랜드인 나이키 앱은 동시 접속자가 많기 때문에 그 이후 고가용성과 회복력을 위해 ELB로 가게 됩니다. 그리고 Auto Scaling ec2을 사용합니다. 그리고 사용하는 datastore는 Neptune입니다. ec2 Auto Scaling 인스턴스는 graph 데이터베이스에 쓰기를 담당하고 있습니다.
-
견뎌야하는 로드때문에 두 쌍의 클러스터를 가지고 있는데, 하나의 writer 노드와 두개의 reader 노드를 지니고 있어서 모든 것이 순조롭게 작동합니다.
-
Amazon Neptune에 사용자들의 선호와 프로필에 기반한 write이 발생했을 때 이러한 시그널은 여러 나이키 팀들이 알아야하기 때문에 SNS를 사용합니다. 고객들이 흥미를 가지고 있는 스포츠에 대한 시그널입니다. SNS에는 여러 구독자들이 있는데, Data lake도 이중 하나이며, CDS라는 나이키의 내부 시스템도 이 중 하나입니다. 나이키에서의 모든 행동들이 이러한 흥미 시그널에 기반하여 이루어지기 때문에 같은 토픽을 들어야하는 복수의 구독자들이 있을 때 SNS를 사용하는 것은 좋습니다.
-
궁극적으로 end user가 보는 모든 컨텐츠들은 이러한 방식으로 큐레이트되며 업데이트된 개인화 맞춤형 컨텐츠입니다. scale에 대해서 수치적으로 살펴보자면 나이키 앱의 사용자는 전세계에 있으며 수억명입니다. 2500만 사용자들에게 1억 2500만의 user relationship(고객-흥미)이 있으며 (한 사용자가 여러 스포츠에 흥미가 있는 경우들이 있기 때문에) 전세계에서 사용하기 때문에 downtime이 24/7 거의 있어서는 안됩니다.
-
Apache cassandra를 사용하다가 나이키만의 ARB원칙과 많은 관리 오버헤드의 문제로 해당 도메인과 맞지 않아 비즈니스 로직에만 신경쓸 수 있는 관리형의 Neptune으로 옮기게 되었습니다. 또 다른 기술적 이점은 한 번만 쿼리할 수 있는 기능과 실제로 키 밸류 스토어를 사용할 수 있는 기능이었습니다. 관계가 직접 저장되지 않기 때문에 동시에 여러 테이블을 쿼리해야 하는 경우에 말입니다. Neptune으로 이를 단순화할 수 있었습니다.
Amazon Neptune이란? 빠르고 안정적인 완전관리형 그래프 데이터베이스 서비스로, 상호연결성이 높은 데이터 집합을 활용하는 애플리케이션을 손쉽게 구축 및 실행할 수 있습니다. Amazon Neptune은 한마디로 수십억 개의 관계를 저장하고 불과 몇 밀리초의 지연 시간으로 그래프를 쿼리하는 데 최적화된, 특수 목적의 고성능 그래프 데이터베이스 엔진입니다. Amazon Neptune은 Property Graph 및 W3C의 RDF 같은 인기 그래프 모델과 그에 맞는 쿼리 언어인 Apache TinkerPop Gremlin 및 SPARQL을 지원하므로, 상호연결성이 높은 데이터 세트를 효율적으로 탐색하는 쿼리를 손쉽게 구축할 수 있습니다. Neptune은 추천 엔진, 부정 탐지, 지식 그래프, 신약 개발 및 네트워크 보안과 같은 그래프 사용 사례를 지원합니다.
2. Homesite
소개
Homesite는 97년도에 설립되어 주택보험을 온라인으로 구매할 수 있는 최고의 경험을 제공하고자하는 비즈니스 모델입니다. 이 모델의 큰 부분은 가정 보험이나 주요 자동차 보험과 같은 다른 보험 제공자로부터 가져오는 것입니다. 그들을 파트너라고 부르며, 그들의 UI에서 우리의 UI로까지의 원활한 경험을 제공합니다. 즉, white-label 회사입니다.
이러한 사용자 경험을 통해 리드를 도입하고 견적을 제시할 수 있습니다. Homesite에는 다양한 파트너의 특정 요구사항을 중심으로 설계해야 하는 많은 경험이 있습니다. 그런 다음 스키마가 서로 다른 세분화 단위로 데이터를 생성하는 솔루션 계층도 많이 있습니다. Homesite가 원하는 것은 이 데이터에 대한 하나의 통합된 비전을 제공하여 서비스를 개선하고 무엇이 작동하고 무엇이 작동하지 않는지 더 잘 이해할 수 있도록 하는 것입니다.
아키텍쳐 다이어그램
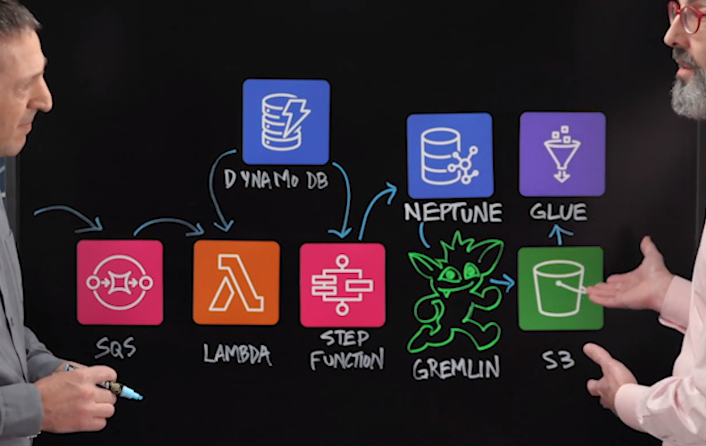
아키텍쳐 설명
-
먼저, 이 전체 다이어그램의 왼쪽에서 시작을 합니다. 왼쪽에는 Glue에 기반한 서버리스 데이터파이프라인이 있는데, 그들이 processing이 끝나면 SQS에 이벤트를 쓰면서 이 다이어그램에서의 아키텍쳐가 시작됩니다. SQS는 단계들간의 조직화를 위해 사용합니다. SQS는 기본적으로 lambda를 트리거할 수 있습니다. Job-Initiator lambda라고 부릅니다.
-
lambda에서 가장 먼저 하는 것은 DynamoDB로부터 파이프라인의 정의를 읽는 것입니다. 이 아키텍쳐에서 DynamoDB로 두 가지의 일을 합니다. 하나는 파이프라인의 환경 설정을 저장하여 이러한 단계들이 이후에 재사용되고 새로운 record를 Dynamo에 씀으로써 쉽게 배포되도록 하는 것입니다. Dynamo는 NoSQL 데이터베이스이기 때문에 JSON으로 정의될 수 있으므로 스키마가 쉽게 적용될 수 있습니다. 두번째는 Dynamo를 사용하여 작업의 종료 상태를 작성하여 전체 파이프라인 및 해당 상태에 대한 오케스트레이션 및 보고를 지원합니다.
-
이 lambda가 파이프라인 정의뿐만 아니라 아키텍쳐의 왼쪽에 있는 모든 다른 파이프라인의 exit 상태를 읽었을 때, 이것은 Step Function을 시작합니다. Step Function은 상세 단계 조정의 핵심으로, 데이터를 Neptune으로 로드하고 다른 작업을 수행하기 위해 실행됩니다. 우리는 vertices와 edges를 Neptune에 로드하는데, 그 이전에, 그러기 위해서는 클러스터가 강력해야 합니다. 모든 리소스들을 가지고 있어야하고 많은 양의 데이터들을 관리해야하기 때문입니다. Step Function에서 인스턴스를 R5.xlarge에서 R5.4xlarge로 scale-up하기 위해 boto3 호출을 사용합니다. 그렇게 하는 이유는 Neptune이 비즈니스 문제를 해결하는 동안 큰 인스턴스가 계속 돌아가기를 원치 않기 때문입니다. UTL을 할 때만 확장하면 비용 차이가 50%가 넘습니다.
-
Scale-up을 하고나면, 필요한 마력이 다 있게 됩니다. 이제는 광범위한 데이터 접근을 관리할 필요가 있습니다. Neptune은 Tom Sawyer와 다른 그래픽 UI를 사용하여 데이터 과학자들에게 유용한 도구입니다. 그 다음 그들은 GREMLIN 쿼리를 만드는데, 이 쿼리에 기반하여 이 모델을 통과하여 데이터를 S3로 내보낼 수 있습니다. 비용효율적인 방법입니다. 그 다음 Glue로 분류해서 Athena를 통해 노출시킵니다.
