Chapter 07. Finetuning to Follow Instructions [完]

https://github.com/rasbt/LLMs-from-scratch/blob/main/ch07
1. Introduction to instruction finetuning
- pretrained LLM은 텍스트 완성에는 능숙하지만, instruction을 따르지는 않았다. instruction을 따르도록 finetuning 해보자.
2. Preparing a dataset for supervised instruction finetuning
- instruction, input, output으로 구성된 json dataset을 finetuning data로 사용한다.
- input은 없을 수 있다.
- json을 style template에 맞게 변형해야 하며, Alpaca-style, Phi-3 prompt style 등이 있다.
3. Organizing data into training batches
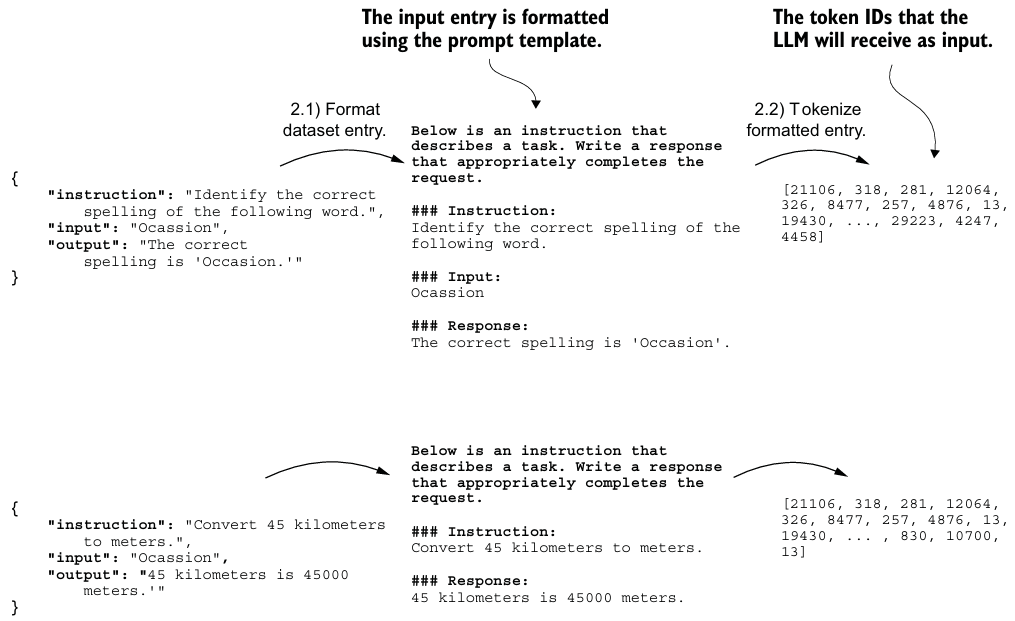
- 이전과 마찬가지로
<|endoftext|>를 사용하여 모든 input을 패딩한다.- 이때,
collate함수를 만들어서 batch마다 다른 길이로 패딩한다. - target도 이전처럼 문장 내 다음 단어이다.
- 손실 함수에서 패딩 토큰을 무시하기 위해
ignore_index를 도입한다.- 패딩 토큰의 값을 -100처럼 매우 낮은 값으로 적용하면, 결과에 영향을 끼치지 않는다.
- instruction에 해당하는 문장도 이러한 방식으로 마스킹하는 것이 일반적이다.
- 모델의 1024 token context size보다 큰 dataset을 사용할 경우
allowed_max_length를 지정하는 것이 좋다.
- 이때,
def custom_collate_fn(
batch,
pad_token_id=50256,
ignore_index=-100,
allowed_max_length=None,
device="cpu"
):
# Find the longest sequence in the batch
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs and targets
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs
targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets
# New: Replace all but the first padding tokens in targets by ignore_index
mask = targets == pad_token_id
indices = torch.nonzero(mask).squeeze()
if indices.numel() > 1:
targets[indices[1:]] = ignore_index
# New: Optionally truncate to maximum sequence length
if allowed_max_length is not None:
inputs = inputs[:allowed_max_length]
targets = targets[:allowed_max_length]
inputs_lst.append(inputs)
targets_lst.append(targets)
# Convert list of inputs and targets to tensors and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor4. Creating data loaders for an instruction dataset
custom_collate_fn을 통해 data를 직접 device로 이동시킨다. (train 함수에서 따로 이동시키지 않는다.)- Dataloader의 일부로 사용할 때 백그라운드 프로세스로 수행할 수 있으므로 효율적이다.
functools라이브러리의partial을 사용하여 원래 함수의 device 인자가 미리 채워진 새 함수를 만든다.
from functools import partial
customized_collate_fn = partial(
custom_collate_fn,
device=device,
allowed_max_length=1024
)5. Loading a pretrained LLM
- 124M model은 너무 작아서 instruction-finetuning이 잘 되지 않기 때문에 그보다 큰 모델을 사용한다.
- 아직 finetuning을 하지 않아 response를 생성하지만 원래 input과 instruction을 반복하기만 한다.
6. Finetuning the LLM on instruction data
optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)
num_epochs = 2
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)7. Extracting and saving responses
- scoring을 위해 test set에 대한 response를 저장한다.
- classfication처럼 명확하게 evaluation하기 힘들기 때문에 다양한 방식이 활용된다.
- 단답형 및 객관식을 벤치마크하는 MMLU(Measuring Massive Multitask Language Understanding)
- 다른 LLM과의 사람의 선호도를 비교하는 LMSYS chatbot arena
- AlpacaEval 등은 자동화된 대화 벤치마크에서는 GPT-4와 같은 또 다른 LLM을 사용하여 응답을 평가한다.
8. Evaluating the finetuned LLM
- Ollama를 이용해 Llama 3.1을 로컬에서 사용하여 평가한다.
- LLMs을 동작시키는 애플리케이션으로, LLM을 pure C/C++로 구현하여 효율성을 극대화한다.
ollama serve,ollama run llama3run대신 REST API를 통해 Ollama를 동작한다.
import urllib.request
def query_model(
prompt,
model="llama3",
url="http://localhost:11434/api/chat"
):
# Create the data payload as a dictionary
data = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"options": { # Settings below are required for deterministic responses
"seed": 123,
"temperature": 0,
"num_ctx": 2048
}
}
# Convert the dictionary to a JSON formatted string and encode it to bytes
payload = json.dumps(data).encode("utf-8")
# Create a request object, setting the method to POST and adding necessary headers
request = urllib.request.Request(
url,
data=payload,
method="POST"
)
request.add_header("Content-Type", "application/json")
# Send the request and capture the response
response_data = ""
with urllib.request.urlopen(request) as response:
# Read and decode the response
while True:
line = response.readline().decode("utf-8")
if not line:
break
response_json = json.loads(line)
response_data += response_json["message"]["content"]
return response_data
model = "llama3"
def generate_model_scores(json_data, json_key, model="llama3"):
scores = []
for entry in tqdm(json_data, desc="Scoring entries"):
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry[json_key]}`"
f" on a scale from 0 to 100, where 100 is the best score. "
f"Respond with the integer number only."
)
score = query_model(prompt, model)
try:
scores.append(int(score))
except ValueError:
print(f"Could not convert score: {score}")
continue
return scores
scores = generate_model_scores(test_data, "model_response")
print(f"Number of scores: {len(scores)} of {len(test_data)}")
print(f"Average score: {sum(scores)/len(scores):.2f}\n")- Ollama는 완전히 결정론적이지 않으므로, 약간은 다를 수 있다.
9. Conclusions
- finetuning 이후 preference fintuning을 할 수 있다.
- 이는 특정 사용자 선호도에 더 잘 맞도록 모델을 커스터마이징 한다.
- axolotl, LitGPT를 통해 실제 애플리케이션에 더 강력한 LLM을 사용할 수 있다.
※ preparing an instruction dataset
1. Finding Near Duplicates
- 데이터셋에서 cosine similarity를 확인해서 중복을 확인한다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import json
def find_near_duplicates(json_data, threshold=0.75, key="instruction"):
"""The higher the threshold, the more similar the texts have to be to match"""
# Extract instructions
text = [preprocess_text(item[key]) for item in json_data if item[key]]
near_duplicates = []
indices_to_remove = set()
if not text:
return {}, near_duplicates
# Vectorize the text data
vectorizer = TfidfVectorizer(stop_words=None, analyzer='char', ngram_range=(1, 3))
tfidf_matrix = vectorizer.fit_transform(text)
# Compute cosine similarity between each pair of entries
cos_sim_matrix = cosine_similarity(tfidf_matrix)
# Find pairs of near-duplicate instructions based on the threshold
for i in range(len(cos_sim_matrix)):
for j in range(i+1, len(cos_sim_matrix)):
if cos_sim_matrix[i, j] > threshold:
if len(json_data[i][key]) <= 1 or len(json_data[j][key]) <= 1:
continue
near_duplicates.append((json_data[i], json_data[j], cos_sim_matrix[i, j]))
if key in ("input", "output"): # Don't remove duplicates based on the instruction
indices_to_remove.add(j) # Mark the second entry for removal
# Remove the near-duplicate entries
filtered_json_data = [item for index, item in enumerate(json_data) if index not in indices_to_remove]
return filtered_json_data, near_duplicates
def find_print_and_remove_near_duplicates(json_data, remove_duplicates=False, threshold=0.75):
"""
Searches each key in the first JSON object for duplicates across a list of JSON objects.
Prints the duplicates if found.
"""
for key in json_data[0].keys():
if remove_duplicates:
json_data, near_duplicates = find_near_duplicates(json_data, key=key, threshold=threshold)
else:
_, near_duplicates = find_near_duplicates(json_data, key=key, threshold=threshold)
separator = 50 * '='
print(f"\n\n{separator}\nSearching '{key}' for duplicates ...\n{separator}")
if not near_duplicates:
print("No duplicates found")
else:
for dup in near_duplicates:
print(
f"Duplicate pair found with similarity {dup[2]:.2f}:\n"
f"1. {dup[0][key]}\n2. {dup[1][key]}\n"
)
return json_data2. Creating Passive Voice Entries
- GPT-4를 이용하여 수동태 output을 추가한다.
from openai import OPENAI
client = OpenAI(api_key=api_key)
def run_chatgpt(prompt, client, model="gpt-4-turbo"):
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
temperature=0.0,
)
return response.choices[0].message.content
# Prepare input
sentence = "I ate breakfast"
prompt = f"Convert the following sentence to passive voice: '{sentence}'"
run_chatgpt(prompt, client)※ Preference finetuning with DPO
- Preference finetuning을 위한 데이터셋을 만들기 위해서 LLM을 활용하는 방법
- instruction-finetuned LLM을 사용하여 response를 만들고 이에 대한 rank를 매기게 한다.
- response를 만들고 사람들이 rank를 매기게 한다.
- 특정 기준에 따라 선호하는 응답과 선호하지 않는 응답을 생성하기 위해 LLM을 사용한다.
# 3번 방식에 대한 Ollama 사용
def generate_model_responses(json_data):
for i, entry in enumerate(tqdm(json_data, desc="Writing entries")):
politeness = random.choice(["polite", "impolite"])
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"slightly rewrite the output to be more {politeness}."
"Keep the modification minimal."
"Only return return the generated response and nothing else."
)
response = query_model(prompt)
if politeness == "polite":
json_data[i]["chosen"] = response
json_data[i]["rejected"] = entry["output"]
else:
json_data[i]["rejected"] = response
json_data[i]["chosen"] = entry["output"] 만든 데이터셋으로 DPO(Direct Preference Optimization)를 통해 사용자 preference와 더 밀접하게 일치하는 응답을 생성하는 능력을 향상시킨다.
1. A brief introduction to DPO
- DPO는 RLHF(Reinforcement Learning from Human Feedback)의 대안으로 제안된 기법으로, Instruction finetuning 이후 Alignment 단계에서 사용된다.
- 이 과정에서 Preference에 맞게 output을 조정한다.
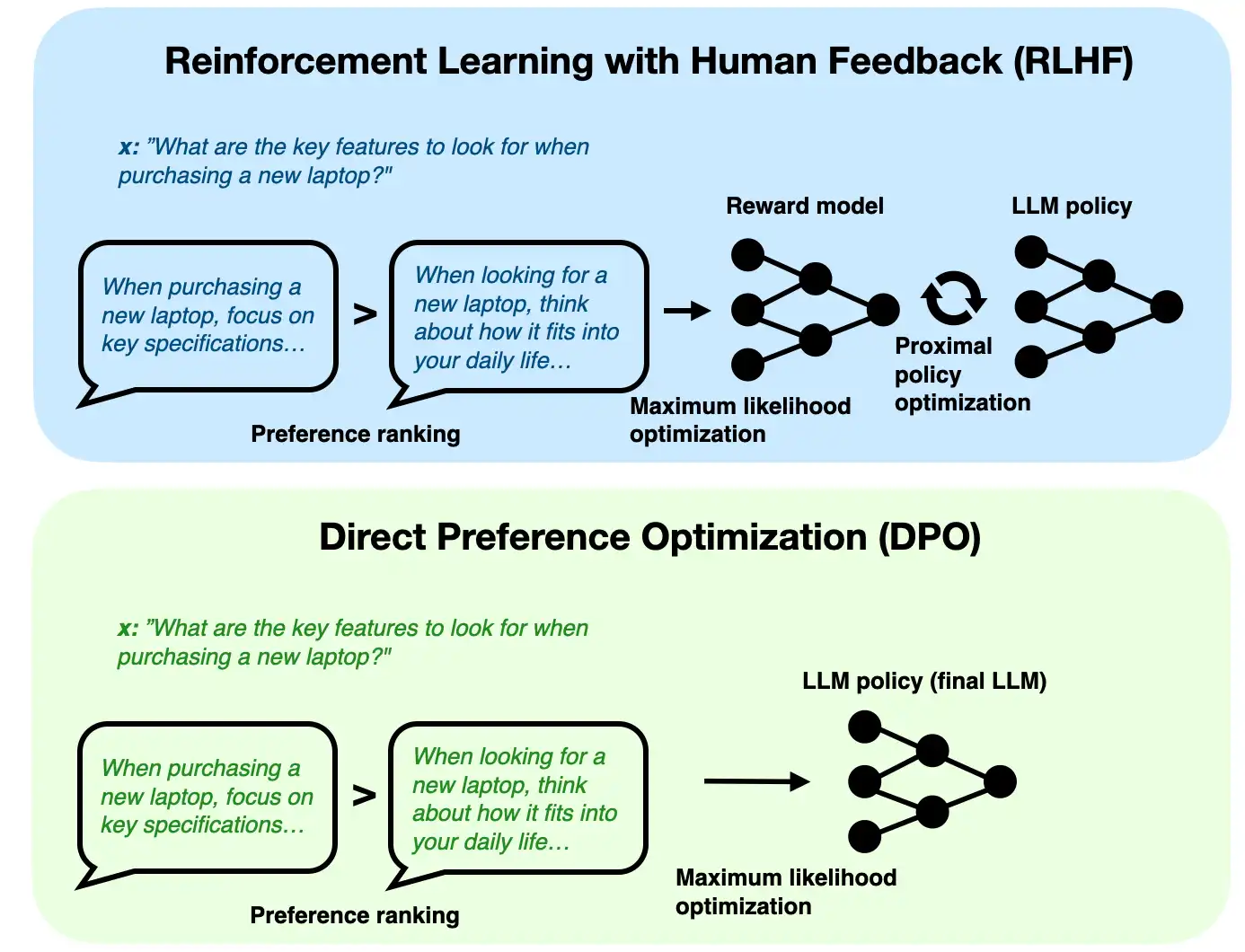
- RLHF와 비교하여 DPO는 간단히 인간 preference나 특정 목적에 맞게 출력을 최적화하는 것을 목표로 둔다.
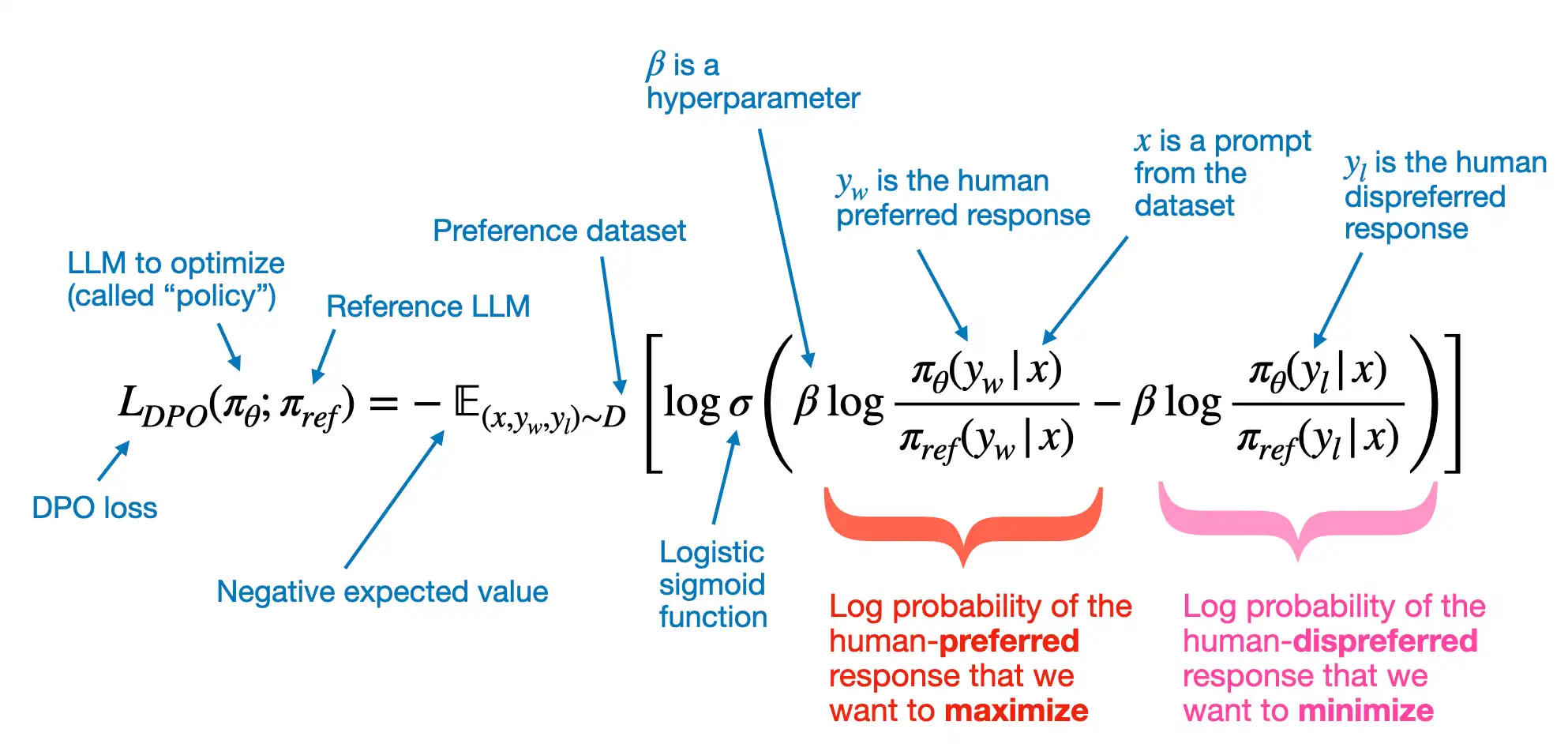
- 는 사용자 preference를 조정하기 위한 random variable의 평균이다.
- 는 와 reference model의 수렴 정도를 로그 우도 관점에서 control한다.
- 는 선호되거나 거부되는 log-odds를 probability score로 변형한다.
2. Preparing a preference dataset for DPO
- 더 친화적이거나 비친화적인 output이 포함된 dataset을 load한다.
- 상대적으로 선호되는 output과 아닌 output으로 구성된 response pair를 return하도록 dataset class를 수정한다.
- 배치 내에서는 같은 길이로 패딩되는 batch collation function로 업데이트한다.
- Dataset에 포함된
chosen_mask와rejected_mask에서True는 실제 response에 포함되는 토큰 ID이고False는 패딩 토큰이나 프롬프트를 나타낸다.
3. Loading a finetuned LLM for DPO alignment
- 이전 챕터에서 배운 instruction-finetuned model을 load한다.
- DPO는 policy model(최적화하려는 model)과 reference model(original model)을 두기 때문에 모델을 복제한다.
4. Coding the DPO Loss Function
compute_logprobs에서compute_dpo_loss의 인자로 넘길 를 계산한다.
def compute_dpo_loss(
model_chosen_logprobs,
model_rejected_logprobs,
reference_chosen_logprobs,
reference_rejected_logprobs,
beta=0.1,
):
"""Compute the DPO loss for a batch of policy and reference model log probabilities.
Args:
policy_chosen_logprobs: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)
policy_rejected_logprobs: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
reference_chosen_logprobs: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)
reference_rejected_logprobs: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)
beta: Temperature parameter for the DPO loss; typically something in the range of 0.1 to 0.5. We ignore the reference model as beta -> 0.
label_smoothing: conservativeness for DPO loss.
Returns:
A tuple of three tensors: (loss, chosen_rewards, rejected_rewards).
"""
model_logratios = model_chosen_logprobs - model_rejected_logprobs
reference_logratios = reference_chosen_logprobs - reference_rejected_logprobs
logits = model_logratios - reference_logratios
# DPO (Eq. 7 of https://arxiv.org/pdf/2305.18290.pdf)
losses = -F.logsigmoid(beta * logits)
# Optional values to track progress during training
chosen_rewards = (model_chosen_logprobs - reference_chosen_logprobs).detach()
rejected_rewards = (model_rejected_logprobs - reference_rejected_logprobs).detach()
# .mean() to average over the samples in the batch
return losses.mean(), chosen_rewards.mean(), rejected_rewards.mean()
def compute_logprobs(logits, labels, selection_mask=None):
"""
Compute log probabilities.
Args:
logits: Tensor of shape (batch_size, num_tokens, vocab_size)
labels: Tensor of shape (batch_size, num_tokens)
selection_mask: Tensor for shape (batch_size, num_tokens)
Returns:
mean_log_prob: Mean log probability excluding padding tokens.
"""
# Labels are the inputs shifted by one
labels = labels[:, 1:].clone()
# Truncate logits to match the labels num_tokens
logits = logits[:, :-1, :]
log_probs = F.log_softmax(logits, dim=-1)
# Gather the log probabilities for the actual labels
selected_log_probs = torch.gather(
input=log_probs,
dim=-1,
index=labels.unsqueeze(-1)
).squeeze(-1)
if selection_mask is not None:
mask = selection_mask[:, 1:].clone()
# Apply the mask to filter out padding tokens
selected_log_probs = selected_log_probs * mask
# Calculate the average log probability excluding padding tokens
# This averages over the tokens, so the shape is (batch_size, num_tokens)
avg_log_prob = selected_log_probs.sum(-1) / mask.sum(-1)
return avg_log_prob
else:
return selected_log_probs.mean(-1)
def compute_dpo_loss_batch(batch, policy_model, reference_model, beta):
"""Compute the DPO loss on an input batch"""
# where policy_model(batch["chosen"]) are the logits
policy_chosen_log_probas = compute_logprobs(
logits=policy_model(batch["chosen"]),
labels=batch["chosen"],
selection_mask=batch["chosen_mask"]
)
policy_rejected_log_probas = compute_logprobs(
logits=policy_model(batch["rejected"]),
labels=batch["rejected"],
selection_mask=batch["rejected_mask"]
)
with torch.no_grad():
ref_chosen_log_probas = compute_logprobs(
logits=reference_model(batch["chosen"]),
labels=batch["chosen"],
selection_mask=batch["chosen_mask"]
)
ref_rejected_log_probas = compute_logprobs(
logits=reference_model(batch["rejected"]),
labels=batch["rejected"],
selection_mask=batch["rejected_mask"]
)
loss, chosen_rewards, rejected_rewards = compute_dpo_loss(
model_chosen_logprobs=policy_chosen_log_probas,
model_rejected_logprobs=policy_rejected_log_probas,
reference_chosen_logprobs=ref_chosen_log_probas,
reference_rejected_logprobs=ref_rejected_log_probas,
beta=beta
)
return loss, chosen_rewards, rejected_rewards
torch.gather는 PyTorch의cross_entropy와 유사한 작용을 한다.- selection 함수로, 정답 토큰인 response에 주어진 토큰을 구하기 위해
selection_mask를 사용한다. - dataloader를 위한
compute_dpo_loss_loader함수를 만든다
- selection 함수로, 정답 토큰인 response에 주어진 토큰을 구하기 위해
- 정리하자면, logits → compute_logprobs → compute_dpo_loss → compute_dpo_loss_batch → compute_dpo_loss_loader → evaluate_dpo_loss_loader이다.
5. Training the model
- cross-entropy loss를 DPO loss로 전환한 후, reward와 reward margin(rejected와 chosen 간의 보상 차이)을 추적하여 DPO 학습 진행을 확인한다.
def train_model_dpo_simple(
policy_model, reference_model, train_loader, val_loader,
optimizer, num_epochs, beta,
eval_freq, eval_iter, start_context, tokenizer
):
# Initialize lists to track losses and tokens seen
tracking = {
"train_losses": [],
"train_chosen_rewards": [],
"train_rejected_rewards": [],
"val_losses": [],
"val_chosen_rewards": [],
"val_rejected_rewards": [],
"tokens_seen": []
}
tokens_seen, global_step = 0, -1
# Main training loop
for epoch in range(num_epochs):
policy_model.train() # Set model to training mode
for batch_idx, batch in enumerate(train_loader):
optimizer.zero_grad() # Reset loss gradients from previous batch iteration
loss, chosen_rewards, rejected_rewards = compute_dpo_loss_batch(
batch=batch,
policy_model=policy_model,
reference_model=reference_model,
beta=beta
)
loss.backward() # Calculate loss gradients
optimizer.step() # Update model weights using loss gradients
tokens_seen += batch["chosen"].numel()
global_step += 1
# Optional evaluation step
if global_step % eval_freq == 0:
res = evaluate_dpo_loss_loader(
policy_model=policy_model,
reference_model=reference_model,
train_loader=train_loader,
val_loader=val_loader,
beta=beta,
eval_iter=eval_iter
)
tracking["train_losses"].append(res["train_loss"])
tracking["train_chosen_rewards"].append(res["train_chosen_reward"])
tracking["train_rejected_rewards"].append(res["train_rejected_reward"])
tracking["val_losses"].append(res["val_loss"])
tracking["val_chosen_rewards"].append(res["val_chosen_reward"])
tracking["val_rejected_rewards"].append(res["val_rejected_reward"])
tracking["tokens_seen"].append(tokens_seen)
train_reward_margin = res["train_chosen_reward"] - res["train_rejected_reward"]
val_reward_margin = res["val_chosen_reward"] - res["val_rejected_reward"]
print(
f"Ep {epoch+1} (Step {global_step:06d}): "
f"Train loss {res['train_loss']:.3f}, Val loss {res['val_loss']:.3f}, "
f"Train reward margins {train_reward_margin:.3f}, "
f"Val reward margins {val_reward_margin:.3f}"
)
# Print a sample text after each epoch
generate_and_print_sample(
model=model,
tokenizer=tokenizer,
device=loss.device,
start_context=start_context
)
return tracking- policy model의 매개변수만 AdamW에 전달하며, 단 1개의 epoch만 훈련한다.
- 이는 DPO가 실제 loss가 줄어들어도 붕괴되기 쉽고, 무의미한 텍스트를 생성할 수 있기 때문이다.
- 매우 적은 학습률을 사용하는 것이 가장 좋고, 로 DPO를 조정할 수 있다.
6. Analyzing the results
- reward와 reward margin이 잘 수렴하였으며, 생성한 text를 보면 style이 미묘하게 변경되어 더 정중해진 것을 확인할 수 있다.
※ Dataset Generation
1. Generate dataset using Ollama
- "hack"으로 불리는 프롬프트를 사용하면 instruction-finetuned Llama 3가 instruction을 생성한다.
- 이를 통해 insruction에 대한 response를 생성하는 방식으로 dataset을 만들어낼 수 있다.
def query_model(prompt, model="llama3", url="http://localhost:11434/api/chat", role="user"):
# Create the data payload as a dictionary
data = {
"model": model,
"seed": 123, # for deterministic responses
"temperature": 1., # for deterministic responses
"top_p": 1,
"messages": [
{"role": role, "content": prompt}
]
}
# Convert the dictionary to a JSON formatted string and encode it to bytes
payload = json.dumps(data).encode("utf-8")
# Create a request object, setting the method to POST and adding necessary headers
request = urllib.request.Request(url, data=payload, method="POST")
request.add_header("Content-Type", "application/json")
# Send the request and capture the response
response_data = ""
with urllib.request.urlopen(request) as response:
# Read and decode the response
while True:
line = response.readline().decode("utf-8")
if not line:
break
response_json = json.loads(line)
response_data += response_json["message"]["content"]
return response_data
def extract_instruction(text):
for content in text.split("\n"):
if content:
return content.strip()
query = "<|begin_of_text|><|start_header_id|>user<|end_header_id|>"
for i in tqdm(range(dataset_size)):
result = query_model(query, role="assistant")
instruction = extract_instruction(result)
response = query_model(instruction, role="user")
entry = {
"instruction": instruction,
"output": response
}
dataset.append(entry)2. Improving Instruction-Data Via Reflection-Tuning Using GPT-4
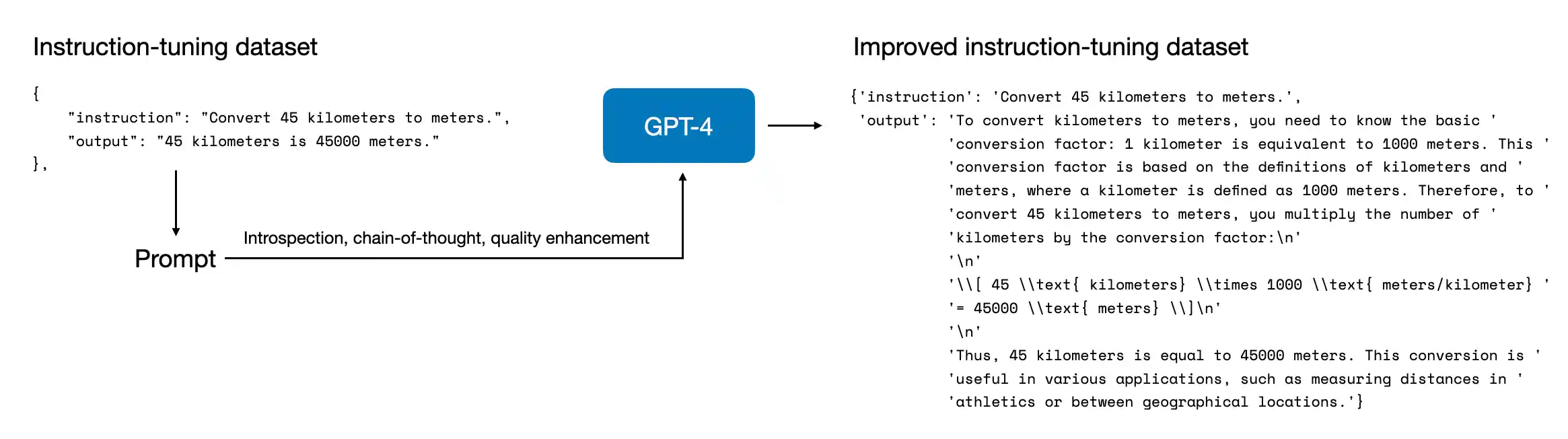
1. improving the instructions
Reflection-Tuning refinement process을 거쳐 instruction을 발전시킨다.
def instr_prompt_no_input(ins, outp):
sys_prompt = "You are a helpful, precise but picky assistant for checking the quality of a given instruction."
prompt_template = "[Instruction]\n{ins}\n\n[The Start of Answer]\n{outp}\n\n[The End of Answer]\n\n[System]\n{criteria}\n\n"
criteria = "We would like you to answer several questions related to the quality of a given instruction. \n" + \
"1. Why this instruction is not good? First analyse the instruction based on Complexity of the Topic, Level of Detail Required, Knowledge Required, Ambiguity of the Instruction and Logical Reasoning or Problem-Solving Involved. \n" + \
"Then analyse why this answer is not good for the given instruction? Analyse based on the Helpfulness, Relevance, Accuracy and Level of Details. \n" + \
"Finally analyse why this bad instruction lead to a bad answer. " +\
"2. Based on the reason you provided, generate a new and complete instruction which is complex and difficult to answer directly. " + \
"Make sure the new instruction is relevent but independent to the original instruction, which can be answered without knowing the original instruction, put the new instruction in the format of [New Instruction] your instruction [End]" +\
"3. Answer the newly generated instruction as detailed as possible, in the format of [New Answer] your answer [End] \n"
prompt = prompt_template.format(
ins=ins, outp=outp, criteria=criteria
)
return sys_prompt, prompt
system_prompt, prompt = instr_prompt_no_input(ins=entry["instruction"], outp=entry["output"])
output = run_chatgpt(prompt=prompt, client=client, system_prompt=system_prompt)- 위 prompting으로 chain-of-thought prompting approach가 향상되어 response가 매우 장황하여 분석 목적에 유용해진다.
- output에서 새 instruction과 실제 outputs을 추출한다.
def extract_ins(text, no_input=True):
if '[New Instruction]' in text:
pattern = r'(\[New Instruction\])(.*?)(\[End\]|\[New Answer\]|New Answer:)'
else:
pattern = r'(New Instruction:)(.*?)(\[End\]|\[New Answer\]|New Answer:)'
segments = re.findall(pattern, text, re.DOTALL)
if len(segments) == 0:
seg_ins = ''
else:
seg_ins = segments[0][1].strip()
if seg_ins.endswith("\n\n3."):
seg_ins = seg_ins[:-4]
return seg_ins
def extract_oup(text, no_input=True):
if '[New Answer]' in text:
pattern = r'(\[New Answer\])(.*?)(\[End\]|$)'
else:
pattern = r'(New Answer:)(.*?)(\[End\]|$)'
# pattern = r'(\[New Answer\]|New Answer:)(.*?)(\[End\]|$)'
segments = re.findall(pattern, text, re.DOTALL)
if len(segments) == 0:
seg_oup = ''
else:
seg_oup = segments[0][1].strip()
return seg_oup
def extract_instruction(text):
if text == '':
return []
seg_ins = extract_ins(text, no_input=True)
seg_oup = extract_oup(text, no_input=True)
return [seg_ins, seg_oup]
new_instr, new_outp = extract_instruction(output)2. improving the responses
유사한 방식으로 output field도 향상시킬 수 있다.
def res_gen_prompt_no_input(ins, outp):
sys_prompt = "You are a helpful, precise but picky assistant for checking the quality of the answer to a given instruction."
prompt_template = "[Instruction]\n{ins}\n\n[The Start of Answer]\n{outp}\n\n[The End of Answer]\n\n[System]\n{criteria}\n\n"
criteria = "We would like you to answer several questions related to the quality of the answer to the given instruction. \n" + \
"1. Why this answer is not good for the given instruction? Analyse based on the Helpfulness, Relevance, Accuracy and Level of Details. \n" + \
"2. Based on the reason you provided, generate a better answer, new and complete, as detailed as possible, in the format of [Better Answer] your answer [End] \n"
prompt = prompt_template.format(
ins=ins, outp=outp, criteria=criteria
)
return sys_prompt, prompt
def res_gen_prompt_input(ins, inp, outp):
sys_prompt = "You are a helpful and precise assistant for checking the quality of the answer to a given instruction and its input."
prompt_template = "[Instruction]\n{ins}\n\n[The Start of Input]\n{inp}\n\n[The End of Input]\n\n[The Start of Answer]\n{outp}\n\n[The End of Answer]\n\n[System]\n{criteria}\n\n"
criteria = "We would like you to answer several questions related to the quality of the answer to the given instruction and corresponding input. \n" + \
"1. Why this answer is not good for the given instruction and corresponding input? Analyse based on the Helpfulness, Relevance, Accuracy and Level of Details. \n" + \
"2. Based on the reason you provided, generate a better answer, new and complete, as detailed as possible, in the format of [Better Answer] your answer [End] \n"
prompt = prompt_template.format(
ins=ins, inp=inp, outp=outp, criteria=criteria
)
return sys_prompt, prompt
system_prompt, prompt = res_gen_prompt_no_input(ins=entry["instruction"], outp=entry["output"])
output = run_chatgpt(prompt=prompt, client=client, system_prompt=system_prompt)
def extract_response(text):
if text.count('[Better Answer]') >= 2:
pattern = r'\[(Better Answer)\](.*?)(\[End\]|\[Better Answer\]|$)'
segments = re.findall(pattern, text, re.DOTALL)
else:
# pattern = r'\[(Better Answer)\](.*?)\[End\]'
pattern = r'\[(Better Answer)\](.*?)(\[End\]|End|$)'
segments = re.findall(pattern, text, re.DOTALL)
return [segment[1].strip() for segment in segments]
response = extract_response(output)[0]3. Improving Dataset
위 두 절차를 Dataset에 적용하여 quality를 향상시킨다.
def reflect_instructions(json_data, client):
new_json_data = []
for entry in tqdm(json_data):
if not entry["input"]:
system_prompt, prompt = instr_prompt_no_input(ins=entry["instruction"], outp=entry["output"])
output = run_chatgpt(prompt=prompt, client=client, system_prompt=system_prompt)
new_instr, new_outp = extract_instruction(output)
new_entry = {"instruction": new_instr, "input": "", "output": new_outp}
new_json_data.append(new_entry)
else:
new_json_data.append(entry)
return new_json_data
def reflect_responses(json_data, client):
new_json_data = []
for entry in tqdm(json_data):
if not entry["input"]:
system_prompt, prompt = res_gen_prompt_no_input(ins=entry["instruction"], outp=entry["output"])
output = run_chatgpt(prompt=prompt, client=client, system_prompt=system_prompt)
new_response = extract_response(output)
if not len(new_response):
new_response = entry["output"]
new_entry = {"instruction": entry["instruction"], "input": "", "output": new_response[0]}
new_json_data.append(new_entry)
else:
system_prompt, prompt = res_gen_prompt_input(ins=entry["instruction"], inp=entry["input"], outp=entry["output"])
output = run_chatgpt(prompt=prompt, client=client, system_prompt=system_prompt)
new_response = extract_response(output)
if not len(new_response):
new_response = entry["output"]
new_entry = {"instruction": entry["instruction"], "input": entry["input"], "output": new_response[0]}
new_json_data.append(new_entry)
return new_json_data
It’s always white night here.