
BERT: Bidirectional Encoder Representations from Transformer
1. BERT
BERT는 2018년에 자연어 처리를 위해 구글에서 고안한 트랜스포머 기반의 머신러닝 기법입니다. BERT의 가장 큰 특징은 문장 전체의 구조를 양방향으로 학습하여 문맥을 파악할 수 있다는 것입니다. 가령, 기존의 Word2vec, Glove와 같은 임베딩 방식은 문맥 파악 없이 단어를 임베딩했다면, BERT는 같은 단어라고 하더라도 앞뒤 문맥을 통해 구분할 수 있다는 것이죠! (참고로 BERT는 저 노란 친구의 이름이기도 합니다.)
BERT는 두 단계로 이루어집니다.
👆 사전학습 (Pre-training): 영문 위키피디아와 BooksCorpus의 데이터를 사용하여 두 가지 학습을 하는데, 하나는 단어를 무작위로 가려놓고 원래 단어를 맞추는 학습 (Masked LM), 다른 하나는 문장의 순서를 예측하는 것을 학습합니다 (Next Sentence Prediction, NSP).
✌️ 미세 조정 (fine-tuning): 사전학습 시 사용된 파라미터를 모두 조정하여 모델이 어느 한 태스크에 국한되지 않고 범용적으로 쓰일 수 있도록 합니다.
2. KeyBERT
키워드 추출을 위해서는 BERT를 적용한 오픈 소스 파이썬 모듈인 KeyBERT를 사용하겠습니다. KeyBERT의 원리는 BERT를 이용해 문서 레벨 (document-level)에서의 주제 (representation)를 파악하도록 하고, N-gram을 위해 단어를 임베딩 합니다. 이후 코사인 유사도를 계산하여 어떤 N-gram 단어 또는 구가 문서와 가장 유사한지 찾아냅니다. 가장 유사한 단어들은 문서를 가장 잘 설명할 수 있는 키워드로 분류됩니다 (https://maartengr.github.io/KeyBERT/index.html).
3. 데이터 분석
그렇다면 KeyBert를 사용해서 넷플릭스에 있는 한국 작품들에 대한 외국 시청자들의 반응을 알아보도록 하겠습니다.
3.1. 데이터 수집
데이터를 수집할 작품은 모두 10개로, 플릭스 패트롤에서 상위 열개의 작품을 선정했습니다 (https://flixpatrol.com/).
| 제목 | 영어 제목 | 플릭스 패트롤 포인트 | 영화/시리즈 | 방영일 |
|---|---|---|---|---|
| 오징어 게임 | Squid Game | 43,657 | 시리즈 | 2021.9.17 |
| 빈센조 | Vincenzo | 19,792 | 시리즈 | 2021.2.20 |
| 갯마을 차차차 | Hometown Cha-Cha-Cha | 10,172 | 시리즈 | 2021.8.28 |
| 마이 네임 | My Name | 8,595 | 시리즈 | 2021.10.15 |
| 스타트업 | Start-Up | 8,404 | 시리즈 | 2020.10.17 |
| 알고 있지만 | Nevertheless | 7,235 | 시리즈 | 2021.6.19 |
| 슬기로운 의사생활 | Hospital Playlist | 7,102 | 시리즈 | 2021.6.17 |
| #살아있다 | #Alive | 6,928 | 영화 | 2020.9.8 |
| 청춘기록 | Record of Youth | 5,966 | 시리즈 | 2020.9.7 |
| 승리호 | Space Sweepers | 5,662 | 영화 | 2021.2.5 |
이번에 외국 시청자의 반응을 보기 위해 사용할 데이터는 IMDb 리뷰입니다. 수집된 데이터는 다음과 같습니다.

3.2. 키워드 추출
KeyBert의 기본적인 사용법은 개발자가 정리한 이 문서를 참고해주세요(https://github.com/MaartenGr/KeyBERT). 제가 작성한 코드는 다음과 같습니다.
def BERT(title):
array_text = pd.DataFrame(df[df['title'] == title]['text']).to_numpy()
bow = []
from keybert import KeyBERT
kw_extractor = KeyBERT('distilbert-base-nli-mean-tokens')
for j in range(len(array_text)):
keywords = kw_extractor.extract_keywords(array_text[j][0])
bow.append(keywords)
new_bow = []
for i in range(0, len(bow)):
for j in range(len(bow[i])):
new_bow.append(bow[i][j])
keyword = pd.DataFrame(new_bow, columns=['keyword', 'weight'])
print(keyword.groupby('keyword').agg('sum').sort_values('weight', ascending=False).head(20))
따라서 BERT('vincenzo')라고 입력하면 드라마 <빈센조>의 키워드가 추출된 아웃풋이 나옵니다.
👉 아웃풋
weight
keyword
mafia 3.7755
comedy 3.6292
best 2.6592
love 2.6583
thriller 2.3891
good 1.7765
romance 1.4485
acting 1.1075
italian 1.0790
perfect 0.9724
worth 0.9630
drama 0.9415
netflix 0.8274
watching 0.7717
korean 0.7549
movie 0.7046
slapstick 0.7029
great 0.7028
funny 0.6778
exaggerated 0.67164. 시각화
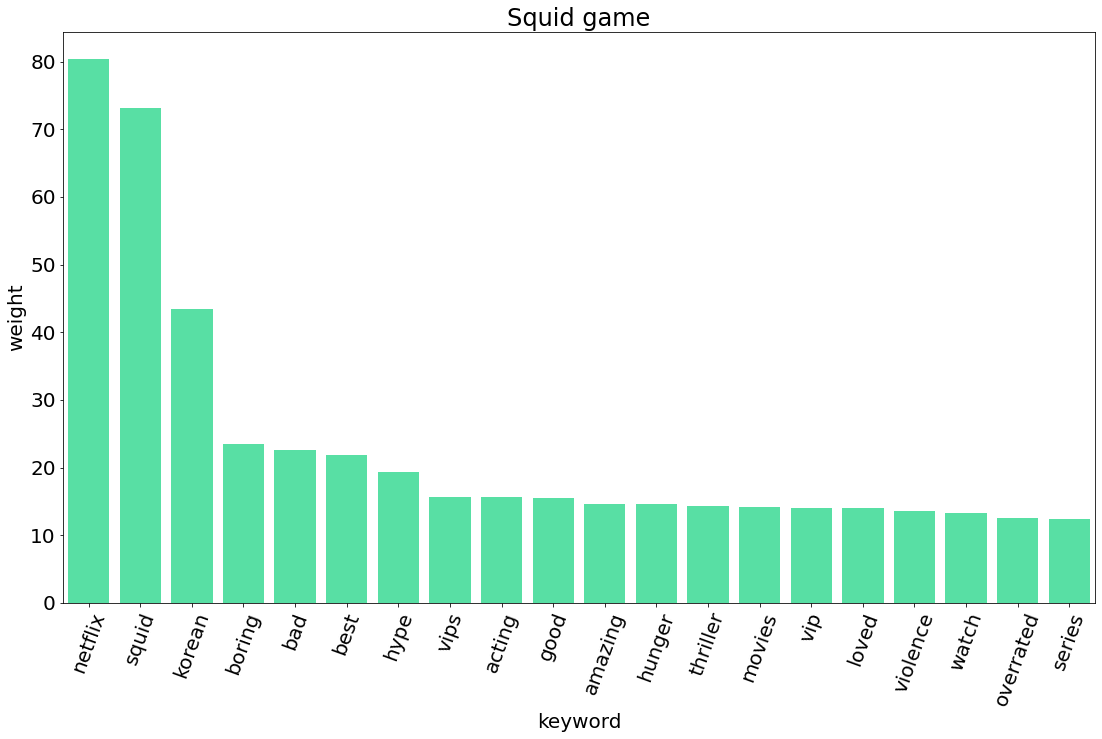
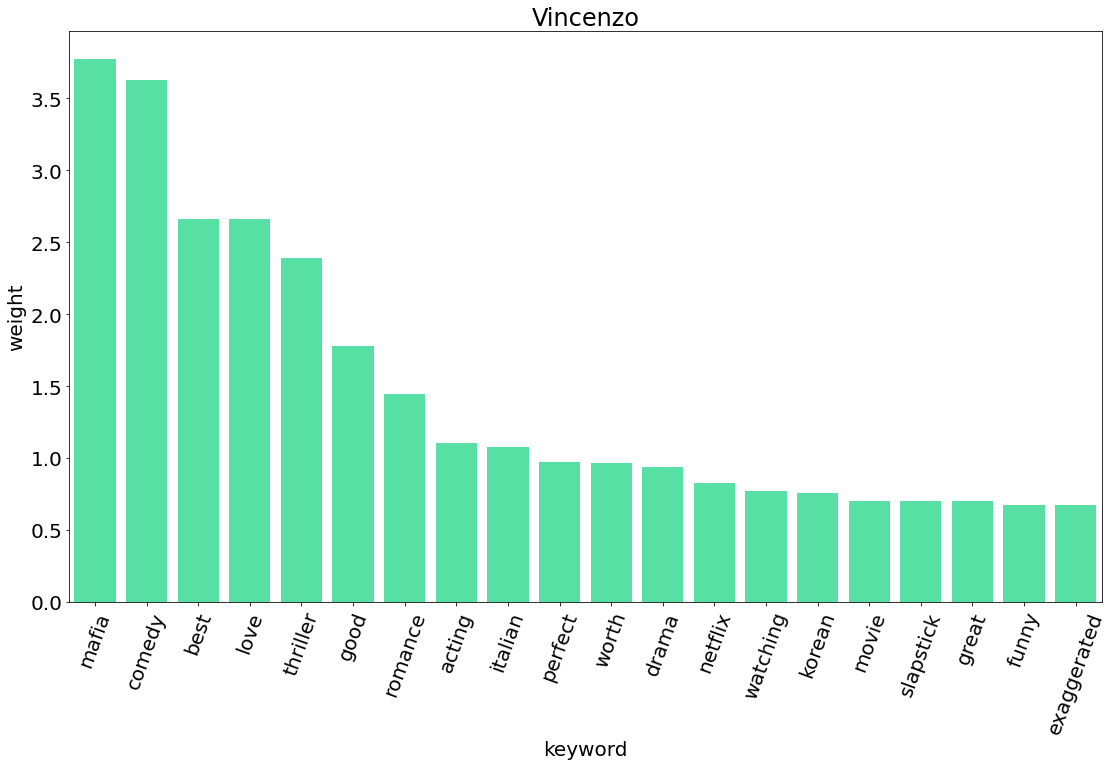
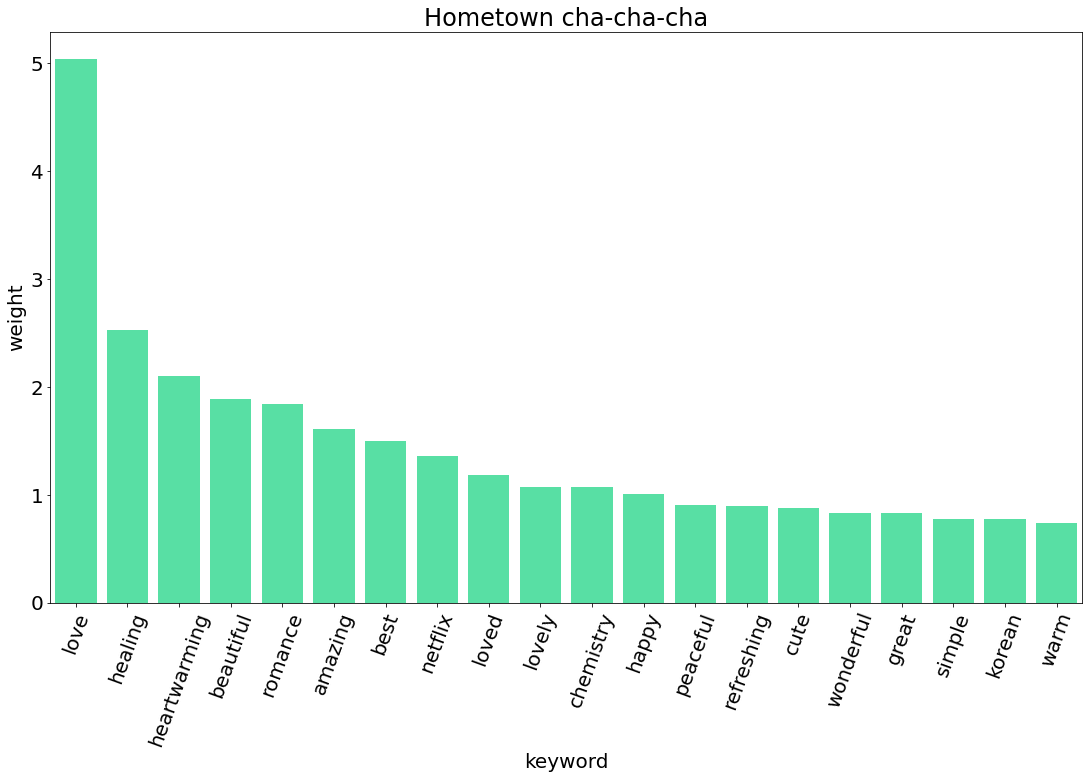
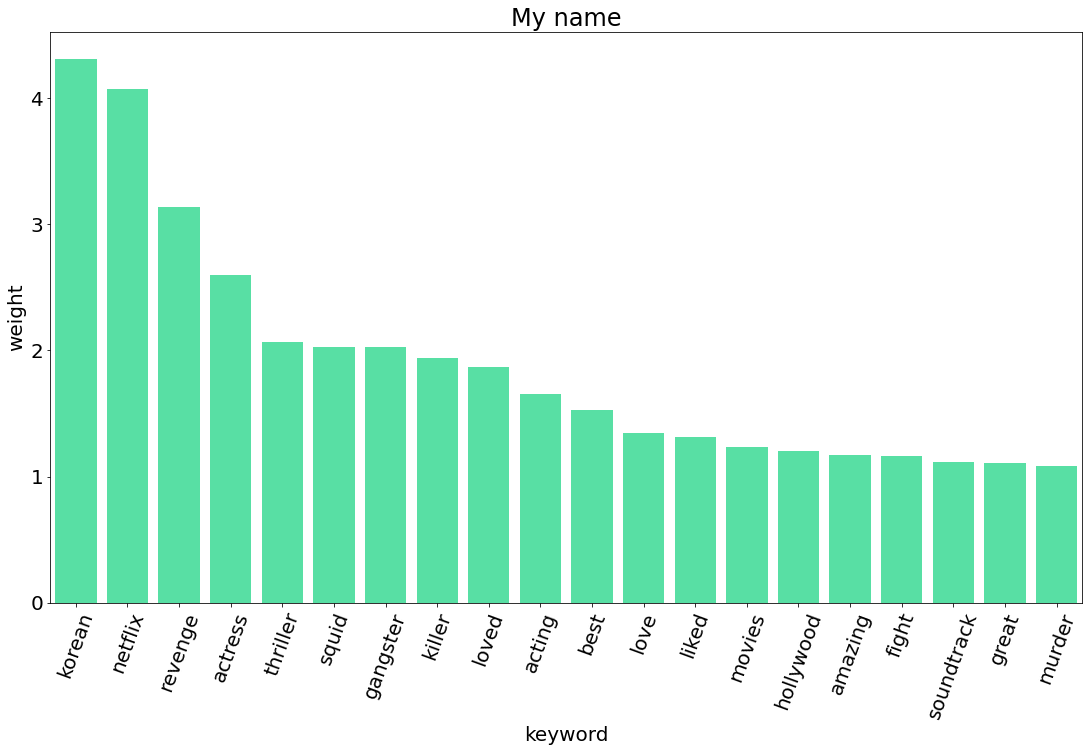
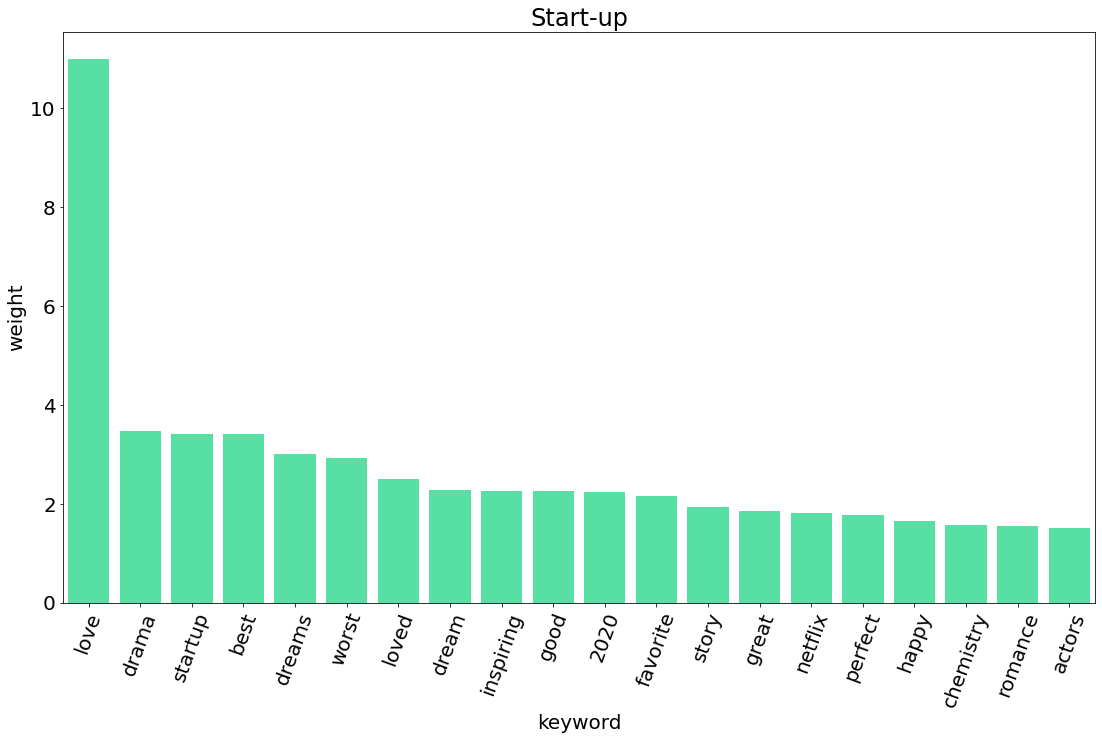
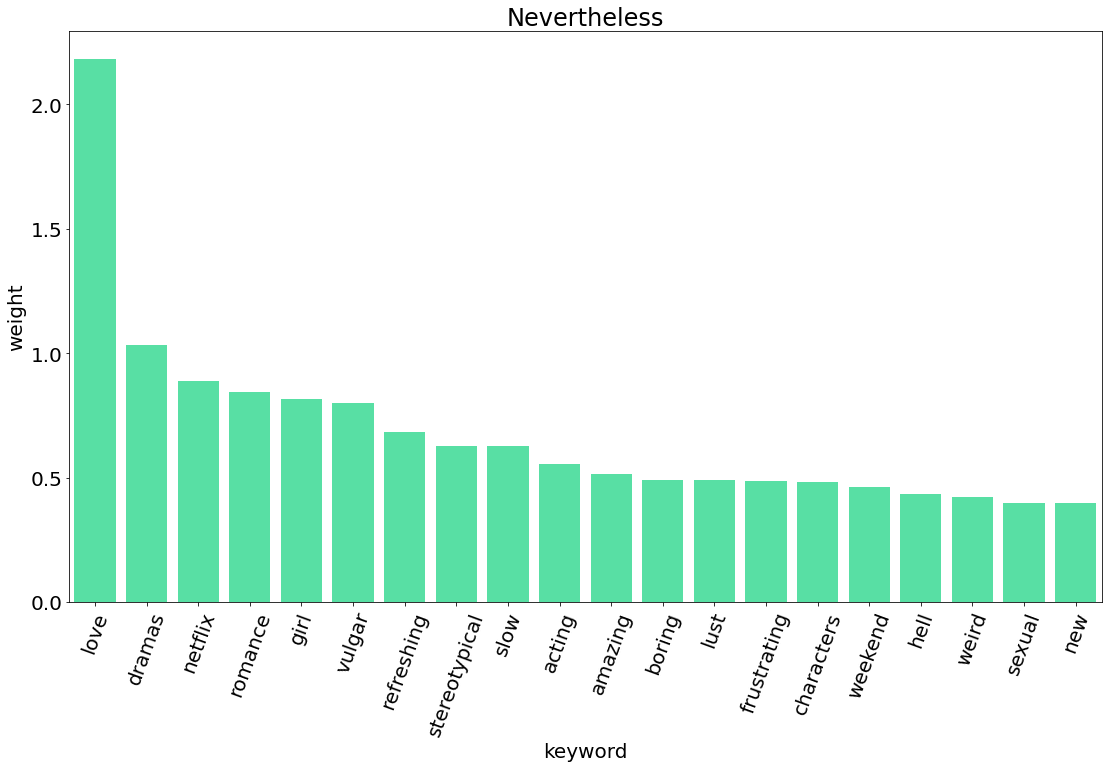
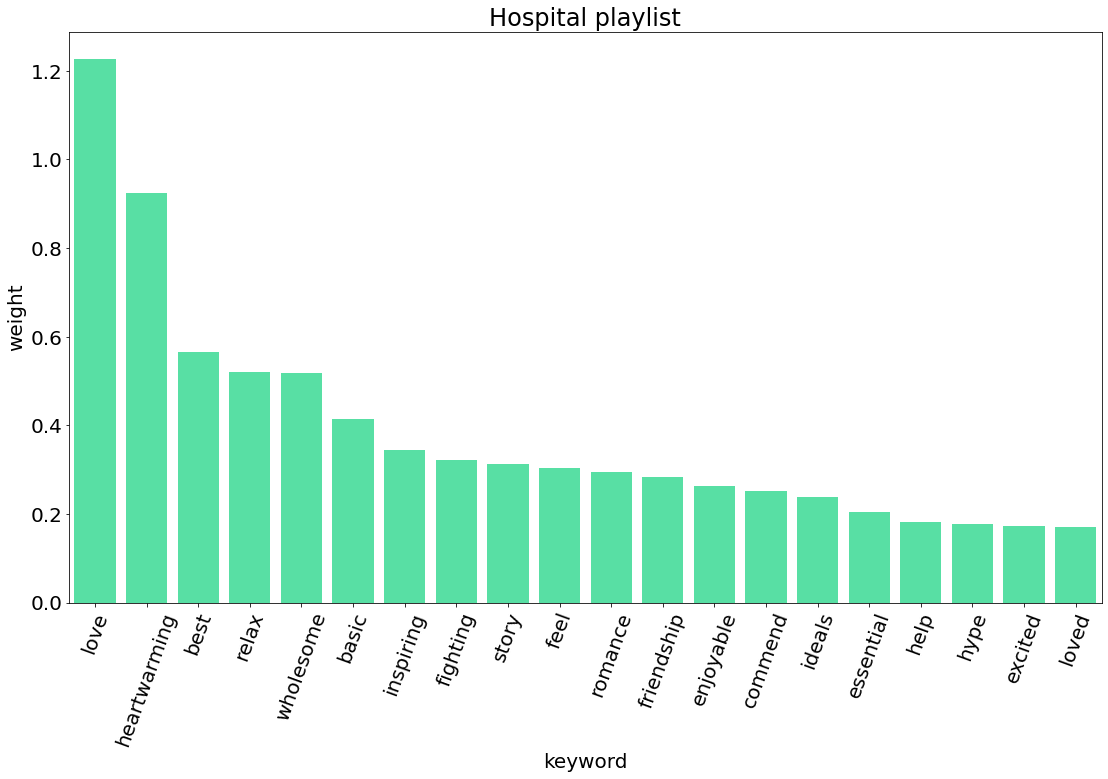
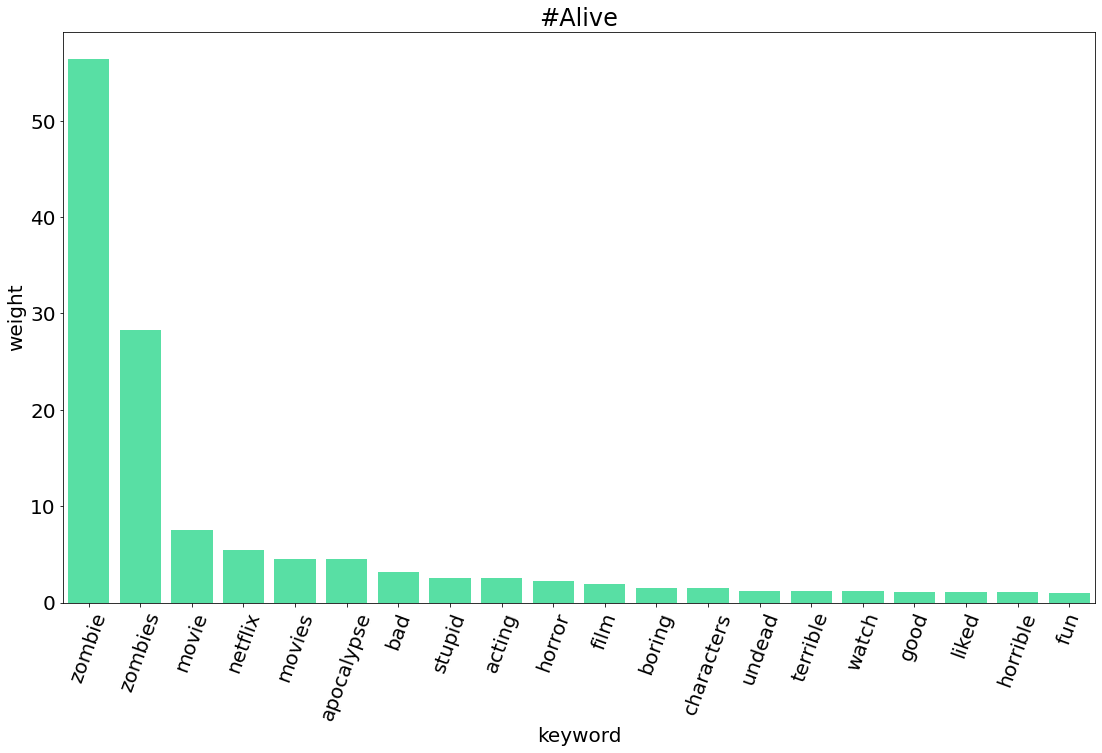
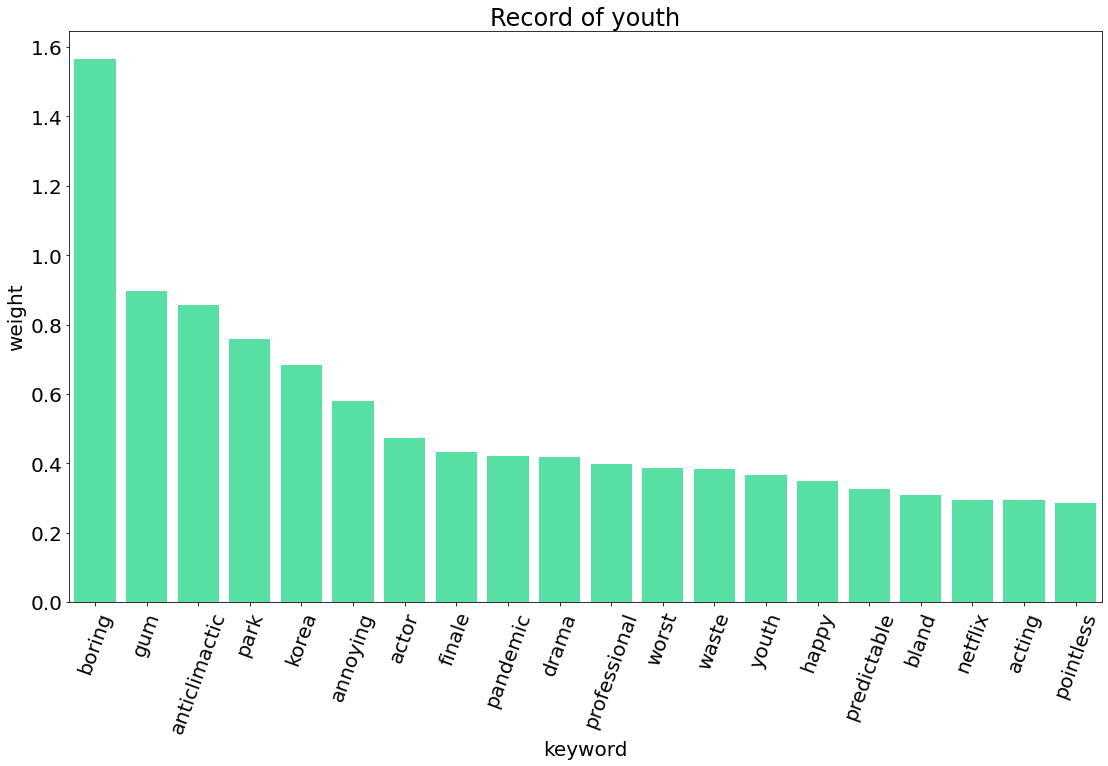
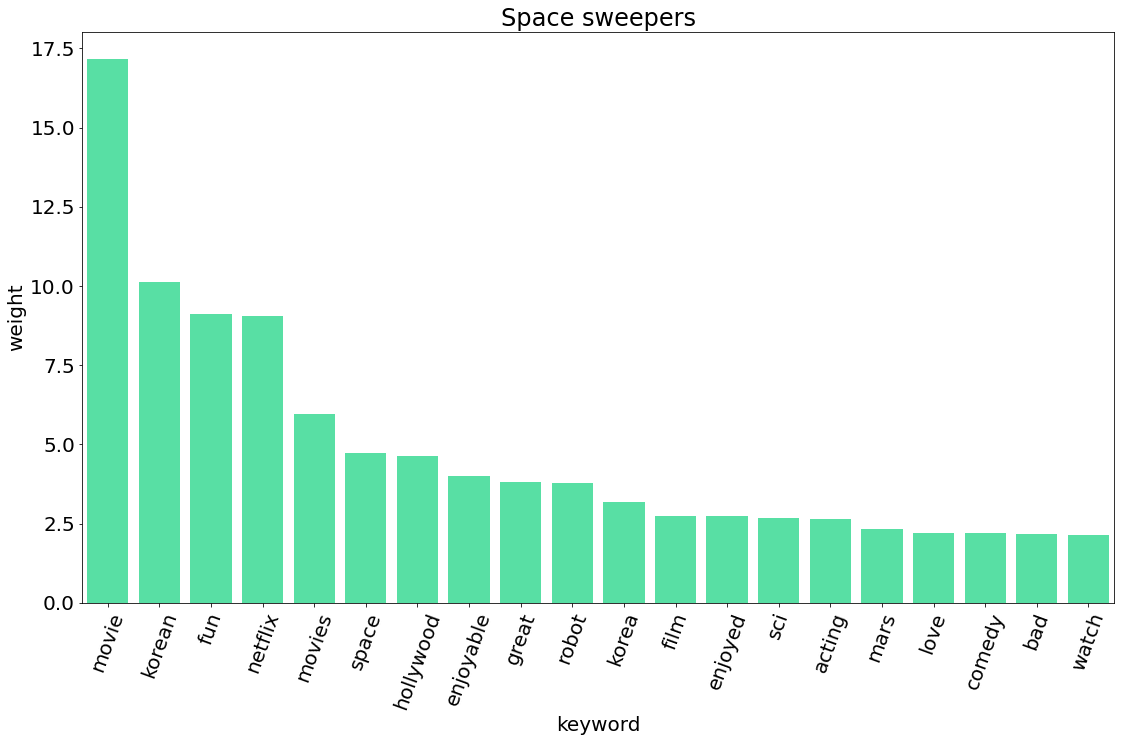
5. TF-IDF 비교
그렇다면 KeyBert의 성능이 더 나은지 보기 위해 기존에 단어의 중요도를 파악하기 위해 사용하던 TF-IDF와 비교해보겠습니다.
TF-IDF: 정보 검색과 텍스트 마이닝에서 이용하는 가중치로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치 (위키피디아).
| TF-IDF Keyword | TF-IDF score | keyBERT Keyword | KeyBERT score |
|---|---|---|---|
| far | 0.254888 | mafia | 3.7725 |
| series | 0.227292 | comedy | 3.6292 |
| great | 0.216156 | best | 2.6592 |
| is | 0.200286 | love | 2.6583 |
| which | 0.181828 | thriller | 2.3891 |
| so | 0.174995 | good | 1.7765 |
| for | 0.165621 | romance | 1.4485 |
| episodes | 0.140714 | acting | 1.1075 |
| flaws | 0.135521 | italian | 1.0790 |
| hell | 0.135521 | perfect | 0.9724 |
딱 봐도 KeyBERT를 통해 추출한 키워드가 훨씬 의미있다는 것을 볼 수 있습니다. TF-IDF를 통해 추출된 단어는 의미없는 단어를 제거하기 위해 전처리가 많이 필요할 것 같아 보이지만, KeyBERT는 별도의 전처리 과정 없이도 만족할만한 결과를 얻을 수 있습니다.
