컴퓨터의 시작이 계산기의 발전된 형태라는 것은 꽤 알려진 이야기다. 때문에 비트에 전기가 흐르는 유무를 0과 1로 표기하고, 해당 표기를 통해 2진법으로 표기하는 방식이 자리잡았다. 하지만, 비트로 다양한 수를 표현할 수 있다면, 그리고 우리가 공통적으로 약속을 공유할 수 있다면 숫자로 문자를 표현하는 것이 충분히 가능하다. 예를 들면, a=1, b=2, ... z=26이라하면 jaeman은 10 1 5 13 1 14로 표현할 수 있을것이다. 지금부터는 이진수로 변환한 비트의 저장값을 활용하여 문자를 표현하기 위한 컴퓨터수학자들의 노력을 알아볼 것이다.
아스키코드
아스키코드는 현재에도 통용되고 있는 매우 효과적인 문자표현방식이다. 정보교환을 위한 미국표준코드(American Standard Code for Information Interchange)인 이 표현방식은 알파벳을 효과적으로 표현한다.
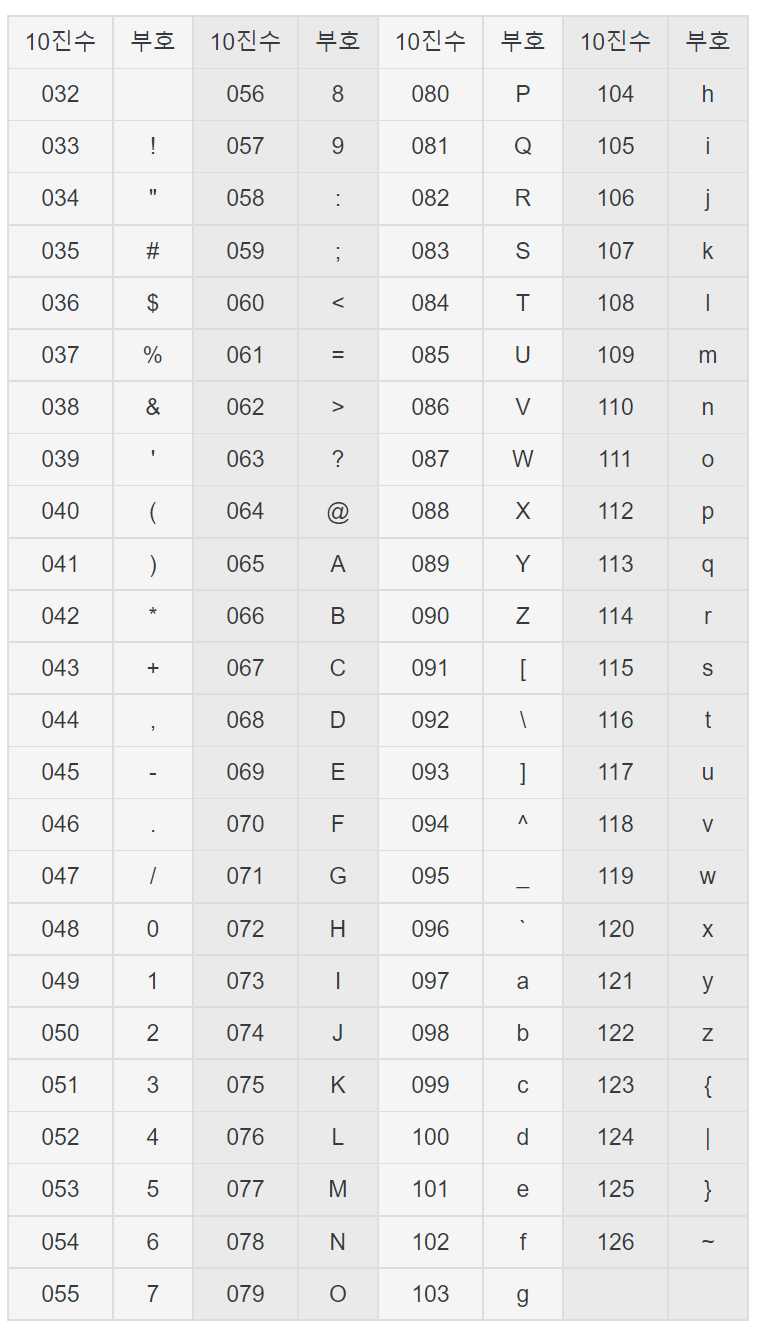
해당 표를 보면 A는 65로 표기하는데 이는 2진법으로 1000001, 8진법으로 0101, 16진법으로 0x41이다. 직관적으로 당연스레 B는 66으로 표기하고 2진법으로 1000010, 8진법으로 0102, 16진법으로 0x42로 표기한다. 아스키가 표현하는 문자는 52개의 영문 대소문자 알파벳과 10개의 숫자, 32개의 특수문자 그리고 공백 하나로 이루어져있다. 그리고 출력 불가능한 제어문자 33개를 포함하여 128개로 구성되어있다. 128개의 문자를 표현하기 위해 필요한 비트수는 7개이므로 7비트로 된 인코딩 부호체계이며, 하나를 더 붙여 여덟 비트로 전송한다. 이때 추가된 비트는 1의 갯수가 짝수면 0, 홀수면 1을 MSB에 붙여 전송함으로써 전송 도중 정보가 변경되는 것을 검출하는 통신에러 검출용도로 활용된다.
유니코드
아스키코드가 저렴한 8비트 용량으로 언어를 효율적으로 표기했지만, 여러가지 언어를 표현하기에 128개의 공간은 턱 없이 모자란다. 국가간 이메일을 교환하면 8비트 표현방식에서는 글자가 전부 깨지는 현상이 발생했다. 때문에 두 개의 바이트(이후에는 21비트까지 확장)을 활용하여 언어를 표현하는 유니코드 방식이 새로운 표준으로 등장했다.
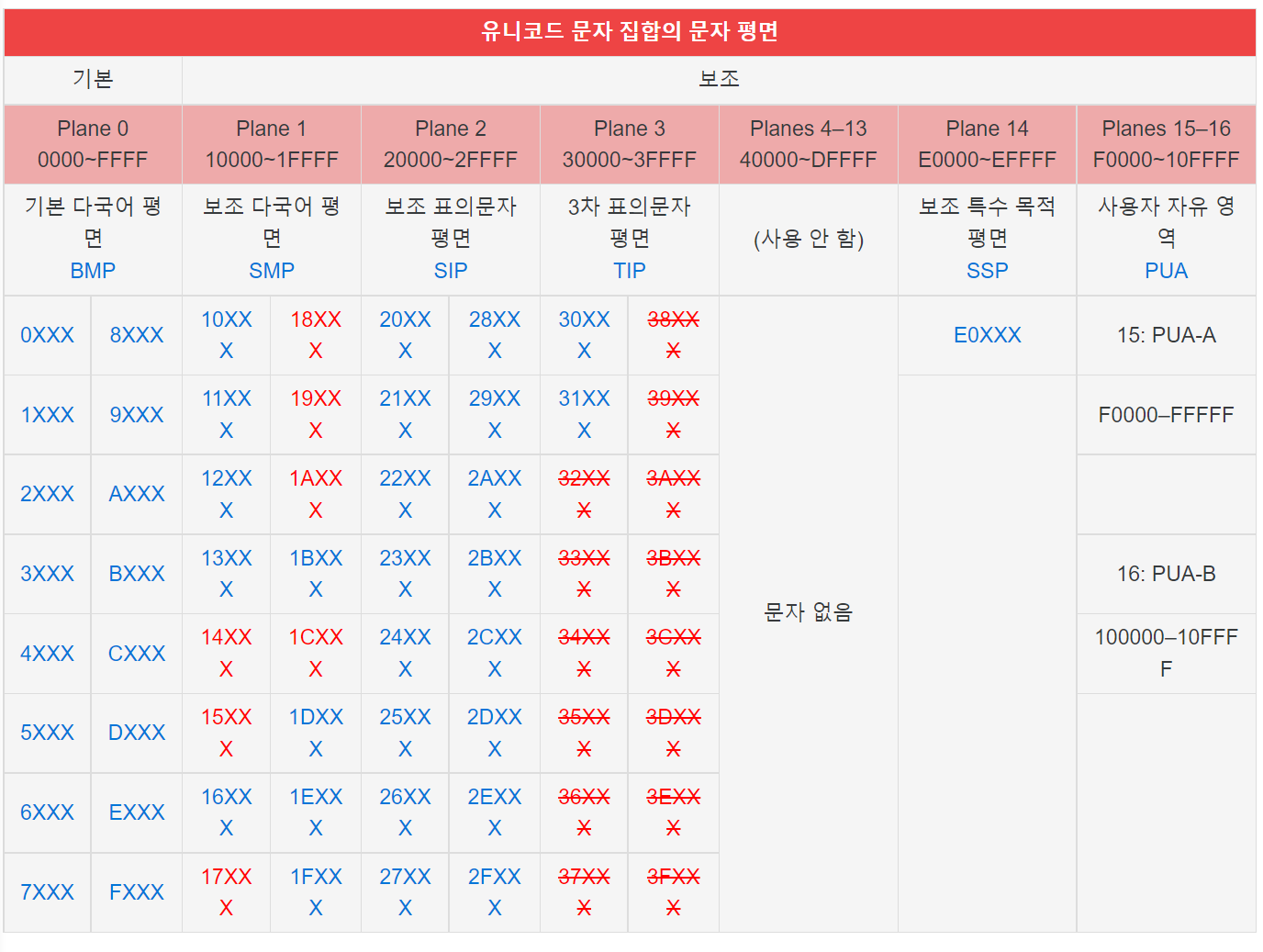
유니코드 변환방식
유니코드 방식이 16비트로 하나의 문자를 표현한다면, 아스키코드에 비해 한 단어를 표현하는데 드는 비용이 두 배가 되어버린다. 해당 문제를 해결하기 위해, 유니코드는 UTF-8이라는 효율을 위한 해석방식을 활용한다.
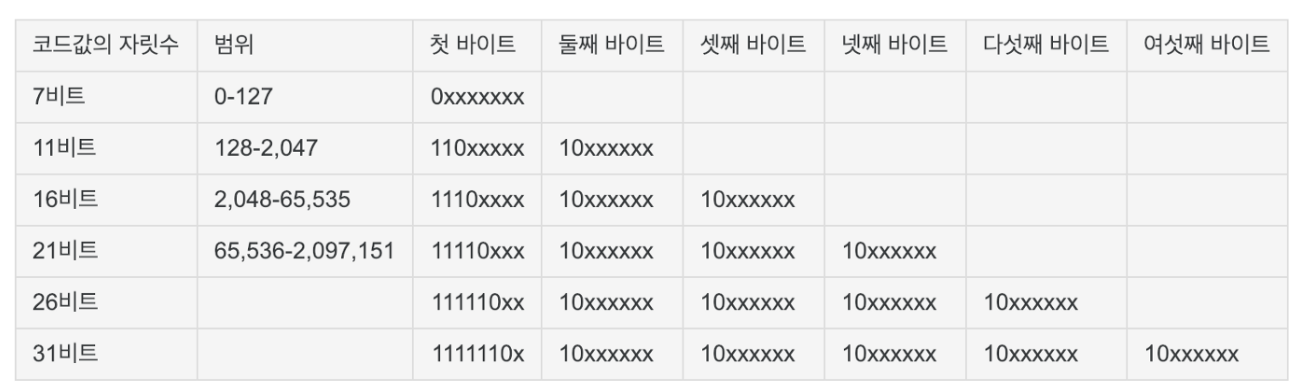
UTF-8
유니코드로 표현된 문자는 당연스레 의미를 담은 부분과 리딩제로부분으로 나뉜다. 의미를 담은 부분, 코드값의 자릿수가 몇 비트를 활용하냐에 따라 UTF-8로 인코딩했을 때 반환되는 바이트 수가 달라진다. 7비트 이내로 표현될 수 있는 경우, 해당 비트의 MSB를 0으로 기재하여 바이트로 반환한다. 때문에 일반적으로 아스키코드로 표현되는 문자는 그대로 반환된다.
비트 수가 8개에서 11개로 표현되는 경우에는 앞의 다섯자리를 한 바이트로, 뒤의 여섯자리를 한 바이트로 표기한다. 이때 앞의 바이트는 110으로 시작하여 110XXXXX로 표현하고, 뒤의 바이트는 10XXXXXX으로 표현한다.
비트 수가 12개에서 16개로 표현되는 경우에는 앞의 네 자리를 한 바이트로, 중간의 여섯자리를 한 바이트로, 뒤의 여섯자리를 한 바이트로 표현한다. 이때 앞의 바이트는 1110XXXX, 중간은 10XXXXXX, 뒤는 10XXXXXX으로 표현한다.
위에 언급한 것처럼 용량을 최소한으로 사용하기 위해, 가능한 적은 수의 바이트를 할당한다. 매우 일반적인 인코딩 방식임에도 불구하고, 3바이트 이상의 저장공간을 활용하는 문자표현에 있어서는 효율이 점차 떨어진다.
UTF-16
UTF-16은 16비트로 저장하는 UTF-8의 변형이다. 한글의 경우 UTF-8로 저장할 경우 3bytes가 필요한데, UTF-16으로 저장하면 2바이트로 저장할 수 있다. 그러나 경우에 따라서는 2바이트 이상을 사용할 경우가 있어 용량의 이점이 크다고 보긴 어렵고, 엔디안 처리를 고려함에 따른 복잡성 증대나 ANSI와 호환이 안되는 단점이 있다.
UTF-32
UTF-32는 모든 문자를 4바이트로 인코딩한다. 문자 변환 알고리즘이나 가변길이 인코딩 방식에 대한 고민을 하고 싶지 않을 때 유용할 수 있다. 그러나 매우 비효율적으로 메모리를 사용하므로 자주 사용되지는 않는다.
마무리
나만 영어 어려워
