저는 얼마 전까지만 해도 리뷰 분석을 위해 LDA 토픽 모델링을 적극적으로 활용했습니다. 다른 분석들 보다도 어떤 주제에 대해 여론이 형성되었는지 확인하기 편리해서 특히 연구를 시작하는 단계에서 한번 해볼만한 분석이죠. 물론 토픽모델링 자체로도 하나의 연구가 될 수도 있고요! 이번에는 LDA 토픽 모델링으로 콘텐츠 리뷰를 분석해보겠습니다.
1. 데이터 전처리
from konlpy.tag import Mecab
from tqdm import tqdm
import re
import pickle
import csv
import pandas as pd
from pandas import DataFrame
import numpy as np우선 데이터를 수집해보겠습니다. 콘텐츠에 대한 의견이 담겨있는 많은 텍스트 데이터가 필요하겠죠. 저는 트위터를 선택했고, 넷플릭스 드라마 <스위트홈>에 대한 트윗을 분석하기로 했습니다. 데이터는 아래처럼 수집되었습니다.
title = '스위트홈.csv'
데이터를 보니 별다른 내용 없이 URL만 있는 경우가 많았는데요, 이런 경우에는 시청자의 의견이 포함되었다고 보기 어렵겠죠. 이런 데이터는 삭제했습니다. 이후 한국어 텍스트만 보기 위해 기본적인 텍스트 정제를 했습니다.
def clean_text(text):
text = text.replace(".", "").strip()
text = text.replace("·", " ").strip()
pattern = '[^ ㄱ-ㅣ가-힣|0-9]+'
text = re.sub(pattern=pattern, repl='', string=text)
return text그리고 문장을 토큰화 해야 합니다. 저는 KoNLPy Mecab 태그 중 일반명사, 고유명사, 형용사, 어근만 추출하도록 하겠습니다. Mecab 품사는 이 문서에 설명되어 있습니다 (https://docs.google.com/spreadsheets/d/1OGAjUvalBuX-oZvZ_-9tEfYD2gQe7hTGsgUpiiBSXI8/edit#gid=0).
def get_nouns(tokenizer, sentence):
tagged = tokenizer.pos(sentence)
nouns = [s for s, t in tagged if t in ['NNG', 'NNP', 'VA', 'XR'] and len(s) >1]
return nouns
def tokenize(df):
tokenizer = Mecab(dicpath='/usr/local/lib/mecab/dic/mecab-ko-dic')
processed_data = []
for sent in tqdm(df['text']):
sentence = clean_text(str(sent).replace("\n", "").strip())
processed_data.append(get_nouns(tokenizer, sentence))
return processed_data그 다음엔 이렇게 토큰화 된 데이터를 다른 파일로 저장하도록 합니다.
def save_processed_data(processed_data):
with open("tokenized_data_"+title, 'w', newline="", encoding='utf-8') as f:
writer = csv.writer(f)
for data in processed_data:
writer.writerow(data)
if __name__ == '__main__':
df = pd.read_csv("file_name.csv")
df.columns=['user', 'date', 'time', 'text', 'comment', 'like', 'share']
df.dropna(how='any')
processed_data = tokenize(df)
save_processed_data(processed_data)👉 아웃풋

그리고 분석을 위해서는 이걸 다시 리스트로 만들어야 합니다.
processed_data = [sent.strip().split(",") for sent in tqdm(open("tokenized_data_"+title,'r',encoding='utf-8').readlines())]
processed_data = DataFrame(processed_data)
processed_data[0] = processed_data[0].replace("", np.nan)
processed_data = processed_data[processed_data[0].notnull()]
processed_data = processed_data.values.tolist()
processed_data2=[]
for i in processed_data:
i = list(filter(None, i))
processed_data2.append(i)
processed_data = processed_data2
processed_data👉 아웃풋
[['스위트', '새벽', '시간'],
['스위트', '송강'],
['스위트', '스위트', '나용'],
['스위트'],
['스위트'],
['앞자리', ...2. LDA 토픽모델링
2.1 Bag of words
LDA 토픽모델링을 하는데 활용할 수 있는 패키지가 하나는 아니겠지만, 가장 많이 활용하는 패키지는 Gensim일 것 같습니다. "인간을 위한 토픽 모델링 (topic modelling for humans)"라는 모토답게 공식 다큐멘테이션만 봐도 이해할 수 있도록 쉬운 문법으로 이루어져 있습니다. LDA 모델 뿐만 아니라 Word2vec 모델도 제공합니다(https://radimrehurek.com/gensim/auto_examples/tutorials/run_lda.html#). Gensim을 설치한 후 필요한 패키지를 import 해줍니다.
from gensim.models.ldamodel import LdaModel
from gensim.models.callbacks import CoherenceMetric
from gensim import corpora
from gensim.models.callbacks import PerplexityMetric
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)첫번째로 Bag of words라고 하는 단어 가방을 만들기 위해 고유한 단어들의 사전을 만들어야 합니다. 사전에는 단어와 고유 번호 정보가 들어있습니다.
dictionary = corpora.Dictionary(processed_data)사전은 필터링을 할 수 있습니다. 너무 흔한 단어나 너무 독특한 단어는 제외하는 것입니다. 예를 들어 본 분석에서는 "스위트홈"과 같은 단어는 너무 자주 등장할텐데, 이렇게 흔한 단어는 의미가 없을 수 있죠. 반대로 빈도가 1인 단어가 포함되면 너무 많은 단어가 생겨 분석에 혼선을 줄 수 있습니다. 따라서 저는 빈도가 2 이상인 단어와 전체의 50%로 이상 차지하는 단어는 필터링했습니다.
dictionary.filter_extremes(no_below=2, no_above=0.5)이렇게 사전이 만들어지면 사전 속의 단어가 문장에서 몇 번 출현하는지 빈도를 세서 벡터화 합니다. 이걸 바로 bag of words라고 하고, 이렇게 구조화된 언어를 코퍼스라고 합니다.
corpus = [dictionary.doc2bow(text) for text in processed_data]2.2 모델링
다음은 본격적인 모델링입니다. 조정 가능한 파라미터가 굉장히 많고, 이걸 어떻게 설정하느냐에 따라 걸리는 시간이나 결과도 천차만별입니다.
class gensim.models.ldamodel.LdaModel(corpus=None, num_topics=100, id2word=None, distributed=False, chunksize=2000, passes=1, update_every=1, alpha='symmetric', eta=None, decay=0.5, offset=1.0, eval_every=10, iterations=50, gamma_threshold=0.001, minimum_probability=0.01, random_state=None, ns_conf=None, minimum_phi_value=0.01, per_word_topics=False, callbacks=None, dtype=<class 'numpy.float32'>)그중에서도 반드시 조정이 필요한 할 변수는 num_topics, chunksize, passes, interations, eval_every입니다. 각 변수를 간단하게 설명하자면,
📌 num_topics: 생성될 토픽의 개수
📌 chunksize: 한번의 트레이닝에 처리될 문서의 개수
📌 passes: 전체 코퍼스 트레이닝 횟수
📌 interations: 문서 당 반복 횟수
물론 이 파라미터를 다른 숫자로 여러번 해서 가장 정확도 높은 모델을 선택하는 것이 가장 좋습니다. 모델의 정확도는 토픽의 일관성으로도 볼 수 있을텐데, 토픽의 일관성은 Coherence를 보면 됩니다. 파라미터 eval_every=1로 설정하여, 매 pass마다 문서의 Convergence 평가하고, 대부분의 문서가 포함되는 pass를 선정할 수도 있습니다.
그리하여! 저는 아래와 같이 설정해 모델링 했습니다. eval_every는 시간이 오래 걸리므로 이번에는 None으로 설정하겠습니다. alpha, eta 는 모두 auto로 해줍니다.
num_topics = 5
chunksize = 2000
passes = 20
iterations = 400
eval_every = None
temp = dictionary[0]
id2word = dictionary.id2token
model = LdaModel(
corpus=corpus,
id2word=id2word,
chunksize=chunksize,
alpha='auto',
eta='auto',
iterations=iterations,
num_topics=num_topics,
passes=passes,
eval_every=eval_every
)그리고 토픽이 어떻게 형성되었는지, Coherence는 적당하게 나왔는지 확인해보겠습니다. 하나의 토픽 당 20개의 단어가 기본으로 보여지지만, 이는 변경 가능합니다.
top_topics = model.top_topics(corpus) #, num_words=20)
# Average topic coherence is the sum of topic coherences of all topics, divided by the number of topics.
avg_topic_coherence = sum([t[1] for t in top_topics]) / num_topics
print('Average topic coherence: %.4f.' % avg_topic_coherence)
from pprint import pprint
pprint(top_topics)👉 아웃풋
Average topic coherence: -5.5557.
[([(0.06853353, '괴물'),
(0.04417699, '송강'),
(0.037925135, '생각'),
(0.036093775, '현수'),
(0.029977145, '트친'),
(0.02422037, '얘기'),
(0.021502791, '원작'),
(0.020061782, '은혁'),
(0.015362978, '장면'),
(0.0135506485, '은유'),
(0.013274875, '탐라'),
(0.01321878, '아저씨'),
(0.012525685, '인간'),
(0.012497223, '지수'),
(0.011028776, '소리'),
(0.010934056, '세계관'),
(0.010197583, '이야기'),
(0.008990835, '상욱'),
(0.00896408, '마음'),
(0.008290118, '주인공')],
...3. 시각화
위의 결과만으로도 충분히 이해가 되긴 하지만, 자동으로 시각화를 할수도 있습니다. 먼저 pyLDAvis를 설치해주고 패키지를 import합니다.
import pickle
import pyLDAvis.gensim_models as gensimvis
import pyLDAvis
from gensim.models.coherencemodel import CoherenceModel
import matplotlib.pyplot as pltpyLDAvis가 Gensim 함수를 지원하기 때문에 코드는 간단합니다.
lda_visualization = gensimvis.prepare(model, corpus, dictionary, sort_topics=False)
pyLDAvis.save_html(lda_visualization, 'file_name.html')👉 아웃풋
그럼 아래와 같은 html 파일이 만들어집니다. 토픽 별로 단어와 빈도를 확인할 수 있습니다.
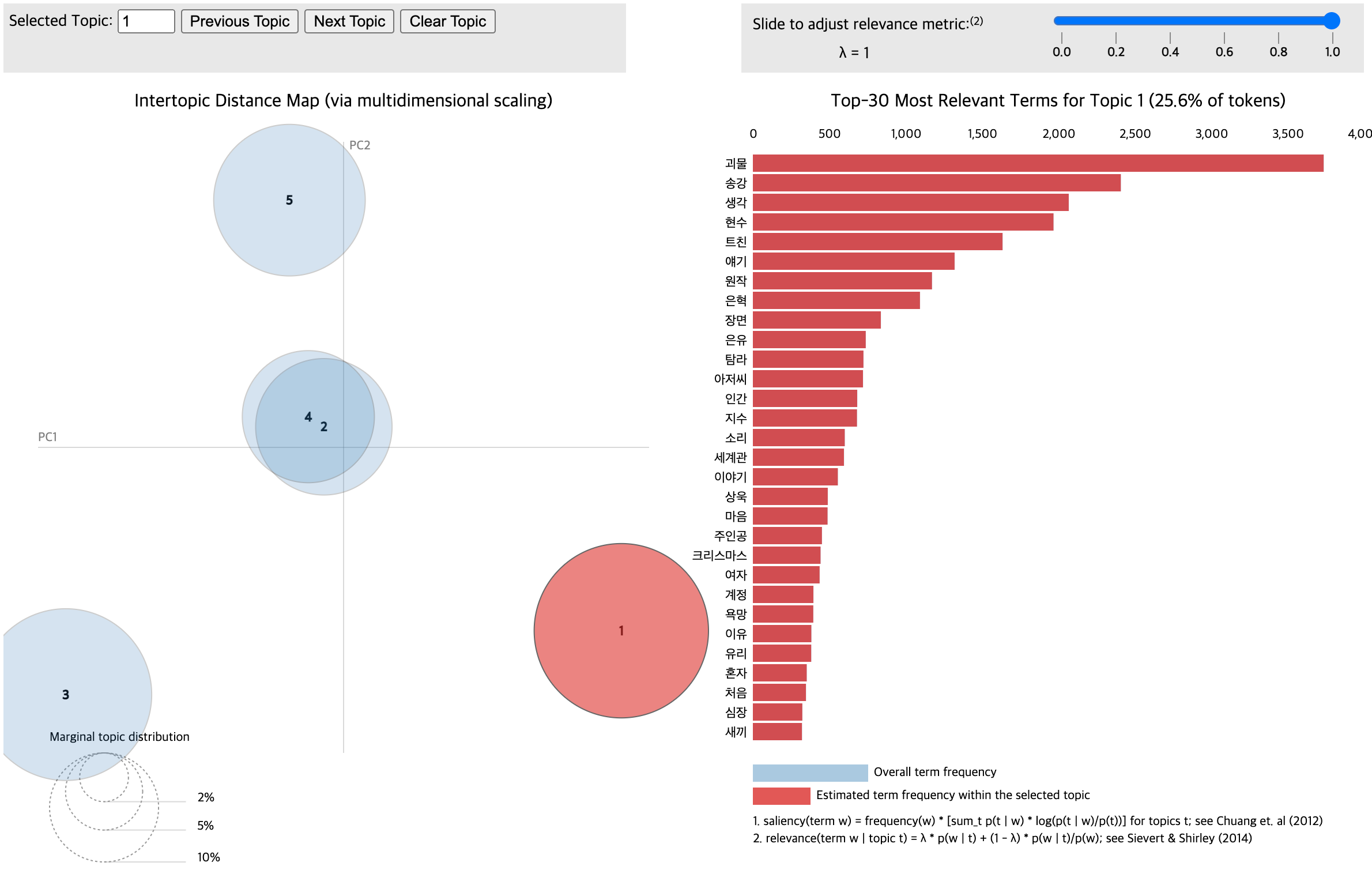
3.1. 결과 해석
LDA를 활용한 토픽 모델링은 여기까지로, 이제 각각의 토픽이 무엇을 의미하는지 파악하는 것은 사람의 몫입니다. 토픽에 해당하는 단어들을 보고 왜 이 단어들이 하나의 토픽으로 뭉쳐졌을지 추론한 뒤, 토픽에 이름을 붙입니다. 즉, 라벨링을 하는 것이죠. 저는 아래와 같이 라벨링을 해봤습니다.
📌 토픽 1. 스토리
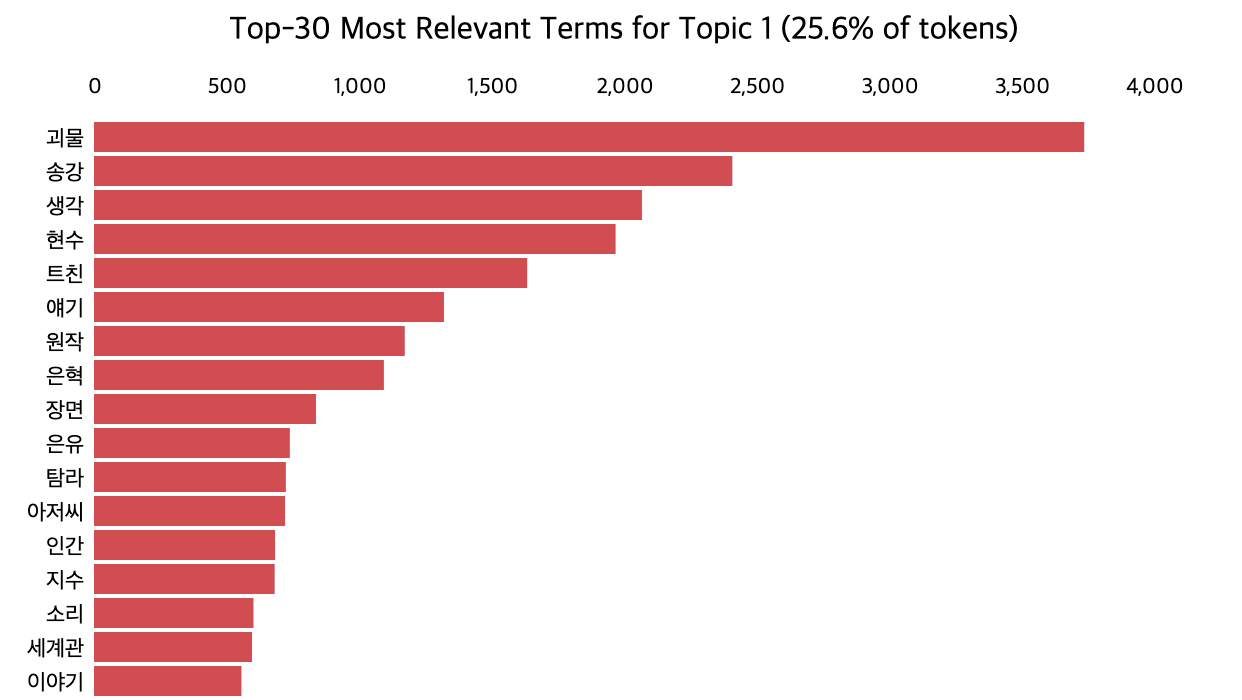
📌 토픽 2. 시청 행태
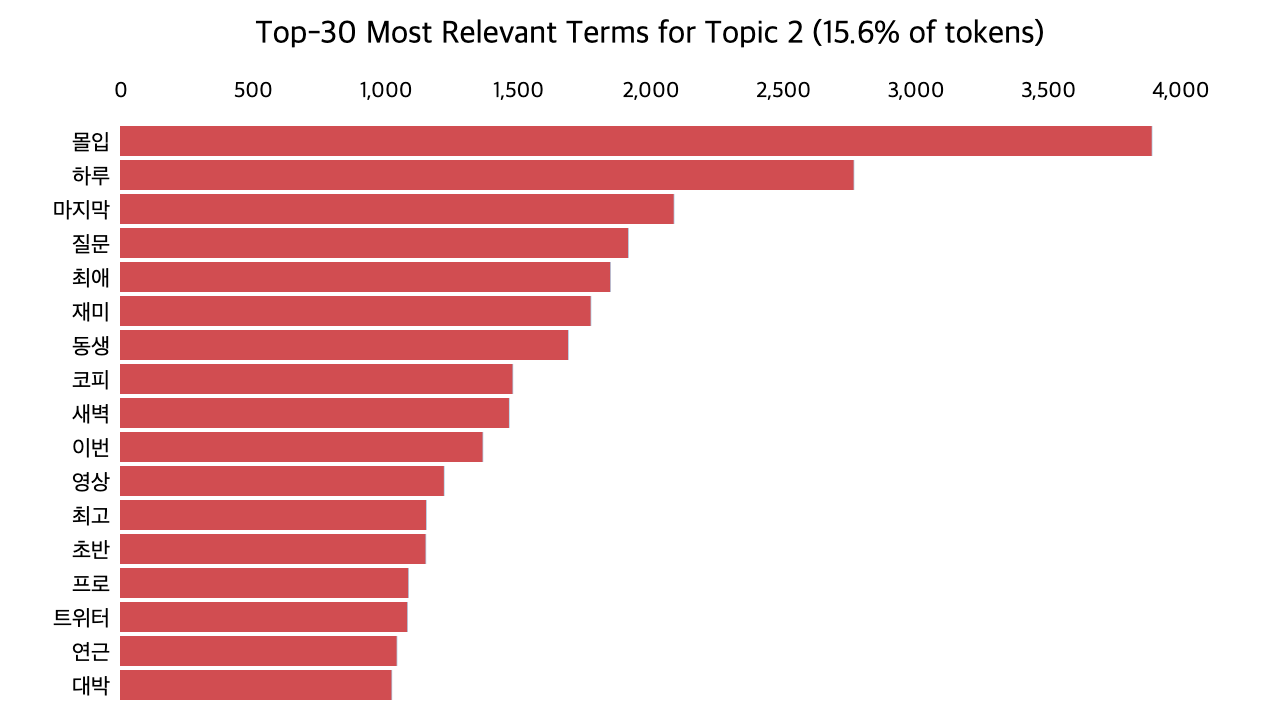
📌 토픽 3. 연출
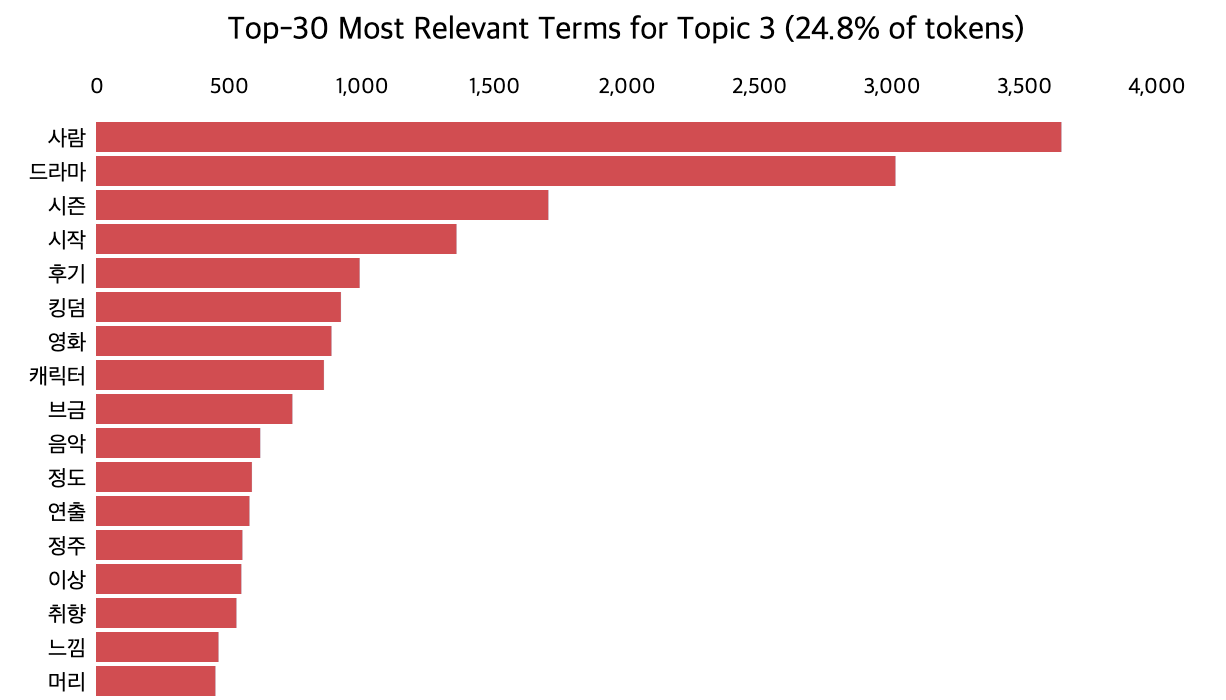
📌 토픽 4. 연관 작품
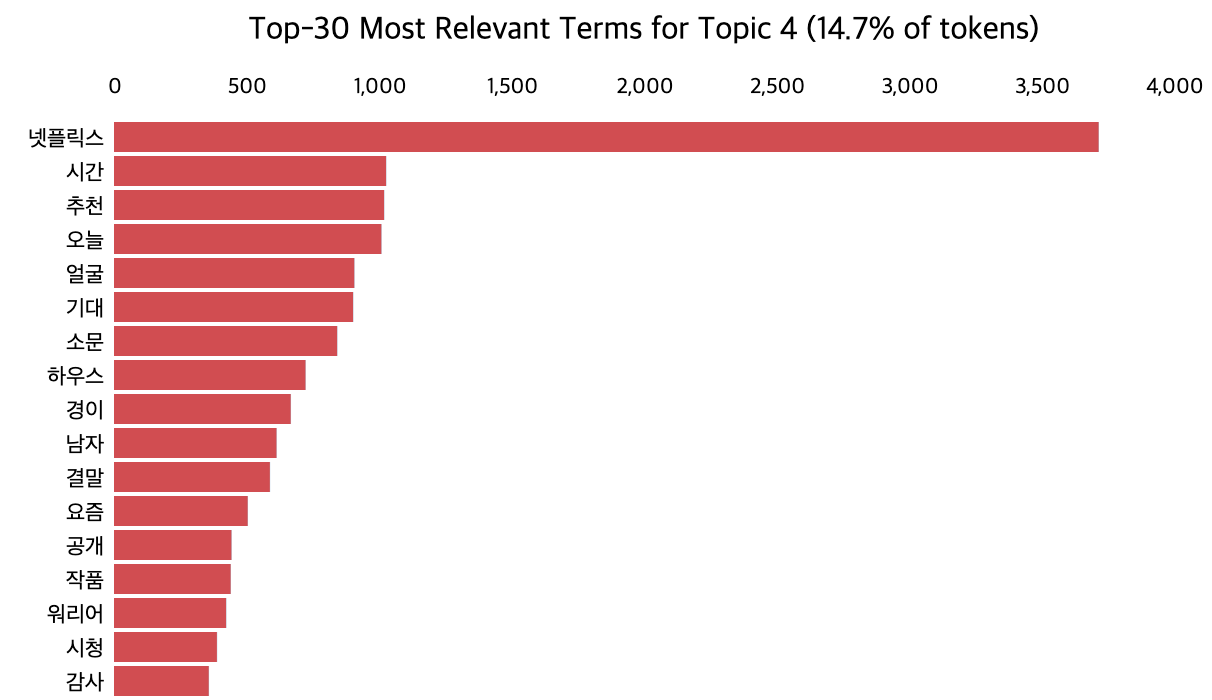
📌 토픽 5. 배우
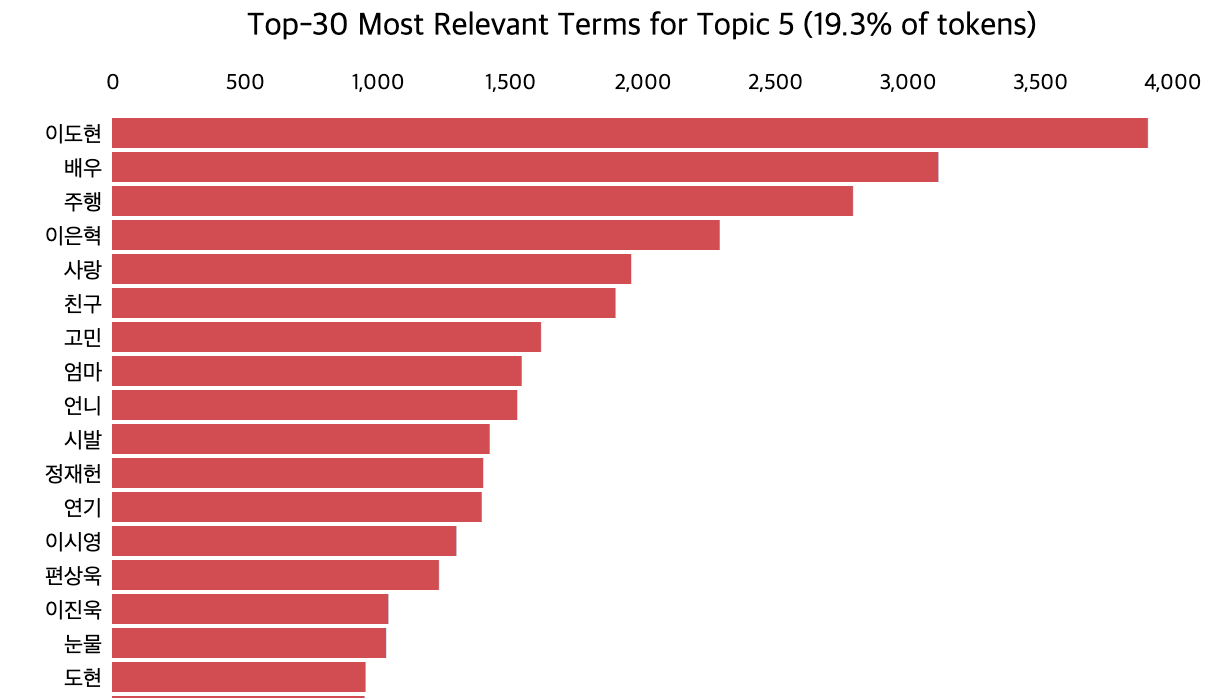
저는 이 정도로 정리해봤는데요, 토픽 모델링의 특성 상 라벨링에는 다른 의견이 존재할 수도 있습니다. 하지만 라벨링을 할 때는 단어들을 보고 이들의 공통점을 최대한 잘 설명할 수 있는 토픽 이름을 지어야 합니다. 만약 여러 사람이 분석에 참여한다면 논의나 블라인드 라벨링 등의 방법을 통해 모두가 동의할만한 주제를 찾을 수 있습니다.



안녕하세요. 토픽 모델링을 해보고 싶어서 코드를 보고 있는데요..
저는 코랩을 사용했습니다.
안되는 것이 있어 여쭤보는데요....
토큰화된 데이터를 저장하는 코드의 title은 무엇을 의미하는지 잘 모르겠어서 문의 드립니다.
"NameError: name 'title' is not defined" 오류가 발생하거든요.. 답변 주시면 감사하겠습니다.