Appendix E. Parameter-efficient Finetuning with LoRA

1. Introduction to LoRA
LoRA(Low-rank adaptation)는 사전학습된 모델 파라미터의 low-rank subset을 조정하여 특정 dataset에 더 잘 맞도록 수정하는 머신러닝 기술이다.
- task-specific data에 대해 효율적인 finetuning이 가능하다.
- 기존 weight matrix를 업데이트 하는 식인 에서 를 로 A와 B라는 작은 weight matrix로 나눈다.
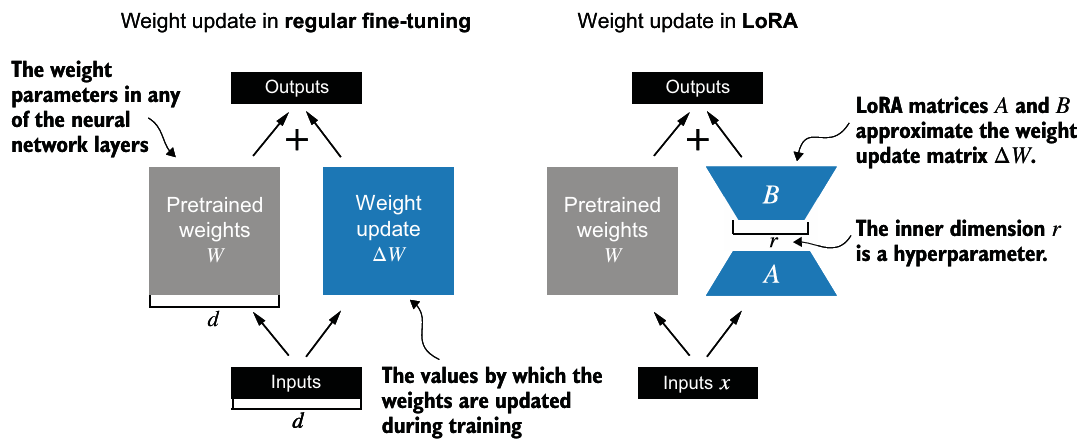
- 행렬 곱셈의 분배 법칙으로 인해 업데이트된 가중치를 더할 필요없이 이를 유지할 수 있다.
- 즉, LoRA weight matrix를 분리할 수 있고, pretrained model의 weights를 수정할 필요가 없다.
2. Preparing the dataset & Initializing the model
- 6과와 같은 방식으로 train, test, validation data loader를 준비한다.
- pretrained GPT-2를 load한다.
3. Parameter-efficient finetuning with LoRA
- A와 B matrix를 만드는
LoRALayer를 초기화한다. - low-rank adaptation output에 적용되는 scaling 하이퍼파라미터인 를 사용한다.
- 이는 adapted layer의 output이 adaptation 중인 레이어의 원래 output에 영향을 미치는 정도를 제어한다.
- 행렬의 내부 차원을 제어하는 rank 하이퍼파라미터인 을 사용한다.
- 이는 추가 파라미터의 수를 제어하며 모델 적응성과 파라미터 효율성 간의 균형을 결정한다.
- LoRALayer가 기존 linear layer를 대체할 수 있도록 구현한다.
class LinearWithLoRA(torch.nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)
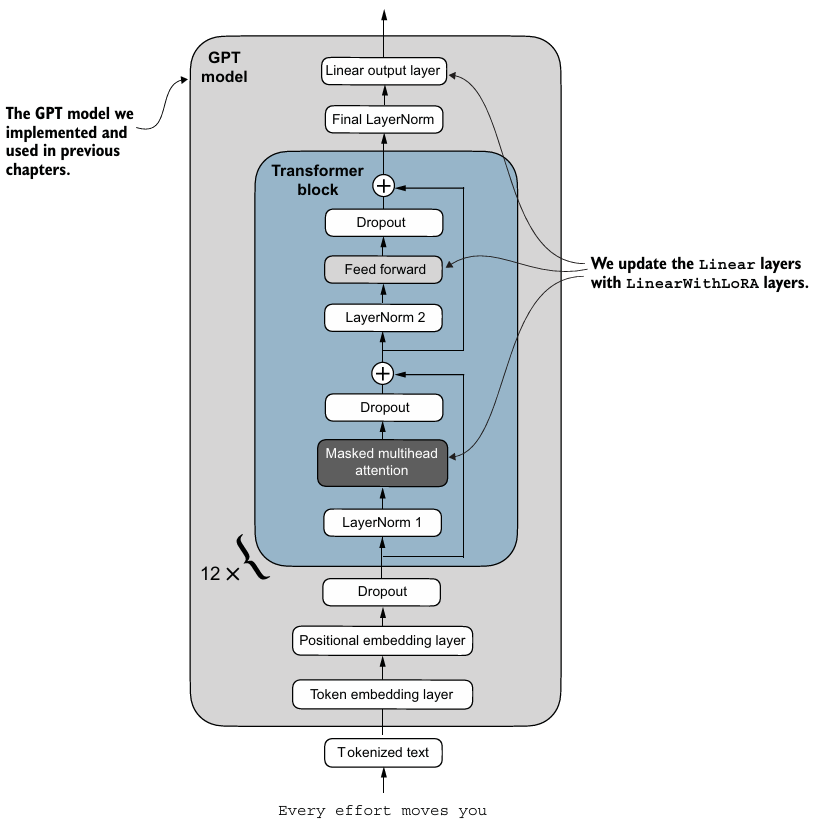
- 위 그림처럼, Linear Layer를 모두 LoRA Layer로 대체한다.
def replace_linear_with_lora(model, rank, alpha):
for name, module in model.named_children():
if isinstance(module, torch.nn.Linear):
# Replace the Linear layer with LinearWithLoRA
setattr(model, name, LinearWithLoRA(module, rank, alpha))
else:
# Recursively apply the same function to child modules
replace_linear_with_lora(module, rank, alpha)- A와 B가 모두 0으로 초기화되어 있기 때문에 finetuning 이전에는 결과가 같다.
- evaluation을 해보면 훈련이 잘 된 것을 확인할 수 있다.

It’s always white night here.