
저번 포스팅이후 퀵랩을 통해 세 개의 뱃지를 획득했다!
챌린지한 퀘스트는 다음과 같다
- Perform Foundational Infrastructure Tasks in Google Cloud

- Create and Manage Cloud Resources

- Perform Foundational Data, ML, and AI Tasks in Google Cloud

코세라를 들으면서 많은 핸즈온랩을 했지만 문제 상황만 보고 직접 고민해서 만들어보는 것이 더 많이 배울 수 있는 것 같아서 다른 퀘스트도 도전해봐야지 다짐했다.
그리고 오늘은! 세개의 퀘스트 중 마지막 퀘스트인 Perform Foundational Data, ML, and AI Tasks in Google Cloud에 있는 Dataflow, Dataprep, Dataproc을 간단히 만드는 방법을 적어보려고한다.
1. Dataprep 시작하기
-
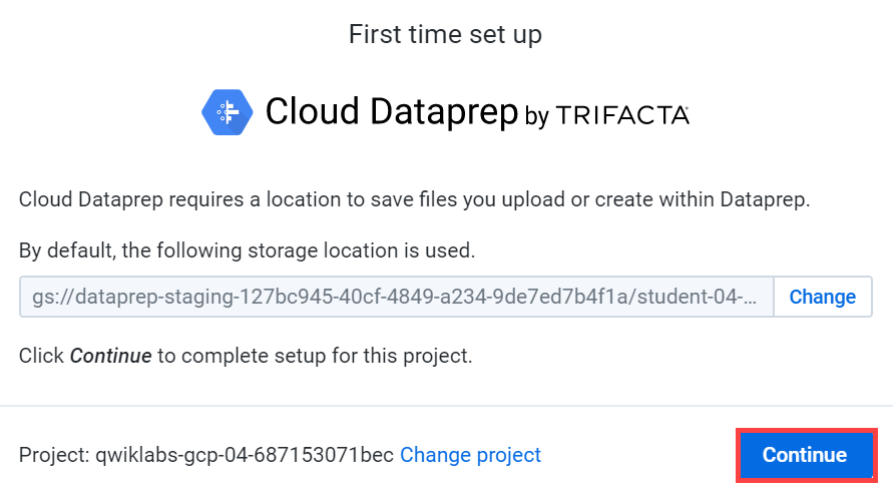
Select Navigation menu > Dataprep
(Dataprep은 초기 허용하고 승인해줘야할 것 들이 많이 뜬다, 다 승인 및 허용에 체크해주고 사용주인 username을 선택해주면 된다!)
-
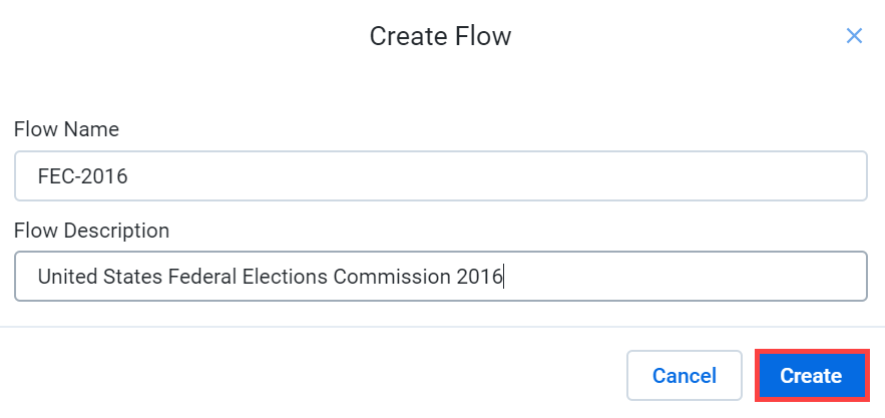
Create Flow를 누르고 Flow name과 Flow description을 지정해준다.

-
Create 버튼 클릭 -> Don't show me any helpers
-
지정한 flow에 데이터셋을 불러 올 차례다!
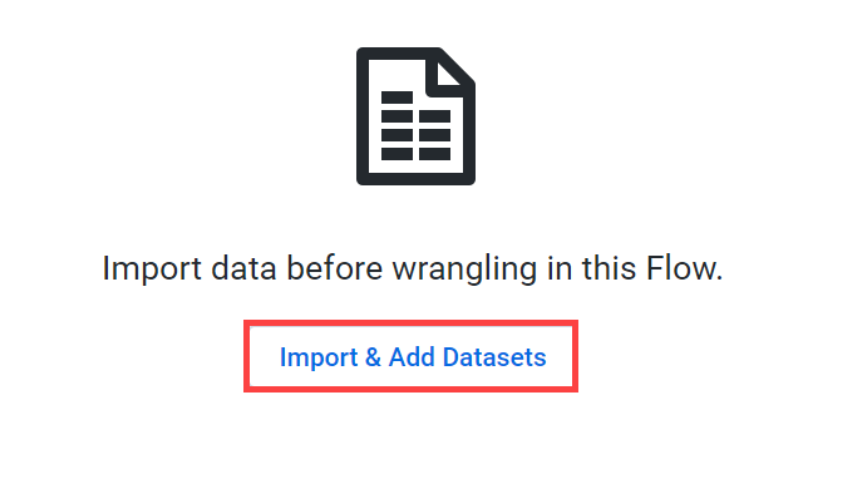
-
cloud storage를 선택해주고 연필을 클릭하여 파일 또는 폴더를 입력하는 칸에 gs://spls/gsp105를 입력해주었다.
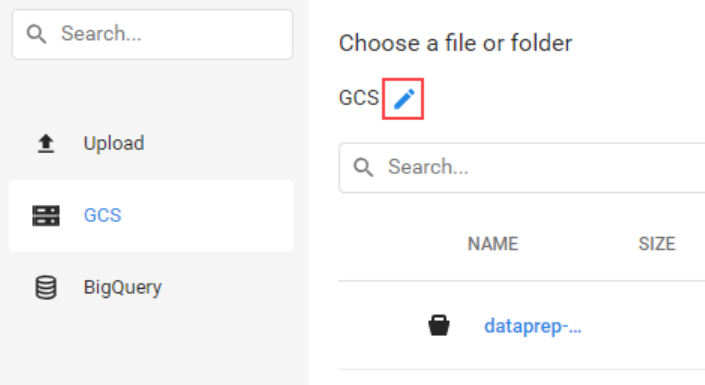
-
Import & Add to Flow 클릭 ! -> 데이터셋을 플로우에 불러오기 성공!
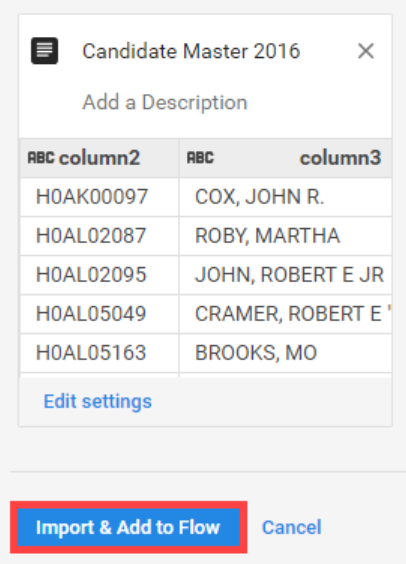
-
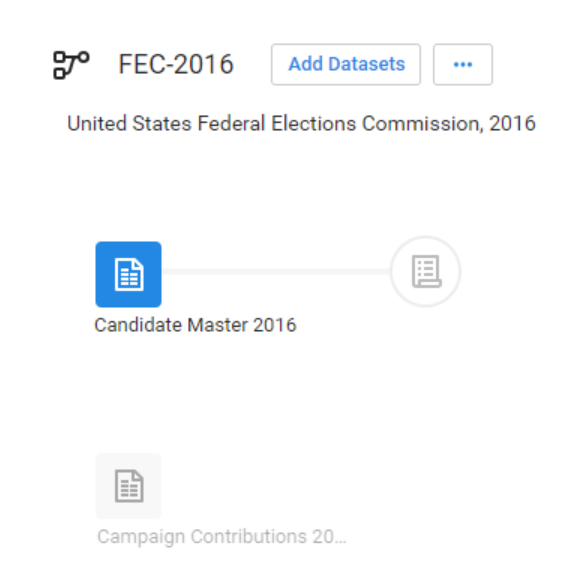
이제 Candidate file을 prep할 시간이다! Add new recipe 클릭하기
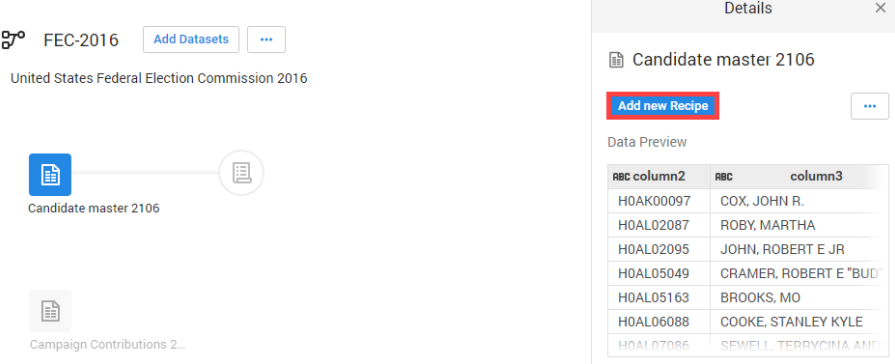
-
Edit recipe 클릭 (플로우에 prep될 파일이 생성된 것을 볼 수 있다)
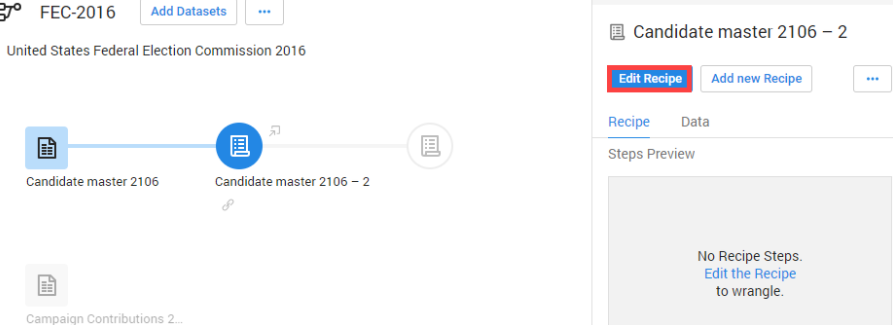
-
퀘스트에서 가장 유용했던 기능! 컬럼을 rename하거나 특정 데이터가 포함된 열을 지우는 등 raw data 를 원하는 데이터로 편집하기에 편리했다!

-
Join도 Dataprep에서 가능하다!
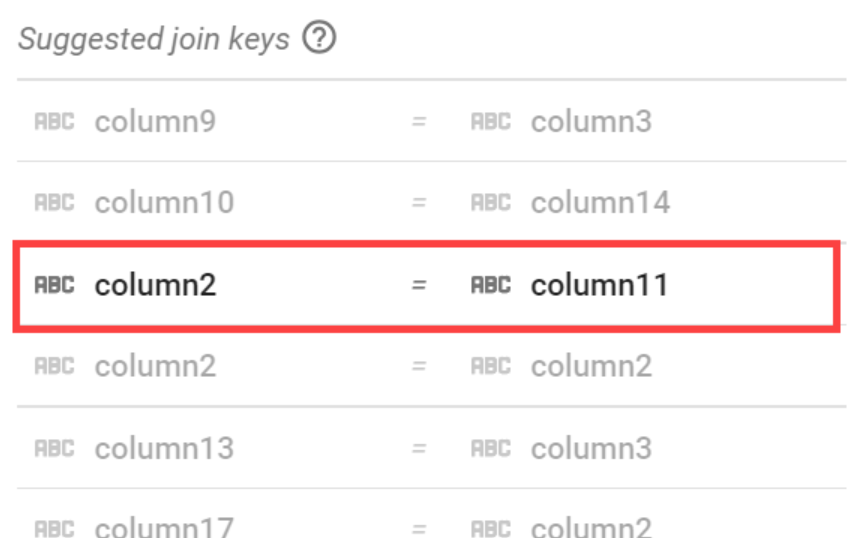
2. Dataflow 시작하기
Dataflow를 이용하여 Big query와 Storage를 연결하기 위해 먼저 Big query와 Storage를 생성해주었다.
1. taxirides 이름의 데이터셋 생성하기
bq mk taxirides- 빅쿼리 테이블 인스턴스화하기
bq mk \
--time_partitioning_field timestamp \
--schema ride_id:string,point_idx:integer,latitude:float,longitude:float,\
timestamp:timestamp,meter_reading:float,meter_increment:float,ride_status:string,\
passenger_count:integer -t taxirides.realtime- 스토리지 버킷 생성하기
export BUCKET_NAME=<your-unique-name>gsutil mb gs://$BUCKET_NAME/- 파이프라인 실행하기
4.1 Navigation > Dataflow 선택
4.2 + Create job from template 클릭
4.3 Job name 만들기
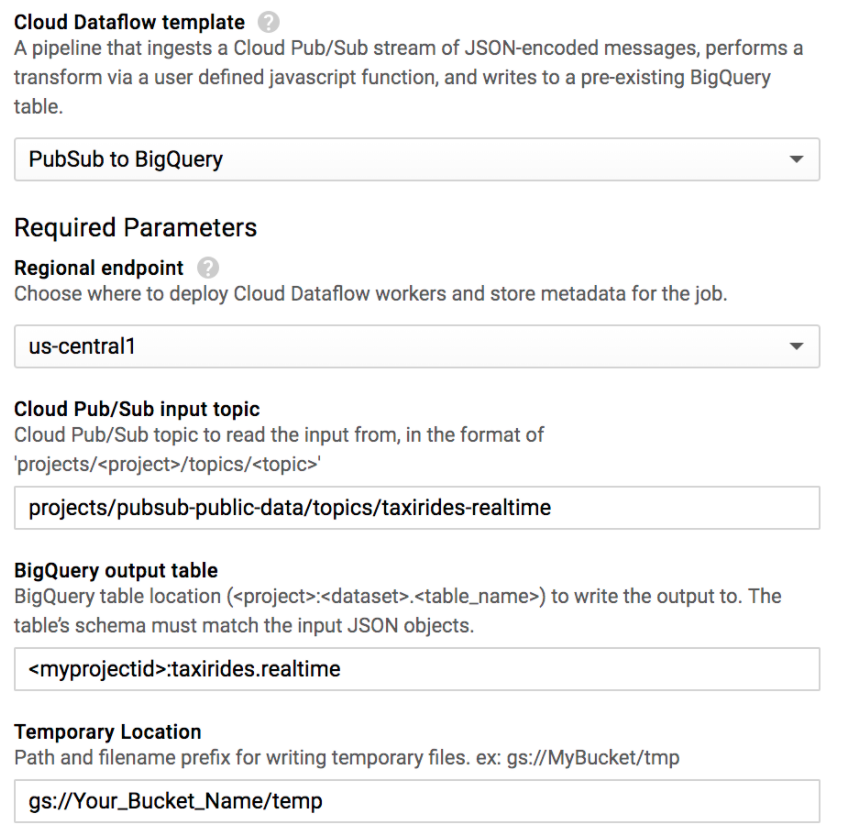
4.4 Dataflow template 선택하기 (이 경우, Cloud Pub/Sub Topic to BigQuery template)
4.5 Cloud Pub/Sub input topic 적어주기
4.6 name of the table 적어주기
4.7 Temporary Location로 생성한 버킷 적어주기
: gs://Your_Bucket_Name/temp
5. Run job !
3. Dataproc 시작하기
- Navigation menu > Dataproc > Clusters
- Create Clusters 클릭
- Name, Region, Zone 등을 설정
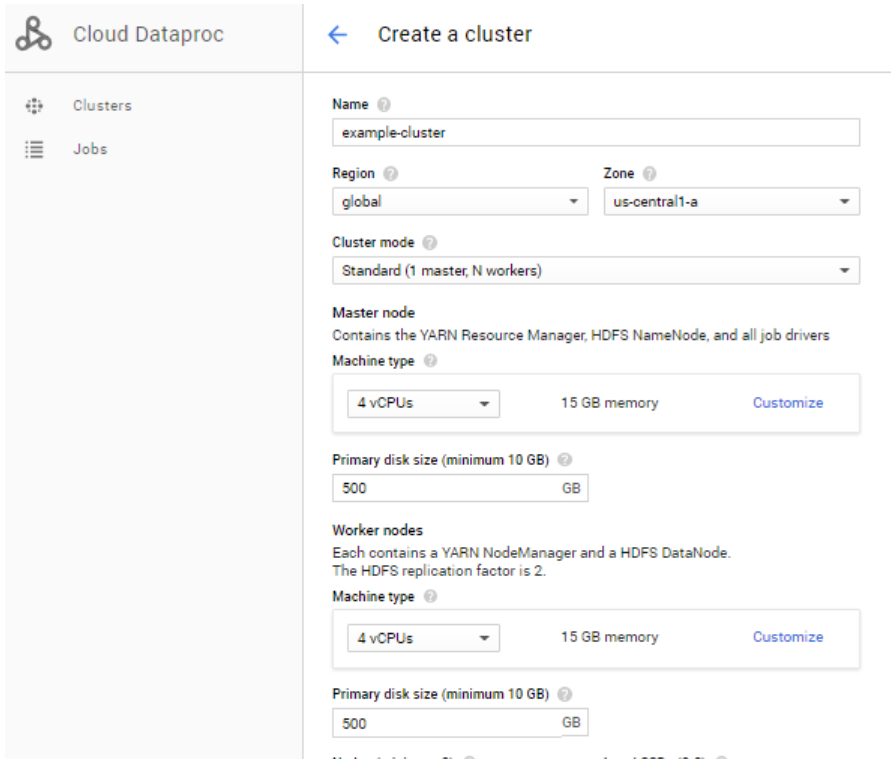
- Create 클릭!
- Navigation menu > Dataproc > Jobs
- Submit jobs
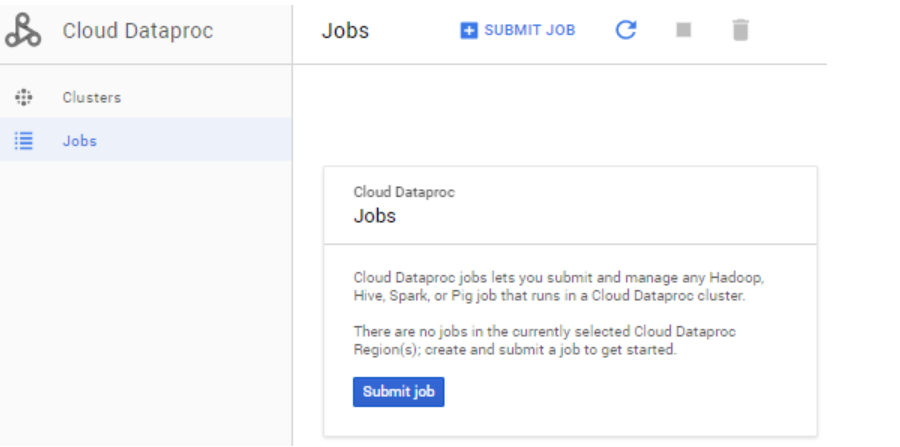
- 아까 생성한 클러스터를 선택해주고, 그 외 job type, Main class or jar, Arguments, jar file 등을 설정해준다.
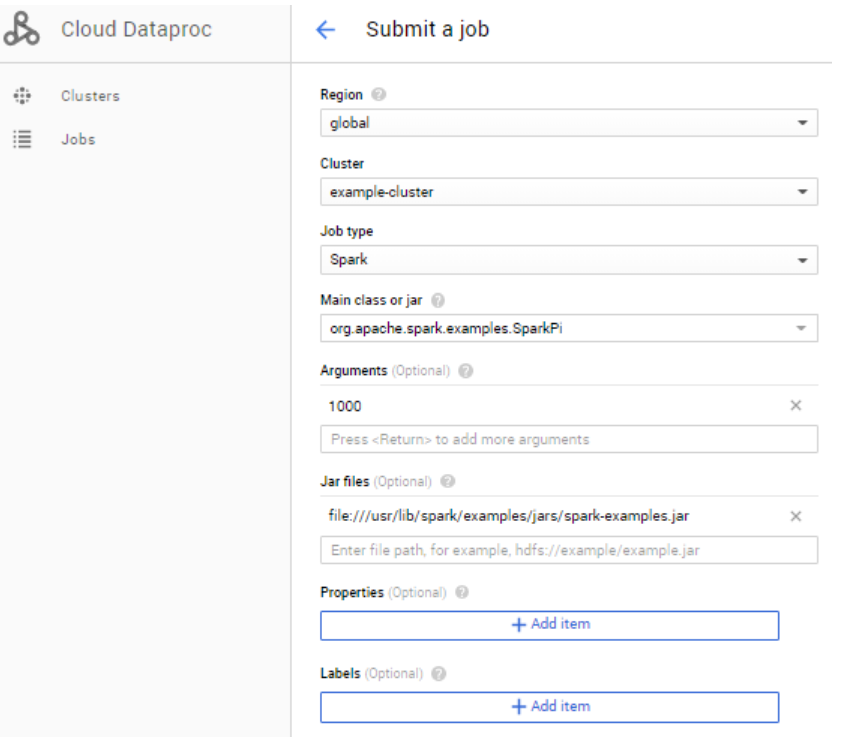
- Create 클릭!
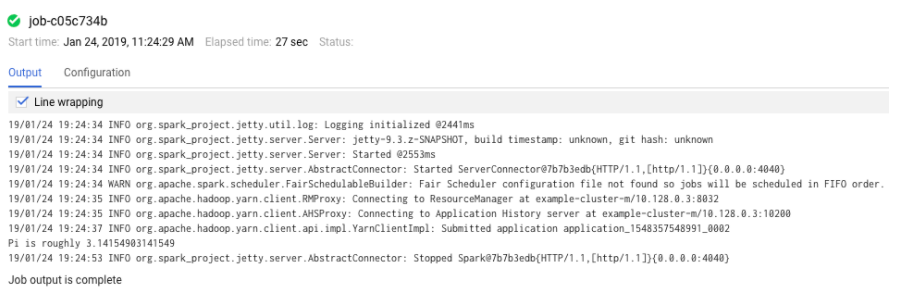
- Jobs 리스트에서 job id를 클릭하면 job output을 볼 수 있다

Looking for some adult fun in Delhi Area's? I've heard some stories about the Escorts in Delhi Area's. Anyone have recommendations for a safe and pocket-friendly Escorts Service in Delhi Area's experience? Specifically looking for nearby you options, maybe even a Housewife Escorts type. Book Tonight ideas are welcome!
Gandhi Nagar Escorts
Greater Noida Escorts Service
Escorts in Inderlok
Escorts Service Kalyanpuri
Escorts Service in Kirti Nagar