1. Object Detection Overview
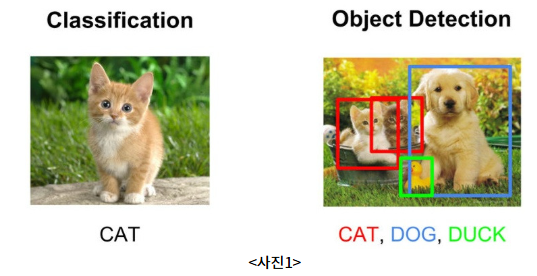
컴퓨터 비전의 하위 분야 중 하나인 객체 감지(Object Detection)는 이미지 및 비디오 내에서 유의미한 특징 객체를 감지하는 작업을 합니다. 객체 감지에는 얼굴 인식(Face Detection), Video Tracking(비디오 추적), 사람 수 세기(People Counting) 등 다양한 분야의 문제를 해결하기 위해서 사용됩니다. 최근 자율 주행 자동차나 의료 데이터에 사용합니다.
https://89douner.tistory.com/75
Object Detection 사용되는 예시

https://www.youtube.com/watch?v=YtSECdCxgNI


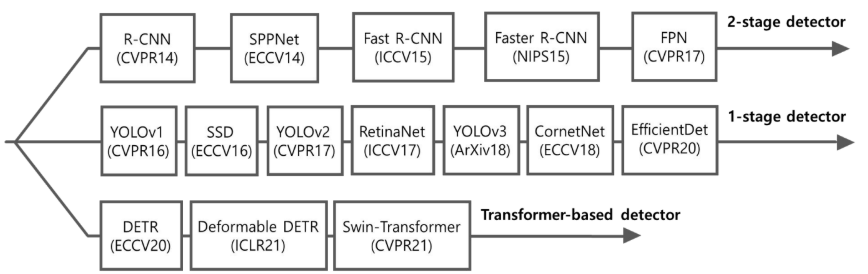
Object Detection의 발전 흐름
2. 2-stage Detector
Region Proposal + Classification 두 단계로 구성된 detector
● R-CNN, SPPNet, Fast R-CNN, Faster R-CNN,

[주요 특징]
높은 정확도: 두 단계에 걸쳐 정밀하게 객체를 탐지하므로, 단일 단계 검출기(1-stage Detector)에 비해 일반적으로 더 높은 검출 정확도를 제공합니다. 특히 작은 객체나 복잡한 배경에서 강점을 보입니다.
상대적으로 느린 속도: 두 단계를 순차적으로 거치기 때문에 단일 단계 검출기에 비해 처리 속도가 느린 경향이 있습니다.
실시간 처리가 중요한 애플리케이션에는 적합하지 않을 수 있습니다.
https://medium.com/data-science/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
https://wsshin.tistory.com/9
1-Stage Detector
구조가 단순하고 속도가 매우 빠른 end-to-end detector
YOLO, SSD, RetinaNet, CenterNet,
https://www.youtube.com/watch?v=9s_FpMpdYW8
3. Neck
객체 검출 모델에서 "Neck(넥)"은 백본(Backbone) 네트워크와 헤드(Head) 네트워크 사이에 위치하여, 백본에서 추출된 다양한 스케일의 특징 맵(Feature Map)들을 효과적으로 통합하고 보강하는 역할을 하는 구성 요소를 의미합니다.
Neck의 역할 및 필요성
객체 검출 모델은 일반적으로 다음과 같은 세 가지 주요 부분으로 구성됩니다.
백본(Backbone): 입력 이미지에서 특징(Feature)을 추출하는 역할을 합니다. 주로 ResNet, VGG, Darknet 등과 같은 이미지 분류용 CNN 모델이 사용됩니다. 백본은 이미지의 저수준 특징(엣지, 코너 등)부터 고수준 특징(객체의 형태 등)까지 다양한 스케일의 특징 맵을 생성합니다.
넥(Neck): 백본에서 나온 다양한 스케일의 특징 맵들을 서로 연결하고 융합하여, 객체 검출에 필요한 더욱 풍부하고 강건한 특징 맵을 생성합니다.
헤드(Head): 넥에서 보강된 특징 맵을 바탕으로 실제 객체의 위치(바운딩 박스)와 클래스(범주)를 예측합니다. 1단계 검출기에서는 단일 헤드가 이 역할을 수행하고, 2단계 검출기에서는 분류 헤드와 회귀 헤드가 분리되어 사용될 수 있습니다.
Neck이 필요한 주된 이유는 다음과 같습니다.
다양한 스케일의 객체 검출: 백본은 깊이가 깊어질수록 고수준의 의미론적 정보를 담지만 해상도가 낮아지고, 얕은 레이어는 해상도는 높지만 저수준의 특징만 담습니다. 작은 객체를 검출하려면 고해상도의 특징이 필요하고, 큰 객체는 고수준의 의미론적 특징이 중요합니다. Neck은 이러한 다양한 스케일의 특징 맵들을 효과적으로 융합하여, 모델이 다양한 크기의 객체를 더 잘 검출할 수 있도록 돕습니다.
정보 손실 최소화: 백본 네트워크를 거치면서 이미지의 공간 정보가 손실될 수 있는데, Neck은 이러한 정보 손실을 최소화하고 보완하는 역할을 합니다.
특징 재활용 및 강화: 다양한 레벨의 특징 맵을 상호 보완적으로 활용하여, 객체 검출 성능을 향상시킵니다.
4. Transformer-based Detector
트랜스포머 기반 검출기(Transformer-based Detector)는 객체 검출 분야에서 최근 주목받고 있는 새로운 패러다임의 모델입니다. 기존의 객체 검출 모델들이 주로 CNN(Convolutional Neural Network)을 기반으로 하던 것과 달리, 자연어 처리 분야에서 큰 성공을 거둔 트랜스포머(Transformer) 아키텍처를 객체 검출에 적용한 것이 특징입니다.
트랜스포머 기반 검출기의 개념 및 작동 방식
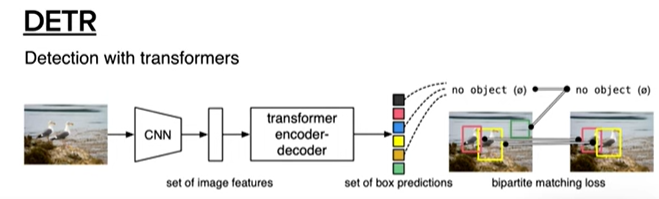
트랜스포머 기반 검출기의 등장은 DEtection TRansformer, 즉 DETR 모델이 2020년에 발표되면서 시작되었습니다.
엔드-투-엔드(End-to-End) 학습: DETR은 객체 검출을 '집합 예측 문제(set prediction problem)'로 재구성하여, 이미지에서 직접 객체들의 집합을 예측하는 엔드-투-엔드 방식을 제안했습니다. 이는 기존 객체 검출 모델에서 필수적이었던 NMS(Non-Maximum Suppression)나 앵커 박스(Anchor Box)와 같은 수동 설계 요소들을 제거하여 모델 설계를 크게 간소화했습니다.
- 트랜스포머 인코더-디코더 구조: DETR은 CNN 백본을 통해 이미지 특징을 추출한 후, 이 특징을 트랜스포머 인코더에 입력합니다. 인코더는 이미지 내의 전역적인 관계를 학습하며, 이후 트랜스포머 디코더는 학습된 특징과 '객체 쿼리(Object Queries)'를 사용하여 최종적으로 객체의 클래스와 바운딩 박스를 예측합니다.