1. Bigtable
대규모 분석 및 운영 워크로드를 위한
확장 가능한 완전 관리형 NoSQL 데이터베이스 서비스
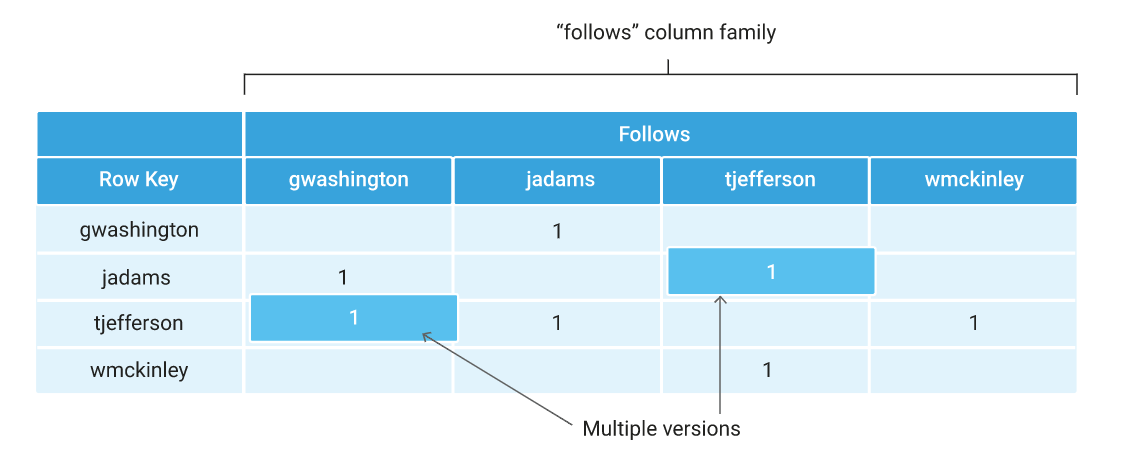
Cloud Bigtable은 수십억 개의 행과 수천 개의 열까지 확장하여 수 테라바이트, 심지어 수 페타바이트의 데이터까지 저장할 수 있으며 데이터 밀도가 낮은 테이블이다. 각 행의 단일 값에 대한 색인이 생성되는데, 이러한 값을 row key라고 부른다. Cloud Bigtable은 매우 낮은 지연 시간으로 매우 많은 양의 단일 키 입력 데이터를 저장하는 데 적합하다. Cloud Bigtable은 낮은 지연 시간으로 높은 읽기 및 쓰기 처리량을 지원한다.
- 뛰어난 확장성
Cloud Bigtable은 클러스터에 있는 머신 수에 따라 확장된다. 자체 관리형 HBase 설치는 특정 임계값에 도달한 후 성능이 제한되는 설계상의 병목 현상이 있지만, Cloud Bigtable은 이러한 병목 현상이 없으므로 클러스터를 계속 확장하여 더 많은 읽기 및 쓰기를 처리할 수 있다. - 간단한 관리
Cloud Bigtable은 업그레이드 및 재시작을 투명하게 처리하고, 높은 데이터 내구성을 자동으로 유지한다. 데이터를 복제할 때 두 번째 클러스터를 인스턴스에 추가하기만 하면 복제가 자동으로 시작된다. 더 이상 복제본 또는 리전을 관리할 필요가 없으며 테이블 스키마만 설계하면 Cloud Bigtable에서 나머지를 자동으로 처리한다. - 다운타임 없이 클러스터 크기 조절
몇 시간 동안 Cloud Bigtable 클러스터 크기를 늘려서 대규모 로드를 처리한 후 클러스터 크기를 다시 줄일 수 있다. 다운타임 없이 이 모든 작업을 수행할 수 있다. 클러스터 크기를 변경하면 일반적으로 Cloud Bigtable에서 클러스터에 있는 모든 노드의 성능을 균등화하는 데 몇 분 정도 걸린다.
장점
Cloud Bigtable은 키/값 데이터에 매우 높은 처리량과 확장성이 필요한 애플리케이션에 적합하다. 여기서 각 값은 일반적으로 10MB 이하이다. 또한 Cloud Bigtable은 일괄 MapReduce 작업, 스트림 처리/분석, 머신러닝 애플리케이션을 위한 스토리지 엔진으로도 적합하다.
Cloud Bigtable를 사용하면 다음 유형의 모든 데이터를 저장 및 쿼리할 수 있다.
- 시계열 데이터 - 여러 서버의 시간별 CPU 및 메모리 사용량
- 마케팅 데이터 - 구매 내역 및 고객 선호도
- 재무 데이터 - 거래 내역, 주식 가격, 통화 환율
- 사물 인터넷(IoT) 데이터 - 에너지 측정기 및 가전제품의 사용량 보고서
- 그래프 데이터 - 사용자가 서로 연결되는 방법에 대한 정보
Cloud Bigtable은 관계형 데이터베이스가 아니다. (NoSQL을 Not only SQL이 아닌 NoSQL의 정의로 사용하여 특징을 지니고 있다.) SQL 쿼리, 조인 또는 다중 행 트랜잭션을 지원하지 않는다. Cloud Bigtable은 1TB 미만의 데이터를 저장하는 데 적합한 솔루션이 아니다.
- OLTP(온라인 트랜잭션 처리) 시스템에 전체 SQL 지원이 필요하면 Cloud Spanner 또는 Cloud SQL을 사용하는 것이 좋다.
- OLAP(온라인 분석 처리)에 대화형 쿼리가 필요하면 BigQuery를 사용하는 것이 좋다.
- 문서 데이터베이스에 고도로 구조화된 객체를 저장하고 ACID 트랜잭션 및 SQL과 비슷한 쿼리를 지원해야 하면 Firestore를 사용하는 것이 좋다.
- 지연 시간이 짧은 인메모리 데이터 스토리지에는 Memorystore를 사용하는 것이 좋다.
- 실시간으로 사용자 간에 데이터를 동기화하려면 Firebase 실시간 데이터베이스를 사용하는 것이 좋다.
2. Bigquery
민첩성을 확보하기 위해 설계된 서버리스 클라우드 데이터 웨어하우스로, 높은 확장성과 비용 효율성을 갖추고 있다.
대규모 데이터세트를 저장하고 쿼리할 때 올바른 하드웨어와 인프라를 사용하지 않으면 많은 시간과 비용이 소비될 수 있다. BigQuery는 Google의 인프라 처리 능력을 사용하여 매우 빠른 SQL 쿼리를 실현함으로써 이러한 문제를 해결하는 기업용 데이터 웨어하우스이다. BigQuery로 데이터를 이동하기만 하면 힘든 작업은 Google에서 처리한다. 비즈니스 요구 사항을 기준으로 다른 사용자에게 데이터를 보거나 쿼리할 수 있는 능력을 부여하는 등 프로젝트와 데이터에 대한 액세스를 제어할 수 있다.
1. 클라우드 서비스로 설치/운영이 필요 없다 (NoOps)
: 간단하게 클릭 몇 번으로 서비스 사용이 가능하고, 별도의 설정이나 운영이 필요 없다.
2. SQL 언어 사용
: 기존 RDBMS에서 사용되는 SQL언어를 그대로 사용한다.
3. 클라우드 스케일의 인프라를 활용한 대용량 지원과 빠른 성능
: 대용량 인프라를 공유하는 클라우드 서비스이기 때문에 다수의 CPU, 하드디스크, 네트워크를 사용할 수 있다. (빠른 성능, 저렴한 비용)
4. 데이터 복제를 통한 안정성
: 3개의 복제본이 서로 다른 데이터 센터에 분산되어 저장되기 때문에 데이터에 대한 유실 위험이 적다.
5. 배치와 스트리밍 모두 지원
: 한꺼번에 데이터를 로딩하는 배치 외에, 실시간으로 데이터를 입력할 수 있는 스트리밍 기능을 제공한다.
6. 비용 정책
: 딱 저장되는 데이타 사이즈와, 쿼리시에 발생하는 트렌젝션 비용만큼만 과금이 된다.
아래 첨부된 테이블은 코세라 수업에서 제시된 기술적 디테일과 유즈케이스 별로 스토리지 옵션을 비교해놓은 표이다.
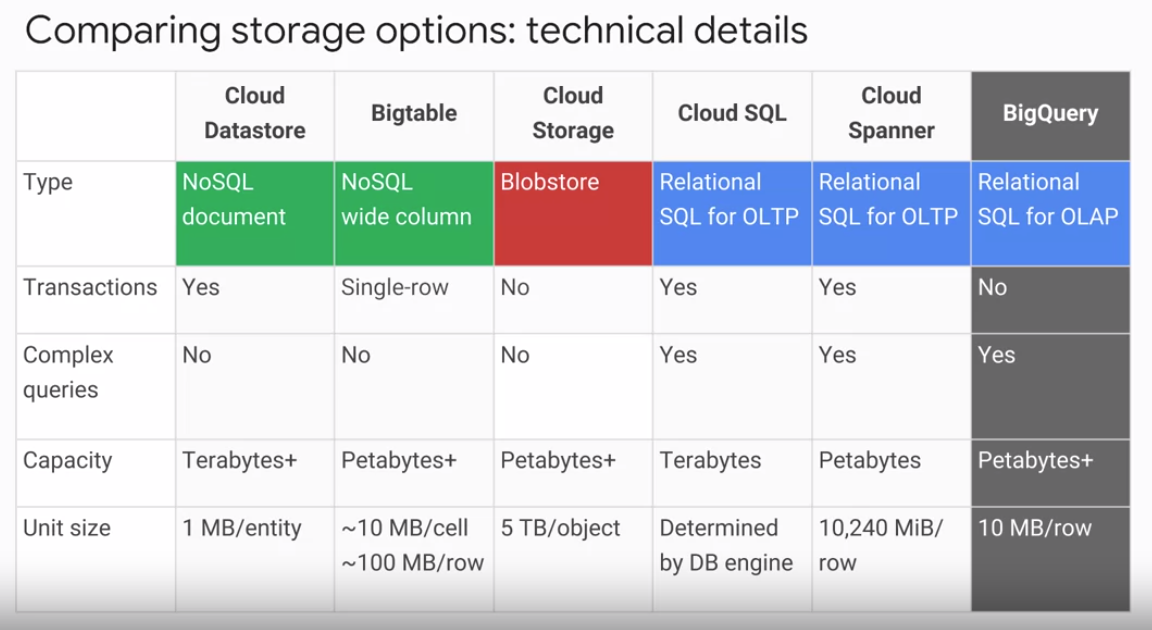

Bigquery 특징 정리 : https://bcho.tistory.com/1116 [조대협의 블로그]

Spice up your love life with our escorts in paharganj! Our gorgeous models know exactly how to blow your mind and rock your world. Ignite your love life with the captivating presence of our gorgeous models. They possess the skills and charm to blow your mind and rock your world with our unforgettable adventures.
Gurgaon Escort
Majnu Ka Tilla Escorts Service
South Ex Escort Service
Escorts In Karol Bagh
Escort In Laxmi Nagar
Escort In Laxmi Nagar
Lajpat Nagar Escorts