
최근 업데이트일 2024-11-24
따라하며 배우는 쿠버네티스: 로그관리 - kubectl logs
쿠버네티스: 로깅 아키텍처
컨테이너 내부에서 발생하는 상황을 이해하고 분석하기 위해 로깅을 해보자.
로그 관리
로그는 애플리케이션 내부에서 발생하는 상황을 이해하는 데 도움이 된다. 특히 문제를 디버깅하고 클러스터 활동을 모니터링하는 데 유용하다.
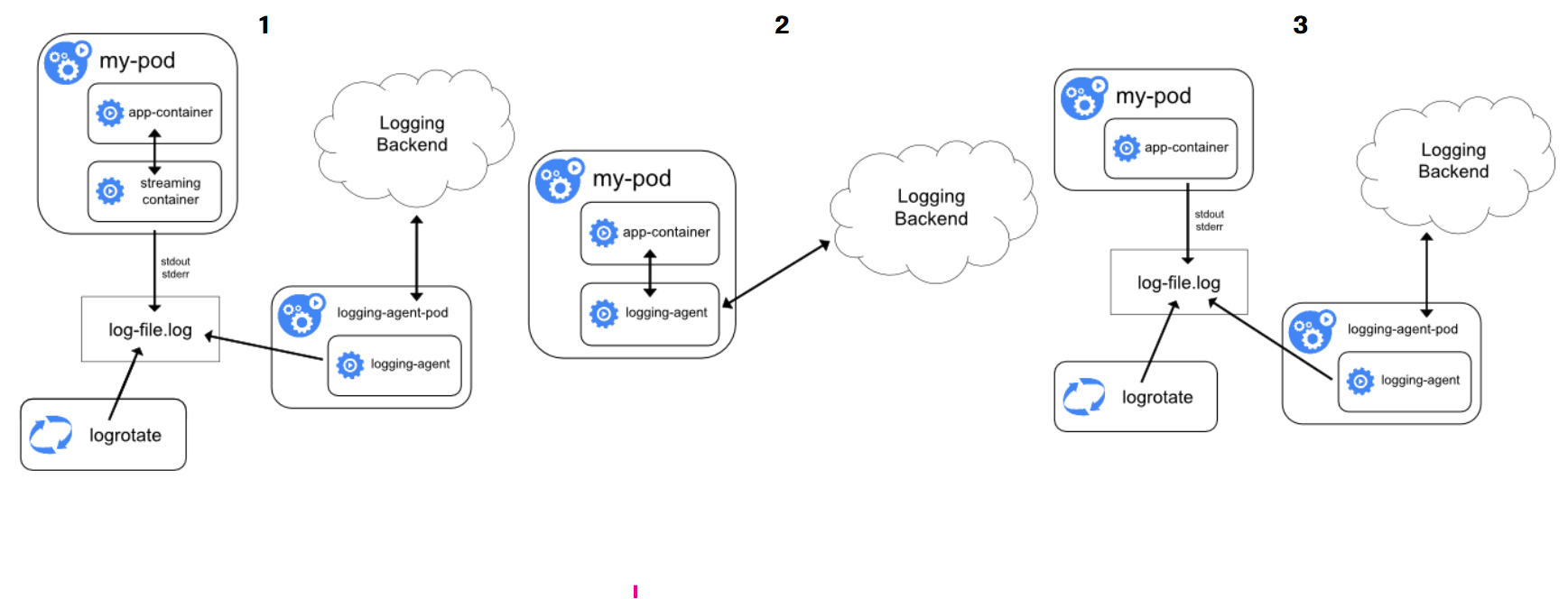
- 컨테이너가 죽거나 Pod가 Node에서 퇴출되도 로그를 볼 수 있도록 하기 위해, 클러스터에서 독립적으로 별도의 스토리지와 라이프사이클을 가져야 한다.
- 로드 밸런싱을 사용중이면 어떤 요청이 여러 Pod로 분산되기 때문에 모든 Pod의 로그를 클러스터 레벨로 중앙화를 해야 용이하다.
- 기본적으로 로그는 컨테이너 런타임에 의해
stdout,stderr를 통해 Node에 기록된다. (kubectl logs로 확인 가능)- kubelet의 Log Rotation 설정으로 로그 파일을 일정한 크기로 관리할 수 있다.
기본적인 로그 수집 방식은 3가지가 있으니 각각 살펴보자.
Node Logging Agent
모든 노드에 Logging Agent를 놓는 방식으로 Agent가
/var/log/containers등에서 로그를 수집해서 logging backend로 보낸다.
- 중앙 집중 방식이고 구성이 쉽다.
- 간단한 예시
- Node Logging Agent는 대부분 Fluentd/Fluent Bit DaemonSet을 사용한다.
- Fluent Bit은 Fluentd의 경량 버전으로 가볍고 빠르며 Node에서 로그를 수집하는 데 특화되어 있다.
- Fluentd는 Fluent Bit의 기본적인 기능에 더하여 대규모 데이터 흐름 제어, 필터링, 복잡한 포맷 변경 등을 지원한다.
- 집중형 로그 라우터 또는 고급 파이프라인 처리기로 적합하다.
- Elasticsearch로 로그 전달 지원 (EFK에서 설명)
helm repo add fluent https://fluent.github.io/helm-charts
helm repo update
kubectl create namespace logging
# 각 노드에 Fluent Bit를 DaemonSet으로 설치
# 배포된 DaemonSet이 `/var/log/containers/*.log` 경로의 컨테이너 로그를 수집
# 수집된 로그를 Fluent Bit Pod의 stdout으로 출력한다.
helm install fluent-bit fluent/fluent-bit -n logging
# 로그 확인
kubectl logs -n logging -l k8s-app=fluent-bitSidecar Container Streaming
logging을 위한 사이드카 컨테이너를 Pod에 포함시키는 방식
- 격리성이 높고 세밀한 처리가 가능하지만 리소스가 많이 필요할 수 있다.
- 특정 앱에 특화된 로그 수집이 필요한 경우 사용할 수 있다.
- 간단한 예시
apiVersion: v1
kind: Pod
metadata:
name: app-with-sidecar
spec:
containers:
- name: myapp
image: myapp:latest
volumeMounts:
- name: logs
mountPath: /app/logs # myapp이 /app/logs/app.log에 로그를 남김
- name: log-forwarder
image: fluent/fluent-bit # fluent-bit 사이드카가 로그를 읽어 외부로 전송
args: ["-i", "tail", "-p", "path=/app/logs/app.log", "-o", "stdout"]
volumeMounts:
- name: logs
mountPath: /app/logs
volumes:
- name: logs
emptyDir: {}Sidecar Container with a Logging Agent
애플리케이션이 자체적으로 로그 수집기 없이 백엔드로 로그를 전송하는 방식
- 애플리케이션 코드에서 직접 Elasticsearch, Kafka, Logstash 등에 전송
- 완전 제어가 가능하지만, 코드 변경이 필요하고 표준화가 어렵다.
- 간단한 예시 (Python → Logstash)
import logging
from logstash import TCPLogstashHandler
logger = logging.getLogger('myapp')
logger.setLevel(logging.INFO)
logger.addHandler(TCPLogstashHandler('logstash-service.default.svc.cluster.local', 5959, version=1))
logger.info("hello from myapp")이 외에도 Runtime interface logging, Logging Operator, Cloud-native 로깅 플랫폼 방식 등도 존재한다.
실제 운영 환경에서는 이 중에서도 가장 보편적이고 널리 채택된 방식이 EFK 스택을 활용한 로그 중앙화로, 어떻게 구성되고 동작하는지 살펴보자.
EFK Stack (Elasticsearch & Fluentd & Kibana)
해당 아키텍처는 각 구성 요소가 명확한 역할을 가지며, 이들이 유기적으로 연결되어 로그 수집 → 저장 → 시각화라는 전체 흐름을 완성한다.
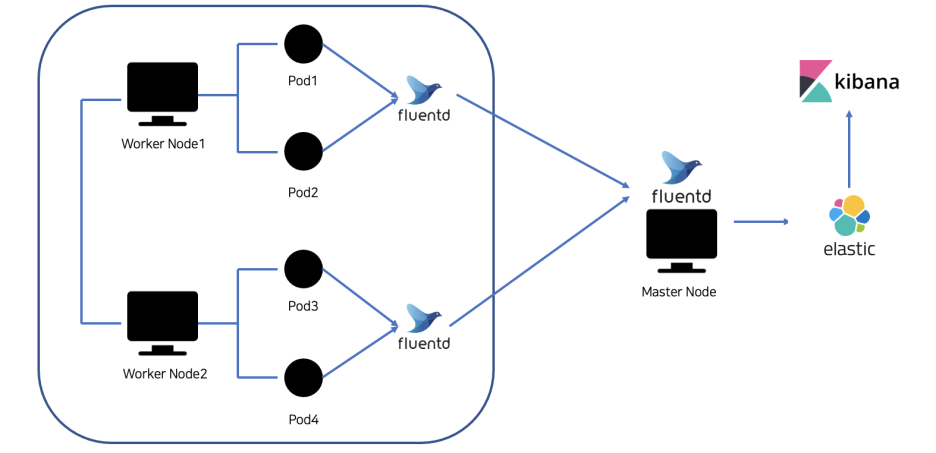
- 사용 환경에 따라 경량화가 필요한 경우 Fluentd 대신 Fluent Bit을 사용할 수 있다.
- Elasticsearch: Fluentd가 수집한 로그를 저장하는 역할
- 빠른 검색을 위한 시계열 로그 데이터 인덱싱과 복잡한 쿼리 기능을 제공한다.
- Lucene 기반 검색 엔진을 가진다.
- 고가용성, 수평 확장, 분산 저장을 지원한다.
- Kibana Query Language을 통한 필터링 및 검색이 가능하다.
- Kibana: Elasticsearch에 저장된 로그 데이터를 웹 UI로 시각화
- 웹 기반 대시보드로 로그 데이터 탐색 및 시각화한다.
- Elasticsearch와 직접 연결하고 KQL 쿼리로 로그 필터링한다.
EFK 사용 예시
- Deploy Elasticsearch Statefulset
- 내부적으로 필요한 PV · PVC까지 할당
apiVersion: apps/v1
kind: StatefulSet # Elasticsearch Pod가 상태 유지하며 실행시키는 StatefulSet
metadata:
name: elasticsearch
namespace: logging
spec:
serviceName: elasticsearch # # StatefulSet이 사용할 headless 서비스 이름
replicas: 1 # # 하나의 Elasticsearch 인스턴스를 실행
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: es
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.9
ports:
- containerPort: 9200 # Elasticsearch 기본 포트
env:
- name: discovery.type
value: "single-node" # 단일 노드 모드로 실행 (개발용)
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data # 데이터 저장 경로
volumeClaimTemplates: # PVC 설정해서 고유한 디스크 보유
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi # 각 인스턴스당 10Gi 볼륨 할당 - Deploy Elasticsearch Service
- Service로 Elasticsearch StatefulSet 노출
apiVersion: v1
kind: Service # Elasticsearch에 접근하기 위한 클러스터 내부용 서비스
metadata:
name: elasticsearch
namespace: logging
spec:
ports:
- port: 9200
name: http
selector:
app: elasticsearch- Deploy Kibana Deployment
- 엔드포인트 URL을 사용하여 Elasticsearch에 연결하기 위해 일단 Kibana Deployment 배포
apiVersion: apps/v1
kind: Deployment # Kibana 웹 UI를 배포하는 Deployment
metadata:
name: kibana
namespace: logging
spec:
replicas: 1 # 1개의 Kibana 인스턴스
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers: # Kibana 공식 이미지를 사용
- name: kibana
image: docker.elastic.co/kibana/kibana:7.17.9
ports:
- containerPort: 5601 # Kibana UI 접속 포트
env: # Kibana가 Elasticsearch에 연결할 주소
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch.logging.svc.cluster.local:9200"- Deploy Kibana Service
- Service로 Kibana Deployment 노출
apiVersion: v1
kind: Service # 클러스터 내 또는 포트포워딩용 Kibana Service
metadata:
name: kibana
namespace: logging
spec:
ports:
- port: 5601
targetPort: 5601
selector:
app: kibana- Create Fluentd Cluster Role
- Pod 및 namespace에 대한 권한을 부여하기 위해 Cluster Role 생성
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole # Fluentd가 Pod나 namespace 정보를 조회할 수 있는 권한 정의
metadata:
name: fluentd-role
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "list", "watch"] # 로그 수집 대상 정보를 조회- Create Fluentd Service Account
- Fluentd 파드와 함께 사용할 Service Account를 생성
apiVersion: v1
kind: ServiceAccount # Fluentd가 사용할 서비스 계정
metadata:
name: fluentd
namespace: logging- Create Fluentd Cluster Role Binding
- 생성된 ClusterRole과 Service Account 간에 연결을 위한 ClusterRoleBinding 생성
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding # ClusterRole과 ServiceAccount를 연결
metadata:
name: fluentd-rolebinding
subjects:
- kind: ServiceAccount
name: fluentd
namespace: logging
roleRef:
kind: ClusterRole
name: fluentd-role
apiGroup: rbac.authorization.k8s.io- Deploy Fluentd DaemonSet
- 환경 변수로 설정한 Elasticsearch 값을 사용하여 Node에서 수집된 로그를 전달을 위해 DaemonSet 생성
apiVersion: apps/v1
kind: DaemonSet # 각 Node에서 로그를 수집하는 Fluentd DaemonSet
metadata:
name: fluentd
namespace: logging
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
serviceAccountName: fluentd # 위에서 생성한 계정 사용
containers:
- name: fluentd
image: fluent/fluentd:v1.14 # Fluentd 기본 이미지
env: # Elasticsearch에 로그를 보낼 주소
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch.logging.svc.cluster.local"
volumeMounts: # 컨테이너 수준에서 볼륨을 어디에 mount할지 지정
- name: varlog
mountPath: /var/log
readOnly: true
volumes: # Pod 수준에서 실제 mount할 볼륨을 정의
- name: varlog
hostPath:
path: /var/log # Node의 로그 디렉토리를 마운트- Verify Fluentd Setup
- 지속적으로 로그를 생성하는 테스트 Pod를 시작하고, 로그는
/var/log/containers에 기록되므로 Fluentd DaemonSet이 자동으로 수집한다.
- 지속적으로 로그를 생성하는 테스트 Pod를 시작하고, 로그는
kubectl run test-logger \
--image=busybox \ # busybox 이미지로 가벼운 컨테이너 실행
--restart=Never \
--namespace=logging \
--command -- sh -c \ # stdout으로 계속 로그를 찍어서 Fluentd가 수집 가능
"while true; do echo \$(date) hello from test-logger; sleep 5; done"- Kibana 연동
- 포트 포워딩 후 Index pattern을 생성한 다음, Kibana → Discover 탭으로 이동해서 로그가 쌓이는 걸 확인한다.
# Kibana UI 접속을 위한 포트 포워딩 후 http://localhost:5601 접속
kubectl port-forward -n logging svc/kibana 5601:5601
# 접속 후 Create index pattern 페이지에 들어가 패턴 입력 및 필드를 선택한다.EFK 스택은 로그를 수집하고 시각화하는 데 효과적이지만,
실시간으로 로그를 빠르게 조회하거나 디버깅할 땐 stern 같은 CLI 도구도 유용
Stern으로 여러 Pod log 한번에 확인
쿠버네티스 클러스터 내 여러 파드의 로그를 실시간으로 동시에 병렬적으로 조회할 수 있는 도구 Stern 깃허브
- 특히 ReplicaSet이나 동일 label을 가진 여러 Pod의 로그를 병렬로 추적할 수 있어 운영/모니터링에 유용하다.
- 설치 방법
- Go 기반 설치 (직접 설치)
- Go와 Govendor 설치 후 stern 설치
go install github.com/stern/stern@latest- Krew 플러그인으로 설치 kubectl krew stern
- Krew는 kubectl에 다양한 플러그인을 추가할 수 있는 플러그인 매니저이다.
kubectl krew install stern
kubectl stern <pod-name-pattern>
kubectl stern --help # 설치 확인- 사용 방법
stern nginx # nginx라는 이름이 포함된 모든 Pod의 로그를 동시에 확인
stern -n logging fluentd # logging 네임스페이스 내 fluentd 관련 파드의 로그 확인
stern --selector app=web # app=web 라벨이 붙은 모든 파드의 로그 확인
stern --exclude-container sidecar # sidecar 컨테이너를 제외하고 로그 확인
stern --container main --color always # main 컨테이너만 컬러 출력으로 보기
```
It’s always white night here.