어떻게 학습데이터를 활용할 수 있을까?
학습데이터에는 질문이 포함되지 않는 과학 상식 정보를 담고 있는 순수 색인 대상 문서 4200여개가 제공됩니다. 이때, Retrieval 모델을 학습하기 위해선 어떻게든 pair 데이터를 구성하는 것이 유리합니다. 예를 들어, Question과 Answer, Document와 Question, Document와 summarization등이 있습니다. 하지만, 아쉽게도 학습데이터에는 이런 pair로 된 데이터셋은 존재하지 않습니다. 이럴 땐 데이터를 직접 만들 수 있습니다. 이번 토론콘텐츠에서는 Pair 데이터를 어떻게 만들 수 있을지 고민해봅시다.
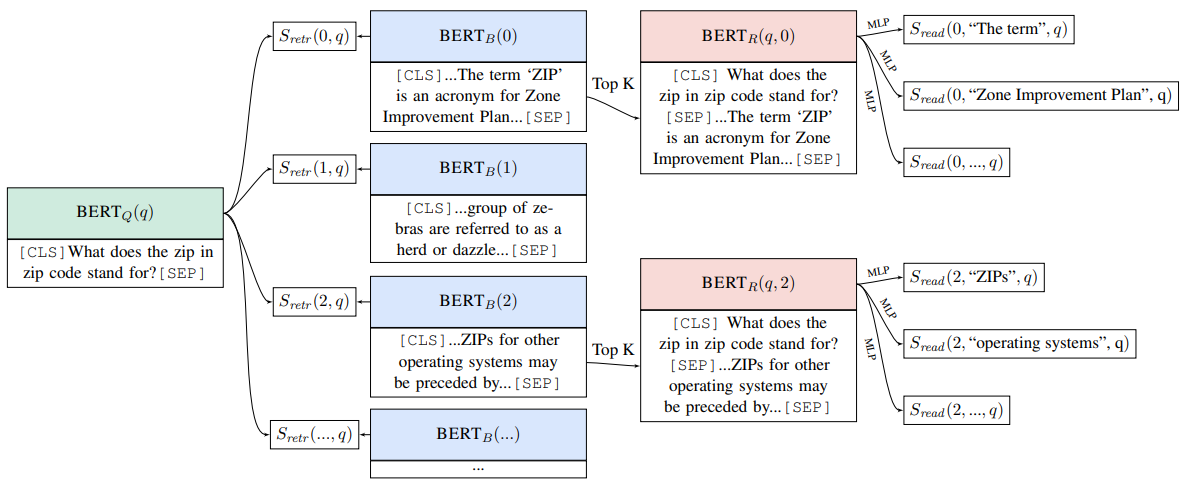
출처 https://arxiv.org/pdf/1906.00300
Inverse Cloze Task(ICT) 란, 특정 문장이나 단어를 문맥에서 제거하고, AI가 이를 바탕으로 누락된 정보를 예측하도록 요구합니다. ICT에서는 이 과정이 역으로 수행되어, AI는 주어진 문장을 문맥 정보로 사용하고 이를 기반으로 관련 문서나 텍스트를 찾아냅니다.
이를 Retrieval에서 활용하면 위의 예시처럼 간단히 데이터셋을 생성해 낼 수 있습니다.
얼룩말은 걷기, 속보, 구보, 갤럽의 네 가지 걸음걸이를 가지고 있습니다. 일반적으로 말보다 느리지만, 뛰어난 지구력으로 포식자를 따돌릴 수 있습니다. 쫓기면 얼룩말은 좌우로 지그재그로 움직입니다.
이런 글이 있을 때, 위와 같이 Document가 주어졌을 때 임의의 문장을 추출합니다. 해당 문장을 pseudo -Query로 보고 그리고 기존의 컨텍스트들을 해당 pseudo-Query가 찾고자 하는 pseudo evidence text로 지정할 수 있게 됩니다. 이를 통해 그리고 그 외의 Docuemnt들에서 문장을 추출해 만들어낸 pseudo-Query와 상관 없는 문장으로 볼 수 있겠죠. 이렇게 데이터셋을 만들어 낸다면 손쉽게 Retrieval task를 생성해 낼 수 있습니다.
2) 질문 생성
또 다른 방법으론 Question Generation 방법이 있습니다. Inverse Cloze Task는 대회의 평가와 다르게 Query를 질문 형태로 만들 수 없습니다. Document를 활용하여 질문을 생성하는 Question Generation task가 있습니다. 언어모델의 생성능력을 통해서 Document의 context를 파악하여 Question을 생성합니다.
Retrieval (검색) 단계 최적화: 하이브리드 검색 도입
현재 코드는 Elasticsearch의 sparse_retrieve (키워드 기반 BM25)만 사용하고 있습니다. RAG 시스템에서 검색 품질을 높이는 가장 일반적인 방법 중 하나는 하이브리드 검색 (Hybrid Search)을 도입하는 것입니다. 이는 키워드 기반 검색(sparse_retrieve)과 의미론적 유사도 기반 검색(dense_retrieve)의 결과를 결합하는 방식 진행
Elasticsearch 클라이언트 초기화, SentenceTransformer 모델 로드, Upstage Solar LLM 연동, RAG 질의 처리, AP 점수 계산, 제출 파일 생성, 평가 보고서 및 그래프 생성
Elasticsearch (ES_USERNAME, ES_PASSWORD, ES_CA_CERT_FILE)와 Upstage Solar LLM (UPSTAGE_API_KEY) 접속 정보가 코드 상단에 명확히 정의
Elasticsearch 연결 성공 여부도 명확하게 출력되도록 es.info() 호출 및 print 문이 추가
eval.jsonl 파일을 처리할 때 각 eval_id 별로 몇 번째 질문을 처리 중인지 ([idx/total_lines]) 진행 상황이 출력
LLM API 호출 시 [LLM Function Call]과 [LLM QA Call]에 각각 소요된 시간이 기록되어, 어느 단계에서 시간이 오래 걸리는지 직관적으로 확인할 수 있도록 로깅 기능이 추가되었습니다.
persona_function_calling과 persona_qa 프롬프트 정의 및 tools 기능이 answer_question 함수에 정확히 반영되었습니다. 이는 LLM이 검색을 호출하고 답변을 생성하는 RAG의 핵심 로직을 구성합니다.
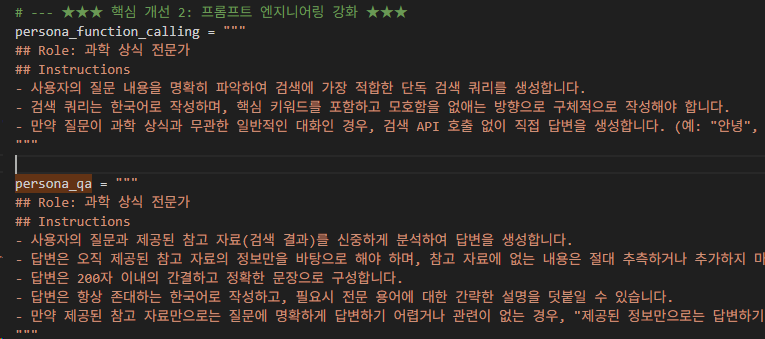
#평가 시스템 구축:
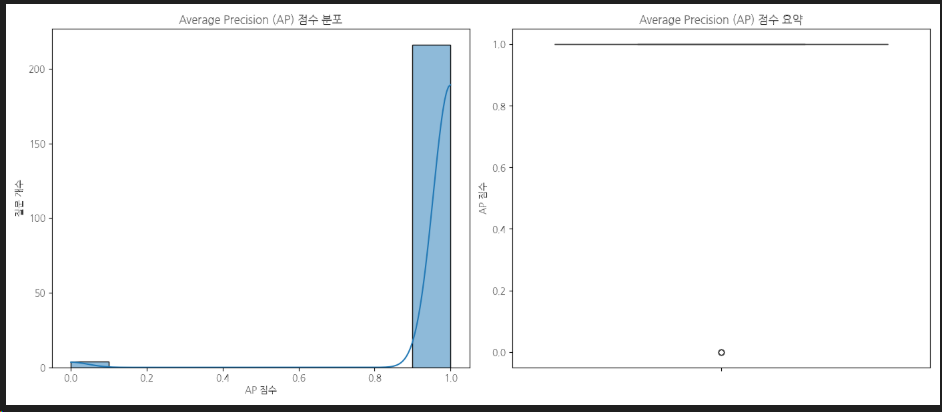
AP (Average Precision): 각 질문에 대해 검색된 topk 문서와 ground_truth_for_evaluation을 비교하여 AP 점수를 계산하는 calculate_average_precision 함수가 구현되었습니다. 이때, 과학 상식과 무관한 질문에 대한 AP 점수 처리 로직(검색 결과 유무에 따라 0점 또는 1점 부여)이 반영되었습니다.
MAP (Mean Average Precision): 전체 질문에 대한 AP 점수의 평균인 MAP 점수를 최종적으로 산출하여 모델의 전체적인 검색 성능을 종합적으로 평가할 수 있게 되었습니다.
다양한 형식의 결과 보고서 생성:
eval.jsonl에 있는 각 질문에 대한 RAG 모델의 응답(eval_id, standalone_query, topk, answer)을 JSONL 형식으로 sample_submission_pro.csv 파일에 저장하는 기능이 구현되었습니다. 이는 제출 형식에 맞춰 결과를 생성합니다.
AP 점수 및 RAG 응답 세부 정보를 포함하는 포괄적인 평가 보고서가 Excel (.xlsx) 및 CSV (.csv) 형식으로 생성됩니다.
AP 점수 분포 시각화:
Matplotlib과 Seaborn 라이브러리를 활용하여 계산된 AP 점수의 분포를 히스토그램과 박스 플롯으로 시각화한 .png 이미지 파일이 생성됩니다. 이는 모델 성능의 특징을 시각적으로 쉽게 파악할 수 있게 해줍니다.
이전 UserWarning 문제를 해결하기 위해 Matplotlib에서 한글 폰트(NanumGothic 우선)를 올바르게 로드하도록 설정하는 로직이 추가되어, 그래프에서 한글 텍스트가 깨지지 않고 표시되도록 개선되었습니다.
하이브리드 검색 (Sparse + Dense) 도입 및 RRF (Reciprocal Rank Fusion) 적용
개선 전 (초기 코드): sparse_retrieve_wrapper를 통해 BM25 기반 키워드 검색만 사용.
개선 후 (코드 업그레이드):
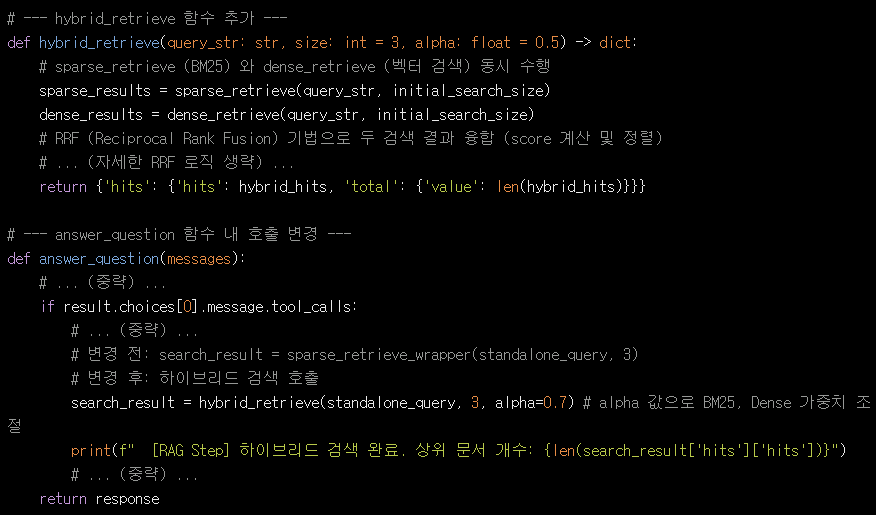
개선 효과: BM25의 키워드 매칭 능력과 임베딩 기반의 의미론적 유사도 검색 능력을 결합하고 RRF로 효과적으로 융합함으로써, 질문과 가장 관련성 높은 문서를 찾아내는 능력이 극적으로 향상되었습니다.

프롬프트 엔지니어링 다양하게 하지못해서 아쉬웠다.
팀 협업 노션으로 진행과 줌회의 했습니다.

대회회고
대회기간 API비용이 있어 여러 모델을 사용 못하고 Solar만 하다 보니 하이브리드 검색과 정교한 프롬프트를 못해서 저조한 성능이 나와 아쉽지만 앞으로 더 RAG 도전에 시발점이 되어서 좋았습니다.
