
이 글의 목적?
이전 글에서는 인덱스에 관련된 개념적인 내용을 살펴보았다. 하지만 실제로 인덱스를 적용하여 성능을 최적화하는 사례가 부족하다는 생각이 들어 10분 테크톡 - 매트, 토르의 MySQL 성능 최적화 영상으로 이해해보기로 했다.
인덱스를 이용한 성능 최적화란?
데이터베이스에서의 성능 최적화는 디스크 I/O를 줄이는 것이 핵심이다. 원하는 데이터를 찾기 위해서는 디스크에서 헤드가 플래터에 담긴 데이터를 가져올 때 물리적으로 움직이는데, 이 움직임 때문에 데이터의 입출력이 느려진다. (SSD가 많이 보편화되었다고 하더라도 여전히 느리다는 문제가 있다.)
일반적인 웹 서비스에서는 수정 및 삭제보다 데이터를 조회하는 비율이 더 많기 때문에 어느정도 손해를 보더라도 조회 성능을 높이는 것을 많이 선택한다.
인덱스를 이용하면 ORDER BY와 GROUP BY 절에서도 이점을 챙길 수 있다. 영상의 예를 그대로 가져와보자.
만약에 인덱스가 없을 경우라면 하단의 쿼리는 데이터를 모두 읽어와 데이터베이스에서 직접 정렬을 해야겠지만, 인덱스가 적용되어있다면 이미 정렬되어 있기 때문에 인덱스 순서대로 파일을 읽기만 하면 되어 성능적으로 이점을 챙길 수 있다.
SELECT *
FROM crew
WHERE nickname >= '매트' AND nickname =< '토르'
ORDER BY nickname;인덱스 실행 계획
실행 계획에는 여러가지가 있지만 영상에서는 가장 많이 나오는 3가지에 대해서 언급했다.
All
테이블 전체를 스캔할 때의 실행 계획이다. 다른 말로는 이전 글에서 정리한 Full Table Scan을 의미한다. 전체 데이터를 스캔하기 때문에 디스크 I/O 측면에서 본다면 성능상 좋지 않다는 것을 알 수 있다.
Full Table Scan이 일어나는 경우는 다음과 같다.
- 인덱스가 없을 경우
- 데이터 전체의 개수가 적을 경우
- 읽고자하는 데이터가 전체 데이터의 25% 이상일 경우
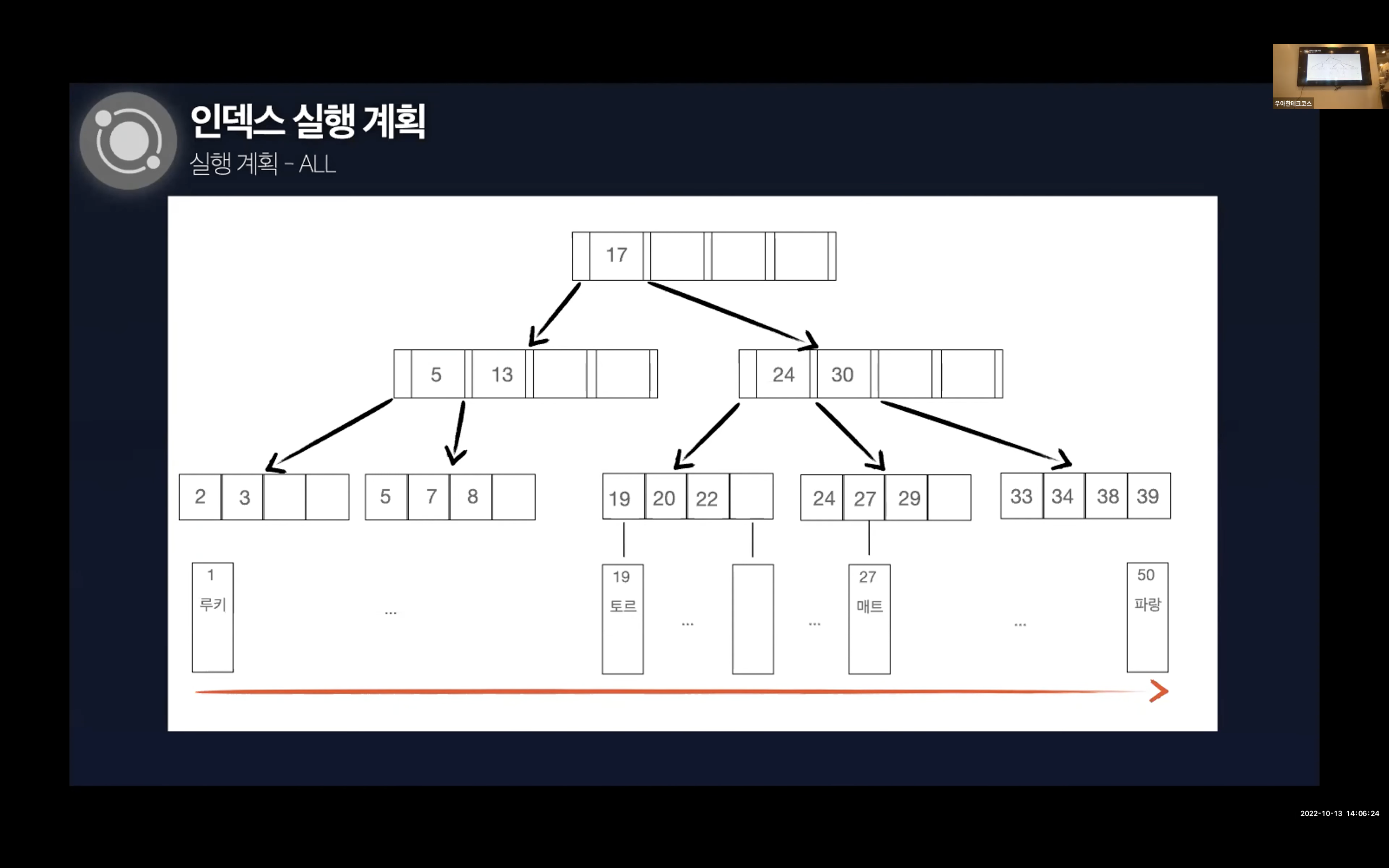
Range
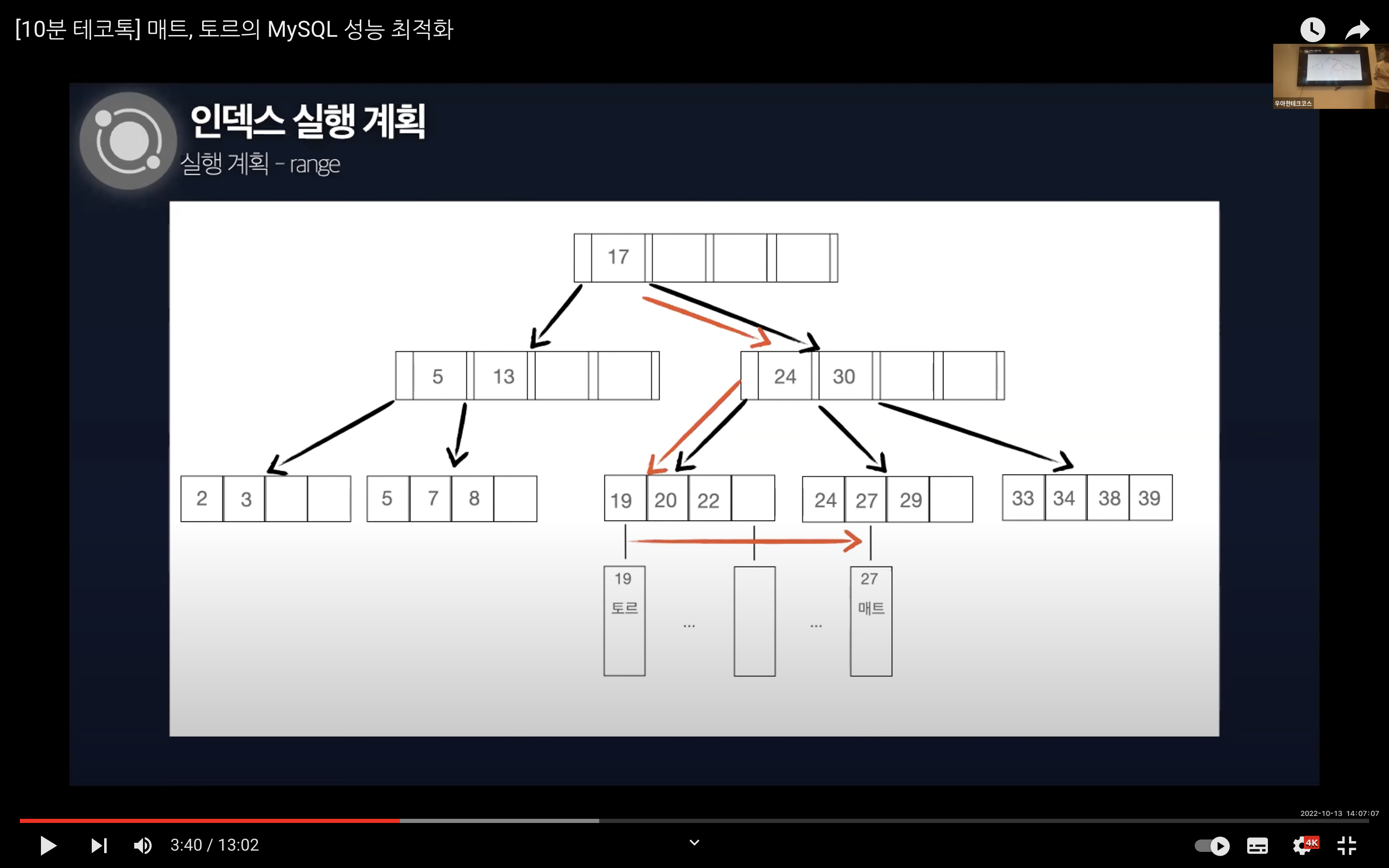
인덱스를 이용하여 범위 검색을 할 때의 실행 계획이다. 이상적으로 인덱스를 잘 설정해두었을 때 발생하는 계획이다. 필요한 부분만을 읽기 때문에 디스크 I/O를 줄일 수 있다.
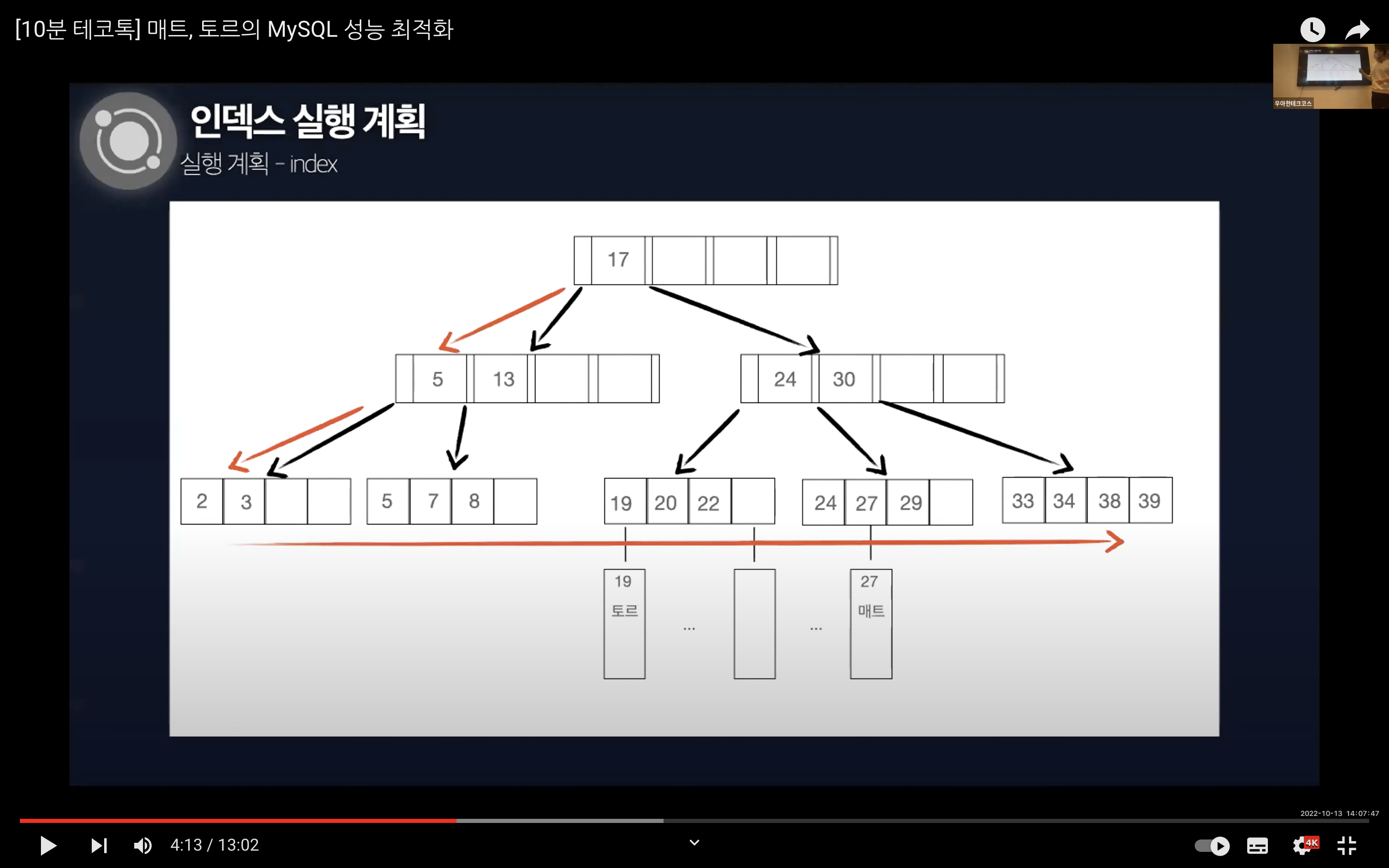
Index
인덱스 전체를 스캔할 때의 실행 계획이다. 다른 말로는 Index Full Scan이라고 한다. 인덱스는 데이터 파일보다 작기 때문에 Full Table Scan 보다는 성능이 좋지만 Range 스캔에 비해서 성능이 떨어진다.
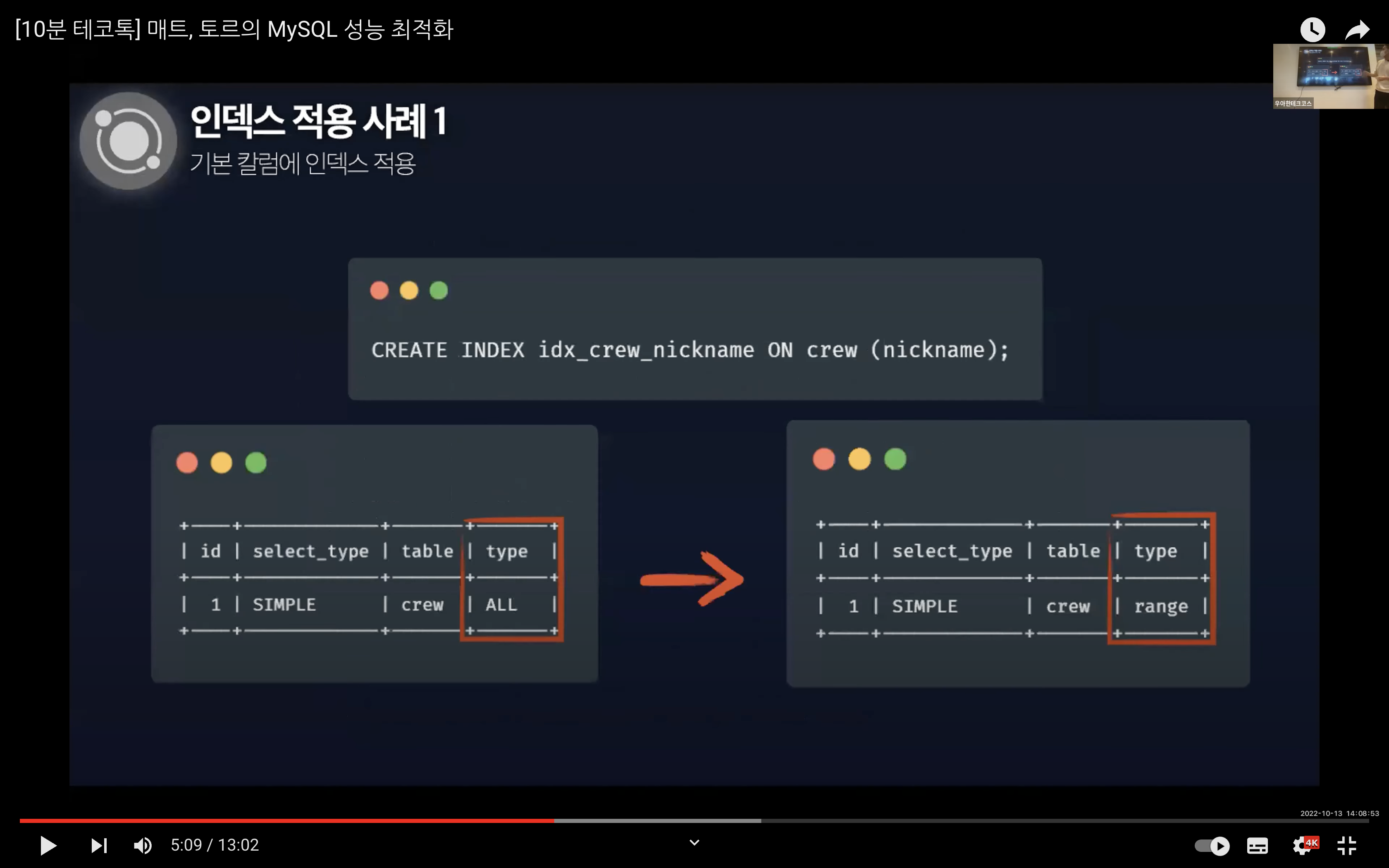
인덱스 적용 사례 1
영상의 첫 번째 사례에서는 하단의 이미지처럼 PK로 id 컬럼은 클러스터링 인덱스가 설정되어있고, nickname이 가장 조회가 많이 일어난다는 가정하에 진행했다. 추가적으로 여기서는 track 컬럼의 카디널리티가 낮기 때문에 nickname에 인덱스를 적용했다. 그 결과 성능이 확실히 좋아지는 결과를 도출해냈다.

인덱스 적용 사례 2
영상의 두 번째 사례에서는 복합 인덱스를 적용한 사례다.
복합 인덱스는 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것을 의미한다. 하나의 컬럼으로 인덱스를 만들었을 때보다 더 적은 데이터 분포를 보여 탐색할 데이터 수가 줄어든다. 복합 인덱스는 결합 인덱스, 다중 컬럼 인덱스, Composite Index라고도 불린다.
시작은 나이순과 nickname순으로 정렬되어있는 상태에서 진행된다.
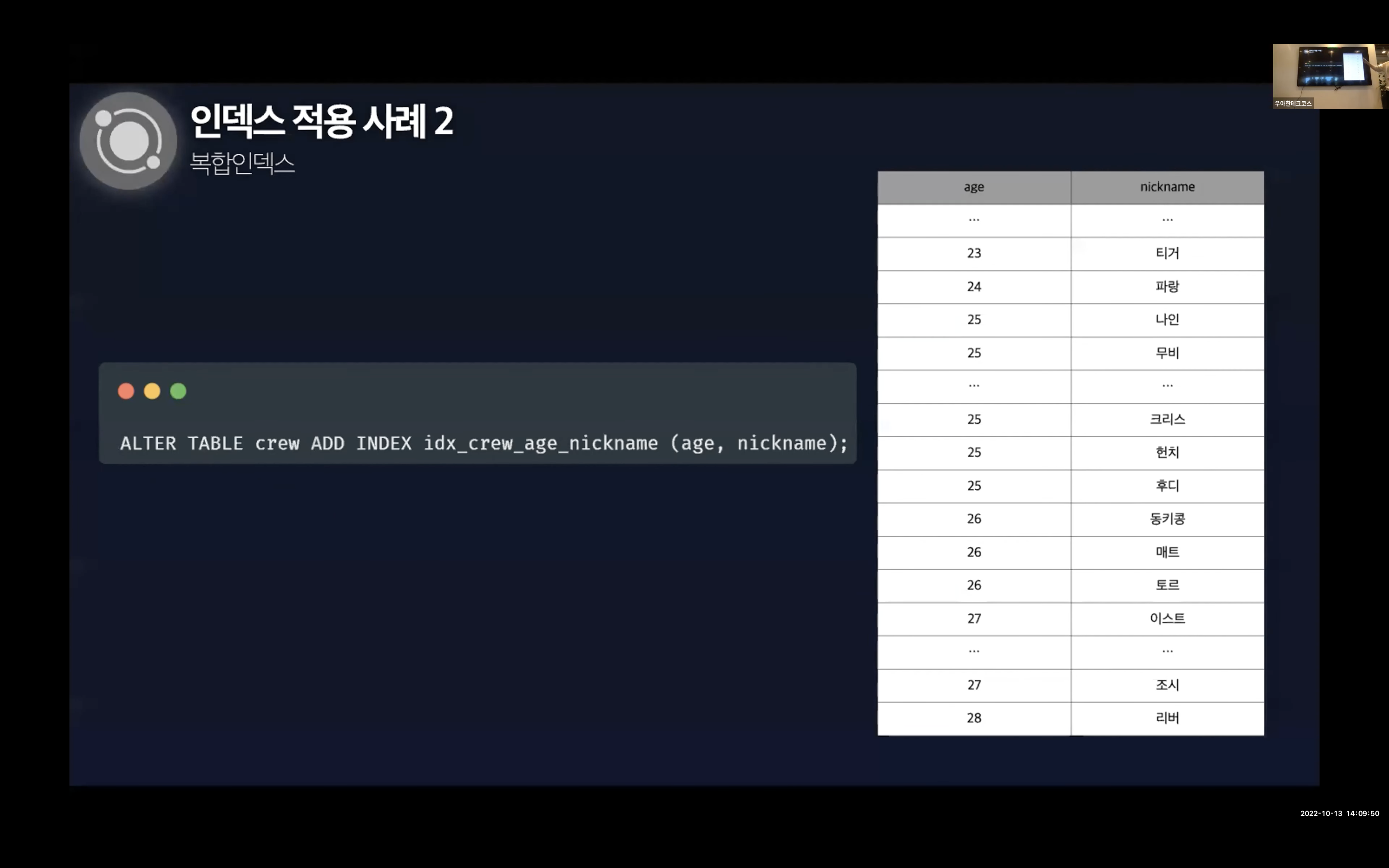
먼저 나이만을 조건으로 걸어둔 쿼리를 날렸을 경우에는 나이순으로 정렬되어있기 때문에 동키콩부터 데이터를 가지고 올 수 있어 탐색 범위가 줄어든다.
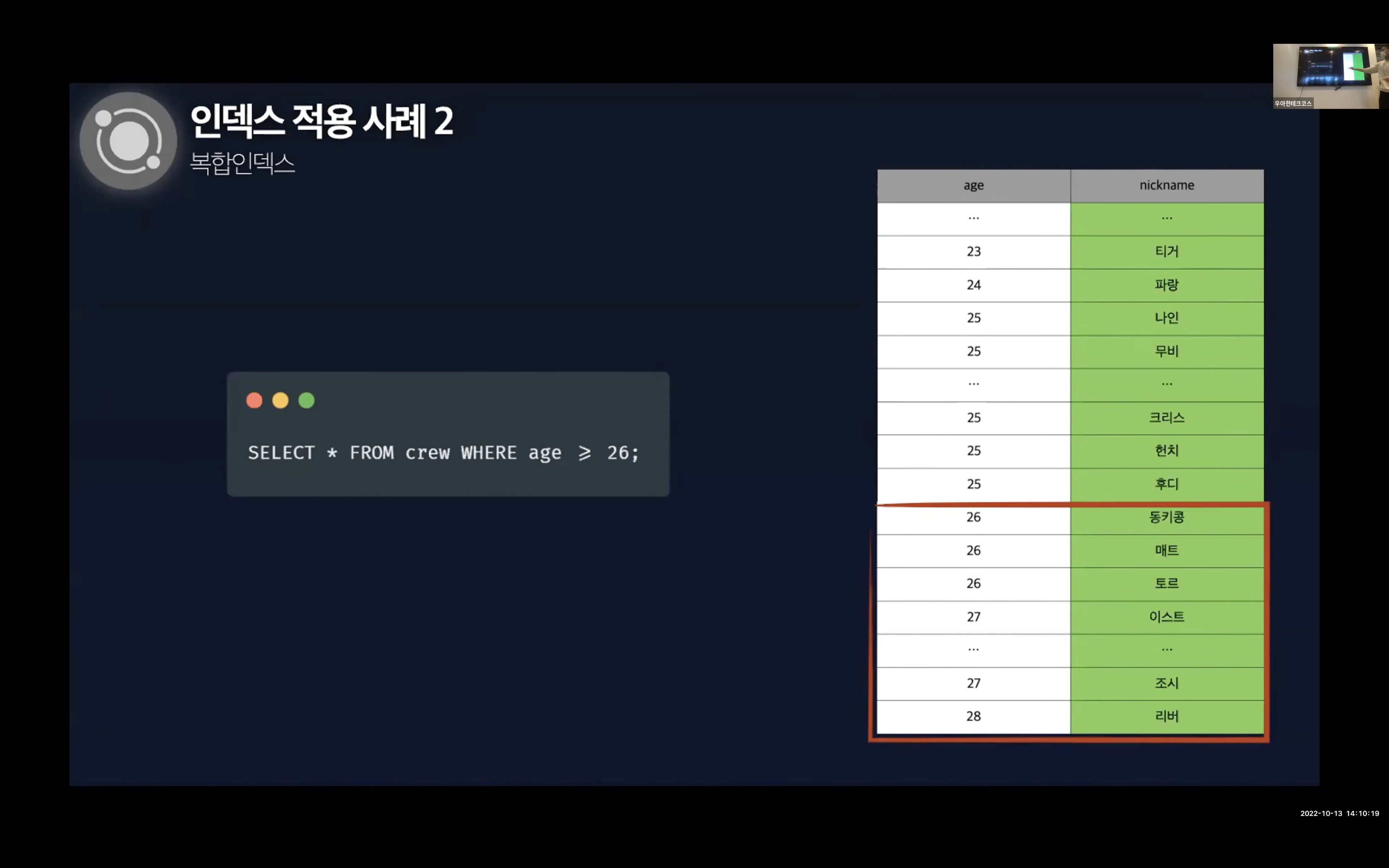
그 다음에는 나이와 nickname을 조건으로 걸어둔 쿼리를 날렸을 경우에는 나이순 그리고 nickname 순으로 정렬되어있어 토르부터 데이터를 가지고 오기 때문에 탐색 범위가 줄어드는 것을 알 수 있다.
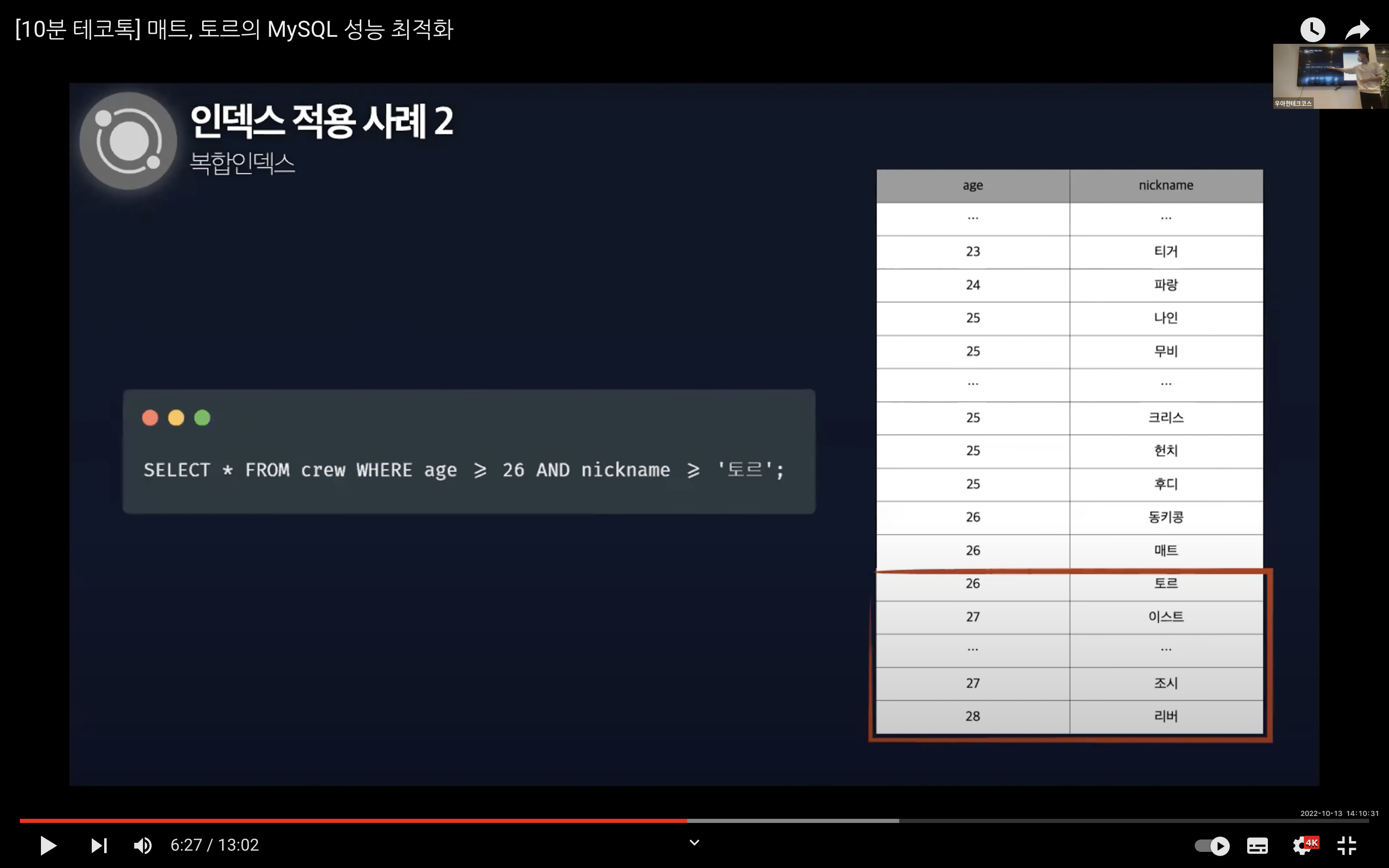
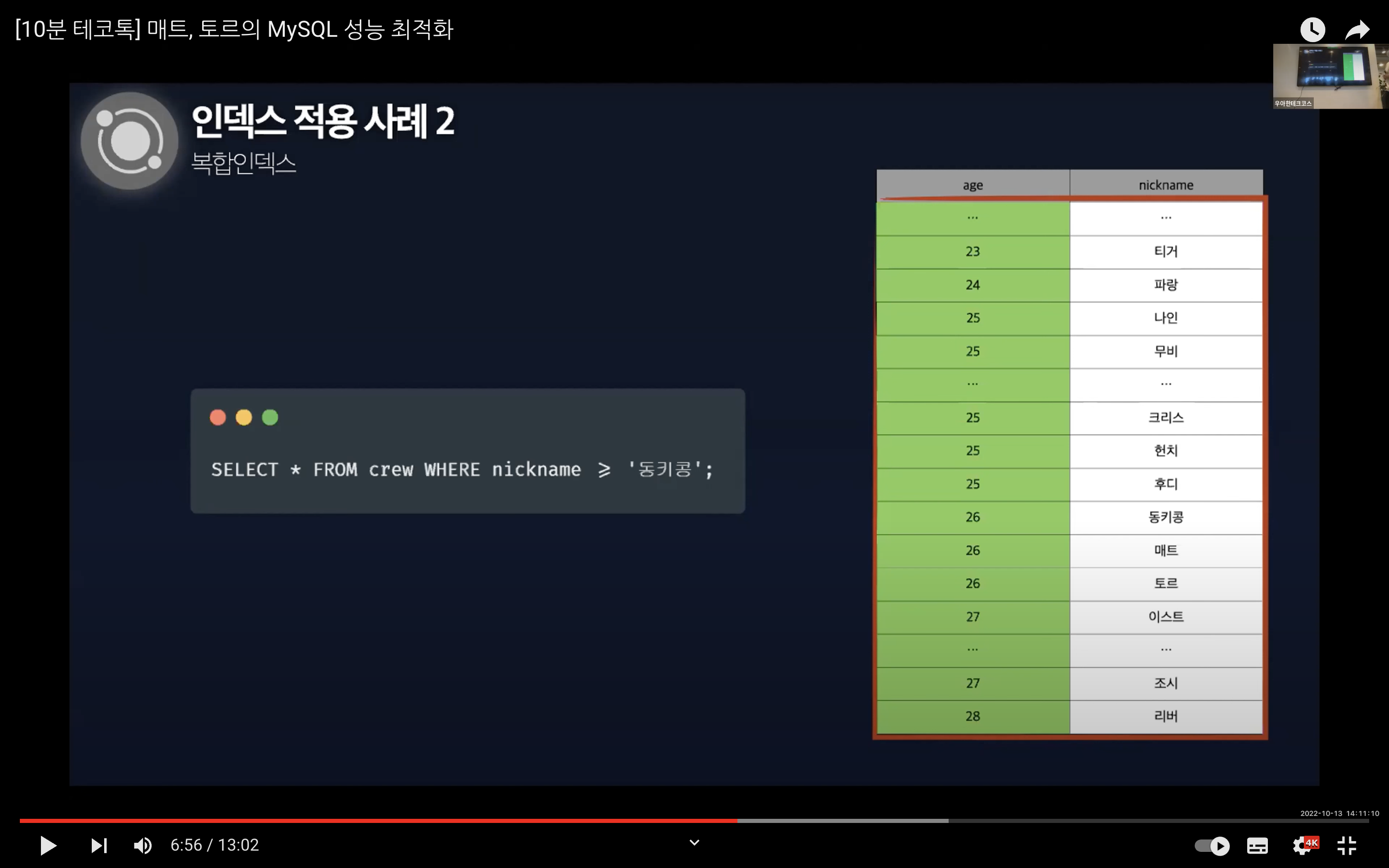
반대로 닉네임을 기준으로 탐색할 경우에는 동키콩보다 이후인 데이터를 가져오고자 했지만 티거, 파랑, 조시, 리버 등의 데이터를 가져오기 때문에 Full Table Scan이 발생한다. 즉, 디스크 I/O를 줄일 수 없게 된다.
인덱스 적용 사례 3
영상의 세 번째 사례에서는 커버링 인덱스를 적용한 사례다.
인덱스를 사용하여 처리하는 쿼리중 가장 큰 부하를 차지하는 부분은 인덱스 검색에서 일치하는 키 값의 레코드를 읽는 것이다. 하단의 이미지처럼 키값에 해당하는 데이터를 읽어올 때 디스크 I/O가 발생하는 것을 볼 수 있다. 최악의 경우에는 N개의 인덱스를 검색할 때 N번의 디스크 I/O가 발생할 수 있다.
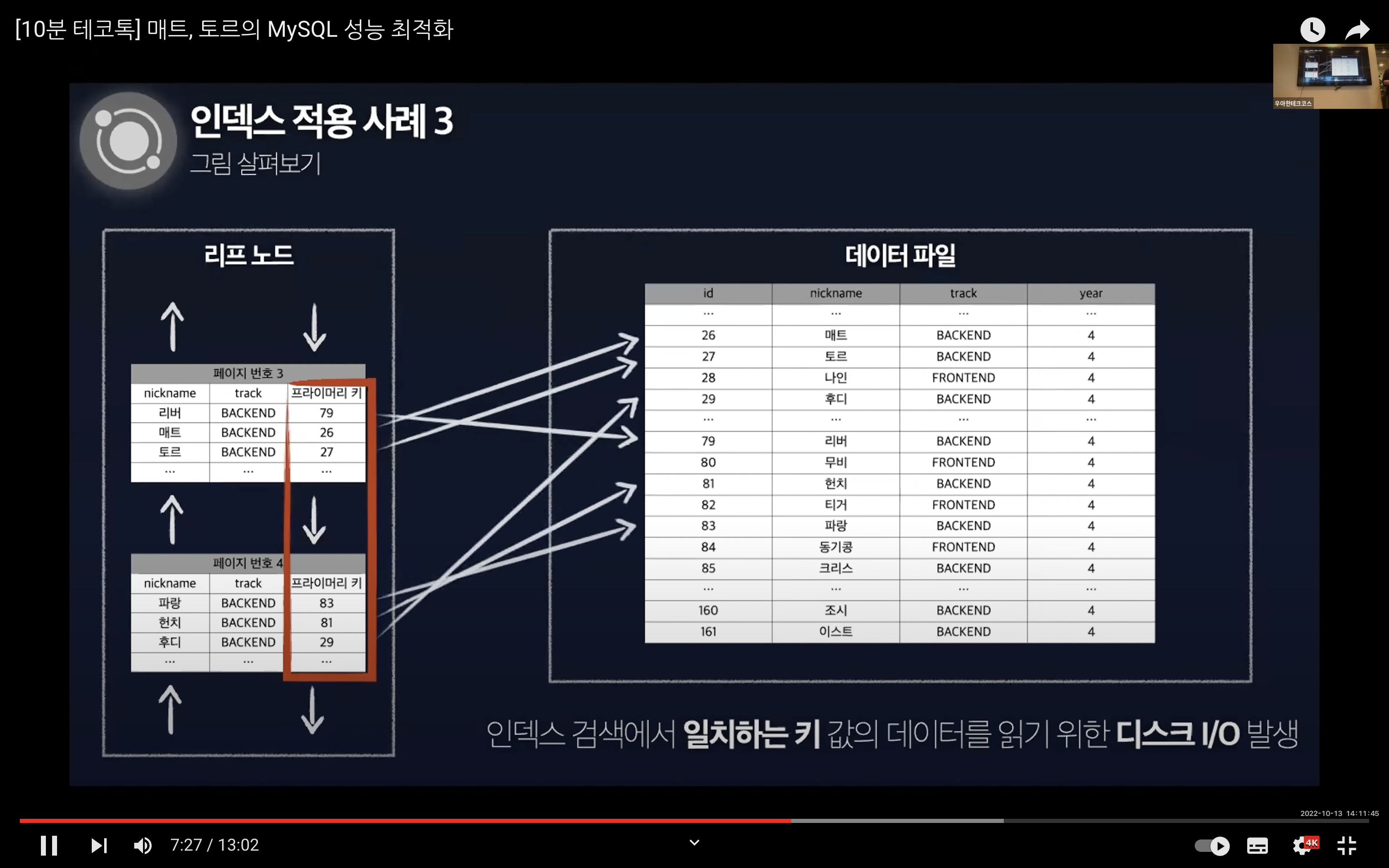
시작은 nickname과 track이 복합 인덱스로 설정되어있고 a와 d 사이의 nickname을 가진 백엔드 크루를 조회하는 것에서 진행된다.
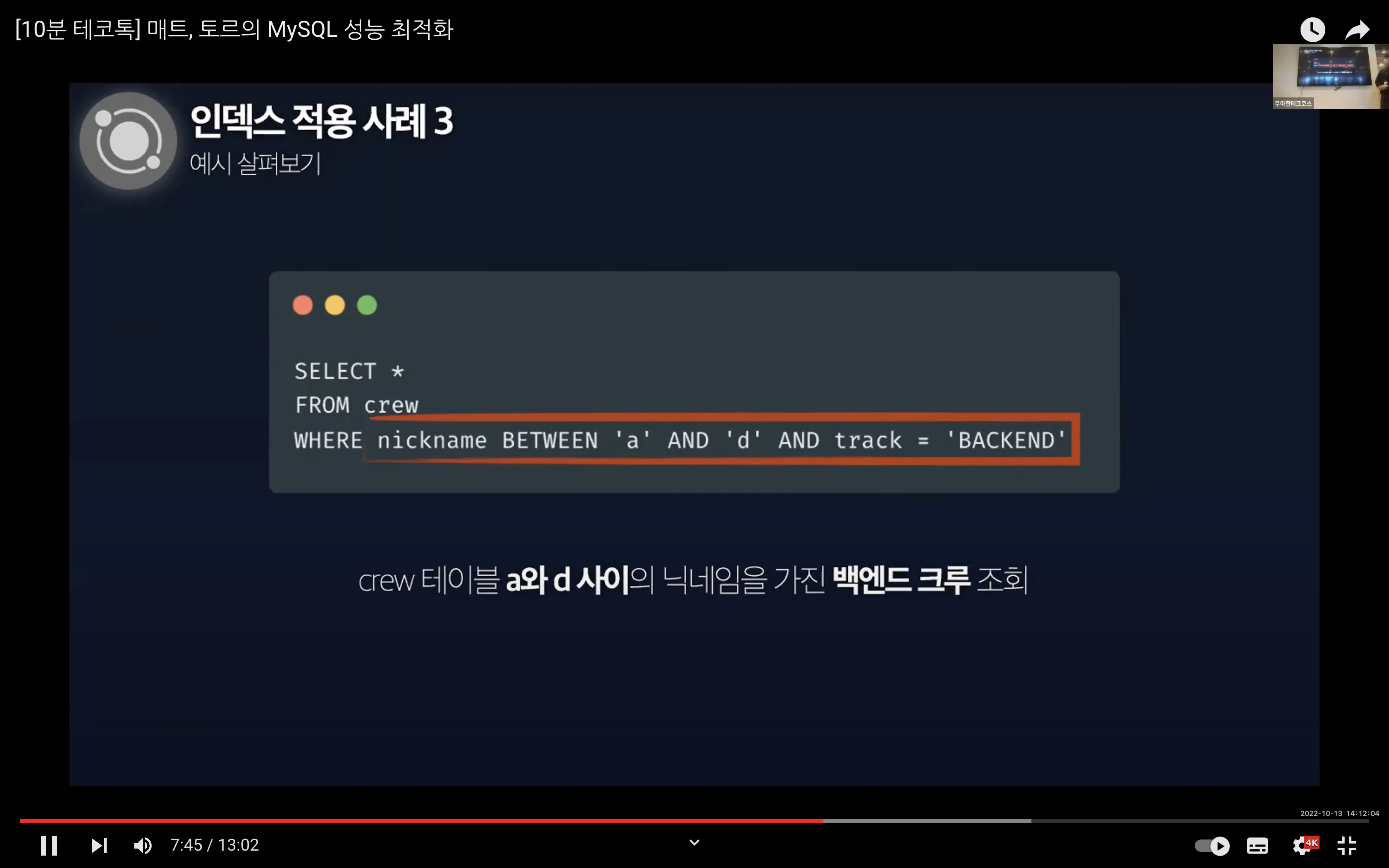
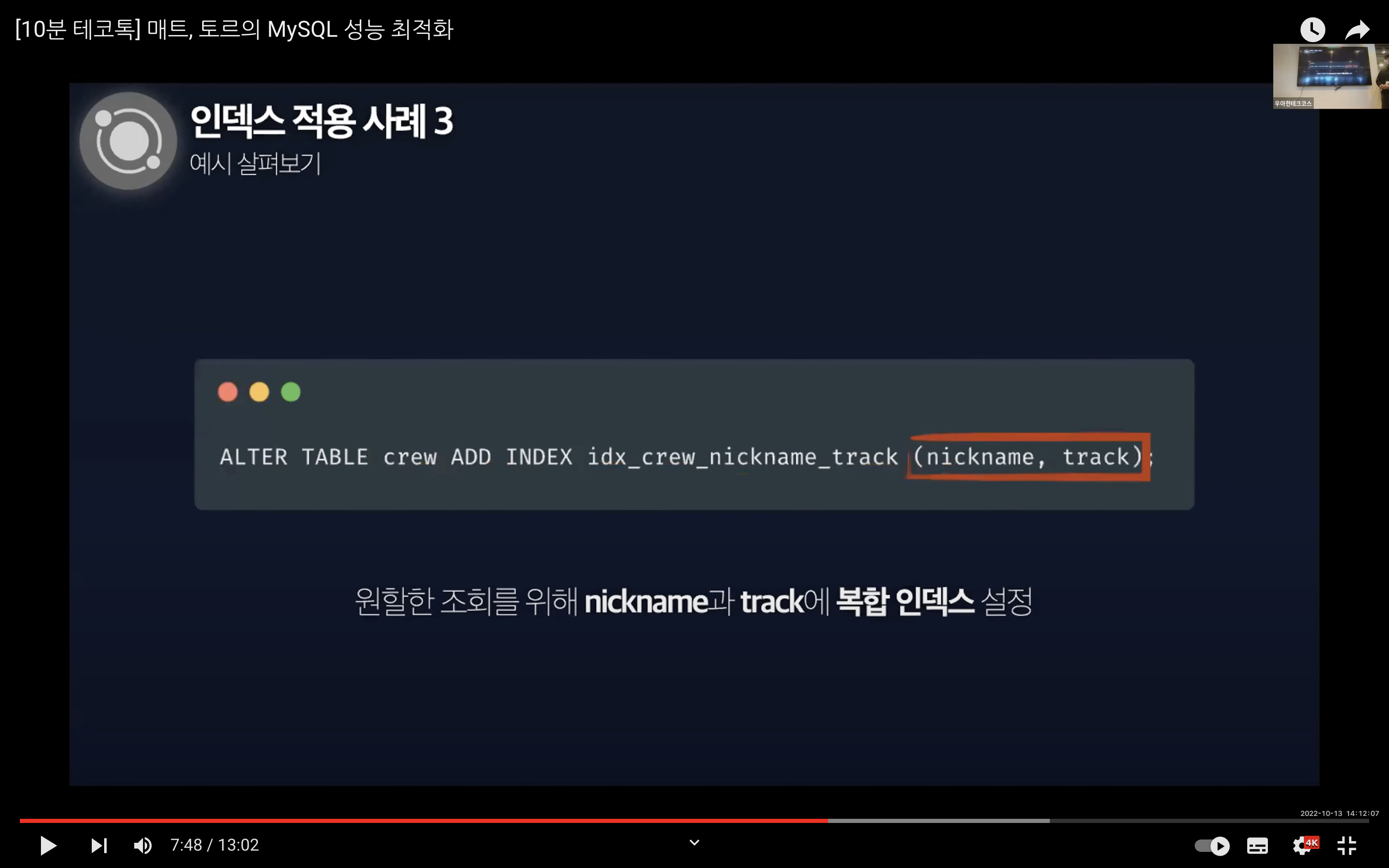
여기서 실행 계획을 살펴보면 Full Table Scan이 발생하는 하단과 같은 이미지가 결과가 나온다.
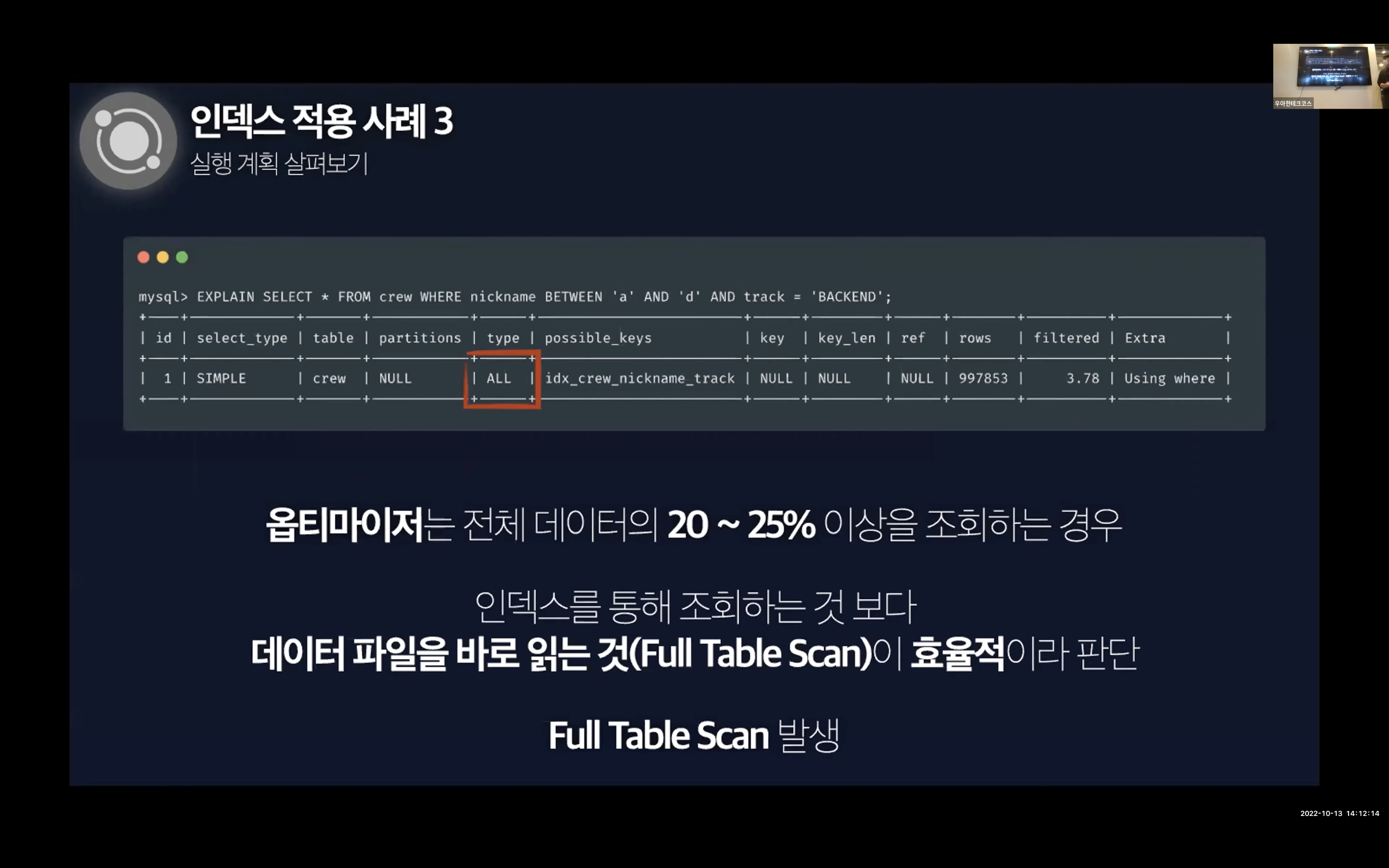
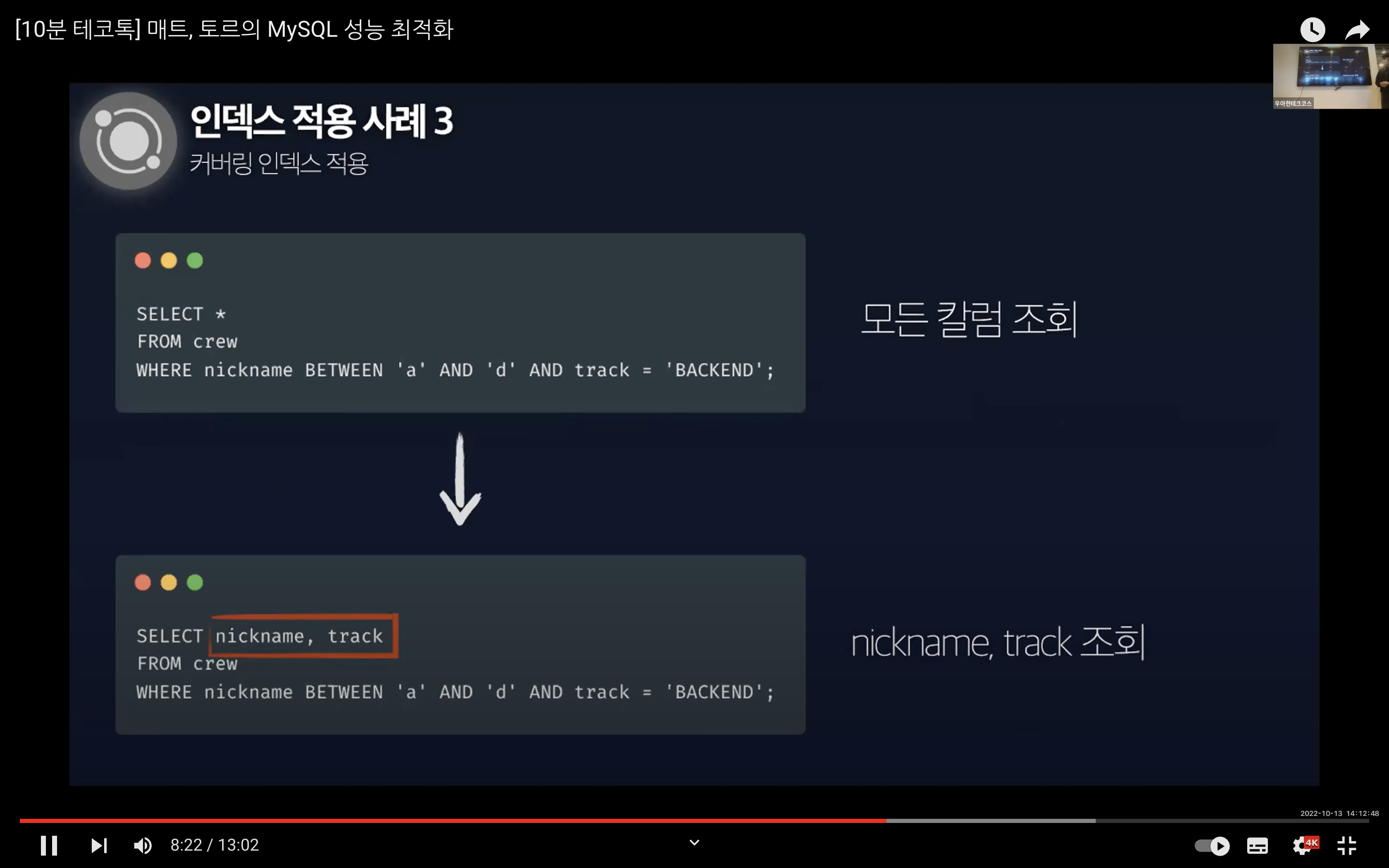
그리고 이 문제는 커버링 인덱스로 개선할 수 있다. 커버링 인덱스는 인덱스로 설정한 컬럼만 읽어 쿼리를 모두 처리할 수 있는 인덱스를 의미한다. 불필요한 디스크 I/O를 줄여 조회 시간을 단축시킨다.
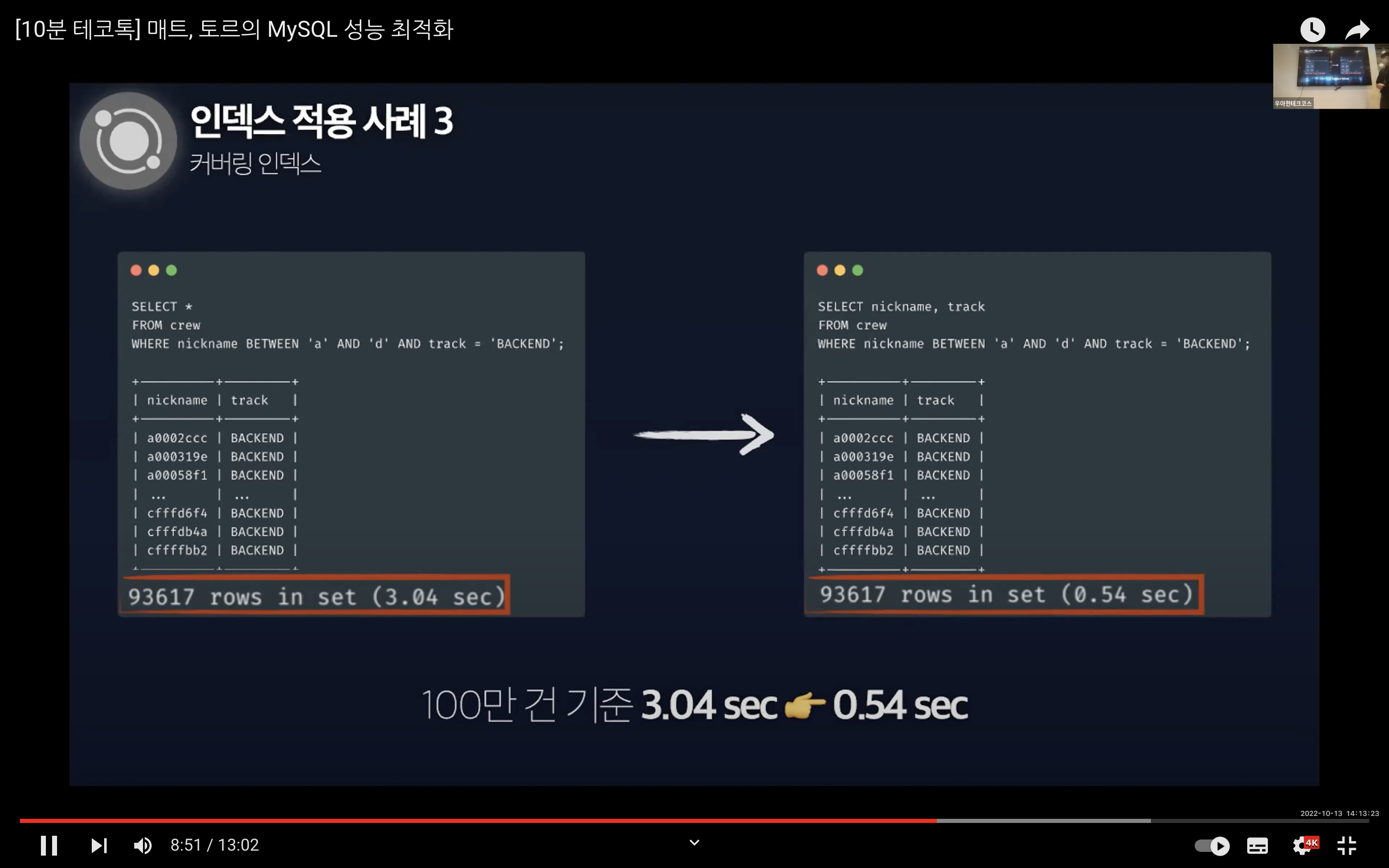
만약 위에서 적용한 쿼리를 인덱스로 설정한 nickname, track 컬럼만을 조회하는 쿼리로 변경하면 데이터 파일을 읽지 않고 인덱스만 읽기 때문에 시간을 단축시킬 수 있다.
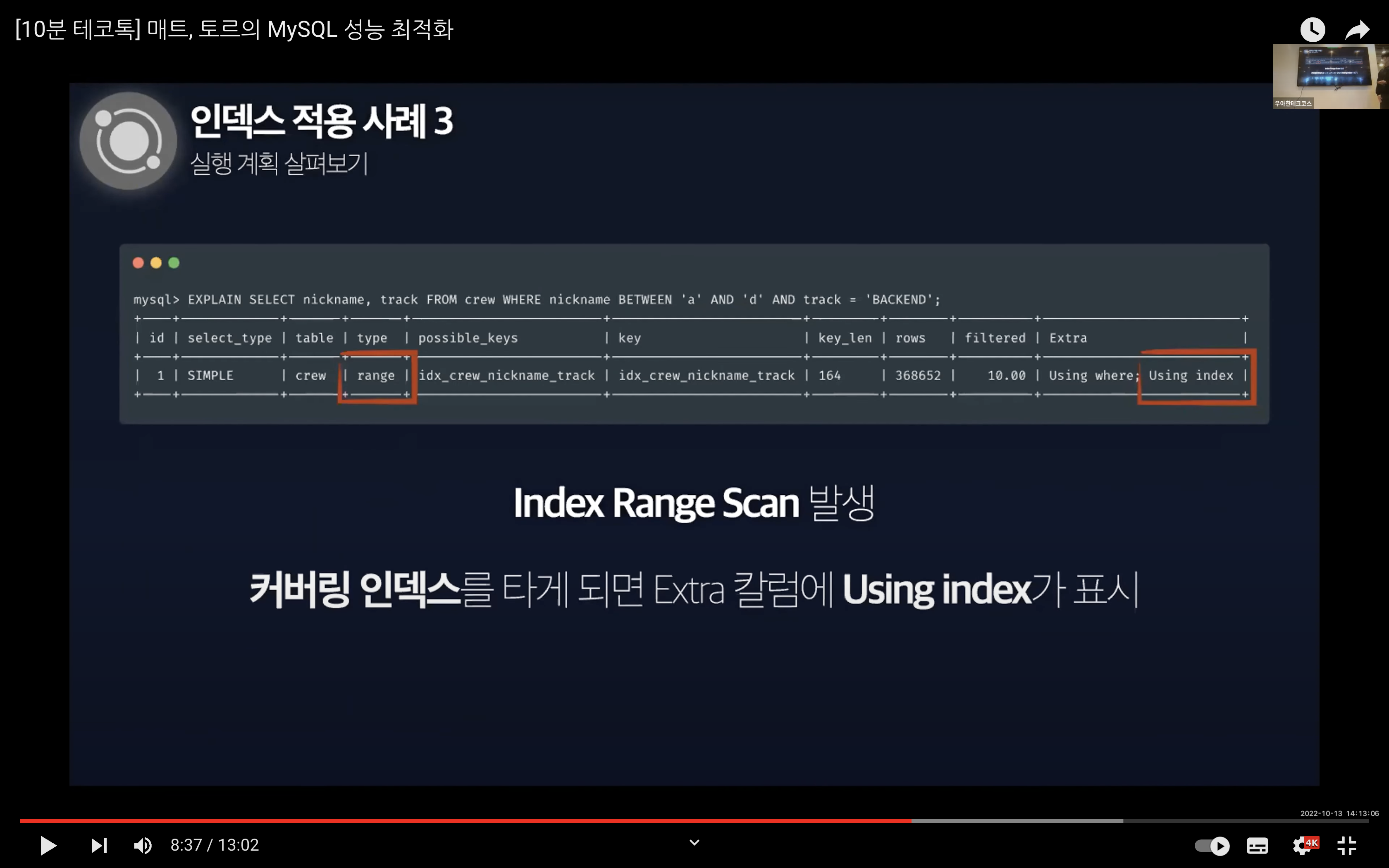
실행 계획을 살펴보면 Range 스캔이 일어나고 Extra 컬럼에 Using index가 표시되는 것을 확인할 수 있다.
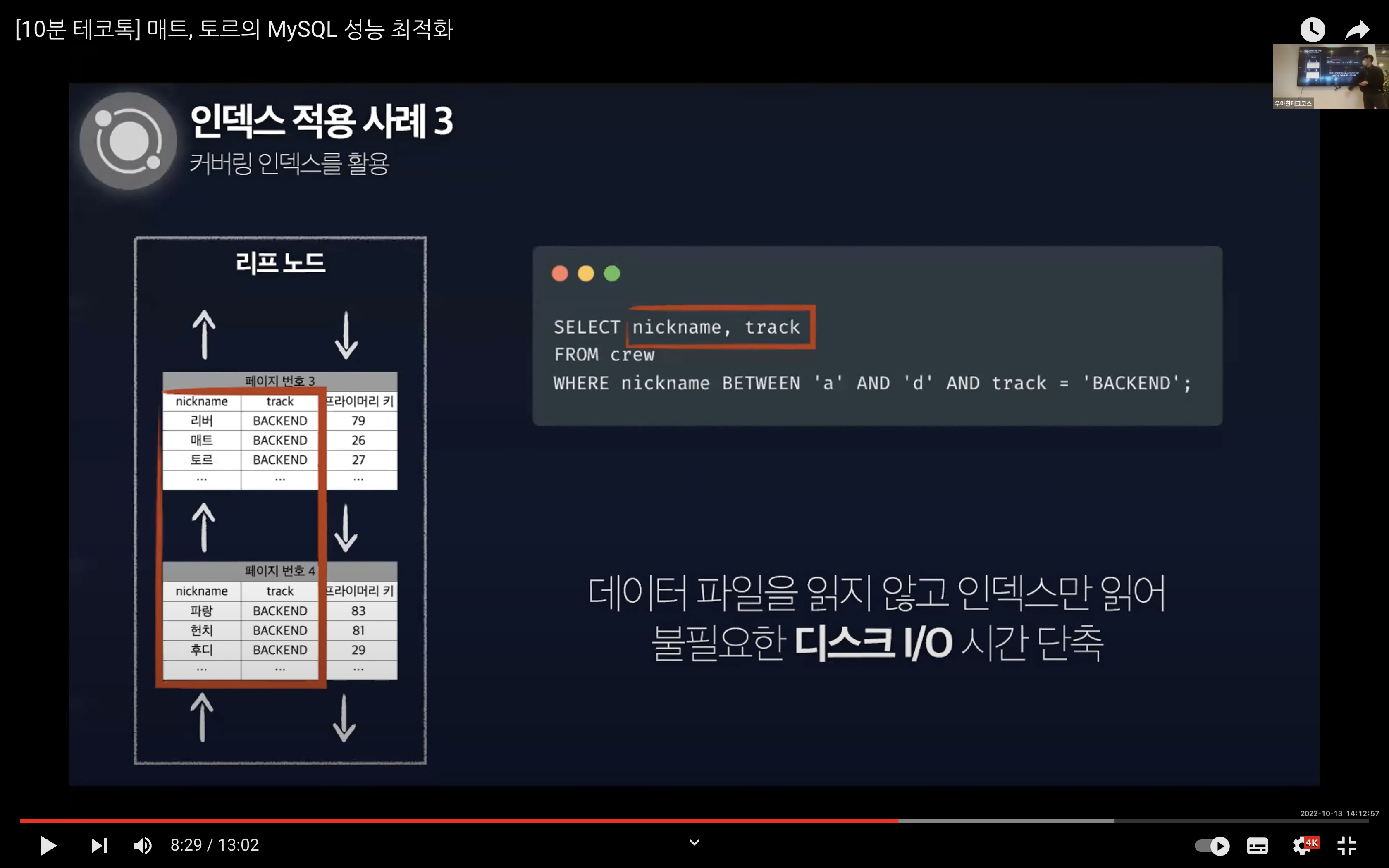
추가적으로 복합 인덱스로 설정하지 않은 PK 컬럼인 id도 같이 조회하면 같은 결과가 나온다. 그 이유는 InnoDB가 가진 세컨더리 인덱스의 특수한 구조 때문이다. 즉, 리프 노드에는 실제 레코드의 주소가 아닌 클러스터링 인덱스가 걸린 PK를 주소로 가지기 때문에 id, nickname, track 모두 활용이 가능한 것이다.
이전 글에서 클러스터링 인덱스에 대해서 정리했었는데, 그 때 실제 레코드 주소가 아닌 PK 값을 가지고 있다는 것을 기억해내면서 뭔가 퍼즐이 맞춰진것 같다! 🤭
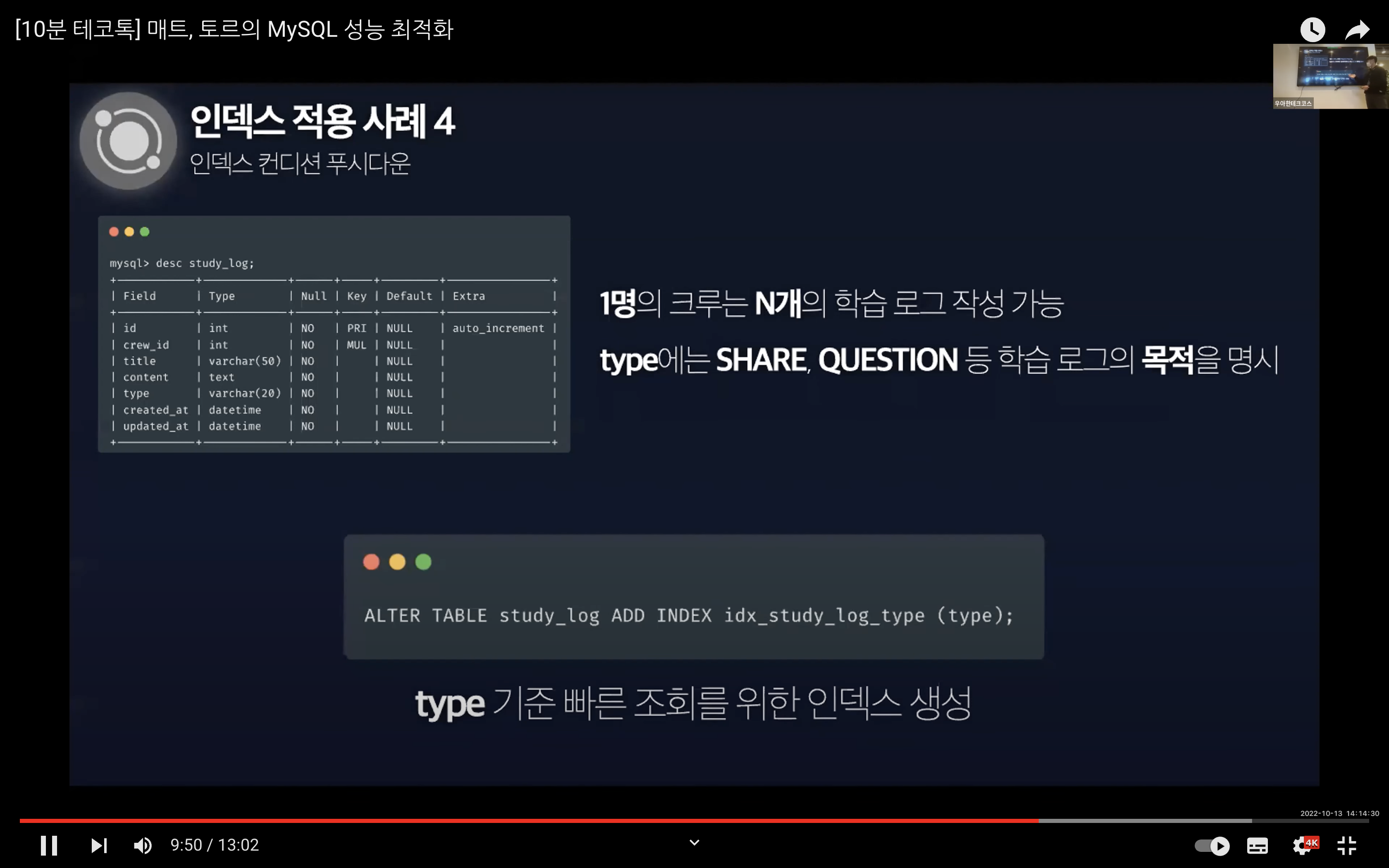
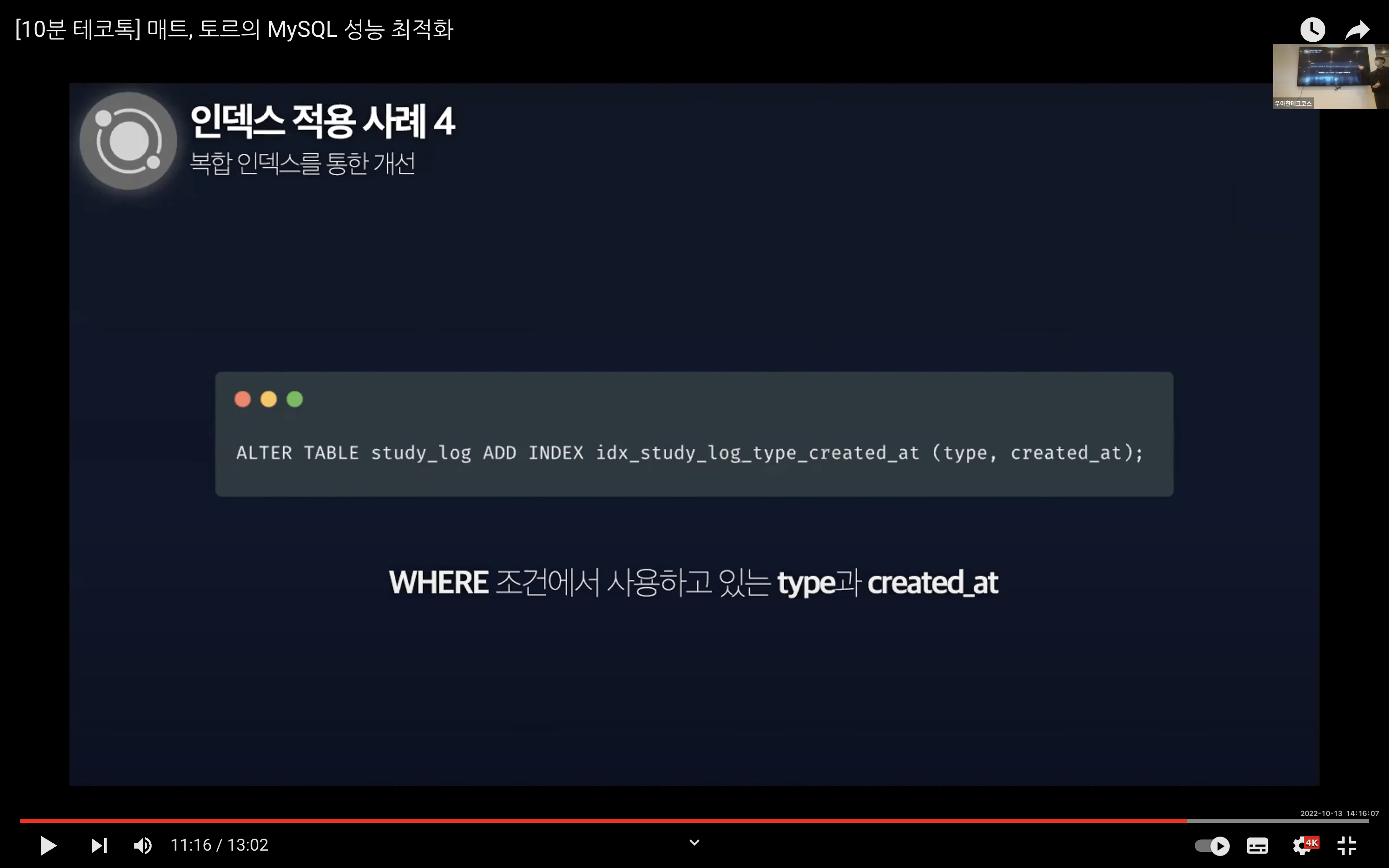
인덱스 적용 사례 4
영상의 네 번째 사례에서는 인덱스 컨디션 푸시 다운에 대한 사례다.
예시는 학습 로그의 목적을 의미하는 type 컬럼에 인덱스를 생성해서 시작된다.
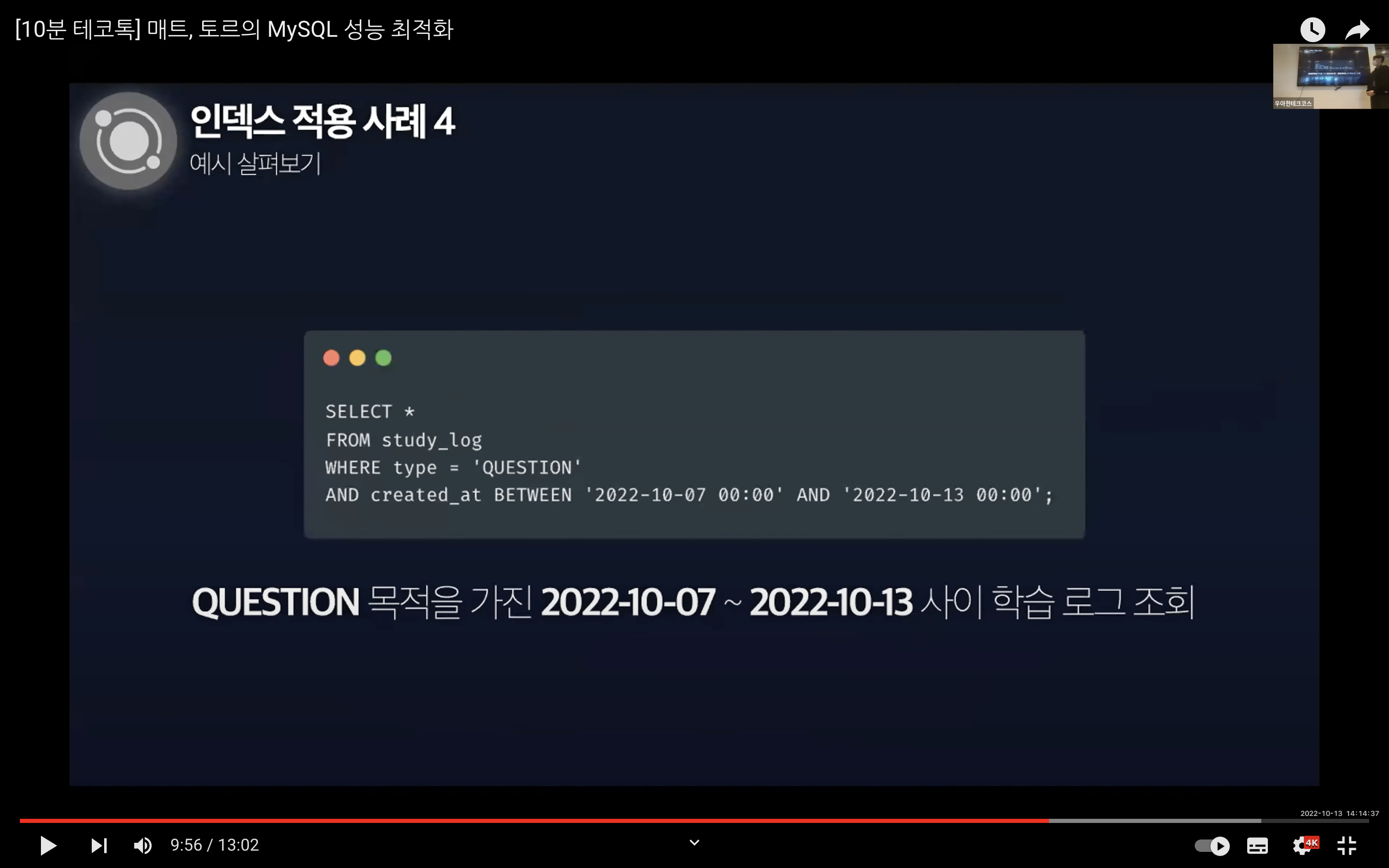
그리고 특정 기간 사이의 QUESTION 타입의 데이터를 조회한다고 했을 때의 실행 계획을 살펴보면 적용한 인덱스가 제대로 동작하는 것을 볼 수 있다.
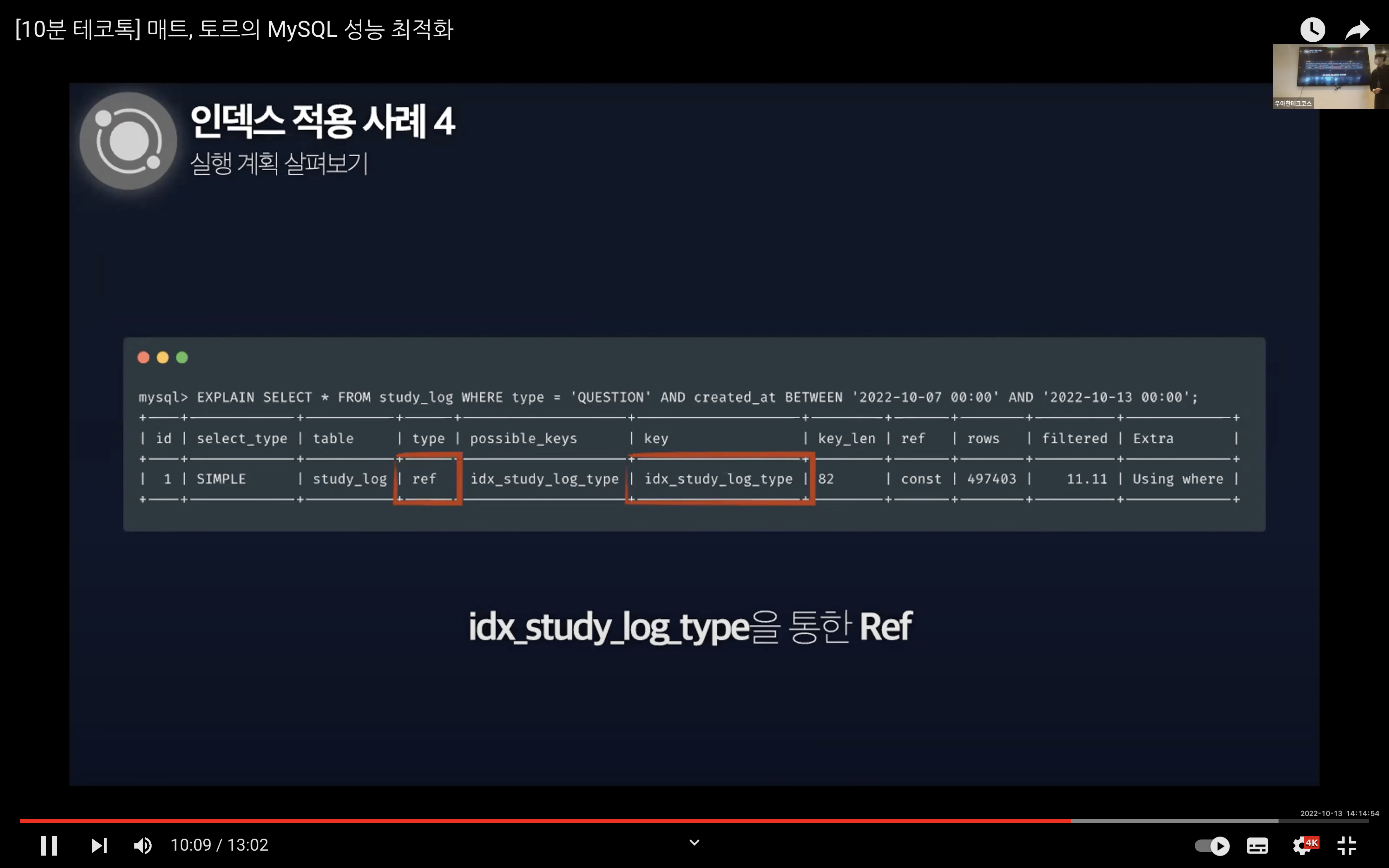
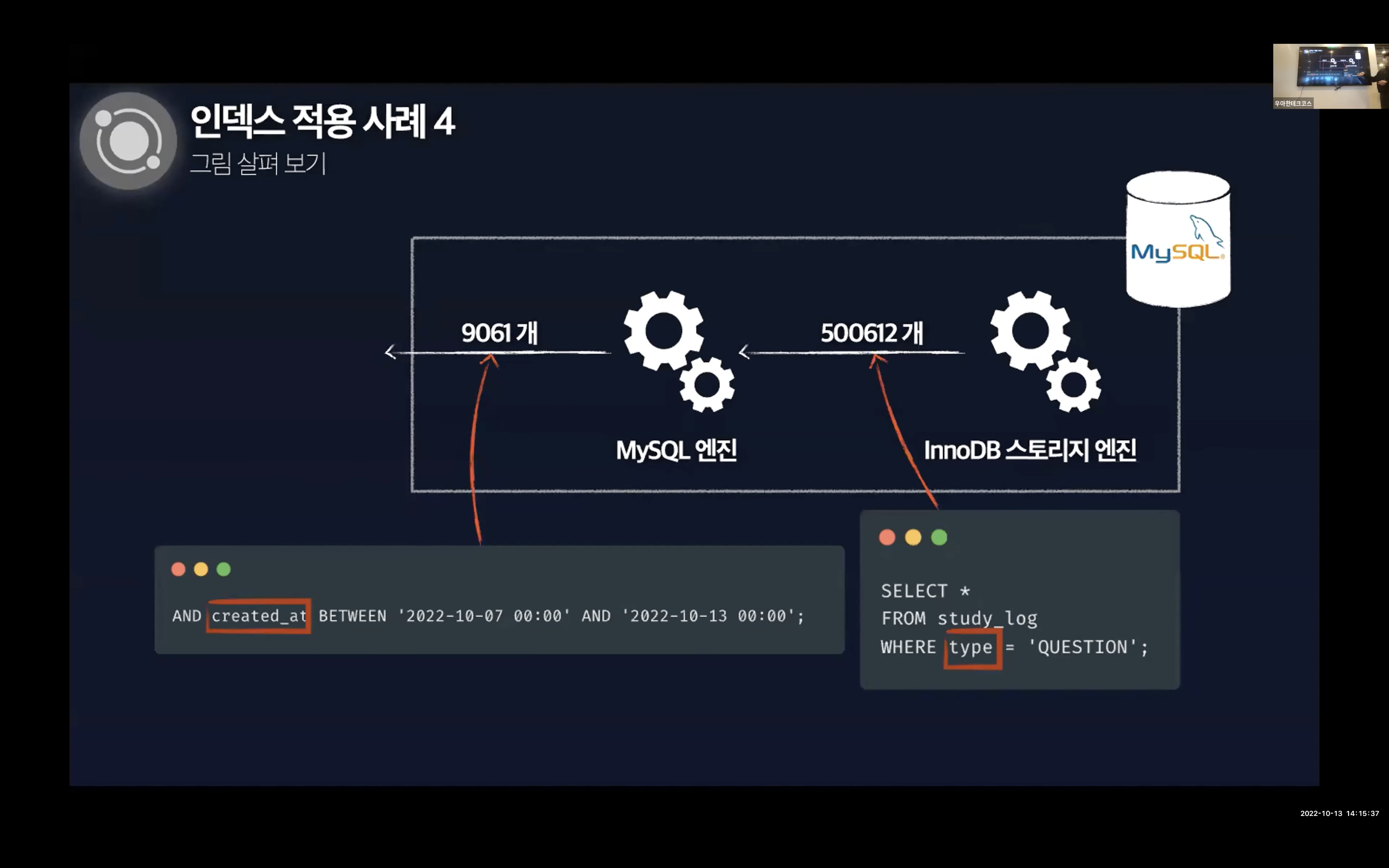
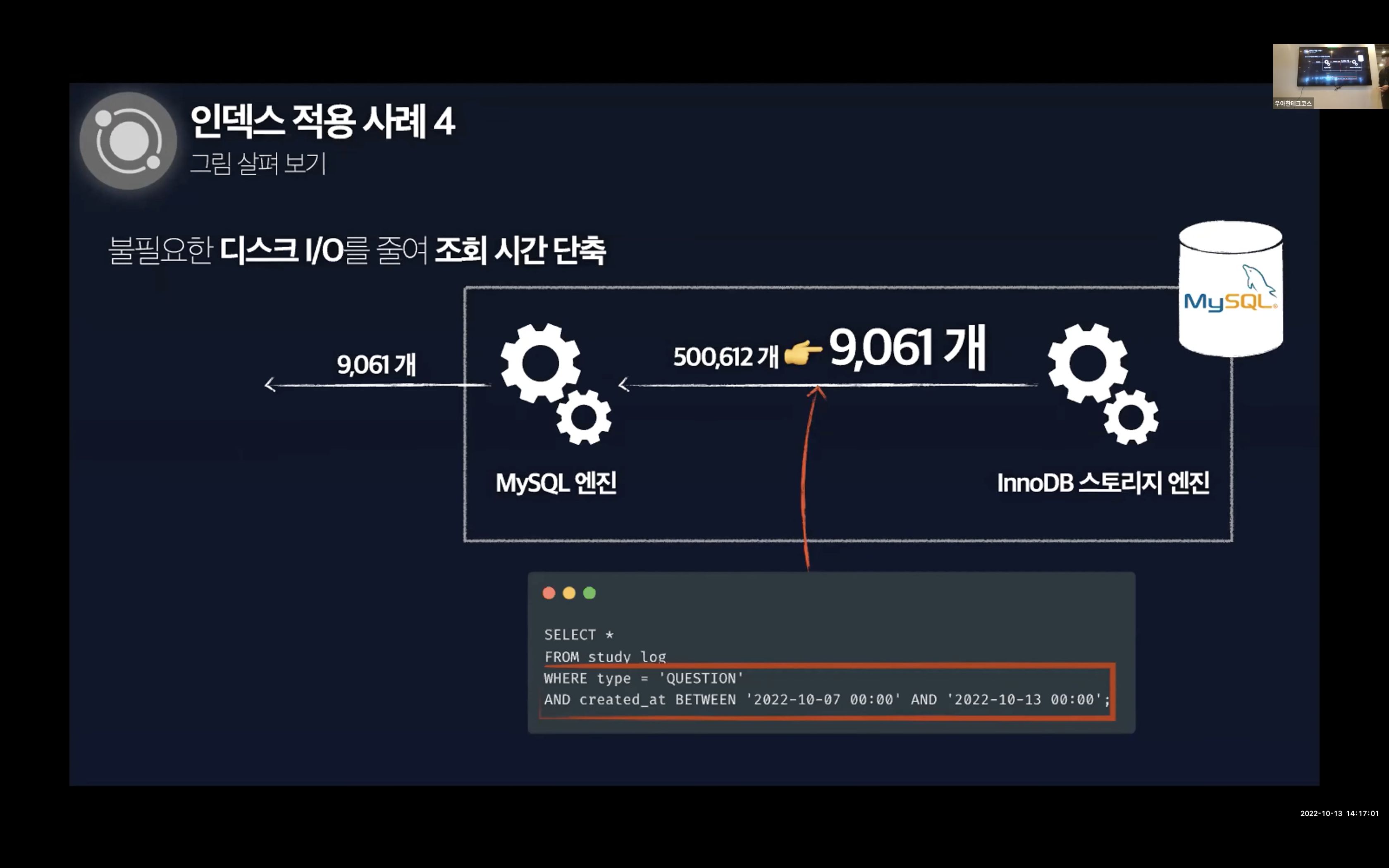
하지만 Extra 컬럼에 Using where라는 정보에 집중해야한다. Extra 컬럼은 쿼리의 실행 계획에서 성능에 관련된 중요한 내용이 표시되고 내부적인 처리 알고리즘에 대해 조금 더 깊은 내용을 보여주는데 - Using where는 InnoDB 스토리지 엔진을 통해 테이블에서 행을 가져온 뒤 MySQL 엔진에서 추가적인 체크 조건을 활용하여 행의 범위를 축소한 것을 의미한다. 즉, InnoDB 스토리지 엔진은 불필요한 데이터를 디스크에서 읽어오게 된다.
이 내용은 하단의 이미지로 보면 확실하게 이해할 수 있다.
이 문제는 복합 인덱스를 통해서 개선할 수 있다. 그리고 복합 인덱스를 적용한 상태에서 실행 계획을 보면 Extra 컬럼에 Using index condition이 표시되는 것을 확인할 수 있다.
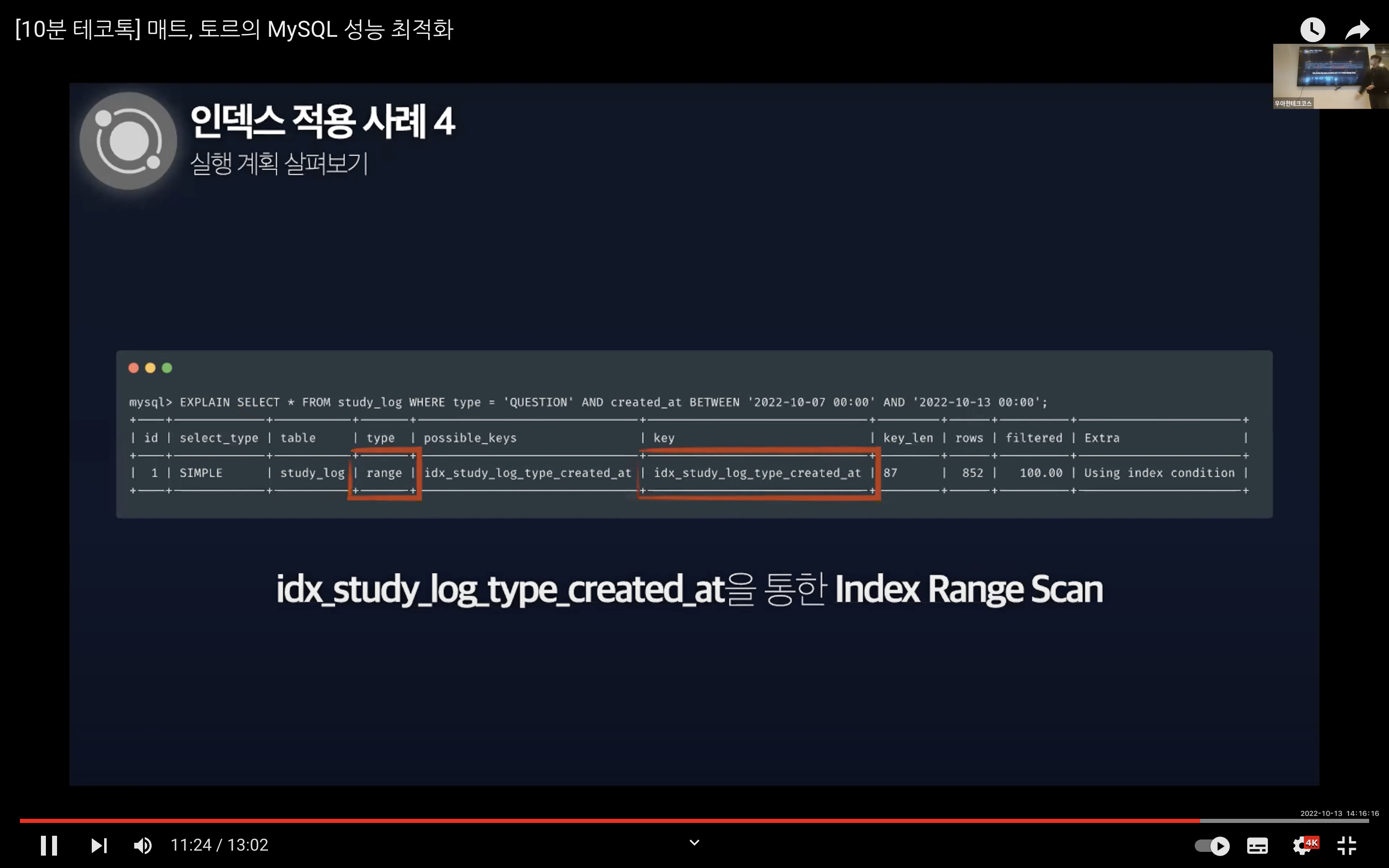
Using index condition은 인덱스 컨디션 푸시 다운으로 인해 표시가 된다. 인덱스 컨디션 푸시 다운은 MySQL이 인덱스를 사용하여 테이블에서 행을 검색하는 경우의 최적화를 의미한다.
이 기능을 이용하면 인덱스의 컬럼만을 사용하여 WHERE 조건의 일부를 평가할 수 있는 경우 MySQL 엔진은 WHERE 조건 부분을 스토리지 엔진으로 푸시한다. (최신 버전의 InnoDB에서는 기본적으로 ICP가 활성화되어 있다.)
그 결과 불필요한 디스크 I/O를 줄이는 것을 알 수 있다.
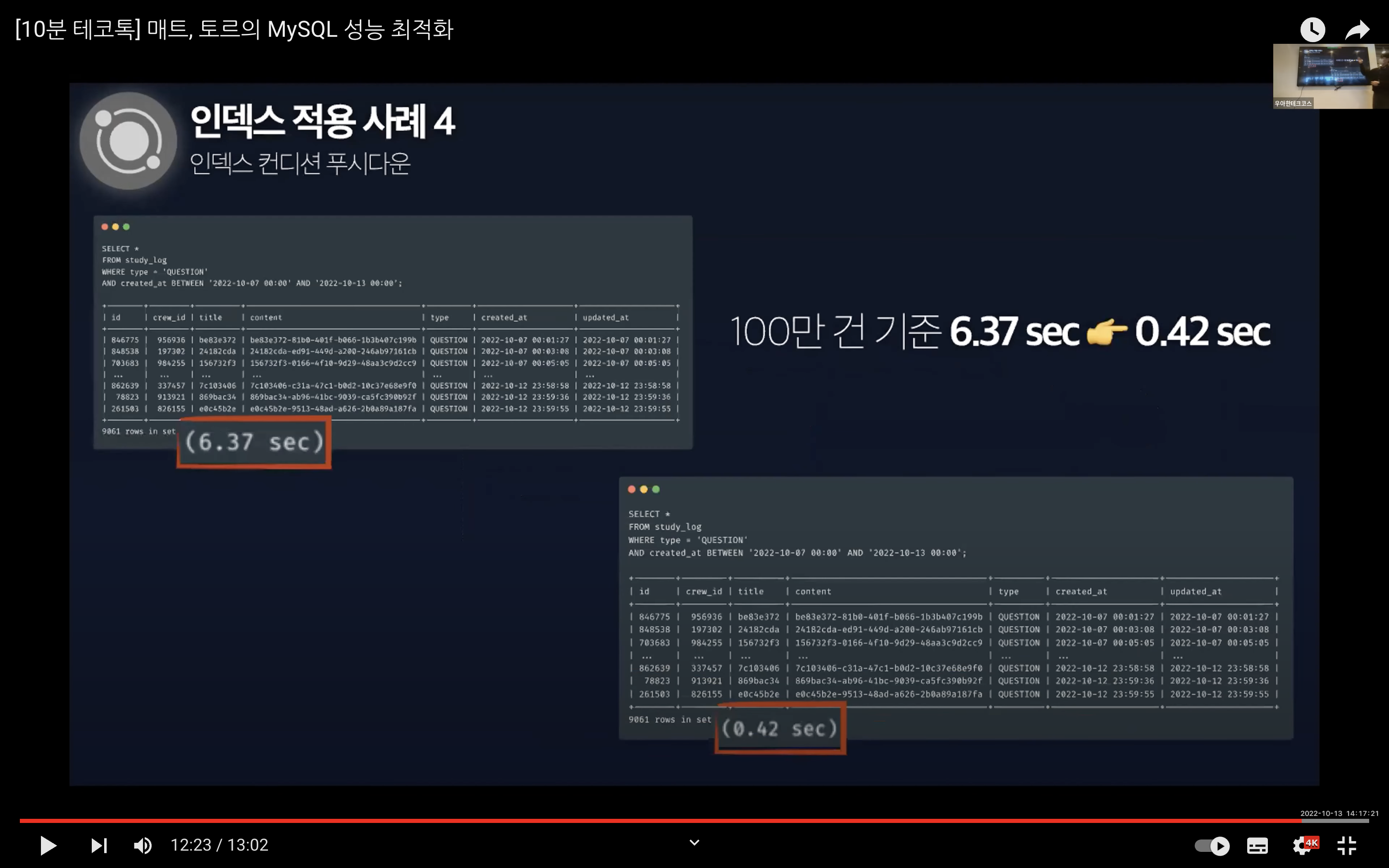
이 과정들을 통해 영상에서는 단순히 실행 계획에서 type 컬럼만을 가지고 판단하는 것이 아닌 Extra 컬럼까지 확인해봐야 한다고 했다.
이 글의 레퍼런스?
