Data-Centric AI란?
데이터 수집, 전처리, 라벨링, 분석 등과 같이 데이터를 중심으로 AI의
품질을 향상하는 접근 방식을 의미합니다.
필수 선수 지식
- Deep Learning Basic
- Pytorch
- Machine Learning Basic
- Computer Vision Basic
- Natural Language Processing Basic
Multimodal
Multimodal Model ... PaLM-E @ Google
구글의 LLM인 PaLM 모델에 로봇 에이전트로부터 얻은 센서 데이터를 학습하여 멀티모달 언어 모델을 생성함
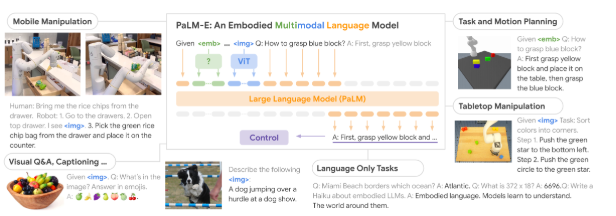
https://palm-e.github.io/
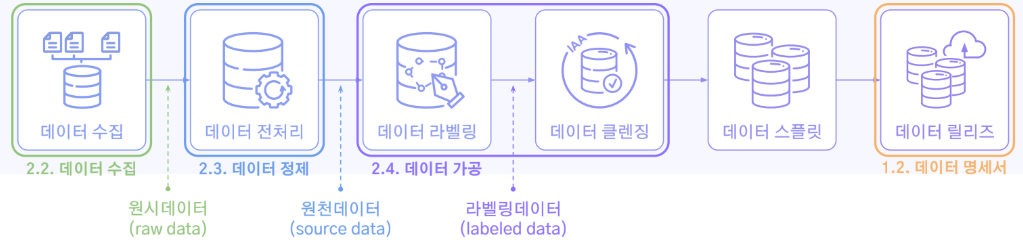
데이터 구축 프로세스는
1) 데이터 수집
2) 데이터 전처리
3) 데이터 라벨링
4) 데이터 클렌징
5) 데이터 스플릿
6) 데이터 릴리즈
데이터 구축 프로세스: 데이터 구축은 일반적으로 ①수집 → ②전처리 → ③라벨링 → ④클렌징 → ⑤스플릿 → ⑥릴리즈의 6단계 파이프라인으로 구성됩니다.
• 데이터 구축 기획서: 데이터 구축의 목적, 방법, 규모, 그리고 데이터 명세서 등을 포함하는 '데이터 구축 기획서' 작성법을 학습합니다. 이는 프로젝트의 방향을 설정하고 리소스 관리, 품질 관리, 잠재적 갈등 방지에 필수적입니다.
학습용 데이터의 기획 여러가지 고려 사항
-어떤 문제를 해결하기 위한 데이터인가?
-어떤 방식으로 해당 데이터를 수집할 수 있는가?
(수집 방식에는 문제가 없는지)
-얼마나 많은 양의,그리고 양질의 데이터를 수집해야 문제를 해결할 수 있는지
(수집한 데이터를 어떤 방식으로 정제할것인지,어떤 라벨을 누구로부터 어떻게 수집하는 것이 적절한지,
수집하는 데에 얼마나 많은 비용이 드는지)
- 기존 데이터와 어떤 차별점을 보이는가?
데이터 구축 기획서를 작성한는 이유
-명확한 방향 설정: 현황분석,데이터 필요성
-리소스 및 일정 관리: 인적,물적,금전적 어떻게 활용하여 마감 내에 완수할지를 결정
-갈등방지: 기획서 예산 및 리소스에 대한 의견 수합
향후 발생한는 문제들에 대한 사전 논의를 통해 갈등을 방지할 수 있음.
데이터 수집
데이터 수집 방법: 직접수집,크롤링,오픈소스,크라우드 소싱,데이터 타당성 검토
수집시 주의 사항: 라이센서,개인정보보호,윤리
크롤링의 프로세스
크롤링의 전체적인 흐름은 아래와 같으며, HTML을 수집하고 정제하는 과정에서 발생하는 예외들에 대해 지속적으로 검토해야 합니다.
1. 웹사이트 구조 파악 : 크롤링할 웹사이트의 계층 구조, URL 패턴, 페이지 간의 관계 등을 파악
2. 크롤링 도구 선택 : BeautifulSoup, Scrapy, Selenium 등의 파이썬 라이브러리 중 어떤 것을 사용할 것인지 결정
3. URL 수집 : 크롤링할 웹사이트의 주요 페이지 URL을 수집하여 크롤링할 URL 목록을 구성
4. HTTP 요청 및 다운로드 : 선택한 크롤링 도구로 대상 URL에 HTTP GET 요청을 보내고 HTML 소스코드를 다운로드
5. 데이터 추출 : HTML 소스코드를 분석하여 필요한 데이터를 추출
○ 이때, CSS 선택자나 XPath를 사용하여 원하는 HTML 요소를 추출함
6. 데이터 가공 : 추출한 데이터를 원하는 형태에 맞게 가공함
7. 데이터 저장 : 가공된 데이터를 크롤링한 데이터를 로컬 파일 또는 데이터베이스에 저장
8. 4 ~ 7번 과정을 반복
도메인별 크롤링
수집하고자 하는 데이터의 도메인에 따라 크롤링 활용
● 이미지/영상 ... 저작권, 보안, 용량 등의 이슈로 크롤링 하기 가장 어려운 데이터
WebVision Dataset
https://data.vision.ee.ethz.ch/cvl/webvision/dataset2018.html
⋀
● 시계열 ... 주식과 같은 데이터는 크롤링 방식으로 수집하는 것이 가장 효과적
https://www.kaggle.com/datasets/andrewmvd/sp-500-stocks
⋀
● 텍스트 ... 최근 NLP 분야가 LLM 위주로 발전함에 따라 크롤링을 통한 대용량의 텍스트 수집이 흔히 이루어짐
https://github.com/abisee/cnn-dailymail
데이터 전처리 (Data Preprocessing): 수집한 원시 데이트를 원천 데이터로 만들기 위해 가공 및 정제하는 단계(데이터 품질 확보,스키마 설계)
HTML(Hyper Text Markup Language)
웹페이지를 표현하기 위해 사용되는 대표적인 마크업 언어(markup language)
아래와 같은 문법을 따르고 있으며, 태그(<>)를 통해 문서의 계층 구조를 표현함
content
● 태그 (Tag)
● 클래스 (Class)
● 특성 (Attribute)
● 본문 (Content)


파이썬 크롤링 라이브러리
크롤링에 사용되는 대표적인 파이썬 라이브러리로는 Requests, BeautifulSoup, Scrapy, Selenium, 그리고 PyQuery가 있음
● Requests : http 요청(request)을 주고 받기 위해 만들어진 라이브러리
● BeautifulSoup : requests 등을 통해 받은 html 자료에서 데이터를 추출하는 데에 사용되는 라이브러리
● Scrapy : 크롤링을 위해 만들어진 프레임워크로, 다양한 기능 및 플러그인을 지원하는 라이브러리
● Selenium : 웹 자동화 테스트용 도구로, JavaScript를 렌더링하고 동적 페이지를 스크랩할 때 유용한 라이브러리
● PyQuery : jQuery와 유사한 구문을 사용하여 웹 페이지에서 데이터를 추출하는 파이썬 라이브러리
데이터 라벨링: Lebel Studio
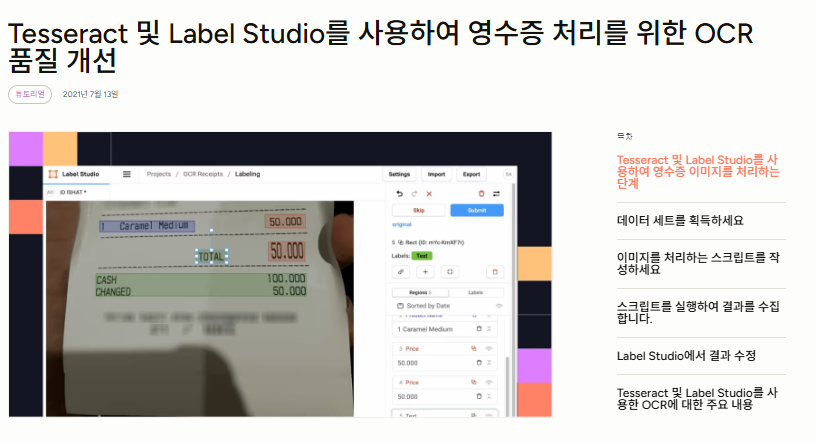
데이터 클렌징 (Data Cleansing; 데이터 정제)
라벨링된 데이터의 품질을 검수하고 기준 이하의 데이터를 정제하는 최종 클렌징 단계
-데이터 내재적 요소 검수
최종 데이터가 가이드라인을 잘 따라 만들어졌는지, 작업자들 간 라벨링이 일치하는지를 평가하여
이를 만족하지 못하는 데이터를 정제하는 단계
-데이터 외재적 요소 검수
데이터 다양성, 신뢰성, 충분성, 윤리 적합성 등 앞서 살펴본 모든 요소들
외부 자문위원들을 통해서 진행하는 것이 가장 이상적
● 기관생명윤리위원회 (Institutional Review Board, IRB)
○ 인간 대상 연구인 경우 IRB 기관 승인이 필요
● 한국정보통신기술협회 (Telecommunications Technology Association, TTA)
○ 인공지능 학습용 데이터 구축 사업의 일환으로 수집되는 데이터들은 모두
TTA로부터 구축 계획서부터 완료 시점까지 지속적인 품질 검수 절차를 밟음
데이터 스플릿 (Data Split)
원천 데이터 및 라벨링 데이터를 배포하기 위해 분할하는 단계
학습, 검증 및 테스트 데이터로의 분할
(데이터 샘플링 기법을 활용하여 전체 데이터셋을 학습, 검증, 테스트 데이터로 3분할 진행)
데이터 릴리즈 (Data Release)
데이터의 구축 의도에 맞는 배포처를 정하고, 데이터의 활용에 필요한 정보를 담은 문서를 제작하여 배포하는 단계
최종 데이터 산출물을 전달 혹은 배포하는 단계
데이터 명세서(최종 데이터 산출물의 명세표)

배포할 내용
● 원천 데이터 및 라벨링 데이터
● 버전 관리 체계에 맞는 버전 및 로그 기록
● 데이터셋의 라벨 분포를 비롯한 샘플 데이터의 형태
● 데이터 분석서 및 품질 평가서
어디에 배포할 것인지?
● 고객사 or 사내 모델개발팀
● 저널 or 학회
● 오픈소스 플랫폼
○ 허깅페이스(Huggingface)
○ 캐글(Kaggle)
데이터 구축 사이클의 종류
폭포수 모델 (Waterfall Model)
순차적인 소프트웨어 개발 프로세스로, 개발의 흐름이 마치 폭포수처럼 지속적으로 아래로 향하는 것처럼 보이는 데서 유래됨
이전 단계가 마무리되어야 다음 단계로 나아갈 수 있으며, 단계별 정의 및 산출물이 명확함
● 대량의 리소스가 필요하여 빠른 이터레이션을 돌리기에 부적합한 데이터의 경우
● 데이터 구축 과정에서 가이드라인 등의 변화가 생길 가능성이 적은 경우

나선형 모델 (Spiral Model)
순환적인 소프트웨어 개발 프로세스로, 일련의 개발 과정이 나선형을 그리며 반복된다는 점에서 유래됨
단순히 순환하는 것이 아닌, 나선형으로 다루고자 하는 범주를 확장해 나가면서 리스크를 줄임
● 소량의 고품질의 데이터를 만들어 빠르게 이터레이션을 돌리기에 적합한 경우
● 리스크를 최대한 줄여야 하는 중요한 데이터 구축 사업인 경우
● 데이터 구축을 장기간에 걸쳐 진행할 수 있는 경우
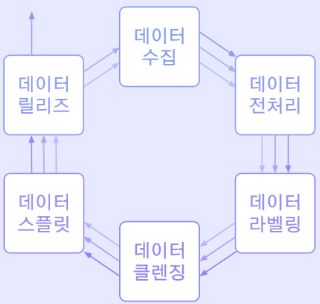
데이터 구축 프로세스의 특징
일반적인 소프트웨어 구축 프로세스보다 유연성이 높음
-이전 프로세스 단계로 돌아가는 과정이 어렵지 않음
-예외 상황이 발생하기 쉬우며 이에 유연한 자세로 대처할 수 있어야 함
어떤 모델을 사용하는지에 관계 없이 모든 데이터 구축 프로세스는 직렬적이지 않은 흐름으로 진행됨
-전처리를 하다가 충분한 양의 데이터가 확보되지 않으면 다시 데이터 수집 단계로 돌아갈 수도 있음
-라벨링을 하다가도 데이터에 문제가 있으면 전처리로 돌아가야할 수도 있음
-릴리즈를 했더라도 모델 성능이 낮으면 데이터 추가를 위해 수집 단계부터 재진행 할 수도 있음
