1. CPU 심화
1️⃣ 제어장치(CU) 스케줄링
CPU를 잘 사용하기 위해서는 프로세스(프로그램 실행 주체)를 잘 배정해야 한다.
OS는 실행 대기중인 프로그램(프로세스)에 CPU 자원배정을 적절히하여 시스템의 최대성능을 끌어올릴 수 있다.
📌 공통 배정조건
오버헤드 ⬇️, 사용률 ⬆️, 기아현상 ⬇️오버헤드: 프로세스가 필요한 자원보다 더 많이 사치부리며 사용하지 않도록 (not too much)사용률: 프로세스가 한번에 최대한 자원을 많이 받고 빨리 처리하도록기아현상: 프로세스가 자원 할당을 받지 못해 배고픈 상태로 대기하지 않도록
📌 목표에 따른 배정조건
| 구분 | 내용 |
|---|---|
| 배치시스템 | - 일괄처리 시스템 - 가능하면 많은 일을 수행하도록 구성 - 시간(time)보다 처리량(throughout)이 중요 |
| 대화형시스템 | - 빠른 응답시간 + 적은 대기시간이 중요 |
| 실시간시스템 | - 실시간(time) 최소응답시간(dead line)이 중요 |
📌 정책에 따른 종류
- CPU 이용률을 최소화
- 오버헤드를 최소화
- 모든 프로세스에게 공평 분배
2️⃣ 선점 스케줄링 (Preemptive Scheduling)
OS가 나서서 CPU 사용권을 선점하고, 특정요건에 따라 각 프로세스의 요청이 있을 때 프로세스에 분배하는 방식
- 가장 자원이 필요한 프로세스에게 CPU를 분배하고, 상황에 따라 강제로 회수할 수도 있음
- 빠른 응답시간을 요하는 대화식 시분할 시스템에 적합
📌 Priority Scheduling (우선순위 스케줄링)
- 정적/동적으로 우선순위를 부여 → 우선순위가 높은 순서대로 처리함
- 우선순위가 낮은 프로세스가 무한정 기다리는 기아현상(Starvation) 발생 가능
- 노화(Aging) 방법으로 기아현상 해결 가능
- 기다리는 시간에 따라 우선순위를 증가시켜주는 방식
- 우선순위가 같으면 FCFS(First Come, First Serve) 적용
📌 Round Robin (라운드로빈)
- FCFS에 의해 프로세스들이 보내지면 각 프로세스들 사이에 우선순위를 두지 않고, 순서대로 시간단위(Time Quantum)로 CPU를 할당
- 정해진 시간 할당량 만큼 프로세스를 실행한 뒤, 작업이 끝난 프로세스는 준비완료 큐(순환 큐)의 가장 마지막에 가서 재할당을 기다림 → 회전식
- 너주 잦은 회전은 빈번한 문맥전환이 발생하고, 너무 긴 회전은 FCFS와 다를 바 없음 → 적절한 시간 할당량이 중요함
📌 Multilevel-Queue (다단계 큐)
- 준비완료 큐를 여러개로 분류해 각 큐가 각각 다른 스케줄링 알고리즘을 가지는 방식
- 메모리크기, 우선순위, 유형 등 프로세스 특성에 따라 하나의 큐에 영구적으로 할당됨
<Queue와 Queue사이의 스케줄링>
- 고정 우선순위와 선점형 방식으로 구현
- 우선순위에 따른 큐의 스케줄링은 절대적임
1. 우선순위가 높은 Forground Queue
> 대화형 프로세스를 위한 큐
> Round Robin
2. 우선순위가 낮은 Background Queue
> 연산작업을 처리하는 프로세스 큐
> FCFS
→ Forground Queue가 비어있지 않는 한 Background Queue는 먼저 실행될 수 없음
→ Background Queue가 먼저 실행중이더라도 Forground Queue에 프로세스가 들어오면 선점됨3️⃣ 비선점 스케줄링 (Non-Preemptive Scheduling)
프로세스 종료 or I/O 등 이벤트가 있을 때까지 실행보장 (처리시간 예측 용이)
- 어떤 프로세스가 CPU를 할당받으면 그 프로세스가 종료되거나, 입출력 요구가 발생하여 자발적으로 중지될 때까지 계속 실행되도록 보장하는 방법
- 순서대로 처리되는 공정성이 있음
- 다음에 처리해야할 프로세스와 상관없이 응답시간을 예상할 수 있음
- 선점방식보다 스케줄러 호출 빈도가 낮음 + 문맥교환에 의한 오버헤드가 적음
- CPU 사용시간이 긴 프로세스가 다른 프로세스들을 대기시킬 수 있어 처리율이 떨어질 수 있다
- 일괄처리시스템에 적합함
📌 FCFS (First Come, First Serve)
- 큐에 도착한 순서대로 CPU 할당
- 실행시간이 짧은 프로세스가 뒤로 가면 평균 대기시간이 길어짐 → Convoy Effect(호위효과) 발생
- FIFO(선입선출) Queue를 이용해 구현함
- 먼저 도착한 프로세스의 버스트타임에 따라 평균 대기시간의 편차가 크다
📌 SJF (Shorted Job First)
- 버스트타임이 짧다고 판단되는 작업을 먼저 수행함
- FCFS보다 평균 대기 시간 감소, 짧은 작업에 유리
- 버스트타임이 동일할 경우 FCFS 방식으로 진행
📌 HRN (Highest Response-ratio Next)
- 우선순위를 계산하여 점유 불평등 보완 → SJF 단점 보완
- 우선순위 = (대기시간 + 실행시간) / (실행시간)
4️⃣ 스케줄링 동작시점
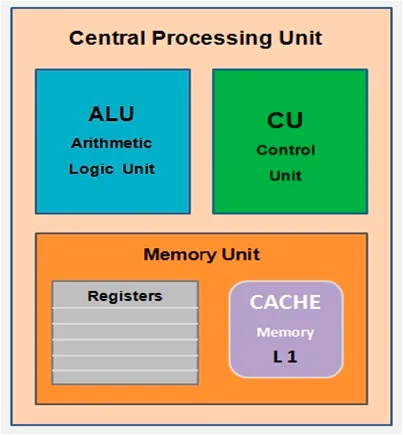
프로세스의 상태변화와 스케줄링 : 스케줄링 알고리즘에 따라 프로세스들은 상태변화가 일어나며 준비/수행 상태일때 CPU를 사용함
📌 프로세스 상태 및 동작
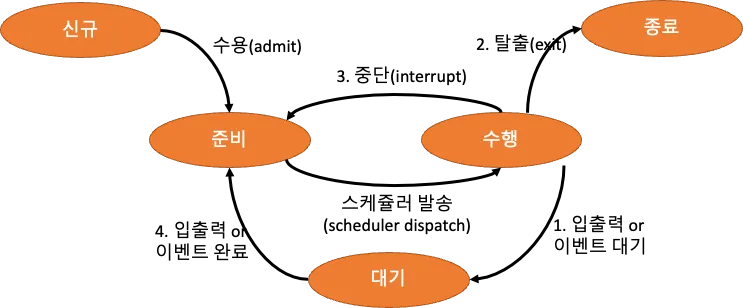
- ① 수행 → 대기 : I/O 요청이 발생하거나, 자식 프로세스가 종료대기를 할 때
- ② 수행 → 종료 : 프로세스가 종료되었을 때
- ③ 수행 → 준비 : 인터럽트(실행 중 I/O 등 예외상황)가 발생했을 때
- ④ 대기 → 준비 : I/O가 완료되었을 때
📌 비선점 스케줄링
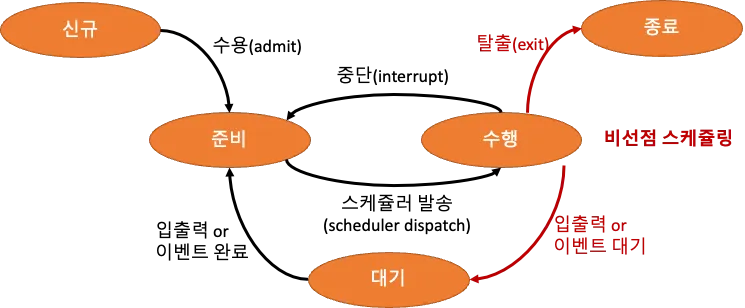
- ①, ②는 프로세스가 스스로 CPU를 반환하기에 비선점 스케줄링
📌 선점 스케줄링
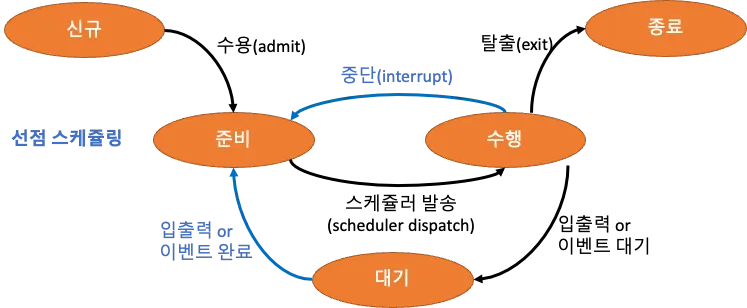
- ③, ④는 프로세스에서 CPU를 강제로 할당(회수)해야 하므로 선점 스케줄링
📌 Example
카카오톡 메세지를 보내기 위해 메세지 창을 켜면 카카오톡 프로세스는 신규 > 준비 상태가 됨.
1. 준비 (Ready) 상태:
1. 카카오톡을 띄워서 메시지를 입력하고 있을 때, 해당 프로세스는 준비 상태.
2. CPU 스케줄링 알고리즘은 준비 상태의 프로세스 중에서 CPU를 할당할 프로세스를 선택.
3. 이때, 선택하는 선점 알고리즘에 따라 우선순위, 라운드 로빈 등 다양한 방식이 있을 수 있음.
2. 대기 (Waiting) 상태:
1. 카카오톡이 비활성화 되어있거나, 가만히 상대방의 답장을 기다릴때 대기 상태가 됨.
2. 해당 프로세스는 대기 상태로 변경되면서 수행중 이었다면 CPU를 반납.
3. CPU 스케줄링 알고리즘은 다른 준비 상태의 프로그램(프로세스)를 선택하여 CPU를 할당할 수 있음.
3. 수행 (Running) 상태
1. 사용자가 메시지를 발송하거나 상대방의 메시지를 수신할때 수행 상태가 됨.
2. CPU 가 준비 상태의 프로세스에 명령을 보내면, 해당 프로세스는 수행 상태로 변경됨.
3. CPU 스케줄링 알고리즘은 실행 시간을 제어하며, 일정 시간이 지나면 해당 프로세스를 중단하고 실행 대기 상태의 다른 프로세스를 선택할 수 있음.
4. 종료 (Terminated) 상태:
1. 카카오톡 프로그램을 종료하면 해당 프로세스는 중지 상태로 변경됨.
2. 이때, CPU 스케줄링 알고리즘은 다른 실행 대기 상태의 프로세스를 선택하여 CPU를 할당할 수 있음.2. 메모리 심화
1️⃣ 캐시
캐시는 데이터를 미리 복사해 놓는 임시 저장소를 뜻함
- 빠른 장치와 느린 장치에서 속도 차이에 따른 병목현상을 줄이기 위한 메모리
- 데이터 접근에 오래 걸리는 경우를 해결하고, 다시 계산하는 시간을 절약
| 구분 | 역할 |
|---|---|
| CPU > 레지스터 | - 메모리와 CPU 사이의 속도차이를 해결하기 위한 캐시 |
| 주기억장치(메인메모리) | - 캐시메모리와 보조기억장치(하드디스크) 사이의 속도 차이를 해결하기 위한 캐시 |
📌 우리가 보는 화면에 출력된 데이터는 모두 메인메모리(주기억장치)에 저장된 데이터
1. 프로그램이 실행되면 하드디스크를 읽어 메인메모리에 복사해두고
2. CPU(MMU)가 메인메모리에서 데이터를 읽어오며 작업을 처리함
3. 이때 캐시가 한번 더 메인메모리의 데이터를 복사해둠
→ CPU(MMU) <-> (캐시) <-> 메인메모리 <-> 하드디스크2️⃣ 지역성의 원리
지역성이란 자주 사용되는 데이터의 특성을 의미함
캐시를 직접 설정할 때 자주 사용되는 데이터를 기반으로 설정해야 하며, 이러한 특성을 캐시의 지역성이라고 함
📌 시간 지역성
- 최근 사용한 데이터에 다시 접근하려는 특성
→ i는 반복문 안에서 계속 접근이 이뤄지는 변수. 최근에 사용했기 때문에 계속 접근하여 +1이 이루어짐
for (int i = 0; i < arr.length; i++) {
answer += arr[i];
}📌 공간 지역성
- 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하려는 특성
→ 배열의 공간에 i가 연속적으로 할당되어 접근하는 방식
int[] intArr = new int[5];
for (int i = 0; i < intArr.length; i++) {
intArr[i] += i;
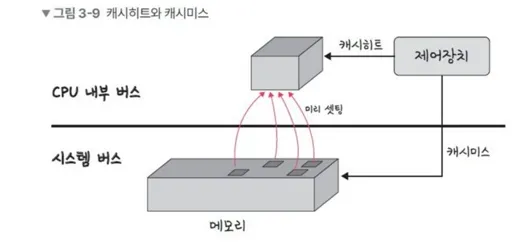
}3️⃣ 캐시히트와 캐시미스
📌 캐시히트
- 캐시에서 원하는 데이터를 찾은 것
- 캐시히트의 경우 데이터를 제어장치(CU)에서 가져오게 됨
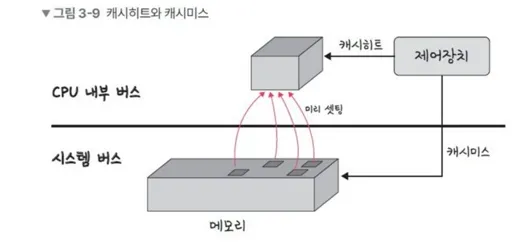
📌 캐시미스
- 캐시에 원하는 데이터가 없는 경우, 메인메모리로 가서 데이터를 찾아옴
- 메인메모리로 가기 위해 시스템 버스를 기반으로 작동하기 때문에 속도가 느림
📌 캐시매핑
- 캐시가 히트되기 위해 매핑되는 방법
- CPU의 레지스터와 메인메모리(RAM) 간에 데이터를 주고 받을 때를 기반으로 함
- 메인메모리에 비해 굉장히 작은 레지스터가 캐시 계층으로써 역할 (매핑 중요)
① 직접매핑
- 메모리가 1~100이 있고, 캐시가 1~10이 있다면 1 : 1~10, 2 : 1~20와 같이 매핑
- 처리가 빠르지만 충돌 발생이 잦음
② 연관매핑
- 순서를 일치하지 않고 관련있는 캐시와 메모리를 매핑
- 충돌이 적지만 모든 블록을 탐색하여 속도가 느림
③ 집합연관매핑
- 직접매핑 + 연관매핑
- 순서는 일치하지만 집합을 둬서 저장하며 블록화되어 있어 검색이 효율적임4️⃣ 메모리 할당
메모리에 프로그램을 할당할 때 시작메모리 위치, 메모리의 할당 크기를 기반으로 할당함
📌 연속할당
- 메모리에 연속적으로 공간을 할당함
| 방식 | 내용 | 단점 |
|---|---|---|
| 고정분할방식 | - 메모리를 미리 사전에 나누어 관리하는 방식 | - 내부 단편화 발생 문제 O |
| 가변분할방식 | - 매 시점 프로그램의 크기에 맞게 동적으로 메모리를 나눠 사용하는 방식 - 최초적합 : 위에서부터 바로 보이는 공간에 바로 할당 - 최적적합 : 가장 크기에 맞는 공간부터 채우고 나머지를 할당 - 최약적합 : 가장 크기가 큰 공간부터 채우고 나머지 할당 | - 외부 단편화 발생 문제 O |
💡 내부단편화
- 메모리를 나눈 크기보다 프로그램이 작아서 들어가지 못하는 공간이 많이 발생하는 현상
- 들어갈 수 있는 공간보다 프로그램이 작아서 공간이 남는 것
💡 외부단편화
- 메모리를 나눈 크기보다 프로그램이 커서 들어가지 못하는 공간이 많이 발생하는 현상
- 들어갈 공간보다 들어갈 프로그램이 더 커서 들어가지 못하고 남아버리는 것📌 불연속할당
- OS는 여러개의 작업을 효율적으로 수행하기 위해 불연속할당 방법을 사용함
- 메모리 공간 할당/해제 시, 오버헤드가 발생할 수 있음 (과한 자원 사용)
- 메모리 공간이 분산되어 있기 때문에, 프로세스의 페이지 교체와 같은 작업이 더 복잡해질 수 있음
| 방법 | 내용 |
|---|---|
| 링크드 리스트 | - 불연속 공간에 프로세스를 할당할 때, 할당된 공간의 주소를 연결 리스트에 저장 - 메모리 할당/해제의 속도는 빠르나, 공간낭비가 발생할 수 있음 |
| 비트맵 | - 메모리 공간의 각 블록을 0 또는 1로 표시해 사용 가능/불가능 블록을 구분하는 방식 - 링크드 리스트보다 효율적인 공간관리를 제공하지만, 메모리 크기가 큰 경우 피트맵이 매우 커질 수 있음 |
| 페이지테이블 | - 가상 메모리 시스템에서 사용되는 방식으로, 물리적인 주소공간을 페이지라는 작은 블록으로 나누어 사용 - 각 프로세스는 고유의 페이지테이블을 가지고, 페이지 테이블은 물리적인 주소와 가상 주소를 매핑하는 역할을 함 - 가장 효율적인 방법 |

🐰 I'm Sunyeon-Jeong, mallang