
📗Minio on windows 10
테스트/개발 목적으로 Windows에서 MinIO를 사용하며 가상 디스크+EC 구조 테스트, API 개발, 간단한 성능 측정이 가능하다. 운영/고성능 목적이라면 최종적으로 Linux 환경에서 다시 검증하는 게 좋다.
(특히 RAID, 디스크 I/O 튜닝, 네트워크 병목 테스트)
🏳️🌈 [궁금한점]
- 테스트 용으로 MinIO를 사용할 때 장점이 무얼까
목차
윈도우 활용 장점
| 항목 | 설명 |
|---|---|
| 빠른 준비 | Windows 설치돼 있으면 별도 OS 설치 없이 바로 MinIO 실행 가능 |
| 가상 디스크 활용 | VHD/VHDX로 손쉽게 다수 드라이브 생성 → EC(Erasure Coding) 테스트에 유리 |
| 관리 도구 풍부 | CrystalDiskMark, Resource Monitor, Process Explorer 등으로 성능/리소스 모니터링이 쉽다 |
| 개발 친화성 | mc(Minio Client), curl, powershell, awscli 등 다양한 툴 바로 설치 가능 |
| 파일 시스템 유연성 | NTFS/exFAT/VHD 파일로 디스크 사이즈나 성능을 빠르게 조정할 수 있다 |
| GUI 환경 지원 | 콘솔을 브라우저로 보면서 파일 올리고 내리기 테스트가 편하다 |
한계점
| 항목 | 설명 |
|---|---|
| 실운영 성능 차이 | Linux에 비해 파일 IO 처리 방식이 달라서 실제 운영환경과 성능이 다를 수 있음 |
| 파일 락 문제 | NTFS 특성 때문에 일부 concurrent write 상황에서 제약이 생길 수 있음 |
| 고급 네트워크 설정 한계 | NIC bonding, jumbo frame 같은 고급 네트워크 설정 테스트가 어려움 |
| 시스템 리소스 | Windows 자체가 백그라운드 서비스가 많아서 리소스 과다 사용 |
프로비저닝 절차
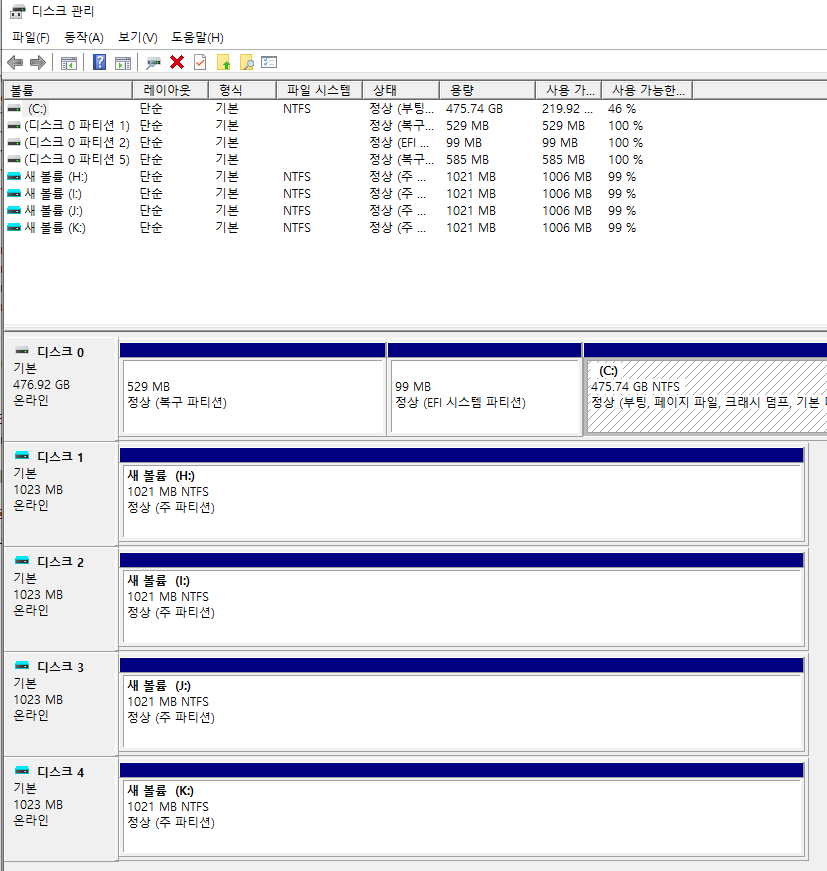
가상 디스크 4개 생성
윈도우 찾기 창에서 diskmgmt.msc 명령을 치고, 가상 디스크 4개를 생성한다.
MinIO 다운로드
https://dl.min.io/server/minio/release/windows-amd64/minio.exeminio.exe 가 117,987 KB 크기로 매우 경량이다.
실행
minio server H:\data I:\data J:\data K:\dataMinIO EC 최소 규칙으로 N개 드라이브 중에서 데이터+패리티 조합으로 사용해서 디스크가 1~2개 고장 나도 살아남도록 한다.
4개면 2+2 방식(데이터2 + 패리티2) 구조이다.
콘솔 접속
http://127.0.0.1:9000
minioadmin/minioadmin
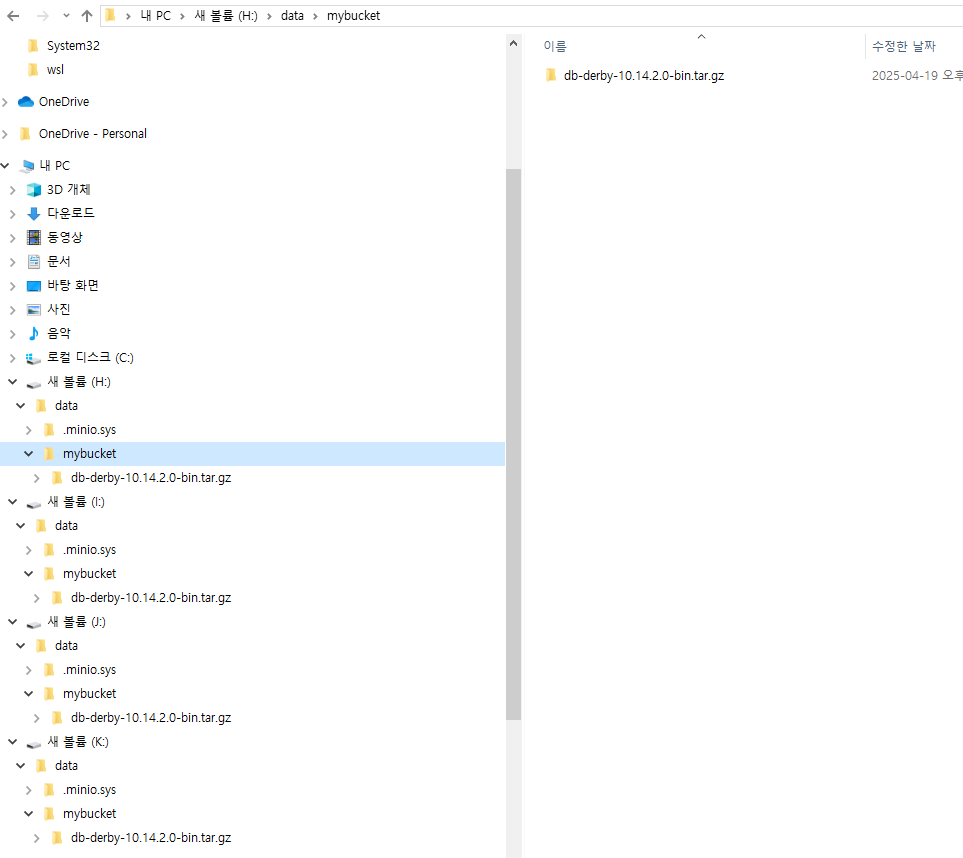
Bucket 생성 후 파일을 업로드 하면 4개의 디스크 모두에 파일이 업로드 된다.
윈도우 용 MC 설치
https://dl.min.io/client/mc/release/windows-amd64/mc.exe성능 확인
| 항목 | 설명 |
|---|---|
| 드라이브 read/write 속도 | 단일 가상 디스크 IO 확인 (CrystalDiskMark 추천) |
| MinIO Throughput | 업로드/다운로드 MB/s 측정 |
| CPU 사용률 | CPU 사용률 확인 |
| 메모리 사용률 | 캐시 세팅했으면 메모리 변동 관찰 |
mc alias set local http://localhost:9000 minioadmin minioadmin
mc mb local/testbucket
fsutil file createnew C:\tmp\bigfile.bin 1073741824 # 1GB 파일 생성
mc cp C:\tmp\bigfile.bin local/testbucket/실행 결과
PS C:\Users\acho> mc mb local/testbucket
Bucket created successfully `local/testbucket`.
PS C:\Users\acho> fsutil file createnew C:\tmp\bigfile.bin 1073741824 # 1GB 파일 생성
C:\tmp\bigfile.bin 파일 작성
PS C:\Users\acho> mc cp C:\tmp\bigfile.bin local/testbucket/
C:\tmp\bigfile.bin: 1.00 GiB / 1.00 GiB [=================================================================] 465.98 MiB/s 2sMinIO 스파크 연계
스파크 설치
sudo apt update
sudo apt install openjdk-11-jdk
tar xvf spark-3.5.5-bin-hadoop3.tgz
echo 'export SPARK_HOME=~/spark-3.5.5-bin-hadoop3' >> ~/.bashrc
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> ~/.bashrc
source ~/.bashrc테스트 소스 생성 (파이썬)
from pyspark.sql import SparkSession
# Spark 세션 생성
spark = SparkSession.builder \
.appName("Read-from-S3A") \
.config("spark.hadoop.fs.s3a.endpoint", "http://172.31.144.1:9000") \
.config("spark.hadoop.fs.s3a.access.key", "minioadmin") \
.config("spark.hadoop.fs.s3a.secret.key", "minioadmin") \
.config("spark.hadoop.fs.s3a.path.style.access", "true") \
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \
.getOrCreate()
path = "s3a://mybucket/"
# 파일 목록 읽기
df = spark.read.format("binaryFile").load(path)
# 파일 경로만 출력
df.select("path").show(truncate=False)결과 확인
spark-submit --packages org.apache.hadoop:hadoop-aws:3.3.4,com.amazonaws:aws-java-sdk-bundle:1.11.1026 h.py+--------------------------------------------+
|path |
+--------------------------------------------+
|s3a://mybucket/db-derby-10.14.2.0-bin.tar.gz|
+--------------------------------------------+
khagor