
최근 업데이트일 2025-01-11
github: NVIDIA/gpu-operator
github: NVIDIA/k8s-device-plugin
Setup GPU Env in K8s
GPU Time Slicing
쿠버네티스 환경에서 NVIDIA GPU를 컨테이너에 할당하고, 더 나아가 하나의 GPU를 여러 Pod가 나눠 쓰는 GPU 분할 방법에 대해 알아보자.
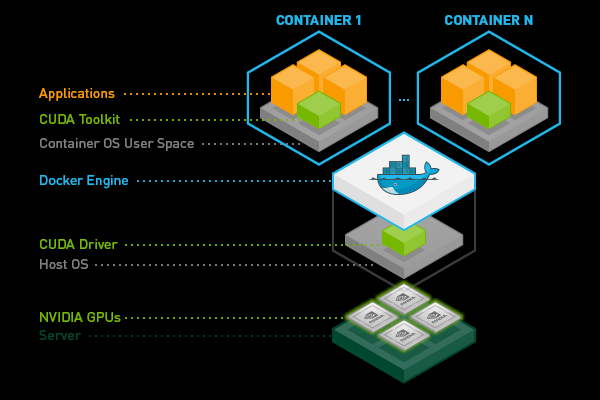
조건: 컨테이너 런타임 설정
쿠버네티스에서 GPU를 사용하려면 호스트 머신의 컨테이너 런타임이 GPU를 인식할 수 있도록
nvidia-container-runtime을 기본 런타임으로 설정해야 하고 이를 위해선nvidia-docker2가 설치되어 있어야 한다.
상태 확인 명령어
# NVIDIA Container Toolkit 도구를 사용하여 GPU 관련 정보 수집 및 출력
nvidia-container-cli -k -d /dev/tty info
# nvidia-container-runtime 설치 여부 및 버전 확인 (Jetson 환경)
sudo dpkg -l | grep nvidia-container-runtime
# Docker default runtime 확인
sudo docker info | grep -i runtimeContainerd 및 Docker 설정 수정
- 런타임 설정을 위해 아래와 같이 설정 파일을 수정하고 서비스를 재시작한다.
1) Containerd 설정 (/etc/containerd/config.toml)
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"] # 위치 주의
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "nvidia"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes] # 위치 주의
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"sudo systemctl restart containerd2) Docker 설정 (/etc/docker/daemon.json)
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
}
}sudo systemctl restart docker워크스테이션에서의 GPU 할당: GPU Operator
- 일반적인 워크스테이션이나 서버 환경에서는 NVIDIA GPU Operator를 사용하여 GPU를 매우 편리하게 할당하고 관리할 수 있다.
- GPU Operator는 k8s 클러스터 내에서 NVIDIA 계열의 GPU 노드로 파드를 편하게 관리할 수 있도록 도와주는 툴이다.
- NFD (Node Feature Discovery)는 GPU 지원 노드를 자동으로 검색하고 레이블을 지정해 주는 도구로, 함께 배포하여 사용할 수 있다.
Jetson에서의 GPU 할당
NVIDIA 공식 문서 따르면, GPU Operator는 외장 GPU(Discrete GPUs)만 지원한다. NVIDIA Jetson과 같은 내장 GPU(Integrated GPUs)가 탑재된 임베디드 플랫폼은 지원하지 않는다.
결론부터 말하면, GPU Operator는 Jetson의 L4T(Linux for Tegra) 드라이버 스택과 호환되지 않기 때문에 설치에 실패한다. GPU Operator는 거대한 자동화 패키지로서 데이터센터용 GPU(A100, H100 등)를 가정하고 동작하기 때문이다.
- 실패하는 이유
- 드라이버 충돌: Jetson은 커널과 드라이버가 깊게 통합된 전용 OS(L4T)를 사용한다. Operator가 데이터센터용 x86 드라이버를 컨테이너 형태로 덮어쓰려 시도하므로 실패한다.
- 모니터링 툴(DCGM) 비호환: GPU 상태를 모니터링하는 DCGM 역시 데이터센터 GPU 전용이므로 Jetson의 통합 GPU(iGPU)와는 호환되지 않는다.
- MIG 미지원: GPU를 하드웨어 레벨에서 분할하는 MIG(Multi-Instance GPU) 기능은 Jetson Orin 하드웨어에서 아예 지원하지 않는다.
해결책: NVIDIA Device Plugin 직접 사용
Jetson 환경에서는 거대한 GPU Operator 대신, 가장 단순하고 독립적인 부품인 NVIDIA Device Plugin만 단독으로 설치해야 한다.
- 이 플러그인은 드라이버를 설치하려 하지 않고, 그저 이미 설치된 L4T 드라이버의 GPU 디바이스 개수를 세어서 Kubelet에 보고하는 역할만 수행하기 때문에 Jetson에서도 완벽하게 동작한다.
curl -O https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.16.2/deployments/static/nvidia-device-plugin.yml
kubectl create -f nvidia-device-plugin.yml # nvidia.com/gpu: 1 할당 가능해짐트러블슈팅: Jetson에서 CUDA 실사용 시 주의점
- Device Plugin 적용 후 테스트 파드를 띄울 때
exec format error가 발생할 수 있다. 이는 아키텍처 불일치 문제로, ARM 64bit에 맞는 이미지를 Pull 받아야 한다.
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "nvidia/cuda-arm64:11.4.0-devel-ubuntu20.04" # ARM64 전용 이미지
command: [ "sleep" ]
args: [ "infinity" ]
resources:
limits:
nvidia.com/gpu: 1- Pod 접속 후
apt-get update를 실행할 때 GPG error(NO_PUBKEY)가 발생할 수 있다. NVIDIA 측에서 pubkey를 변경 중일 때 흔히 나타나는 문제로, 아래와 같이 수동으로 키를 등록해 주면 해결된다.
# NVIDIA GPG Pubkey 수동 등록
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys A4B469963BF863CC- GPU 할당 및 상태 확인 도구
tegrastats: Jetson GPU 사용량 모니터링./deviceQuery(CUDA Sample): CUDA 정보 확인
GPU 분할: 하나의 GPU를 여러 Pod가 사용
비싼 GPU 자원을 하나의 컨테이너가 독점하는 것은 비효율적이다. GPU를 분할하여 여러 Pod가 공유하는 방법에는 크게 5가지가 있다.
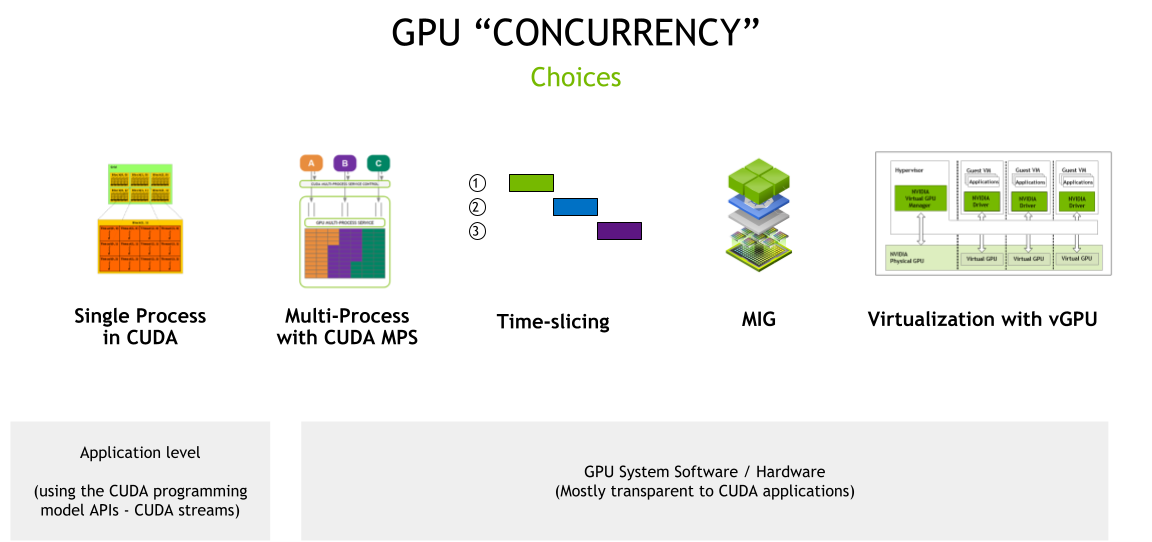
- CUDA 스트림 (Streams)
- Time Slicing (시분할)
- CUDA MPS (Multi-Process Service)
- MIG (Multi-Instance GPU - 하드웨어 분할)
- vGPU를 사용한 가상화
이 중 쿠버네티스 환경에서 가장 널리 쓰이는 소프트웨어적 분할 방식인 Time Slicing 적용 방법을 알아본다.
워크스테이션 환경: GPU Operator와 Helm을 이용한 설정
- 워크스테이션에서는 설치된 GPU Operator의 설정을 Helm과
kubectl patch를 통해 변경하여 적용한다.kubectl patch: Kubernetes 리소스를 삭제하지 않고 원하는 필드만 업데이트하는 명령어
# 1. Helm 설치 및 GPU Operator 레포지토리 추가
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh
helm repo add nvidia https://nvidia.github.io/gpu-operator
helm install --wait --generate-name -n gpu-operator --create-namespace nvidia/gpu-operator
# 2. Time Slicing ConfigMap 생성 및 적용
kubectl create -n gpu-operator -f time-slicing-config-all.yaml
kubectl patch clusterpolicy/cluster-policy \
-n gpu-operator --type merge \
-p '{"spec": {"devicePlugin": {"config": {"name": "time-slicing-config-all", "default": "any"}}}}'Jetson 환경: Device Plugin ConfigMap을 이용한 분할
- Jetson은 MIG를 지원하지 않지만, Time-Slicing을 통한 소프트웨어적 공유는 완벽하게 지원한다. GPU Operator 없이 NVIDIA Device Plugin의 ConfigMap을 수정하여 활성화할 수 있다.
ConfigMap에 아래와 같이timeSlicing설정을 추가한다.
version: v1
flags:
sharing:
timeSlicing:
resources:
# 'nvidia.com/gpu' 대신 'nvidia.com/gpu-shared'라는 새로운 리소스 타입 생성
- name: "nvidia.com/gpu-shared"
replicas: 10 # 10개의 컨테이너가 1개의 GPU를 공유 가능- 설정 후 파드를 생성할 때 기존의
nvidia.com/gpu: 1대신 새롭게 정의한 공유 리소스를 요청하면 된다.
resources:
limits:
nvidia.com/gpu-shared: 1- 이후 10개의 다른 파드가 하나의 Jetson Orin GPU를 짧은 시간 간격으로 번갈아 가며 효율적으로 공유할 수 있게 된다.
워크스테이션과 Jetson 환경은 하드웨어 아키텍처와 드라이버 구조가 완전히 다르기 때문에 GPU를 할당하고 분할하는 접근법도 달라져야 한다.
데이터센터에서는 GPU Operator의 강력한 자동화를 활용하고, Jetson에서는 Device Plugin과 Time Slicing을 직접 구성하여 한정된 자원을 최대한 활용해 보자.
