
이 글의 목적?
프로젝트를 진행하면서 데이터베이스를 설계를 하던 중에 모든 테이블에 id라는 PK 컬럼을 지정해주는게 맞는가에 대해 고민했다. 그러다 갑자기 PK의 용도를 정확하게 정의할 수 없는 내 자신을 보고 온몸에 소름이 돋았다.
그래서 PK에 대한 내용을 찾아보다가 Real MySQL 책에서도 읽었던 것 같기도한 내용인 InnoDB는 기본적으로 데이터를 저장하고 인덱싱을 하기위해 PK를 요구한다는 글을 보았는데, 이 문장을 보고나서 한참을 멍하게 화면만 처다봤다.
결국 나는 기본적으로 데이터베이스가 내부적으로 어떻게 동작을 하고 있는건지에 대한 기본 지식이 부족하다는 생각이 들어 10분 테크톡 - 우기의 MySQL아키텍처 영상을 시청하게 되었고, 그 동안 내가 얼마나 무지성으로 테이블을 설계해왔는지에 대해 수치심(?)을 느끼며 영상의 내용을 글로 정리해보고자 한다.
(영상 마지막에 참고자료에는 Real MySQL 책이 있던 것같은데... 너 내가 진짜 언젠간 정복하고 만다.. 😠)
MySQL 아키텍처
MySQL 아키텍처는 총 4가지로 분리할 수 있다.
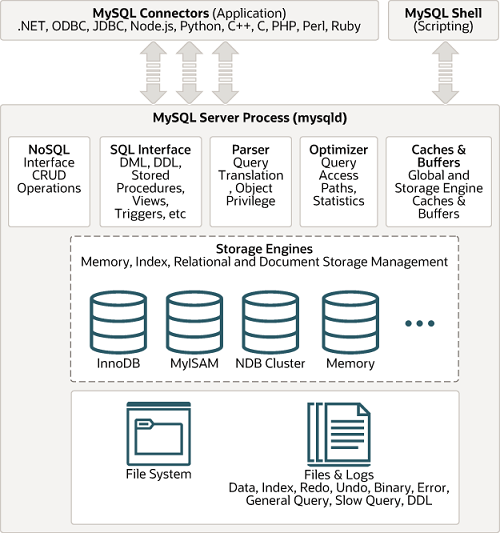
1. MySQL 접속 클라이언트
MySQL은 대부분의 언어에 대해 접속 API를 제공한다. 대표적으로는 JDBC, Shell이 있다.
2. MySQL 엔진 (두뇌)
클라이언트의 접속과 SQL 요청을 처리한다. MySQL 엔진은 다시 쿼리 파서, 전처리기, 옵티마이저, 실행 엔진 등으로 이루어져있다. 두뇌라고 불리는 이유 중 하나는 바로 SQL문을 최적화해서 실행시키기 위해 실행 계획을 구성하는 역할을 수행하는 옵티마이저 때문이다.
3. MySQL 스토리지 엔진 (손발)
스토리지 엔진은 실제로 디스크에 데이터를 저장하거나 읽어오는 역할을 수행한다. MySQL 엔진은 옵티마이저가 작성한 실행 계획에 따라서 스토리지 엔진을 적절히 호출하여 쿼리를 실행한다. (MySQL 엔진이 스토리지를 호출할 때 사용하는 API를 핸들러 API라고 한다.)
4. 운영체제, 하드웨어
실제 테이블의 데이터와 로그 데이터를 파일로 저장하는 공간이다.
쿼리 실행 과정
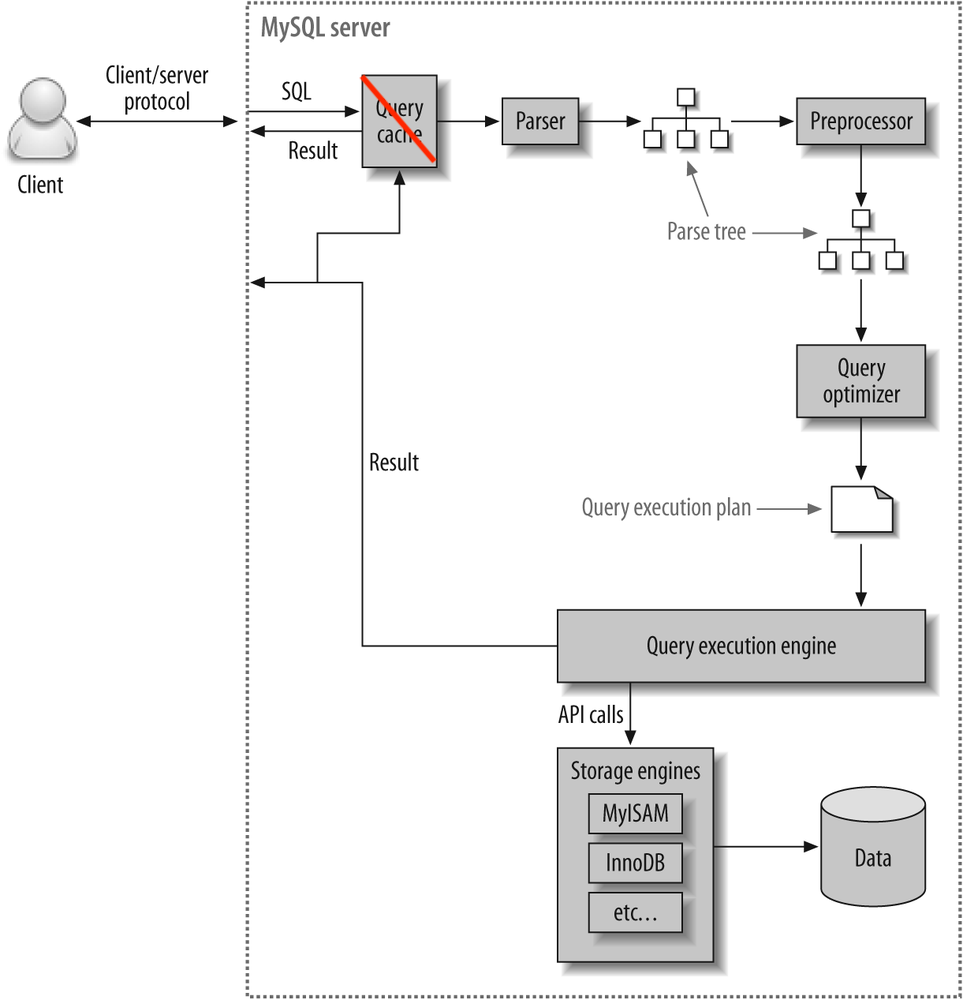
1. Query Cache
쿼리를 보내면 가장 먼저 만나는 곳이 바로 쿼리 캐시다. 쿼리 캐시는 쿼리 요청 결과를 캐싱하는 모듈로, 동일한 SQL 요청에 대한 결과를 빠르게 반환해준다. 그리고 테이블의 데이터가 변경될 경우에는 쿼리 캐시에서 캐싱 데이터를 삭제한다.
문제는 쿼리 캐시에 접근하는 쓰레드에 락이 걸리면서 동시 처리 성능 저하를 유발하기 때문에 MySQL 8.0부터는 완전히 삭제되었다.
2. Query Parser
쿼리 파서는 기본적인 SQL 문장 오류를 체크하는 역할을 수행한다. 그리고 하단의 이미지처럼 의미있는 단위의 토큰으로 쪼개어 트리로 만든다. MySQL은 내부적으로 파서 트리를 이용하여 쿼리를 실행한다.
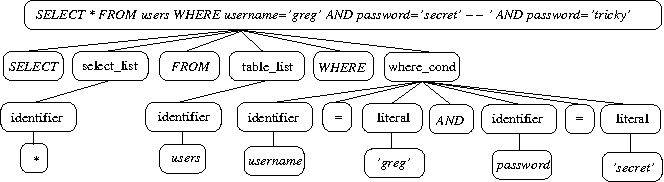
3. Preprocessor
전처리기는 쿼리 파서가 만든 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인한다. 파스 트리의 토큰을 하나씩 검사하면서 토큰에 해당하는 테이블명, 컬럼, 권한 등을 체크한다.
4. Query Optimizer
옵티마이저는 SQL을 최적화해서 실행시키는 쿼리 실행 계획을 수립한다. 옵티마이저가 최적화하는 방법으로는 규칙 기반 최적화와 비용 기반 최적화가 있다.
- 규칙 기반 최적화 : 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립
- 비용 기반 최적화 : 작업의 비용과 대상 테이블의 통계 정보를 활용하여 실행 계획을 수립
5. Query Execution Engine
쿼리 실행 엔진은 옵티마이저가 만든 실행 계획대로 스토리지 엔진을 호출하여 쿼리를 수행한다.
6. Storage Engine
스토리지 엔진은 쿼리 실행 엔진이 요청한대로 데이터를 디스크에 저장하거나 읽어오는 역할을 수행한다. 대표적으로는 InnoDB, MyISAM이 있다. 플러그인 형태로 제공되기 때문에 사용자가 원하는 스토리지 엔진을 선택하여 사용이 가능하다.
MySQL은 검색어 파서, 사용자 인증 모듈 등도 플러그인 형태로 제공한다. 하지만 플러그인끼리는 통신할 수 없고, MySQL의 변수나 함수를 직접 호출하기 때문에 캡슐화를 위반한다는 단점이 있다. 따라서 MySQL 8.0부터는 플러그인 아키텍처가 아닌 컴포넌트 아키텍처를 제공하게 되었다.
InnoDB 스토리지 엔진 아키텍처
PK에 의한 클러스터링
PK에 의한 클러스터링은 PK를 기준으로 데이터를 묶어서 저장하는 것이다. 즉, PK 순서대로 레코드를 정렬하여 디스크에 저장하는 것을 의미한다. InnoDB에서는 PK를 통해 데이터 파일에 접근하며, PK에 대한 인덱스를 자동으로 생성해준다.
PK 기준으로 데이터가 정렬되어 묶여서 한 곳에 저장되어있기 때문에 클러스터링을 수행하면 PK 기반 범위 검색 속도가 매우 빨라진다. 하지만 PK값이 변경되면 레코드의 물리적 순서도 하나씩 변경해줘야 하기 때문에 쓰기 성능은 저하된다는 단점이 있다.
InnoDB는 PK를 설정안하면 내부적으로 PK를 자동 생성하여 클러스터링을 진행하는데, 사용자가 직접 사용할 수 없기에 가능하면 PK를 직접 설정해주는 것을 권장한다.
트랜잭션 지원
MVCC
InnoDB는 기본적으로 커밋과 롤백 기능을 제공한다. 그리고 추가적으로 MVCC(Multi Version Concurrency Control) 기능을 제공한다. MVCC 기능은 어떤 것을 제공할까?!
영상의 내용을 이해하려면 InnoDB 버퍼풀과 언두 로그의 개념을 가볍게 이해하고 넘어가야한다.
- InnoDB 버퍼풀 : 변경된 데이터를 디스크에 반영하기 전까지 잠시 버퍼링하는 공간
- 언두 로그 : 변경되기 이전 데이터를 백업해두는 공간
이제 구체적인 내용은 영상의 자료를 첨부하여 설명해보면 다음과 같다.
데이터 삽입 및 커밋
우선 데이터를 삽입하고 커밋을 하는 과정에서 시작된다.


데이터 업데이트 (커밋 전)
그 다음에는 삽입한 데이터를 업데이트 쿼리를 요청했을 때, InnoDB 버퍼풀에 있는 데이터는 바로 변경되며 이전 데이터는 언두 로그에 복사된다.
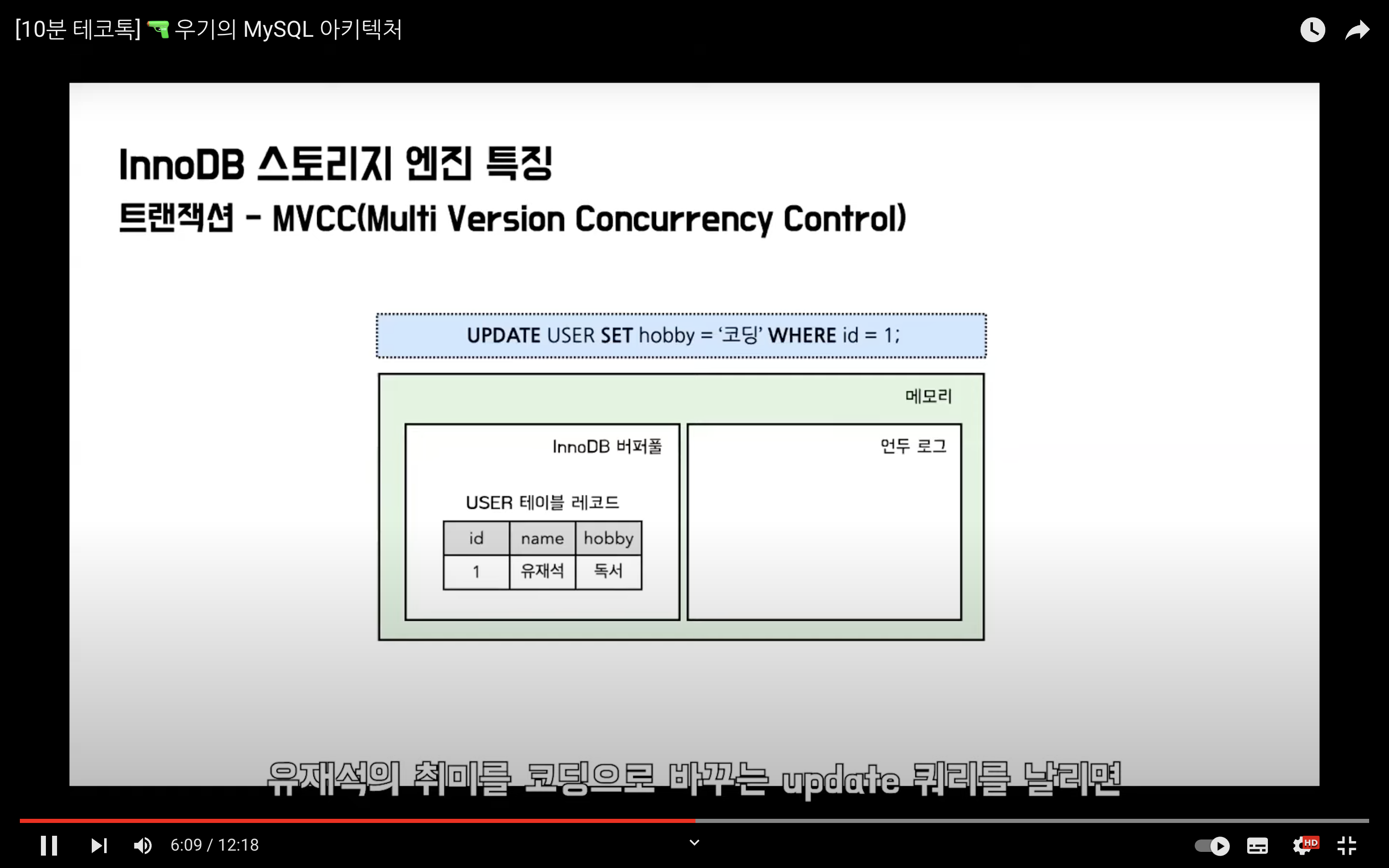
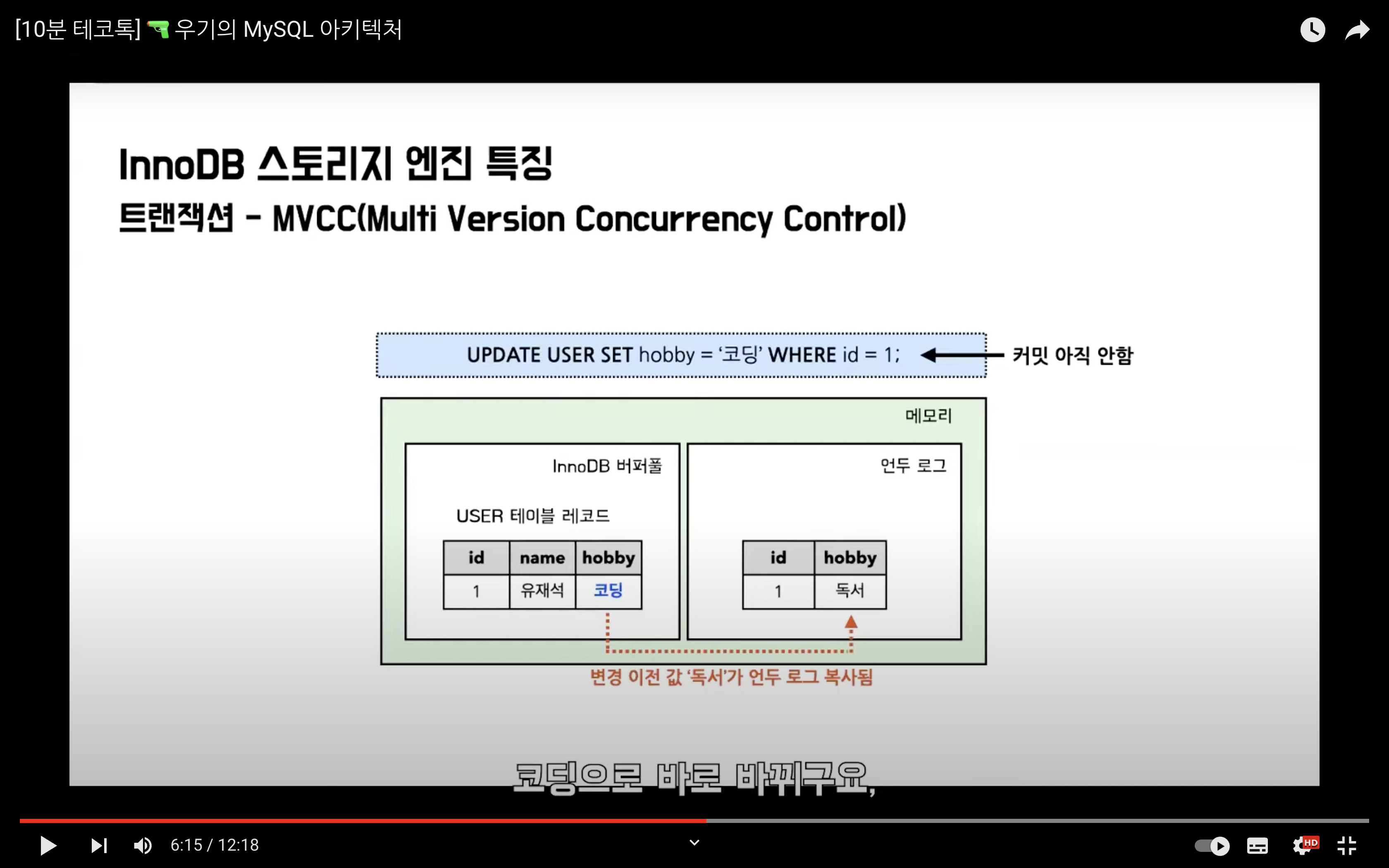
여기서 다른 트랜잭션이 해당 데이터를 조회할 경우 어떻게 될까?
여기서 이전에 정리해둔 트랜잭션 격리 수준에 대한 퍼즐이 맞춰지는 순간이였다. 😀
이 상태에서 조회되는 데이터는 트랜잭션 격리 수준에 따라 다른 결과를 출력해낸다.
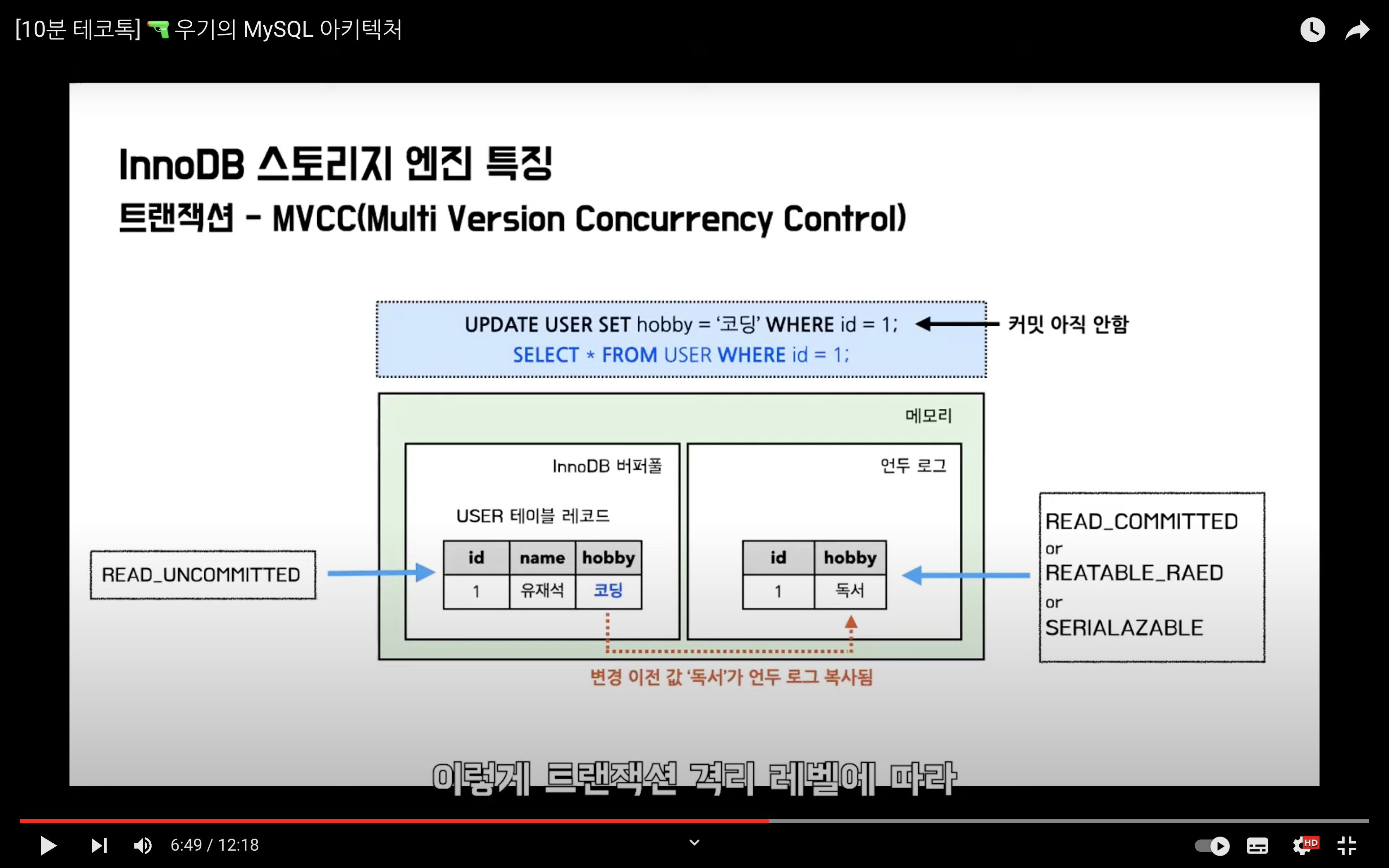
즉, MVCC는 다양한 버전이 동시에 관리되는 것으로 - 트랜잭션 격리 레벨에 따라 조회되는 데이터가 달라지는 기술을 의미한다. 가장 중요한 점은 MVCC를 통해 레코드에 잠금을 걸지 않고도 트랜잭션 격리 레벨에 따라 일관된 읽기를 할 수 있게 된다는 점이다.
Undo & Redo Log
언두 로그는 변경되기 이전 데이터를 백업해서 트랜잭션을 보장한다. 예를 들어 롤백할 경우 언두 로그의 데이터를 그대로 복원해주면 된다. 그리고 위에서 언급했듯이 트랜잭션 격리 수준을 보장해준다.
리두 로그는 트랜잭션의 영속성을 보장해준다. 리두 로그에는 변경되었고 커밋된 데이터를 백업해둔다. 하드웨어나 소프트웨어의 문제로 인해 MySQL이 비정상적으로 종료되면 리두 로그를 통해 데이터를 복원한다.
Record 단위 잠금
데이터베이스에서 데이터를 변경할 때는 동시성 문제를 고려하여 레코드에 대한 접근을 막는 것을 잠금이라한다. InnoDB는 레코드 단위로 잠금을 걸기 때문에 동시 처리 성능이 좋다. 하지만 실제로는 레코드가 아닌 인덱스 레코드를 잠근다.
영상에서는 하나의 예시를 통해 레코드 단위 잠금을 설명했다. 아까 말했듯이, InnoDB는 인덱스 레코드를 잠그는 방식으로 처리된다. 따라서 하단의 이미지처럼 업데이트할 레코드를 검색할 때 사용된 인덱스 레코드가 잠금이된다. (박씨 인덱스 레코드가 모두 잠긴다!!)

만약 검색할 때 사용할 인덱스가 없을 경우에는 레코드를 찾기 위해서 기본으로 생성된 PK 인덱스를 이용하여 테이블 풀 스캔을 한다. 마찬가지로 검색에 사용된 모든 PK 인덱스는 잠기게 된다. (모든 5000개의 레코드가 잠긴다!!)

반대로 복합 인덱스가 설정되어있을 경우에는 단 하나의 레코드만 잠기게 된다.
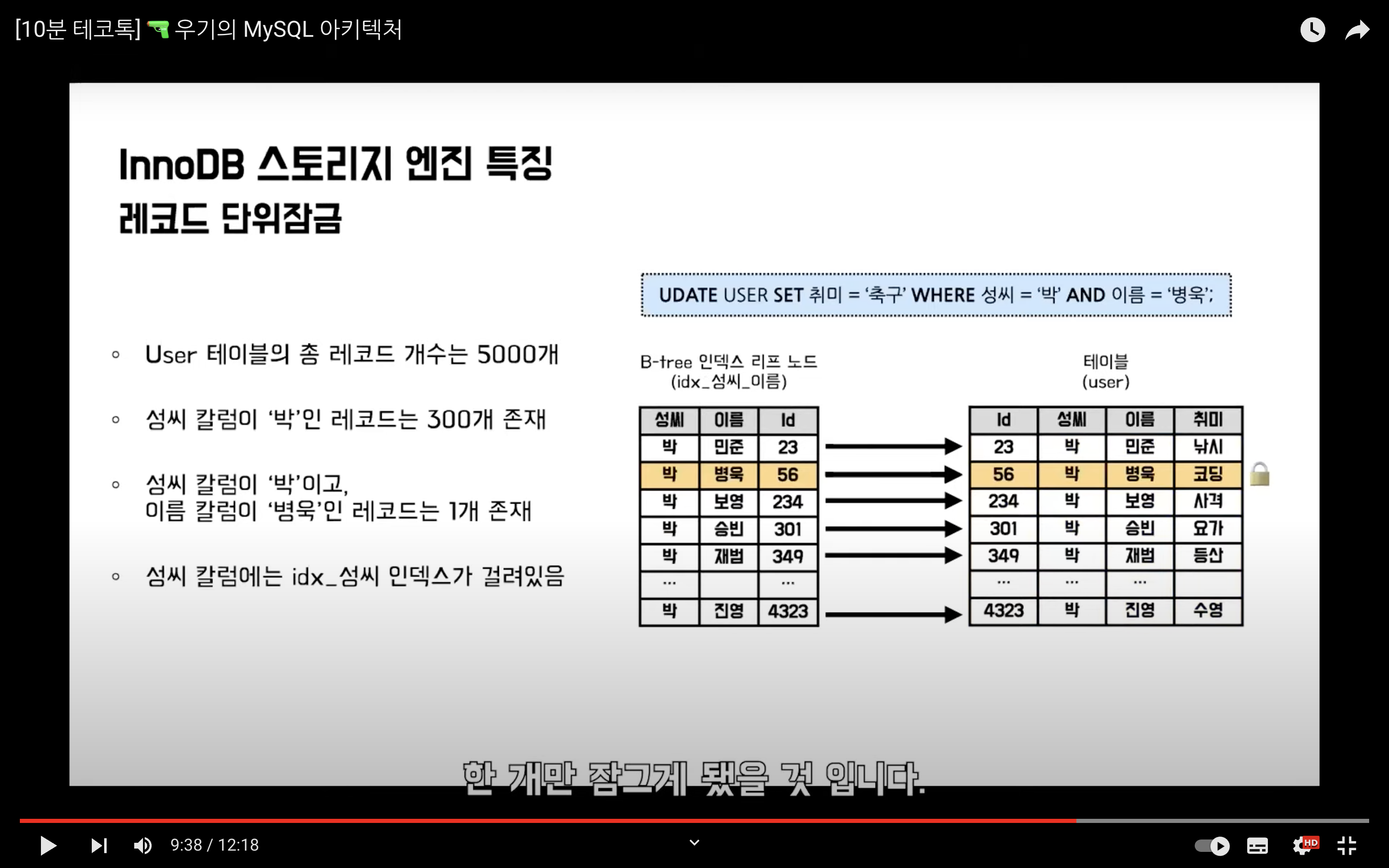
인덱스를 어떻게 설정하는지에 따라 레코드의 잠금 범위가 달라질 수 있기에 인덱스를 신중하게 설정해줘야한다는 것을 기억하자! 🙂
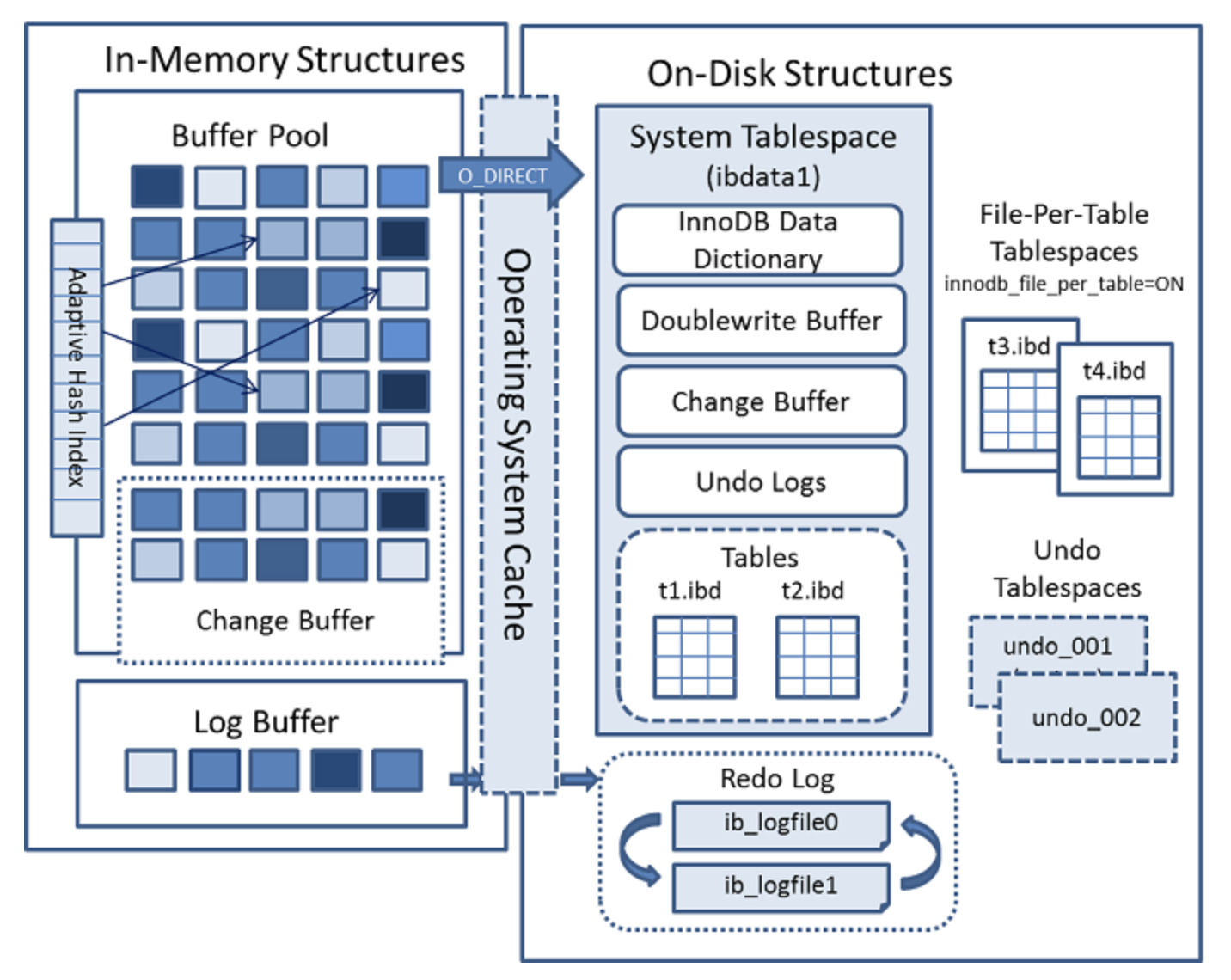
InnoDB Buffer Pool
InnoDB 버퍼풀은 변경된 데이터를 디스크에 반영하기 전까지 잠시 버퍼링하는 공간이라고 설명했다. 더 정확하게 설명한다면 버퍼풀은 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐싱해두는 공간이다.
버퍼풀은 SQL 요청 결과를 일정한 크기의 페이지 단위로 캐싱을 하게 되는데, InnoDB는 페이지 교체 알고리즘으로 LRU 알고리즘을 사용한다.
버퍼풀은 쓰기 작업을 지연시켜 일괄적으로 작업을 처리해주기도 한다. Insert, Update Delete 명령으로 변경된 페이지를 더티 페이지라고 하는데, InnoDB는 이를 모아 주기적으로 이벤트를 발생시켜 한번에 디스크에 반영한다. 모아서 처리하는 이유는 디스크 랜덤 I/O를 줄이기 위함이다.
Adaptive Hash Index
어댑티브 해시 인덱스는 인덱스 키와 페이지 주소값 쌍으로 구성된 인덱스다. 페이지에 빠르게 접근하기 위해 사용한다. InnoDB는 사용자가 자주 요청하는 데이터에 대해 자동으로 만들어준다. 원하는 페이지에 빠르게 접근할 수 있기 때문에 쿼리를 더 빠르게 처리할 수 있다.
추가적으로 영상에서는 MyISAM 스토리지 엔진에 대해서도 언급했지만 MyISAM이 제공하는 대부분의 기능들은 InnoDB에서도 지원해주고 있고, 이 후 더 이상 사용되지 않을 거라는 이야기가 있어 MyISAM 내용에 대해서는 생략하겠다.
이 글의 레퍼런스
