
1. 들어가며
이직한 회사에서 처음으로 GCP 계정 가입부터 데이터 적재 프로세스를 만들고, API 연결 및 과거 데이터 백필, Cloud Run을 통해 Daily 배치 함수를 배포해보고 있습니다. 모두 처음 해보는 과정이라 스스로 잊지 않기 위해 기록하고 있으며, 전체 코드는 하단에서 확인할 수 있으나 효율적인 방법이나 클린코드임을 담보할 수 없다는 점을 미리 밝힙니다.
본 글에서는 메타 Marketing AP 앱만들기 > 과거 데이터 백필 > Daily 업데이트 과정 중 앱을 만들고 과거 데이터 백필과정까지에 대해 다룹니다
1.1 예상독자
- 처음 메타 API를 GCP에 적재하려고 하시는 비데이터엔지니어 출신 기획자/데이터분석가/마케터 등
2. 앱만들기
2.1 권한 업데이트하기
-
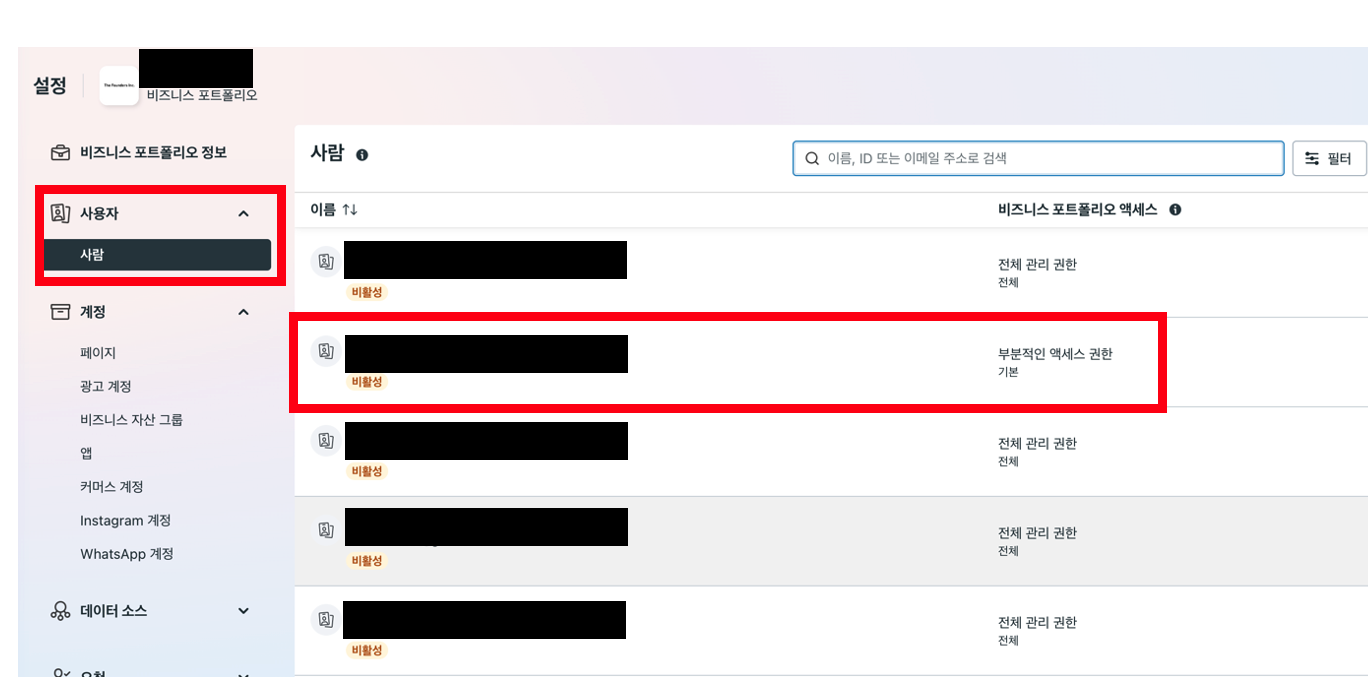
이미 Meta 계정이 있어서 조회가능하더라도 앱 개발을 위해서 비즈니스포트폴리오 엑세스 권한을 부분적인 엑세스 권한 > 전체 관리권한으로 업데이트가 필요
-
⚠️ 단순히 광고 계정 권한할당이 아니라 사용사 > 사람에서 권한 부여가 필요
-
이미 전체관리 권한을 보유한 분께 권한설정페이지에서 업데이트를 요청드리고, 총 2명의 승인과정을 거쳐 전체 관리 권한 부여됨
2.2 앱 만들기
1️⃣ 앱 생성
- 메타 개발자 페이지 접속
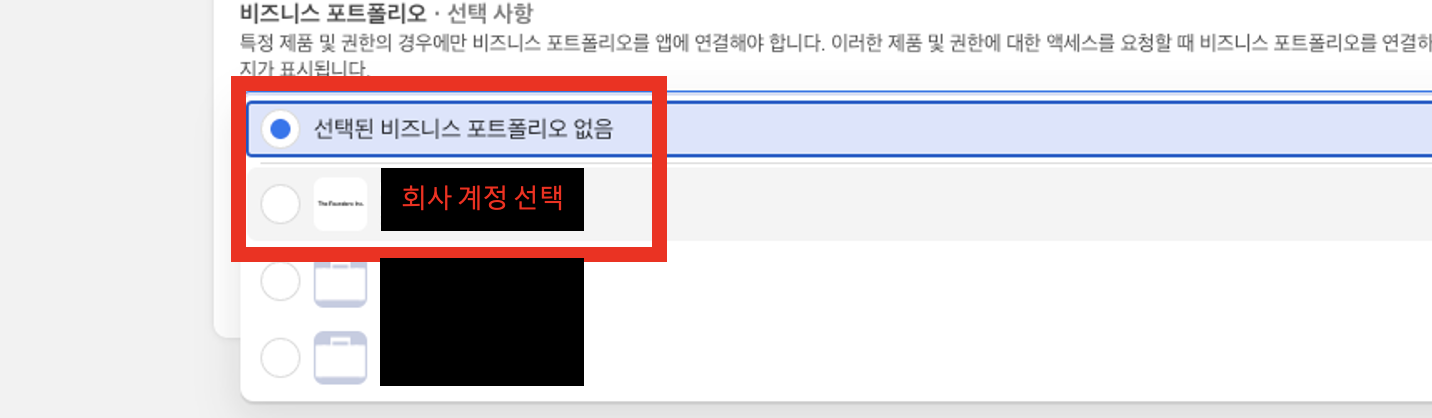
- 내앱 > 앱만들기 > 이용 사례 : 기타 클릭 > 앱유형선택 :비즈니스 클릭 > 상세정보 : 비즈니스포트폴리오 회사 계정을 선택
만약, 이 단계에서 회사 계정이 뜨지 않는다면 권한 설정이 되지 않은 것이며, 다시 한번 요청드려야합니다
2️⃣ 앱 정보 확인
- 마케팅 API 설정 클릭
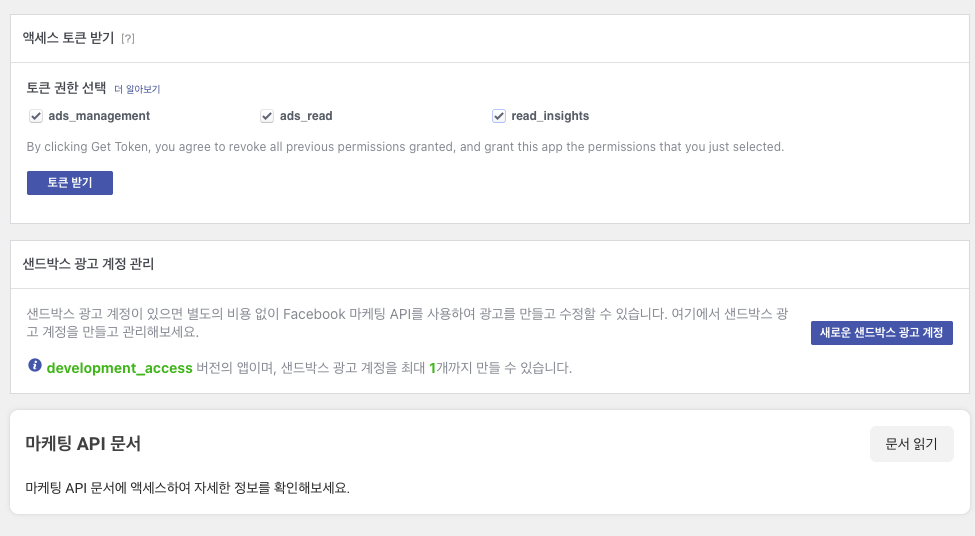
- 토큰권한을 선택하고 토큰 받기 클릭 > 생성된 토큰 정보 복사
- 앱ID, 시크릿 코드 : 앱 대시보드 > 앱 설정 > 기본 설정에서 조회하기 > ID, 시크릿코드 복사

3.GCP 권한
3.1 GCP 서비스계정 키 발급
API 데이터를 GCP에 적재해야하므로 접근할 수 있는 권한을 부여해야합니다
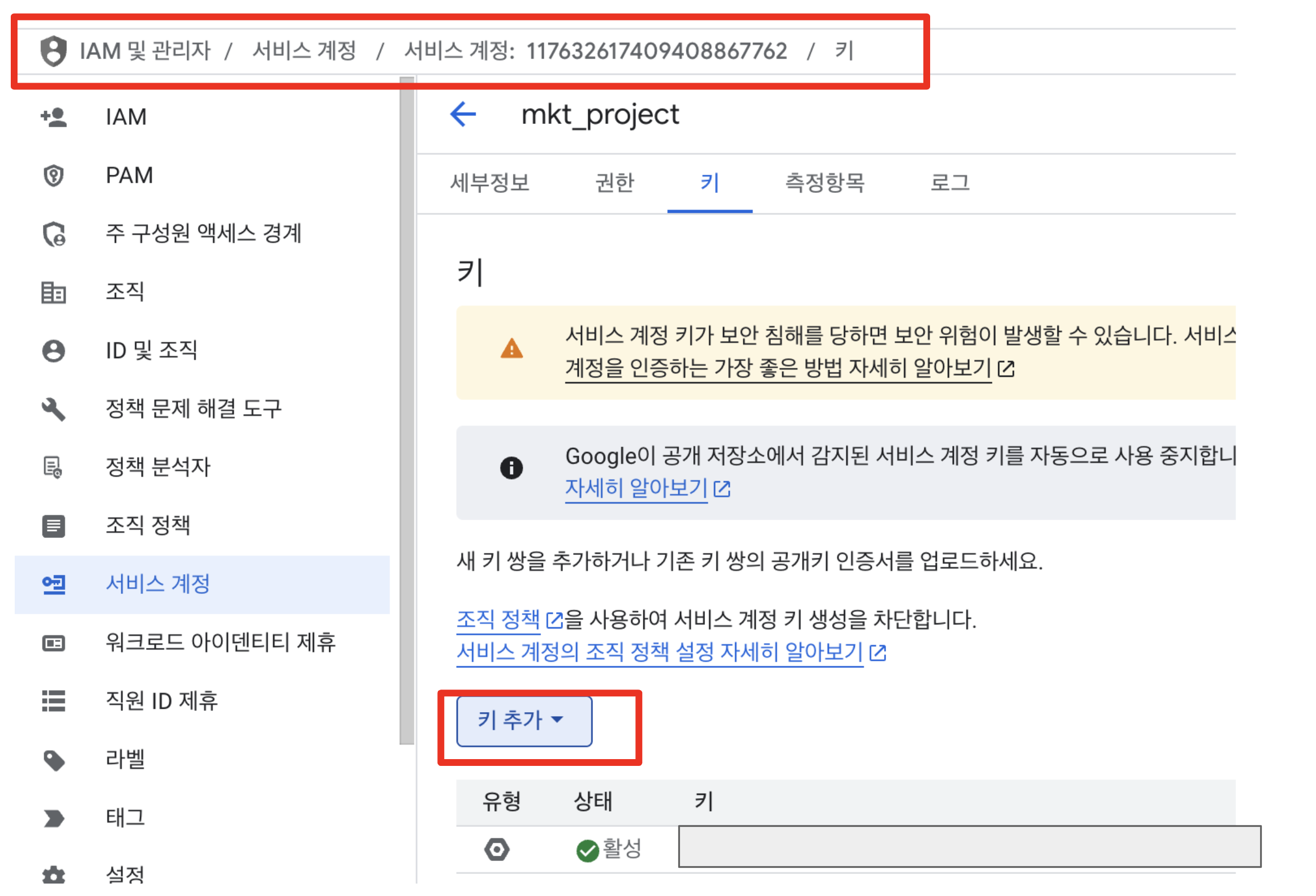
- IAM 및 관리자 > 서비스 계정 > 키 추가 클릭
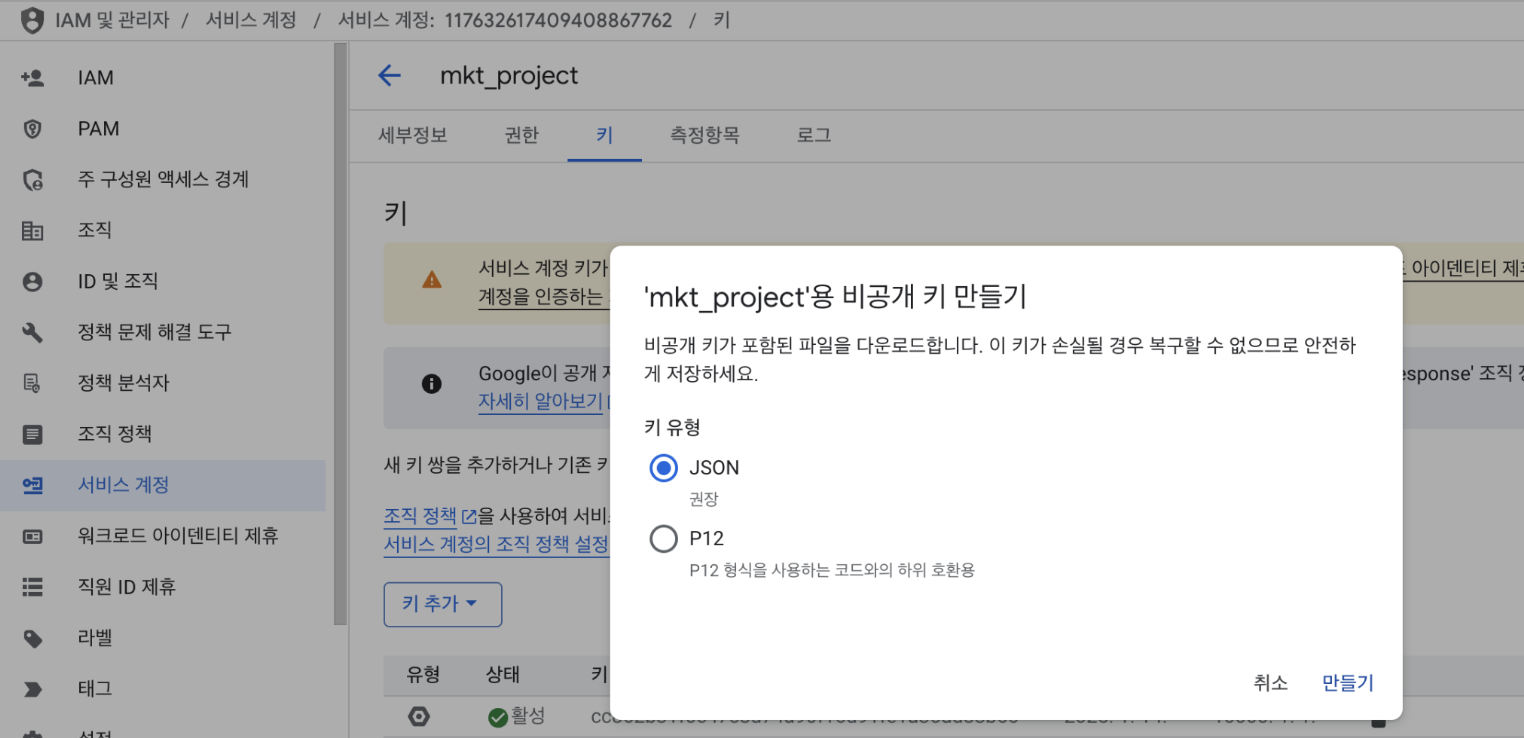
- JSON형식으로 다운 받고 다운받은 경로 저장하기
예)/Users/user/Desktop/API/mkt_prodect.json
단, 파일 경로를 확인하여 하드코딩하는 과정은 로컬에서 실행할 때에만 필요하며,GCP 환경(Cloud Functions, Cloud Run 등)에서 실행할 때는 기본 인증을 사용하므로 생략할 수 있습니다.
4. 코드
액세스 토큰 정보 등 수정이 용이하도록 코드를 두 단계로 나눈 것일 뿐, 실행할 때에는 두 코드를 연결하여 실행해주세요!
4.1 환경 설정 관련 코드
import requests
import pandas as pd
import json
import time
from datetime import date, timedelta
from google.cloud import bigquery
from google.oauth2 import service_account
import logging
# Logging setup
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
#3.1 단계에서 GCP 서비스계정 키 발급받은 정보
KEY_PATH = "GCP json파일저장한 경로"
credentials = service_account.Credentials.from_service_account_file(
KEY_PATH,
scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
client = bigquery.Client(credentials=credentials, project=credentials.project_id)
# GCP프로젝트, 데이터셋, 테이블 정보
PROJECT_ID = 'GCP_PROJECTID'
DATASET_ID = 'GCP_DATASETID'
TABLE_ID = 'GCP_TABLEID'
TABLE_REF = f"{PROJECT_ID}.{DATASET_ID}.{TABLE_ID}"
# 액세스토큰정보
#가져올 광고계정정보
ACCESS_TOKEN = '발급받은 토큰 정보 저장하기'
API_VERSION = 'v22.0'
ACCOUNT_IDS = [
{'id': 'act_광고계정넘버', 'name': '자사몰'},
{'id': 'act_광고계정넘버', 'name': '올리브영'}
] 4.2 데이터 적재 관련 코드
# 조회할 데이터의 기간 정보 - 직접 지정
start_date = "2024-03-01" # 시작일 (YYYY-MM-DD 형식)
end_date = "2024-03-15" # 종료일 (YYYY-MM-DD 형식)
# GCP 인증 설정
def initialize_bigquery_client(key_path=None):
"""BigQuery 클라이언트 초기화"""
try:
if key_path:
# 서비스 계정 키 파일을 사용하여 인증
credentials = service_account.Credentials.from_service_account_file(
key_path,
scopes=["https://www.googleapis.com/auth/cloud-platform"],
)
client = bigquery.Client(credentials=credentials, project=credentials.project_id)
else:
# 기본 인증 사용 (GCP 환경에서 실행 시)
client = bigquery.Client()
logger.info(f"BigQuery 클라이언트 초기화 완료: {client.project}")
return client
except Exception as e:
logger.error(f"BigQuery 클라이언트 초기화 오류: {e}")
raise
def create_table_if_not_exists(client):
"""테이블이 없으면 생성"""
try:
# 테이블 존재 여부 확인
try:
table = client.get_table(TABLE_REF)
logger.info(f"테이블이 이미 존재합니다: {TABLE_REF}")
except Exception:
# 테이블이 없으면 생성
logger.info(f"테이블이 존재하지 않습니다. 테이블 생성 중: {TABLE_REF}")
schema = [
bigquery.SchemaField("date", "DATE", mode="REQUIRED", description="광고 날짜"),
bigquery.SchemaField("campaign_name", "STRING", mode="NULLABLE", description="캠페인명"),
bigquery.SchemaField("adset_name", "STRING", mode="NULLABLE", description="애드셋명"),
bigquery.SchemaField("ad_name", "STRING", mode="NULLABLE", description="광고명"),
bigquery.SchemaField("platform", "STRING", mode="NULLABLE", description="플랫폼"),
bigquery.SchemaField("impressions", "INTEGER", mode="NULLABLE", description="노출수"),
bigquery.SchemaField("spend", "FLOAT", mode="NULLABLE", description="지출 비용"),
bigquery.SchemaField("clicks", "INTEGER", mode="NULLABLE", description="클릭수"),
bigquery.SchemaField("installs", "INTEGER", mode="NULLABLE", description="앱 설치 수"),
bigquery.SchemaField("purchases", "INTEGER", mode="NULLABLE", description="구매 수"),
bigquery.SchemaField("purchase_value", "FLOAT", mode="NULLABLE", description="구매 가치"),
bigquery.SchemaField("account_id", "STRING", mode="REQUIRED", description="계정 ID"),
bigquery.SchemaField("account_name", "STRING", mode="REQUIRED", description="계정 이름"),
bigquery.SchemaField("load_timestamp", "TIMESTAMP", mode="REQUIRED", description="로드 시간"),
]
table = bigquery.Table(TABLE_REF, schema=schema)
table = client.create_table(table)
logger.info(f"테이블이 생성되었습니다: {TABLE_REF}")
except Exception as e:
logger.error(f"테이블 생성 오류: {e}")
raise
def delete_existing_data(client, start_date, end_date):
"""지정된 날짜 범위의 기존 데이터 삭제"""
query = f"""
DELETE FROM `{TABLE_REF}`
WHERE date BETWEEN '{start_date}' AND '{end_date}'
"""
try:
query_job = client.query(query)
query_job.result()
logger.info(f"기존 데이터 삭제 완료: {start_date} ~ {end_date}")
except Exception as e:
logger.error(f"기존 데이터 삭제 오류: {e}")
raise
def get_meta_data_sync(access_token, api_version, act_id, act_name, start_date, end_date):
"""동기 방식으로 Meta Ads 데이터를 가져오는 함수"""
start_date_obj = date.fromisoformat(start_date)
end_date_obj = date.fromisoformat(end_date)
all_data = []
# 날짜별로 데이터 수집
current_date = start_date_obj
while current_date <= end_date_obj:
date_str = str(current_date)
url = f"https://graph.facebook.com/{api_version}/{act_id}/insights"
params = {
'access_token': access_token,
'level': 'ad',
'breakdowns': 'publisher_platform',
'fields': 'date_start,date_stop,ad_name,campaign_name,adset_name,impressions,spend,inline_link_clicks,actions,action_values',
'time_range': json.dumps({"since": date_str, "until": date_str}),
'use_unified_attribution_setting': 'true',
}
logger.info(f"계정 {act_id} - {date_str} 데이터 요청 중...")
response = requests.get(url=url, params=params)
data = response.json()
if 'data' in data:
# 계정 정보 추가
for item in data['data']:
item['account_id'] = act_id.replace('act_', '')
item['account_name'] = act_name
all_data.extend(data['data'])
logger.info(f"- {date_str} 데이터 {len(data['data'])}개 수집됨")
# 페이징 처리
next_page = data.get('paging', {}).get('next')
while next_page:
response = requests.get(next_page)
data = response.json()
if 'data' in data:
# 계정 정보 추가
for item in data['data']:
item['account_id'] = act_id.replace('act_', '')
item['account_name'] = act_name
all_data.extend(data['data'])
logger.info(f"- 추가 데이터 {len(data['data'])}개 수집됨")
next_page = data.get('paging', {}).get('next')
else:
next_page = None
else:
logger.warning(f"- {date_str} 데이터 없음 또는 오류: {data}")
# 다음 날짜로 이동
current_date += timedelta(days=1)
# API 호출 제한 방지를 위한 지연
time.sleep(1)
# 수집된 데이터를 DataFrame으로 변환
if not all_data:
logger.warning(f"계정 {act_id}에 대해 수집된 데이터가 없습니다.")
return pd.DataFrame()
meta_date = []
meta_campaign = []
meta_adset = []
meta_ad = []
meta_publisher_platform = []
meta_imp = []
meta_spend = []
meta_clicks = []
meta_install = []
meta_purchase = []
meta_purchase_value = []
meta_account = []
meta_account_name = []
for item in all_data:
meta_date.append(item.get("date_start"))
meta_campaign.append(item.get("campaign_name"))
meta_adset.append(item.get("adset_name"))
meta_ad.append(item.get("ad_name"))
meta_publisher_platform.append(item.get("publisher_platform"))
meta_account.append(item.get("account_id"))
meta_account_name.append(item.get("account_name"))
meta_imp.append(item.get("impressions", 0))
meta_spend.append(item.get("spend", 0))
meta_clicks.append(item.get("inline_link_clicks", 0))
# action 및 action_values 처리
meta_install_in, meta_purchase_in = 0, 0
meta_purchase_value_in = 0
if 'actions' in item:
for action in item['actions']:
if action.get("action_type") == "omni_app_install":
meta_install_in = action.get("value", 0)
elif action.get("action_type") == "omni_purchase":
meta_purchase_in = action.get("value", 0)
if 'action_values' in item:
for action_value in item['action_values']:
if action_value.get("action_type") == "omni_purchase":
meta_purchase_value_in = action_value.get("value", 0)
meta_install.append(meta_install_in)
meta_purchase.append(meta_purchase_in)
meta_purchase_value.append(meta_purchase_value_in)
col = ["date", "campaign_name", "adset_name", "ad_name", "platform",
"impressions", "spend", "clicks", "installs",
"purchases", "purchase_value", "account_id", "account_name"]
meta_data_df = pd.DataFrame(zip(meta_date, meta_campaign, meta_adset, meta_ad,
meta_publisher_platform, meta_imp, meta_spend,
meta_clicks, meta_install, meta_purchase,
meta_purchase_value, meta_account, meta_account_name), columns=col)
return meta_data_df
def collect_all_accounts_data(start_date, end_date):
"""모든 계정의 데이터를 수집하여 하나의 DataFrame으로 반환"""
all_data_frames = []
for account in ACCOUNT_IDS:
logger.info(f"\n계정 {account['name']} ({account['id']}) 처리 중...")
# 동기 방식으로 직접 데이터 수집
df = get_meta_data_sync(ACCESS_TOKEN, API_VERSION, account['id'], account['name'], start_date, end_date)
if not df.empty:
all_data_frames.append(df)
logger.info(f"계정 {account['name']}에서 {len(df)}개 행의 데이터 수집 완료")
else:
logger.warning(f"계정 {account['name']}에서 데이터를 수집하지 못했습니다.")
if all_data_frames:
# 모든 데이터프레임 병합
result_df = pd.concat(all_data_frames, ignore_index=True)
logger.info(f"\n총 {len(result_df)}개 행의 데이터 수집 완료")
return result_df
else:
logger.warning("모든 계정에서 데이터를 수집하지 못했습니다.")
return pd.DataFrame()
def upload_to_bigquery(client, df):
"""DataFrame을 BigQuery에 업로드"""
try:
# 데이터 타입 변환
df['date'] = pd.to_datetime(df['date']).dt.date
df['impressions'] = pd.to_numeric(df['impressions'], errors='coerce').fillna(0).astype('int64')
df['clicks'] = pd.to_numeric(df['clicks'], errors='coerce').fillna(0).astype('int64')
df['installs'] = pd.to_numeric(df['installs'], errors='coerce').fillna(0).astype('int64')
df['purchases'] = pd.to_numeric(df['purchases'], errors='coerce').fillna(0).astype('int64')
df['spend'] = pd.to_numeric(df['spend'], errors='coerce').fillna(0).astype('float64')
df['purchase_value'] = pd.to_numeric(df['purchase_value'], errors='coerce').fillna(0).astype('float64')
# 로드 타임스탬프 추가
from datetime import datetime
df['load_timestamp'] = datetime.now()
# BigQuery에 데이터 적재
job_config = bigquery.LoadJobConfig(
write_disposition=bigquery.WriteDisposition.WRITE_APPEND
)
job = client.load_table_from_dataframe(
df,
TABLE_REF,
job_config=job_config
)
job.result() # 작업 완료 대기
logger.info(f"BigQuery에 {len(df)}개 행의 데이터 적재 완료")
return True
except Exception as e:
logger.error(f"BigQuery 적재 오류: {e}")
import traceback
logger.error(traceback.format_exc())
return False
def main(key_path=None):
"""메인 실행 함수"""
try:
logger.info(f"Meta Ads 데이터 수집 및 BigQuery 적재 시작 (기간: {start_date} ~ {end_date})")
# BigQuery 클라이언트 초기화
bq_client = initialize_bigquery_client(key_path)
# 테이블 생성 (없는 경우)
create_table_if_not_exists(bq_client)
# 기존 데이터 삭제 (같은 기간 데이터가 있는 경우)
delete_existing_data(bq_client, start_date, end_date)
# 모든 계정 데이터 수집
meta_data = collect_all_accounts_data(start_date, end_date)
if not meta_data.empty:
# BigQuery에 데이터 적재
success = upload_to_bigquery(bq_client, meta_data)
if success:
logger.info("데이터 수집 및 적재 과정이 성공적으로 완료되었습니다.")
return True
else:
logger.error("데이터 적재에 실패했습니다.")
return False
else:
logger.warning("수집된 데이터가 없습니다.")
return False
except Exception as e:
logger.error(f"처리 중 오류 발생: {e}")
import traceback
logger.error(traceback.format_exc())
return False
if __name__ == '__main__':
import argparse
# 명령줄 인자 처리
parser = argparse.ArgumentParser(description='Meta Ads 데이터를 수집하여 BigQuery에 적재')
parser.add_argument('--key_path', type=str, help='GCP 서비스 계정 키 파일 경로 (로컬 실행 시)')
parser.add_argument('--start_date', type=str, help='시작 날짜 (YYYY-MM-DD 형식)')
parser.add_argument('--end_date', type=str, help='종료 날짜 (YYYY-MM-DD 형식)')
args = parser.parse_args()
# 명령줄에서 날짜 범위가 제공되면 업데이트
if args.start_date:
start_date = args.start_date
if args.end_date:
end_date = args.end_date
logger.info(f"설정된 날짜 범위: {start_date} ~ {end_date}")
# 메인 함수 실행
success = main(args.key_path)
if success:
logger.info("프로그램이 성공적으로 완료되었습니다.")
else:
logger.error("프로그램 실행 중 오류가 발생했습니다.")
5. 마무리
본 글에서는 메타 Marketing AP 앱만들기 > 과거 데이터 백필 > Daily 업데이트 과정 중 앱을 만들고 과거 데이터 백필과정까지 다뤄보았습니다.
다음 글에서는 데일리로 데이터를 증분하는 코드를 GCP Cloud 환경에서 수행하고, 스케줄잡을 설정하는 과정에 대해 다뤄보겠습니다.
관련문서
