학습데이터 .csv형식
기차 : 12457
개발자: 499
테스트 : 250
숨겨진 테스트 : 249
평가데이터
인격에 평가에는 하나의 대화에서 다양한 인격으로 구성된 3개의 요약문으로 평가
baseline Code
BART 모델

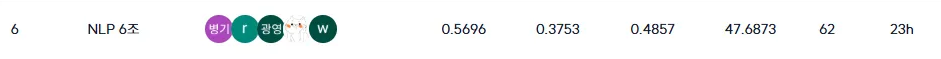
LLM 경진대회 회고: 도전, 학습, 그리고 성장
안녕하세요. 이번 LLM(거대 언어 모델) 경진대회에 참여하며 얻은 소중한 경험과 학습 내용을 공유하고자 합니다. 인공지능 분야에 대한 깊은 이해를 바탕으로 실질적인 문제를 해결하고, 기술적 역량을 확장할 수 있었던 의미 있는 시간이었습니다.
- 대화 요약 과제에 대한 깊은 이해와 데이터 전처리
이번 대회의 핵심은 '일상생활 시나리오의 Multi-turn 대화 요약'이었습니다. 구어체이지만 은어와 이모티콘이 적고, 개인 정보가 마스킹 처리된 형식적인 스타일의 대화 데이터를 다루는 것은 비정형 텍스트 데이터 처리의 중요성을 일깨워주었습니다.
잘한 점:
데이터 특성 분석: 초기에 대화 데이터의 길이, 구어체 특징, 주제 다양성 등을 면밀히 파악하여 모델링 방향을 설정하는 데 활용했습니다.
꼼꼼한 전처리: encoder_max_len, decoder_max_len과 같은 길이를 데이터 특성에 맞춰 조정하며, 데이터셋을 효율적으로 구성했습니다.
데이터 증강 시도: 한정된 학습 데이터의 한계를 극복하기 위해 역번역(Back-translation) 기반의 BART 증강과 EDA(Easy Data Augmentation) 기법을 시도하여 모델의 일반화 성능 향상을 꾀했습니다. 증강된 데이터를 기존 학습 데이터에 통합하는 과정에서 데이터 파이프라인의 유연성을 확보할 수 있었습니다.
아쉬웠던 점:
한국어 증강 기법의 한계: WordNet 기반의 동의어 대체와 같은 EDA 기법이 영어에 비해 한국어 데이터에는 제한적으로 적용될 수밖에 없었습니다. 한국어 특성을 더욱 깊이 반영한 증강 기법(예: 형태소 기반 증강, 한국어 동의어 사전 활용)에 대한 추가적인 연구와 적용이 필요하다고 느꼈습니다.
증강 데이터의 품질 검증: 증강된 데이터의 양적 증가만큼 질적 측면(의미 보존, 문법성)에 대한 심층적인 분석 및 필터링 과정이 부족했습니다. 무분별한 증강이 오히려 모델 성능에 부정적인 영향을 줄 수도 있음을 인지하게 되었습니다.
2. 모델 탐색 및 적용 과정의 시행착오와 학습
이번 대회를 통해 다양한 LLM 아키텍처를 경험하고, 실제 문제에 적용하며 각 모델의 특징을 체감할 수 있었습니다.
BART & T5 (인코더-디코더 모델) 활용:
잘한 점: 베이스라인 코드를 시작점으로 BART(hyunwoongko/kobart)와 T5(t5-base) 모델을 적용하며 인코더-디코더 구조의 시퀀스-투-시퀀스 모델이 요약 과제에 얼마나 강력한지 직접 확인할 수 있었습니다. 특히 T5 모델에 필요한 summarize: 프롬프트 추가 방식과 Seq2SeqTrainer의 활용법을 완벽히 이해하게 되었습니다. config.yaml 파일을 통해 모델과 하이퍼파라미터를 유연하게 관리하며 효율적인 실험 환경을 구축한 점도 긍정적이었습니다.
아쉬웠던 점: 초기 transformers 라이브러리의 버전 차이로 인한 ImportError (AdamW, load_metric), TypeError (evaluation_strategy), ValueError (save/eval strategy 불일치) 등 잦은 오류와 씨름하며 많은 시간을 할애했습니다. 이러한 오류 해결 과정은 라이브러리의 깊은 이해를 돕기는 했으나, 실험 속도를 늦추는 주요인이었습니다. 안정적인 환경 구축의 중요성을 다시 한번 느꼈습니다.
Unsloth와 Decoder-Only 모델 (Qwen) 탐색:
잘한 점: 기존 인코더-디코더 모델의 잠재적 성능 한계를 고려하여 Qwen과 같은 디코더-온리 모델 및 Unsloth 라이브러리 탐색을 시도했습니다. Unsloth가 QLoRA Fine-tuning에서 VRAM 효율성과 학습 속도 측면에서 얼마나 혁신적인지 직접 파악할 수 있었습니다. 이는 향후 대규모 LLM 활용 시 매우 유용한 경험이 될 것입니다.
아쉬웠던 점: Unsloth와 디코더-온리 모델 적용은 단순한 model_name 변경을 넘어 데이터 전처리 방식, 학습 Trainer 클래스 등 코드 구조의 근본적인 변경을 요구했습니다. 시간 제약으로 인해 이 부분에 깊이 있는 성능 최적화 실험까지는 도달하지 못한 점이 아쉽습니다. 다음번에는 충분한 시간을 갖고 디코더-온리 모델의 잠재력을 최대한 끌어올리는 실험을 해보고 싶습니다.
3. WandB (Weights & Biases)를 활용한 실험 관리
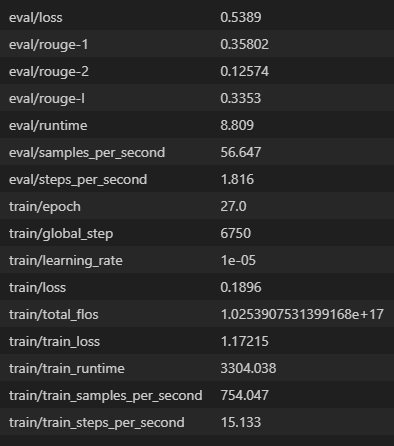
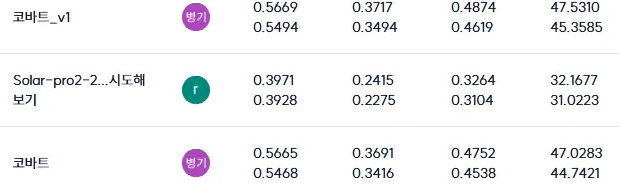
잘한 점: wandb를 적극적으로 활용하여 모든 실험의 진행 상황, 모델의 성능 지표(Loss, ROUGE Score), 하이퍼파라미터 변경 사항 등을 체계적으로 기록하고 시각화할 수 있었습니다. 수많은 실험 결과를 한눈에 비교하고 분석하며, 어떤 시도가 효과적이었는지 명확하게 판단할 수 있었던 점은 이번 대회의 성공적인 운영에 결정적인 역할을 했습니다. Early Stopping의 동작 방식과 최적 모델 저장 여부를 직관적으로 확인하는 데도 큰 도움이 되었습니다.
아쉬웠던 점: wandb의 모든 기능을 100% 활용하지는 못했습니다. 예를 들어, wandb에서 제공하는 고급 하이퍼파라미터 스윕(Sweep) 기능을 더 일찍 도입했더라면 다양한 파라미터 조합을 더욱 효율적으로 탐색하고 최적의 설정을 찾는 시간을 단축할 수 있었을 것입니다.
4. 대회 소감 및 앞으로의 다짐
이번 LLM 경진대회는 저에게 단순한 AI 모델 개발을 넘어선 깊이 있는 학습과 성장의 기회를 제공했습니다. 문제 해결을 위한 끊임없는 탐색, 예상치 못한 오류와의 씨름, 그리고 동료들과의 지식 공유는 값진 경험으로 남을 것입니다.
특히, 대규모 언어 모델의 빠르게 변화하는 생태계 속에서 새로운 기술(Unsloth, Qwen,Solar 등)을 이해하고 기존 프레임워크에 통합하려는 도전은 기술적 유연성의 중요성을 깨닫게 했습니다. 비록 모든 목표를 달성하지는 못했지만, 목표를 향해 나아가는 과정 자체가 큰 배움이었습니다.
앞으로는 한국어 LLM의 특성을 더욱 심층적으로 연구하고, 데이터 증강 및 모델 최적화 기법에 대한 실질적인 숙련도를 높여나가고자 합니다. 또한, 이번 대회를 통해 얻은 인사이트를 바탕으로 실제 비즈니스 문제 해결에 LLM을 효과적으로 적용할 수 있는 전문가로 성장할 것을 다짐합니다.
도전은 계속될 것입니다. 다음 대회에서는 더욱 정교한 모델과 효율적인 실험 관리로 더 나은 성과를 보여드릴 수 있도록 노력하겠습니다.
