오늘 할 랩은 Dataflow와 Bigquery를 이용해서 ETL Processing!
1. 시작 코드 다운로드하기
gsutil -m cp -R gs://spls/gsp290/dataflow-python-examples .
자주 사용할 변수를 정해준다.
export PROJECT=<YOUR-PROJECT-ID>gcloud config set project $PROJECT2. 스토리지 버킷 만들기
gsutil mb -c regional -l us-central1 gs://$PROJECTus-central1 리전에 만들어주었다.
3. 파일들을 버킷에 복사하기
gsutil cp gs://spls/gsp290/data_files/usa_names.csv gs://$PROJECT/data_files/
gsutil cp gs://spls/gsp290/data_files/head_usa_names.csv gs://$PROJECT/data_files/4. Big query에 데이터셋 만들기
bq mk lakelake라는 이름의 데이터셋을 만들었다. 모든 데이터들이 Big query에 로드된다.
5. Dataflow Pipeline 만들기
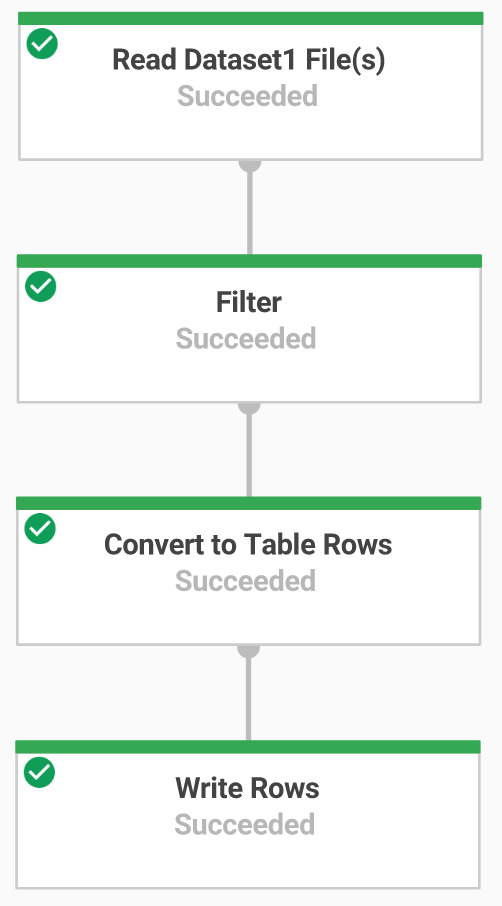
6. pipeline 파이썬 코드 리뷰하기
Code Editor를 클릭하여, dataflow-python-examples > dataflow_python_examples의 data_ingestion.py를 열어서 리뷰한다.
7. Apache Beam Pipeline 작동시키기
Cloud shell로 돌아와서 필요한 파이썬 라이브러리에 대해 약간의 설정을 수정한다.
cd dataflow-python-examples/
# Here we set up the python environment.
# Pip is a tool, similar to maven in the java world
sudo pip install virtualenv
#Dataflow requires python 3.7
virtualenv -p python3 venv
source venv/bin/activate
pip install apache-beam[gcp]==2.24.0이제 클라우드에서 Dataflow 파이프 라인을 실행한다.
python dataflow_python_examples/data_ingestion.py --project=$PROJECT --region=us-central1 --runner=DataflowRunner --staging_location=gs://$PROJECT/test --temp_location gs://$PROJECT/test --input gs://$PROJECT/data_files/head_usa_names.csv --save_main_session
콘솔로 돌아와서 메뉴에서 Dataflow를 선택한다. 작업 이름을 클릭하여 진행 상황을 본다. 작업 상태가 Succeeded로 변경되었다.
이제는 Bigquery로 가서 데이터가 다 채워졌는지 확인한다. (Navigation menu > BigQuery)
프로젝트 이름(lake)을 클릭 하면 데이터 세트 아래의 usa_names 테이블이 표시된다.
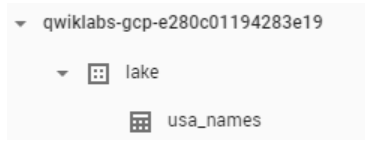
표를 클릭한 다음 미리보기 탭으로 이동 하여 usa_names데이터의 예를 확인한다.
8. 데이터 변환
이제 TextIO 소스와 BigQueryIO Destination이있는 Dataflow 파이프 라인을 빌드하여 데이터를 BigQuery로 수집한다. 구체적으로 다음을 수행한다.
- Cloud Storage에서 파일을 수집한다.
- 읽은 줄을 dictionary object로 변환한다.
- 연도가 포함된 데이터를 BigQuery가 날짜로 인식하는 형식으로 변환한다.
- 행을 BigQuery에 출력한다.
code editor로 이동하여 data_transformation.py 코드를 리뷰한다.
9. Apache Beam Pipeline 실행
python dataflow_python_examples/data_transformation.py --project=$PROJECT --region=us-central1 --runner=DataflowRunner --staging_location=gs://$PROJECT/test --temp_location gs://$PROJECT/test --input gs://$PROJECT/data_files/head_usa_names.csv --save_main_session콘솔로 돌아와서 메뉴에서 Dataflow를 선택한다. 작업 이름을 클릭하여 진행 상황을 본다. 작업 상태가 Succeeded로 변경되었다.
이제는 Bigquery로 가서 데이터가 다 채워졌는지 확인한다. (Navigation menu > BigQuery)
프로젝트 이름(lake)을 클릭 하면 데이터 세트 아래의 usa_names_transformed 테이블이 표시된다.
