📗HDFS 개요
HDFS(Hadoop Distributed File System)는 대규모 데이터를 저장하고 관리하기 위한 분산 파일 시스템으로, Hadoop 에코시스템의 핵심 구성 요소 중 하나다.
HDFS는 클러스터의 여러 노드에 데이터를 분산 저장하여 확장성, 내결함성, 높은 처리량을 제공하는 파일 시스템이다. 주로 빅데이터 처리에 최적화되어 있어 대량의 데이터를 저장하고 분석하는 데 사용된다.
🏳️🌈 [궁금한점]
- HDMS는 파일 시스템과 어떤 차이가 있나
- HDMS의 동작방식
🔗[목차]
구성 요소
HDFS는 크게 NameNode와 DataNode로 구성된다.
NameNode
- 파일 시스템의 메타데이터(파일의 위치, 블록 정보 등)를 관리
- 데이터의 저장 위치를 트래킹하지만 실제 데이터를 저장하지 않음
- 단일 장애점(SPOF, Single Point of Failure)이 될 수 있어 HA(High Availability) 구성이 필요
DataNode
- 실제 데이터를 블록 단위로 저장
- 주기적으로 NameNode에 상태 정보를 보고
- 여러 개의 DataNode가 데이터 복제본(Replication)을 유지하여 내결함성 제공
hdfs 정상 설치 확인 방법
hadoop fs -ls /
hadoop fs -ls / 명령어 수행 시 결과가 ls / 의 것과 다르다.
root@86f09ef0495f:/usr/local/hadoop# hadoop fs -ls /
Found 2 items
drwxr-xr-x - root supergroup 0 2025-04-05 09:02 /test_out
drwxr-xr-x - root supergroup 0 2025-04-05 09:01 /user
root@86f09ef0495f:/usr/local/hadoop# ls /
bin dev home lib32 libx32 mnt proc run srv tmp var
boot etc lib lib64 media opt root sbin sys usr파일 시스템 설정 확인
hdfs 명령어가 작동하나 파일 시스템을 hdfs 이 아닌 로컬 파일 시스템을 쓰는 경우가 있다.
- 하둡
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode:9000</value>
</property>- 파일 시스템
<property>
<name>fs.defaultFS</name>
<value>file:///</value>
</property>아래 명령어로 파일 시스템 설정을 확인한다.
root@86f09ef0495f:/usr/local/hadoop# hdfs getconf -confKey fs.defaultFS
hdfs://0.0.0.0:9000
root@86f09ef0495f:/usr/local/hadoop# grep -A1 '<name>fs.defaultFS</name>' $HADOOP_HOME/etc/hadoop/core-site.xml
<name>fs.defaultFS</name>
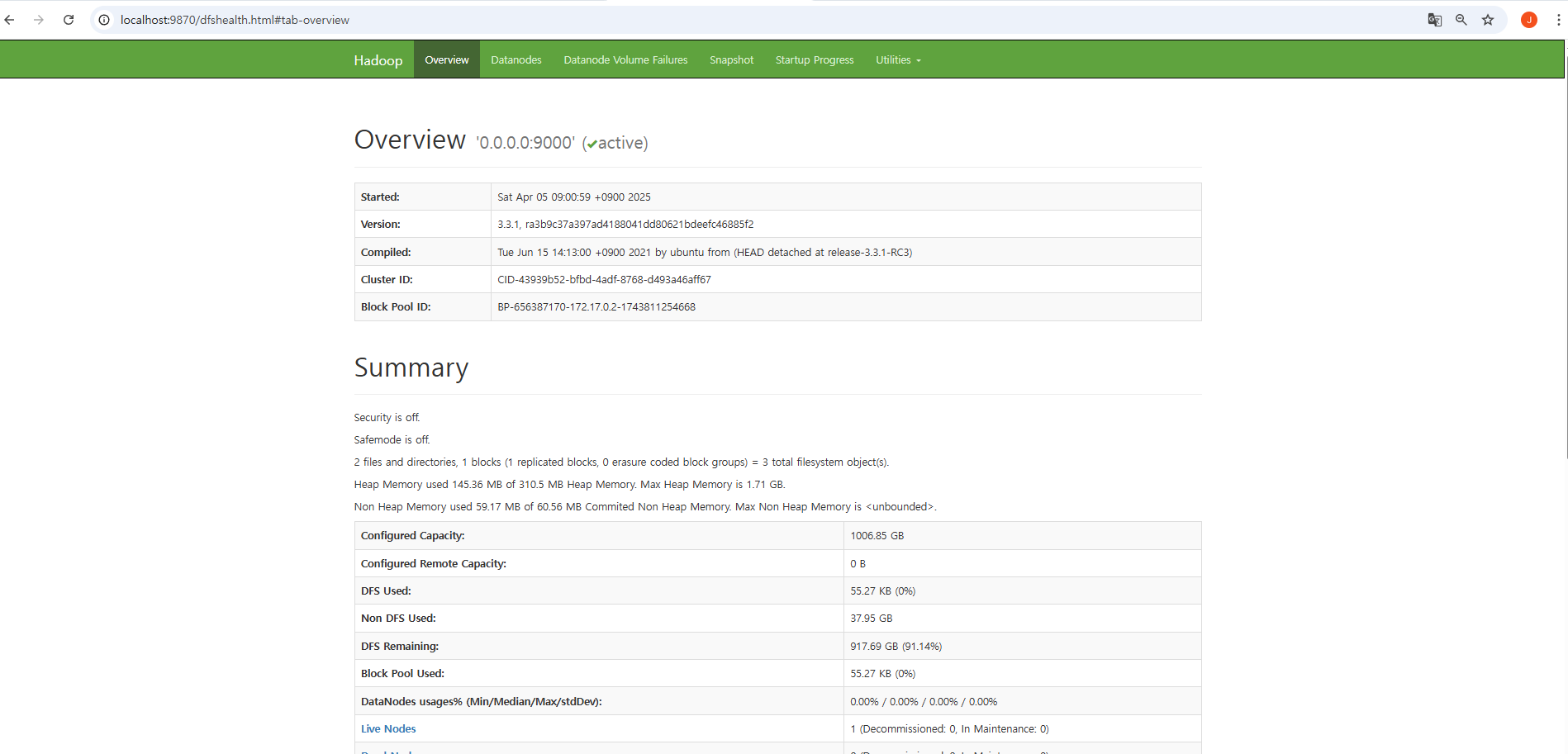
<value>hdfs://0.0.0.0:9000</value>웹콘솔 확인
http://localhost:9870 실행 시 웹콘솔 작동하는 지 확인한다.
명령어 활용
몇가지 명령어를 날려 hdfs 작동 여부를 확인할 수 있다.
root@86f09ef0495f:/usr/local/hadoop# hdfs dfs -stat /
2025-04-05 00:02:08hdfs 에 파일을 업로드 해본다.
echo "hello" > test.txt
hdfs dfs -put test.txt /
hdfs dfs -ls /파일 시스템 확인을 위해 alias 를 만들어 두고 사용하면 편리하다.
root@86f09ef0495f:/usr/local/hadoop# alias checkfs='hdfs getconf -confKey fs.defaultFS'
root@86f09ef0495f:/usr/local/hadoop# checkfs
hdfs://0.0.0.0:9000HDMS
HDMS 특징
-
파일 블록(Block) 단위 저장
-
- HDFS는 큰 파일을 기본 128MB 또는 256MB 크기의 블록으로 나누어 저장
-
- 여러 개의 DataNode에 분산 저장하여 병렬 처리가 가능
-
복제(Replication) 메커니즘
-
- 기본적으로 데이터 블록을 3개 복제(Replication Factor = 3)
-
- 노드 장애 발생 시 다른 복제본을 활용하여 데이터 손실을 방지
-
쓰기 한번, 읽기 여러 번(Read-Optimized)
-
- HDFS는 데이터 수정보다는 한 번 저장하고 주로 읽는(Read-heavy) 워크로드에 최적화
-
- 데이터 변경이 필요할 경우 전체 파일을 다시 써야 함
-
스트리밍 데이터 처리에 최적화
-
- 한 번에 대용량 데이터를 읽고 처리하는 방식에 강점
-
- 작은 파일을 많이 다루는 경우에는 성능이 좋지 않음
동작 방식
-
파일 저장
-
- 클라이언트가 파일을 업로드하면 NameNode가 블록을 나누고 각 블록의 저장 위치를 결정
-
- DataNode에 분산 저장하며, 복제본을 자동 생성
-
파일 읽기
-
- 클라이언트가 요청하면 NameNode가 파일 블록의 위치를 알려줌
-
- 클라이언트가 직접 해당 DataNode에서 데이터를 읽어옴
-
장애 처리
-
- DataNode 장애 발생 시 NameNode가 자동으로 다른 복제본을 활용
-
- 복제본 개수가 부족하면 자동으로 새로운 복제본을 생성
Hadoop JDK 지원
| Hadoop 버전 | 권장 JDK 버전 | 지원 여부 |
|---|---|---|
| 3.4.x (최신) | JDK 11, JDK 17 | 공식 지원 (JDK 21은 실험적) |
| 3.3.x | JDK 8, JDK 11 | JDK 8 기본, JDK 11은 일부 기능 제한 |
| 3.2.x | JDK 8 | 안정적 지원 |
| 3.1.x | JDK 8 | 안정적 지원 |
| 3.0.x | JDK 8 | 지원됨 |
| 2.10.x | JDK 7, JDK 8 | JDK 8 권장, JDK 7 일부 지원 |
| 2.7.x ~ 2.9.x | JDK 7 | 제한적 지원, 오래됨 |
HDFS 명령어
| 명령어 | 설명 | 예제 |
|---|---|---|
| 파일 및 디렉토리 작업 | ||
hdfs dfs -ls <경로> | 디렉토리 목록 조회 | hdfs dfs -ls /input |
hdfs dfs -mkdir <경로> | 디렉토리 생성 | hdfs dfs -mkdir /data |
hdfs dfs -rmdir <경로> | 디렉토리 삭제(비어 있어야 함) | hdfs dfs -rmdir /empty_dir |
hdfs dfs -rm -r <경로> | 파일 또는 디렉토리 강제 삭제 | hdfs dfs -rm -r /data |
| 파일 조작 | ||
hdfs dfs -put <로컬파일> <HDFS경로> | 로컬 파일을 HDFS에 업로드 | hdfs dfs -put test.txt /data/ |
hdfs dfs -copyFromLocal <로컬파일> <HDFS경로> | -put과 동일 | hdfs dfs -copyFromLocal test.txt /data/ |
hdfs dfs -get <HDFS파일> <로컬경로> | HDFS 파일을 로컬로 다운로드 | hdfs dfs -get /data/test.txt . |
hdfs dfs -copyToLocal <HDFS파일> <로컬경로> | -get과 동일 | hdfs dfs -copyToLocal /data/test.txt . |
hdfs dfs -cat <파일> | 파일 내용 출력 | hdfs dfs -cat /data/test.txt |
hdfs dfs -tail <파일> | 파일 끝부분 출력 | hdfs dfs -tail /data/log.txt |
hdfs dfs -text <파일> | 압축된 파일을 텍스트로 출력 | hdfs dfs -text /data/compressed.gz |
| 파일 권한 및 소유권 | ||
hdfs dfs -chmod <모드> <파일> | 파일/디렉토리 권한 변경 | hdfs dfs -chmod 755 /data/test.txt |
hdfs dfs -chown <사용자>:<그룹> <파일> | 파일 소유자 변경 | hdfs dfs -chown hadoop:supergroup /data/test.txt |
hdfs dfs -chgrp <그룹> <파일> | 그룹 변경 | hdfs dfs -chgrp supergroup /data/test.txt |
| 디스크 사용량 및 상태 확인 | ||
hdfs dfs -du -s <경로> | 디스크 사용량 확인 | hdfs dfs -du -s /data |
hdfs dfs -count <경로> | 파일 개수 및 용량 확인 | hdfs dfs -count /data |
hdfs dfs -df -h | 전체 HDFS 디스크 사용량 확인 | hdfs dfs -df -h |
hdfs dfs -stat <옵션> <파일> | 파일 정보 출력 | hdfs dfs -stat %b /data/test.txt |
| 파일 복제 및 이동 | ||
hdfs dfs -mv <원본> <대상> | 파일 이동 및 이름 변경 | hdfs dfs -mv /data/test.txt /backup/ |
hdfs dfs -cp <원본> <대상> | 파일 복사 | hdfs dfs -cp /data/test.txt /backup/ |
| 기타 유용한 명령어 | ||
hdfs dfsadmin -report | HDFS 클러스터 상태 확인 | hdfs dfsadmin -report |
hdfs namenode -format | HDFS 포맷 (최초 1회) | hdfs namenode -format |
hdfs dfs -help | HDFS 명령어 도움말 | hdfs dfs -help |
데이터 물리적 위치 확인
hdfs dfs -ls 명령어는 논리적인 경로만 보여주고, 실제 데이터가 어느 DataNode에 저장되어 있는지(물리적 위치)는 보여주지 않는다.
root@86f09ef0495f:/usr/local/hadoop# hadoop fs -ls /
Found 1 items
-rw-r--r-- 3 root supergroup 6 2025-04-05 09:30 /test.txtHDFS의 블록 위치와 DataNode 정보는 아래 명령어를 이용해 확인이 가능하다.
hdfs fsck /test.txt -files -blocks -locationsroot@86f09ef0495f:/usr/local/hadoop# hdfs fsck /test.txt -files -blocks -locations
Connecting to namenode via http://0.0.0.0:9870/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Ftest.txt
FSCK started by root (auth:SIMPLE) from /172.17.0.2 for path /test.txt at Sat Apr 05 09:51:01 KST 2025
/test.txt 6 bytes, replicated: replication=3, 1 block(s): Under replicated BP-656387170-172.17.0.2-1743811254668:blk_1073741827_1003. Target Replicas is 3 but found 1 live replica(s), 0 decommissioned replica(s), 0 decommissioning replica(s).
0. BP-656387170-172.17.0.2-1743811254668:blk_1073741827_1003 len=6 Live_repl=1 [DatanodeInfoWithStorage[172.17.0.2:9866,DS-52e75ec5-048b-46f6-a8d8-f187440106f9,DISK]]
Status: HEALTHY
Number of data-nodes: 1
Number of racks: 1
Total dirs: 0
Total symlinks: 0
Replicated Blocks:
Total size: 6 B
Total files: 1
Total blocks (validated): 1 (avg. block size 6 B)
Minimally replicated blocks: 1 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 1 (100.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 1.0
Missing blocks: 0
Corrupt blocks: 0
Missing replicas: 2 (66.666664 %)
Blocks queued for replication: 0
Erasure Coded Block Groups:
Total size: 0 B
Total files: 0
Total block groups (validated): 0
Minimally erasure-coded block groups: 0
Over-erasure-coded block groups: 0
Under-erasure-coded block groups: 0
Unsatisfactory placement block groups: 0
Average block group size: 0.0
Missing block groups: 0
Corrupt block groups: 0
Missing internal blocks: 0
Blocks queued for replication: 0
FSCK ended at Sat Apr 05 09:51:01 KST 2025 in 6 milliseconds
The filesystem under path '/test.txt' is HEALTHY권한 체계
Hadoop에서 파일 및 디렉토리에 대한 접근 제어는 Linux 스타일의 사용자-그룹-권한 모델을 따르며, supergroup은 이 구조에서 슈퍼유저 그룹(관리자 그룹) 역할을 한다.
Hadoop의 권한 시스템은 크게 다음 세 가지 구성요소를 기반으로 한다
| 구성요소 | 설명 |
|---|---|
| 사용자 (User) | 파일/디렉토리의 소유자. |
| 그룹 (Group) | 해당 사용자가 속한 그룹. |
| 권한 (Permission) | 사용자/그룹/기타 사용자에 대한 r(read), w(write), x(execute) 권한. |
이는 리눅스의 권한 체계(chmod, chown, chgrp)와 거의 동일하다.
supergroup
supergroup은 Hadoop 클러스터의 관리자 그룹 이름이다. 이 그룹에 속한 사용자는 HDFS의 모든 권한을 무시하고 접근 가능하다. 기본 설정에서 hdfs 사용자는 supergroup에 포함되어 있고, NameNode를 실행한 사용자도 일반적으로 포함된다.
기본 설정에서는 supergroup이 그룹 이름이지만, core-site.xml에서 바꿀 수도 있다.
- supergroup의 위치 및 변경
- 설정 파일: hdfs-site.xml
<property>
<name>dfs.permissions.superusergroup</name>
<value>supergroup</value>
</property>여기서 값을 admin, rootusers 등 다른 이름으로 바꾼 후 NameNode 재시작 한다.
용량 관리
총 파일 크기 계산
파일의 실제 바이트 크기(복제 고려 X) 확인
root@86f09ef0495f:/usr/local/hadoop# hdfs dfs -stat %b /test.txt
6복제(replication)를 반영한 실제 디스크 사용량
root@86f09ef0495f:/usr/local/hadoop# hdfs dfs -du -s -h /test.txt
6 18 /test.txt복제 정보 확인
파일이 몇개로 복제되었는 지 확인
root@86f09ef0495f:/usr/local/hadoop# hdfs dfs -stat %r /test.txt
3파일 크기와 복제 수 확인
root@86f09ef0495f:/usr/local/hadoop# hdfs dfs -ls /test.txt
-rw-r--r-- 3 root supergroup 6 2025-04-05 09:30 /test.txt전체 파일 시스템 디폴트 블록 크기와 복제 수
hdfs getconf -confKey dfs.blocksize
hdfs getconf -confKey dfs.replication
root@86f09ef0495f:/usr/local/hadoop# hdfs getconf -confKey dfs.replication
3데이터노드 수 확인
root@86f09ef0495f:/usr/local/hadoop# hdfs dfsadmin -report
Configured Capacity: 1081101176832 (1006.85 GB)
Present Capacity: 985356812288 (917.69 GB)
DFS Remaining: 985356767232 (917.69 GB)
DFS Used: 45056 (44 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 1
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 1
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 172.17.0.2:9866 (86f09ef0495f)
Hostname: 86f09ef0495f
Decommission Status : Normal
Configured Capacity: 1081101176832 (1006.85 GB)
DFS Used: 45056 (44 KB)
Non DFS Used: 40752009216 (37.95 GB)
DFS Remaining: 985356767232 (917.69 GB)
DFS Used%: 0.00%
DFS Remaining%: 91.14%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Sat Apr 05 10:08:26 KST 2025
Last Block Report: Sat Apr 05 09:01:02 KST 2025
Num of Blocks: 1복제 수 설정 방법
- hdfs-site.xml 설정 (전역)
<property>
<name>dfs.replication</name>
<value>3</value> <!-- 기본은 3 -->
</property>- 파일/디렉토리 단위 설정
hdfs dfs -setrep -w 2 /test.txt-w: replication 완료될 때까지 대기
- 업로드 시 바로 설정
hdfs dfs -Ddfs.replication=2 -put test.txt /test.txt베스트 프랙티스
| 상황 | 권장 복제 계수 |
|---|---|
| 테스트 환경 (단일 노드) | 1 |
| 소규모 개발 환경 (2~3노드) | 2 또는 3 |
| 운영 환경 (3개 이상의 노드) | 3 (기본) |
| 고가용성 요구 (10+ 노드) | 4 이상 (중요 파일만) |
| 백업 용도 / 대용량 읽기 전용 | 2 (공간 절약 목적) |
권장 기준
- 복제 계수 ≤ DataNode 수가 원칙!
- 중요 파일은 -setrep으로 따로 관리.
너무 높은 복제 계수는 디스크 낭비와 네트워크 부하를 초래한다. NameNode Web UI(보통 9870 포트)에서 under-replicated 블록 확인이 가능하다.
setrep
파일을 업로드한 후 복제 계수를 조정하는 방식으로 -setrep을 자주 사용한다. HDFS 공간이 부족할 경우, 덜 중요한 파일의 복제본 수를 줄이는 것도 하나의 전략이다. 설정한 복제 계수가 현재 DataNode 수보다 크면 복제가 되지 않고 under-replicated 상태로 남는다.
DataNode 용량 모니터링
hdfs dfsadmin -report
결과의 DFS Used%: 0.00% 값이 80% 넘으면 용량 고려
| 항목 | 방법 |
|---|---|
| 수동 모니터링 | dfsadmin -report, NameNode Web UI |
| 자동 모니터링 | Prometheus + Grafana + Alertmanager |
| 판단 기준 | 사용률 > 80%, 블록 under-replicated, DataNode 장애 발생 시점 |
| 자동 확장 | Webhook → VM 생성 → Hadoop 설치 및 설정 복사 → DataNode 자동 등록 |
