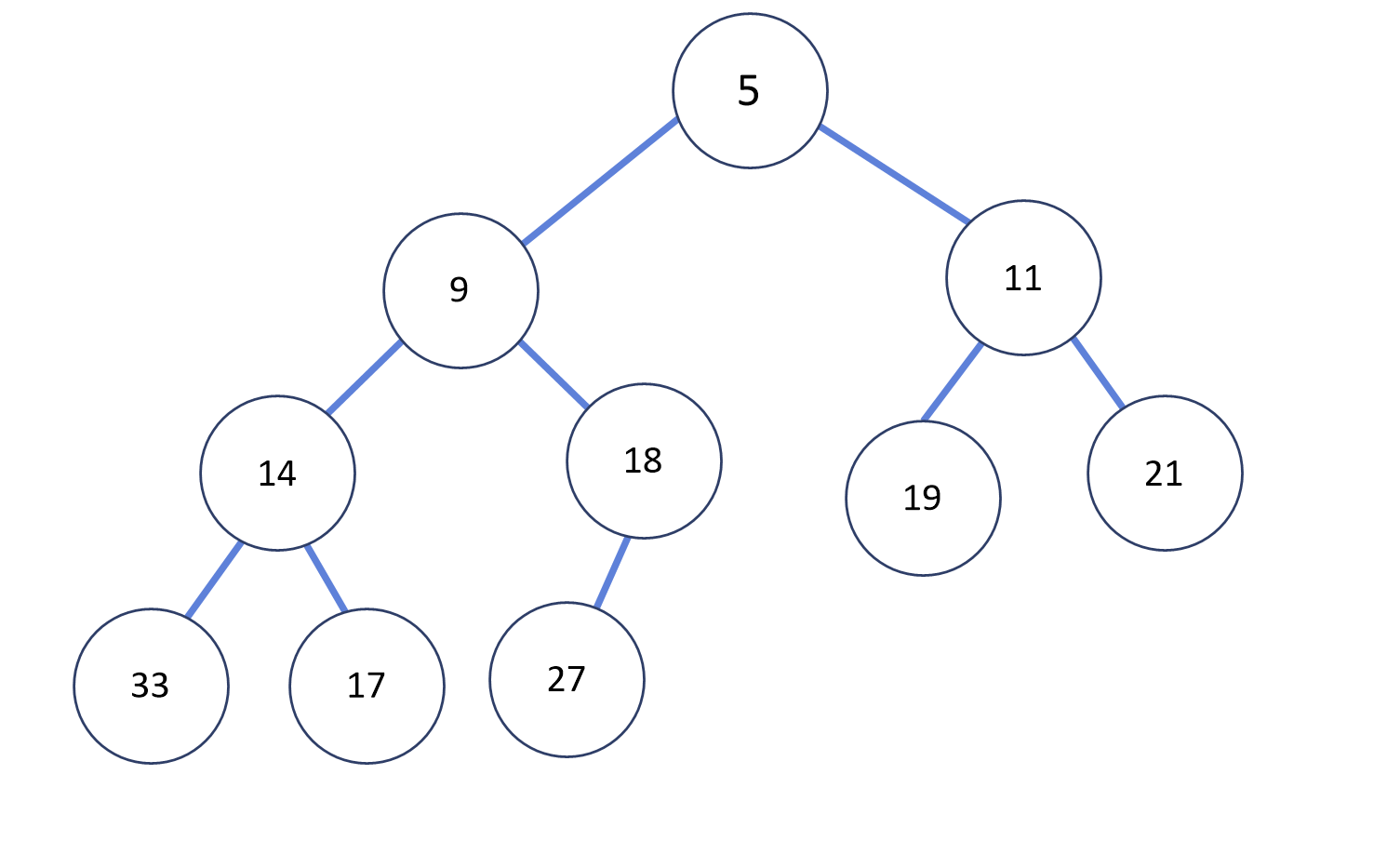
힙(HEAP)
힙이란 힙정렬에 의해 설계된 자료구조로, 부모노드에 비해 큰 값을 자식노드의 값으로 저장하거나 작은 값을 자식노드에 저장하는 하나의 규칙이 추가된 트리 형태의 자료구조이다. 완전이진트리에 위의 조건을 추가한 이진 힙의 형태를 흔히 사용하며, 이진힙과 리스트를 활용하여 효율적 연산을 가능케 한다. 이진 힙의 경우 BST 역시 완전이진트리에 오름차순 정렬이라는 조건이 붙여진 경우라 같은 종류로 혼동할 수 있으나, 전체의 부모-자식노드 간의 관계만 정리되므로 레벨별, 좌우별 정렬은 이루어지지 않는다.
힙의 효용
대부분의 자료구조는 불가능한 계산을 가능케하기 위해서가 아니라, 일반적인 연산과정의 효율을 극대화하기 위함이다. 그런 측면에서 생각하면 힙은 틈새 시장을 제대로 겨냥한 자료구조이다. 사용하는 목적이 명확하고, 적당한 정렬로 효율을 극대화하는 방식을 취하고 있다.
힙의 핵심 키워드는 우선순위라고 할 수 있다. 가장 우선하여 탐색할 값을 미리 올려두도록 하는 힙연산을 통해 구현된 자료구조이기에 해당 노드에서 바로 하나를 꺼내면 내 의도에 맞는 값을 반환하는게 기본적인 사용법이다. 뿐만 아니라, 원하는 값을 탐색하여 제거하거나, 추가하는 경우에도 큰 이점을 갖는다. 하지만 이를 이야기하기 위해 어떤 종류의 자료구조와 비교할지를 언급할 필요가 있다. 때문에 힙의 종류와 쓰임새를 탐구하고, 그 역할에 어울리는 다른 자료구조와 비교해보자.
힙의 종류
힙의 종류에는 대표적인 두 가지가 있다. 최소 힙과 최대 힙이다. 최소 힙은 루트에 최소값이 저장되고, 부모노드가 자식노드보다 작은 값을 저장하는 힙을 말한다. 최대 힙은 루트에 최대값이 저장되고, 부모노드가 자식노드보다 큰 값을 저장하는 힙을 말한다. 이 두가지 노드를 활용해 가장 큰 값 혹은 작은 값을 우선순위 값으로 설정하고 O(1)이라는 저렴한 값에 반환하는 것이다.(사실 반환한 이후에 폐기할 것이 아니라면, 재정렬이 필요하다.)
그렇다면 조금 더 나아가면, 새로운 값을 힙 안에 저장하거나, 삭제하여 재정렬하는 것 역시 충분히 가능할 것이다. 중요한 내용은 이 부분에 있다. 사실 우선순위 값 하나를 반환하는 것은 정렬된 배열만으로도 충분히 가능하기 때문이다.
힙과 정렬된 배열, 정렬된 연결리스트 비교
세 자료구조의 공통점은 값을 꺼낼 때 편리하다는 것이다. 각 함수의 pop을 통해 반환한 노드의 값이 우선순위에 해당하는 값이므로 아주 만족스러운 값을 얻을 수 있다. 그 중에 우선순위가 구조 자체의 개성인 힙은 오히려 값을 꺼내는 연산에 있어서 효율이 상대적으로 떨어진다. 그 이유는 빠진 루트를 대체할 새로운 루트를 선정해야하고, 새 루트가 빠진 자리를 자식 노드 중에서 선정해야하는 연쇄작용이 일어나기 때문이다. 때문에 일반적으로 트리의 높이 log n에 비교연산까지 포함하여 가장 많은 연산을 할 경우 log2n정도의 연산이 필요하다. 즉 시간복잡도가 O(log n)이다. 그에 비해 배열과 정렬된 연결리스트는 해당 값을 제외하고, 우선순위 값을 최신화해주기만 하면 끝날 일이다. 시간복잡도로는 O(1)에 해당한다.
하지만 값을 추가할 때는 상황이 역전된다. 힙에 새로운 값을 넣는 과정은 삭제의 역순이다. 리프에 값을 추가하여, 부모와 연속적으로 비교를 하고 조건에 맞지 않는 순간이 해당 값의 위치가 된다. 따라서 삽입 역시 O(log n)의 시간복잡도를 갖는다. 그에 비해 정렬된 배열과 연결리스트는 우선순위가 높은 갚을 하나 추가해준다고 하면, 나머지 값들의 인덱스를 하나씩 밀어야한다. 때문에 n개의 요소를 가졌다면 n번의 인덱스 갱신 작업이 이루어진다. 때문에 O(n)의 시간복잡도를 갖는다.
이를 통해, 완벽한 정렬을 포기한 힙의 전략이 돋보인다. 삭제 비용을 조금 포기하는 대신, 효과적인 삽입 비용으로 고객층을 공략한 것이다.
힙의 구현
아래는 파이썬으로 구현한 최대 힙이다. 물론 모듈인 heapq(=우선순위 큐)를 쓰면 구현하여 쓸 일이 거의 없을 것이다.
# 클래스 선언
class BinaryMaxHeap:
# 효율적인 계산을 위하여 0번째 index를 None으로 정하여 items 초기화
def __init__(self):
self.items = [None]
# len 매직매서드 선언, len(self) 시 items의 길이를 반환
def __len__(self):
return len(self.items)
# 삽입 함수 선언. items의 마지막 인덱스에 밸류 값을 넣고, 부모값과 비교하는 함수 실행
def insert(self, k):
self.items.append(k)
self._percolate_up()
# 마지막 인덱스 값과 부모값들을 비교 정렬하는 함수 선언.
def _percolate_up(self):
# 조정할 값의 인덱스를 cur에 저장. 인덱스 값은 마지막 요소이기 때문에 len(self)
# len(self)-1이어야 하지만 items = [None]으로 초기화했기 때문에 len(self)
cur = len(self)
# 부모 값은 전체 길이값의 반값이다. 전체 길이가 홀수인 경우 내림(혹은 버림) 값
parent = cur//2
# 부모의 인덱스 값이 0보다 크면 == 부모가 루트에 도달한 경우까지 계속 반복
while parent > 0:
# 들어온 값이 부모의 값보다 크다면
if self.items[cur] > self.items[parent]:
# 두 값을 교환
self.items[cur], self.items[parent] = self.items[parent], self.items[cur]
# 현재 인덱스 값을 부모의 인덱스 값으로 갱신
cur = parent
# 부모의 인덱스 값 갱신
parent = cur//2
# 삭제 함수 선언.
def extract(self):
# 저장 값이 없으면, 아무 값도 반환하지 않음.
if len(self) < 1 :
return None
# 루트 저장
root = self.items[1]
# 마지막 노드의 값을 루트의 값과 교환
self.items[1] = self.items[-1]
# 마지막 노드(루트의 값) 제거
self.items.pop()
# 루트(마지막 노드의 값)을 자식 값과 비교하는 함수 선언.
self._percolate_down(1)
return root
# 루트(마지막 노드의 값)와 자식 값을 비교하는 함수 선언.
def _percolate_down(self, cur):
# 루트의 인덱스를 biggest에 저장( 재귀 시 부모 인덱스를 담는 변수)
biggest = cur
# 왼쪽 자식노드 인덱스 값 저장
left = 2*cur
# 오른쪽 자식노드 인덱스 값 저장
right = 2*cur+1
# 만약 left의 인덱스값이 items 안의 인덱스 값이고, 자식노드 값이 더 크다면
if left <= len(self) and self.items[left] > self.items[biggest]:
# 루트의 인덱스 값을 left로 갱신
biggest = left
# 만약 right의 인덱스값이 items 안의 인덱스 값이고, 자식노드 값이 더 크다면
if right <= len(self) and self.items[right] > self.items[biggest]:
# 루트의 인덱스 값을 right로 갱신
biggest = right
# 만약 루트의 인덱스가 갱신되었다면
if biggest != cur:
# cur이 가리키는 값과 갱신된 인덱스가 가리키는 값을 교환
self.items[cur], self.items[biggest] = self.items[biggest], self.items[cur]
# 갱신된 biggest를 루트로 재귀함수 실행
self._percolate_down(biggest)각각 삽입함수 insert는 _percolate_up을 호출하고, extract는 _percolate_down을 호출한다. _percolate_up은 조건에 대해 부모함수와의 비교를 하고, _percolate_down은 자식함수와 비교하도록 한다.
마무리
This is heap-pop()
