Provisioning
1.Provisioning, Python

프로비저닝(provisioning)은 IT 인프라에서 필요한 자원(서버, 네트워크, 스토리지, 소프트웨어 등)을 준비하고 배포하는 과정을 의미한다. 이는 물리적, 가상화, 클라우드 환경에서 모두 적용되며, 자동화 도구를 활용하여 효율성을 극대화할 수 있다.프로비저닝을
2.Provisioning, fastapi
FastAPI는 Python 기반의 웹 프레임워크로, API 개발을 빠르고 효율적으로 할 수 있도록 설계되었다. 성능이 뛰어나고, 타입 힌트를 적극적으로 활용하여 코드의 안정성과 가독성을 높일 수 있다.rest api 프레임워크를 fastapi로 선택한 후 필요한 일을
3.Provisioning, Nginx Architecture
NGINX는 가볍고 빠른 웹 서버이자 리버스 프록시, 로드 밸런서, API 게이트웨이 역할을 수행하는 오픈소스 소프트웨어이다. 높은 동시 연결 처리 성능과 비동기 이벤트 기반 아키텍처를 통해 트래픽이 많은 환경에서도 안정적인 서비스를 제공한다.✔ 고성능 웹 서버 정적
4.Provisioning, Nginx reverse proxy
볼륨을 준비하여 정적 리소스가 POD 가 삭제되더라고 유지하도록 처리필수 유틸리티 (curl, vi), 네트워크 확인 도구가 기본 설치된 분석용 이미지를 준비.nginx설정 파일을 컨피그맵에 구성하여 확장 시 동일한 파일을 볼 수 있도록 처리Nginx 이미지 선택 -
5.Provisioning, MetalLB

MetalLB는 Kubernetes 환경에서 LoadBalancer 서비스를 제공하는 오픈소스 네트워크 로드 밸런서이다. 기본적으로 Kubernetes의 LoadBalancer 타입 서비스는 클라우드 환경(GCP, AWS, Azure 등)에서만 동작하는데, MetalL
6.Provisioning, BFF
Backend for Frontend(BFF) 는 특정 프론트엔드(웹, 모바일 앱 등)의 요구사항에 맞게 백엔드를 커스텀하여 제공하는 아키텍처 패턴이다.일반적인 API Gateway는 모든 클라이언트(웹, 모바일, 데스크톱 등)에 대해 동일한 API를 제공하지만, BF
7.Provisioning, Dockerhub
Docker 이미지는 컨테이너 실행을 위한 핵심 요소이며, 이를 효율적으로 관리하려면 중앙화된 저장소(Registry)가 필요하다.중앙 관리: 여러 환경(개발, 스테이징, 운영)에서 동일한 이미지를 쉽게 배포 가능배포 자동화: CI/CD 파이프라인에서 자동으로 이미지를
8.Provisioning, MinIO
MinIO는 고성능의 오픈 소스 객체 스토리지 솔루션으로, Amazon S3와 호환되는 API를 제공한다. 이는 퍼블릭 및 프라이빗 클라우드, 베어메탈 인프라, 오케스트레이션된 환경, 엣지 인프라 등 다양한 환경에 배포할 수 있도록 설계되었다. 데이터 저장 및 관리:
9.Provisioning, Airflow
Apache Airflow는 워크플로우 자동화 및 배치 처리를 위한 오픈소스 도구이다. DAG(Directed Acyclic Graph)를 기반으로 워크플로우를 정의하고, 실행 상태를 모니터링하며, 복잡한 데이터 파이프라인을 손쉽게 관리할 수 있도록 도와준다.복잡한 배
10.Provisioning, tools/git
GitHub의 토큰만 있으면 (사용자 아이디, 패스워드 불필요) 레포지토리 생성, 목록 조회 등의 오퍼레이션을 코드로 진행할 수 있다. REST API를 통해 단위 작업이 가능하고 파이썬 등의 언어로 구현도 가능하다.주로 레포지토리 명과 git clone 시 사용하는
11.Provisioning, Spark / Local
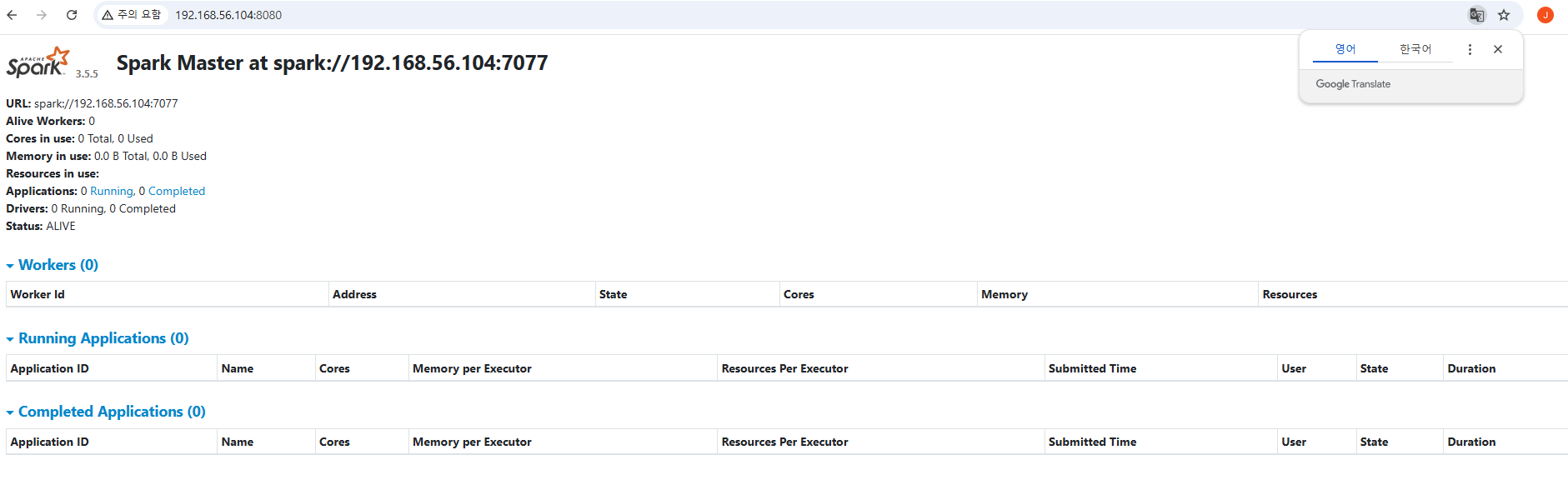
단일 노드(CPU)에서 Spark 애플리케이션 실행하는 형태다. 클러스터 설정 없이 간편하게 Spark 사용 가능하고테스트, 디버깅, 개발 목적에 최적화되어 있다. local\* → CPU 코어 수만큼 쓰레드 실행local1 → 단일 쓰레드 실행자신의 IP 를 정확히
12.Provisioning, Spark / Cluster
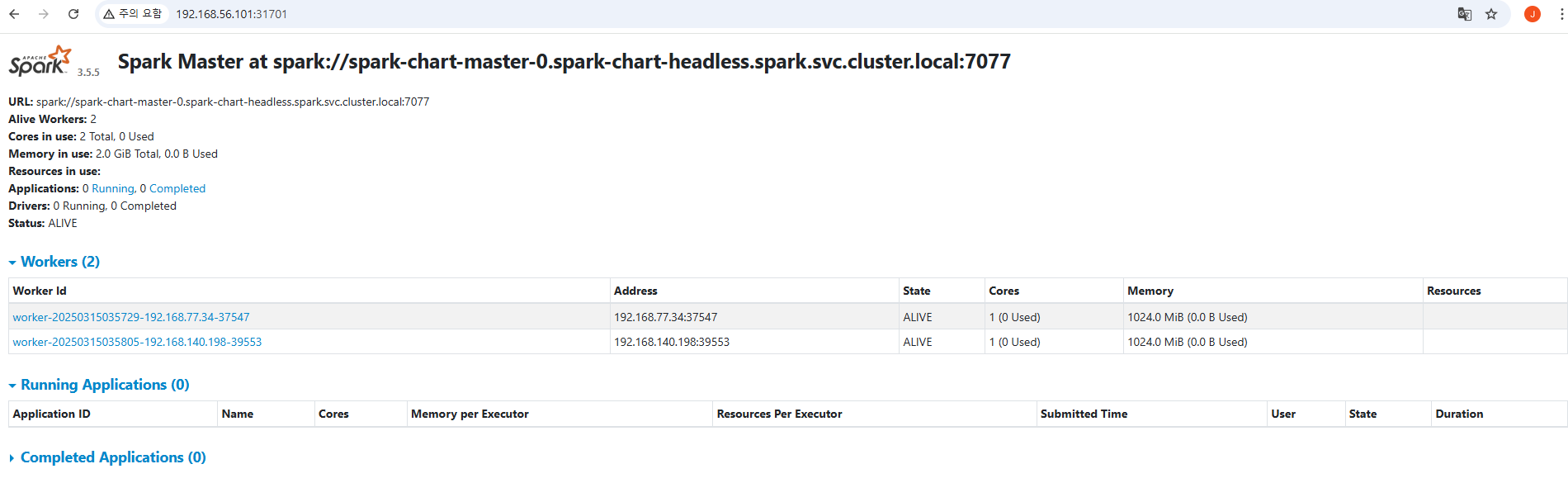
여러 노드를 추가하여 데이터 처리 성능을 높일 수 있음Local 모드는 한 개의 머신의 CPU와 메모리만 사용하지만, 클러스터 모드는 수십~수백 대의 노드가 협업하여 작업을 수행클러스터 모드는 데이터를 분산 저장하고 병렬 처리하여 성능이 뛰어남Local 모드는 단일 머
13.Provisioning, tools / Vagrant
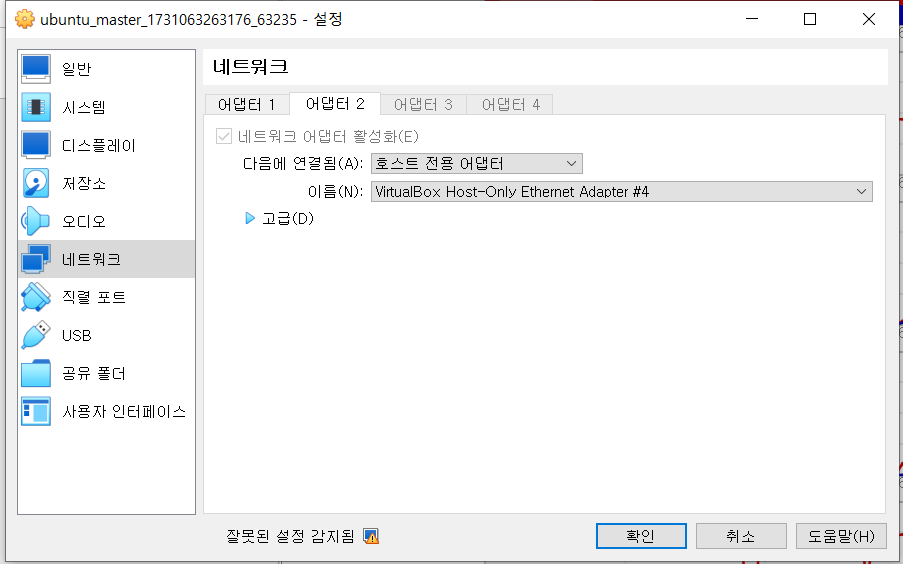
Vagrant는 개발 환경을 코드로 정의하고 쉽게 관리할 수 있도록 도와주는 도구다.명령어 스크립트를 이용해 가상 머신(VM)을 자동으로 생성, 설정, 배포할 수 있다.개발 환경 자동화 → VM 생성, 네트워크 설정, 소프트웨어 설치 등을 자동화다양한 가상화 제공자
14.Provisioning, tools / Ansible
Ansible은 에이전트가 필요 없는 자동화 도구로, IT 인프라 및 애플리케이션 배포를 간소화하는 데 사용된다. SSH 기반으로 원격 서버를 관리하며, YAML 기반의 Playbook을 사용하여 작업을 자동화한다.에이전트리스 (Agentless) → 원격 서버에 별도
15.Provisioning, tools / WSL
WSL(Windows Subsystem for Linux)은 Windows에서 리눅스 환경을 실행할 수 있도록 해주는 기능이다. WSL을 사용하면 가상 머신(VM)이나 듀얼 부팅 없이도 Windows에서 직접 리눅스 명령어와 애플리케이션을 실행할 수 있다. 프로비저닝
16.Provisioning, tools / Docker
Docker는 컨테이너(Container) 기반 가상화 플랫폼으로, 애플리케이션을 격리된 환경에서 실행할 수 있도록 해주는 도구이다. 도커를 통해 개발, 테스트, 배포 환경을 표준화할 수 있다.실행 가능한 애플리케이션과 환경을 포함한 불변(Immutable)한 패키지예
17.Provisioning, HMS (1/3) / Standalone
HiveServer2(HS2)는 기본적으로 Apache Derby를 Metastore DB로 사용한다.하지만 Derby는 기본적으로 싱글 유저 모드(single-user mode) 로 동작하기 때문에 HiveServer2가 실행 중이면 직접 접근이 제한될 수 있다. l
18.Provisioning, HMS (2/3) / HS2 연동
HMS standalone 버전을 이용하지 않고, HMS(메타스토어)와 HS2 를 분리하여 설치하고, 연동시킨다.🏳️🌈 궁금한점HS2, HMS 연동 방법📚 외부문서연결있음📗HMS 프로비저닝, HMS와 HS2 연동 - 도커 환경(- 🔗\[목차](- HS2와
19.Provisioning, HMS (3/3) / PostgreSQL 연동
환경변수로 DB_DRIVER=postgres 설정을 해주어야 기본 Derby 데이터베이스에서 postgresql 에 맞추어진 메타데이터를 자동으로 설치해 준다. 🏳️🌈 궁금한점Derby 대신 PostgreSQL을 이용하는 방법프로비저닝 📗HMS, PostgreS
20.Provisioning, Spark-On-K8s
🏳️🌈 궁금한점Spark를 쿠버네티스에서 구동할 수 있나 설치( - 헬름 REPO 설정( - SPARK-ON-KUBERNETES 설치( - 서비스 어카운트 생성( - 클러스터 롤 바인딩( - 상태 확인( - 오퍼레이터 POD 확인(- 잡 생성( - S
21.Provisioning, MinIO / Windows

테스트/개발 목적으로 Windows에서 MinIO를 사용하며 가상 디스크+EC 구조 테스트, API 개발, 간단한 성능 측정이 가능하다. 운영/고성능 목적이라면 최종적으로 Linux 환경에서 다시 검증하는 게 좋다.(특히 RAID, 디스크 I/O 튜닝, 네트워크 병목
22.Provisioning, Kafka (dev)
🏳️🌈 궁금한점schema-registry 설치 방법 및 테스트 방법kafka 브로커 실행( - 도커를 이용한 kafka 실행 (Standalone)( - Docker Run 명령어 옵션 설명(- kafka 브로커 테스트( - kafka 컨테이너 접속( -
23.Provisioning, Kafka / Schema registry
🏳️🌈 궁금한점schema-registry 설치 방법 및 테스트 방법kafka 브로커 실행( - 도커를 이용한 kafka 실행 (Standalone)( - Docker Run 명령어 옵션 설명(- kafka 브로커 테스트( - kafka 컨테이너 접속( -
24.Architecture, Java
🏳️🌈 궁금한점JAVA 다른 버전 선택 방법JAVA 인증서 처리 방법자바 버전 변경( - pom.xml에서 Maven 컴파일러 설정 변경( - 실제 빌드에 사용될 JDK 설정( - Ubuntu/Linux (update-alternatives 사용 시):(
25.Provisioning, Jenkins/Dev
🏳️🌈 궁금한점Jenkins 설치 방법젠킨스 설치( - 초기 비밀번호 확인( - 패스워드 초기화(- 파이프라인 생성(~/jenkins_home에 Jenkins 설정과 데이터가 저장된다. 컨테이너를 삭제해도 데이터는 유지된다.보안상 주의: 이 구성은 Jenkin
26.Provisioning, Harbor/Dev
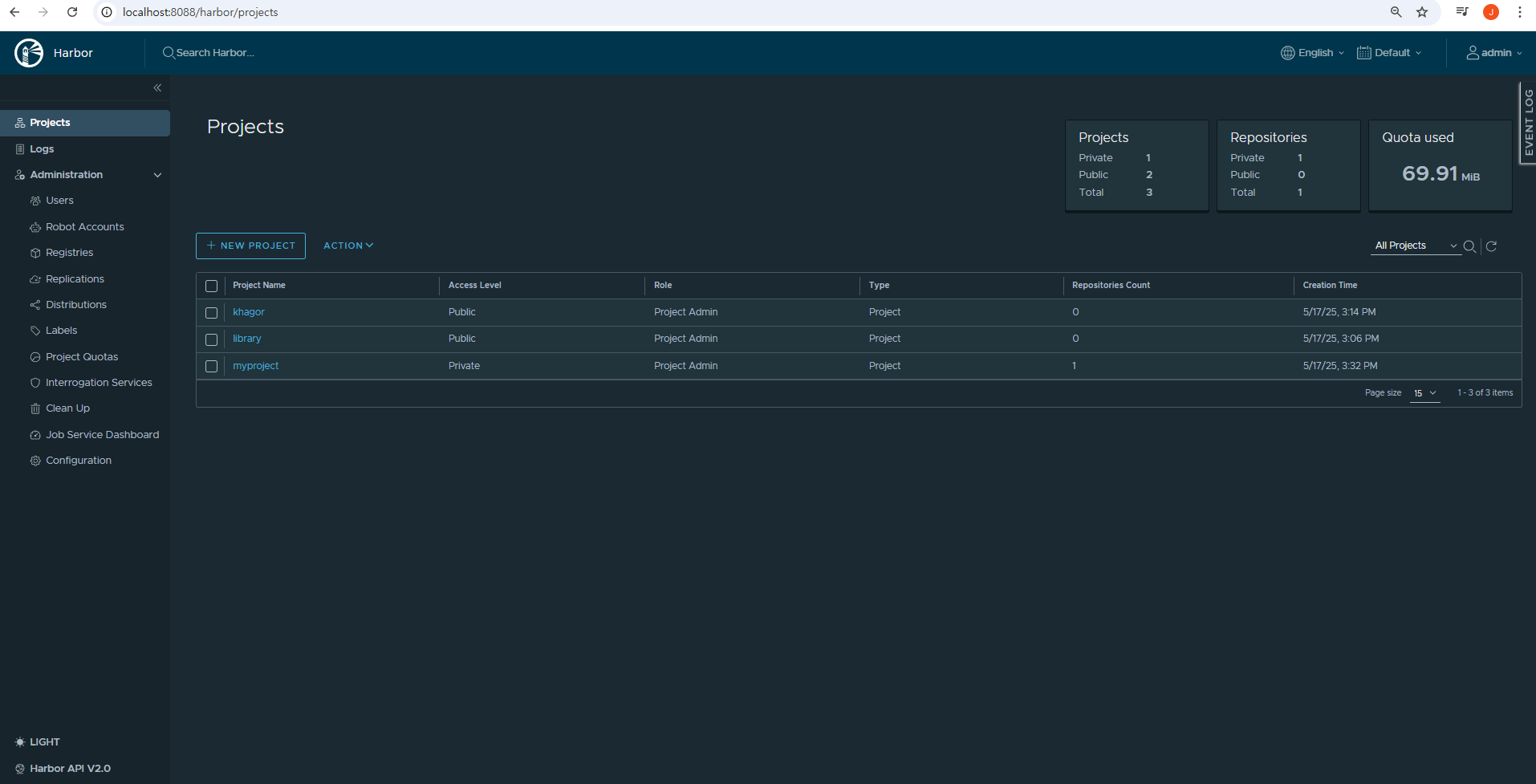
🏳️🌈 궁금한점로컬 환경에 이미지 저장소를 만들어 활용하는 방법Harbor 설치( - 사전준비( - Harbor 설치 파일 다운로드( - harbor.yml 구성( - 관리자 비밀번호( - Harbor 설치 실행( - 접속 확인(- Harbor 이미지
27.Provisioning, Helm
🏳️🌈 궁금한점Helm 개요, 아키텍처Helm 설치( - Helm 일반 설치 ( v3.17.1 )( - Helm 버전 지정 설치 ( v3.8.0 )( - Helm 차트 직접 내려받기(- Helm 릴리즈 관리( - Helm 릴리스 저장 방식( - Helm
28.Provisioning, Heml/Custom Chart
🏳️🌈 궁금한점Helm 직접 만들어 사용하는 방법커스텀 Helm 차트를 사용하는 이유(- Helm 커스텀 차트 생성( - 1. Helm Chart 생성( - 2. Chart.yaml 수정( - 3. values.yaml 설정( - 4. templates/
29.Provisioning, Spark/Custom Helm
🏳️🌈 궁금한점Spark를 쿠버네티스에 설치하기 위한 커스텀 헬름 차트 생성스파크 설치 환경 설정( - 헬름 REPO 설정( - SPARK-ON-KUBERNETES 설치( - Kubectl 설치( - service account 생성( - spark 설치
30.Provisioning, Nginx
🏳️🌈 궁금한점Bitnami 차트를 이용한 Nginx 설치 방법Nginx 설치( - 1️⃣ 준비 - 헬름 차트 다운로드( - 2️⃣ 설정 - 사용자 Values 파일 생성( - 3️⃣ 설치 - Nginx 설치( - 4️⃣ 검증 - 설치 확인( - 리소
31.Provisioning, Nginx ingress controller
🏳️🌈 궁금한점Bitnami 차트를 이용한 Nginx 설치 방법(선행) Nginx 가 서비스로 설치 및 실행되어야 함- Provisioning - Nginx Nginx Ingress Controller 설치( - 1️⃣ 준비( - Nginx Web Serv
32.Provisioning, HMS / Docker
HiveServer2(HS2)는 기본적으로 Apache Derby를 Metastore DB로 사용한다.하지만 Derby는 기본적으로 싱글 유저 모드(single-user mode) 로 동작하기 때문에 HiveServer2가 실행 중이면 직접 접근이 제한될 수 있다. l
33.Provisioning, Spark / Hms
🏳️🌈 궁금한점Hive 4.0.1에 연결하여 Spark로 Query를 날리는 방법 HMS 프로비저닝
34.Provisioning, Trino / K8S
🏳️🌈 궁금한점TRINO K8S 설치(선행) Postgres 가 서비스로 설치 및 실행되어야 함- Provisioning - PostgreSQL Trino 설치( - 1️⃣ 준비( - 헬름 차트 다운로드( - JDK 설치( - Trino CLI
35.Provisioning, PostgreSQL / K8S
🏳️🌈 궁금한점PostgreSQL 설치 방법 (HostPath 방식)PostgreSQL 설치( - 1️⃣ 준비( - PostgreSQL 차트 다운로드( - StorageClass 작성( - PV 구성( - 2️⃣ 설정 - 사용자 Values 파
36.Provisioning, HMS / Docker
🏳️🌈 궁금한점HMS를 MinIO 와 연결하는 방법HMS를 메타 데이터를 PostgreSQL에 저장하고, 데이터는 MinIO에 저장HMS를 도커 이미지로 만드는 방법MinIO 가 실행되어야 한다. 여기서는 엔드 포인트가 http://172.31.144.1
37.Provisioning, DaemonSet / example
🏳️🌈 궁금한점모든 노드에 /tmp/data1 ~ /tmp/data20 까지 폴더 자동 생성 및 관리 방법1️⃣ 준비( - 생성할 폴더 정의(- 2️⃣ 설정( - 데몬셋 정의(- 3️⃣ 설치( - 데몬셋 적용(- 4️⃣ 검증( - hostPath 확인(
38.Provisioning, MinIO / standalone
개발·테스트 목적이면 standalone으로 충분하다. 운영환경에서 고가용성 및 노드 장애 허용이 필요하면 반드시 distributed 모드를 써야 한다. MinIO는 4개 이상의 노드/디스크가 있어야 분산 모드로 작동하며, 내부적으로 erasure coding을 통해
39.Provisioning, Nginx / standalone
최소 구성으로 PV, Ingress 제외하하고 테스트 시 활용. 예를 들어, Nginx Ingress Controller 테스트 시 사용🏳️🌈 궁금한점Nginx bitnami 차트 설치 방법1️⃣ 준비( - Nginx 차트 다운로드(- 2️⃣ 설정( - Ngi
40.Provisioning, Redis / standalone
🏳️🌈 궁금한점PV 용도1️⃣ 준비( - {프로그램명} StorageClass( - {프로그램명} 데이터 디렉토리( - {프로그램명} PV 생성( - {프로그램명} 차트 다운로드(- 2️⃣ 설정( - {프로그램명} 사용자 Values 파일 생성(- 3️⃣
41.Provisioning, PostgreSQL / standalone
🏳️🌈 궁금한점PostgreSQL의 최소한의 스펙으로 설치하는 방법 (하버에서 참조,로컬 테스트용)1️⃣ 준비( - PostgreSQL 차트 다운로드( - StorageClass( - 데이터 디렉토리( - PV(- 2️⃣ 설정 - 사용자 Values 파일
42.Provisioning, Strimzi
🏳️🌈 궁금한점Strimzi를 이용한 Kafka 설치 방법1️⃣ 준비( - Strimzi StorageClass( - Strimzi 데이터 디렉토리( - Strimzi PV 생성( - Strimzi 차트 다운로드(- 2️⃣ 설정( - Strimzi 사용자
43.Provisioning, Hive - Docker
Hive 개요( - 레이크 하우스 전환 이전의 역할( - MinIO 도입(레이크하우스 전환) 시 Hive의 역할 변화(- Hive 설치( - 네트워크 생성( - hive-site.xml( - Hive Metastore 실행( - SERVICE_NAME(
44.Provisioning, Hive-Posgresql-Docker
Hive 설치( - 네트워크 생성( - PostgreSql 설치( - Hiver Metastore( - SERVICE_NAME( - DB_DRIVER 용도( - Beeline 실행(- PostgreSql 메타 데이터 저장소(- 참고( - hive 사