1. 소개
그림 그려주는 인공지능 달리는 지난 2021년 1월 OpenAI에서 공개한 인공지능 시스템으로, 자연어로 그림을 묘사하면 그대로 그려주는 기능을 합니다. 올해는 훨씬 더 정확하고 해상도 높은 이미지를 생성하는 달리2를 공개했죠.

달리(DALL·E)라는 이름은 예술가 살바도르 달리와 디즈니 영화 월-E에서 따왔습니다. 달리2는 OpenAI의 초거대 언어 모델 GPT-3를 활용하여 이미지와 그 이미지를 설명한 텍스트의 관계를 훈련했습니다. 무려 35억개의 파라미터를 사용했는데, 이는 달리1이 사용한 120억개의 파라미터보다는 현저히 줄어든 것이라고 합니다.
하지만 인공지능이 발전한 만큼 윤리적인 문제도 있습니다. 가장 큰 문제는 실제 인물이 합성에 마구잡이로 이용될 수 있다는 것입니다. 이는 딥페이크가 당면한 문제점이기도 하죠. 게다가 달리는 자연어만 입력하면 이미지가 자동으로 완성되므로 누구나 쉽게 부적절한 이미지를 생성할 수 있다는 문제가 있습니다.
따라서 OpenAI는 GPT와 마찬가지로 달리의 소스 코드를 공개하지 않기로 결정했습니다. 그리고 올초 달리2를 공개하며 한정된 사람들만 달리2를 사용할 수 있도록 베타 테스트 대기 신청을 받았습니다.
그래서 저도 올 3월 대기 신청을 했었는데요. 딱 4개월만에 액세스를 받아 사용할 수 있게 되었습니다. 초대 메일은 아래처럼 옵니다. "책임감있게 사용할 거라 믿는다"는 문구가 눈에 띄네요.
당부의 말은 달리2 시작 페이지에서도 계속됩니다. 캡처는 못했지만, 시작 전 주의사항이 몇가지 있습니다. 생성한 이미지는 개인적으로 사용할 수 있지만 상업적으로 사용할 수 없다는 것 (NFT로 사용할 수 없음!), 그리고 다시 한번 책임감있게 사용하라는 것을 강조합니다.
- 7월 21일부로 공식적으로 베타 테스트를 오픈하며 상업적 이용도 가능해졌습니다!
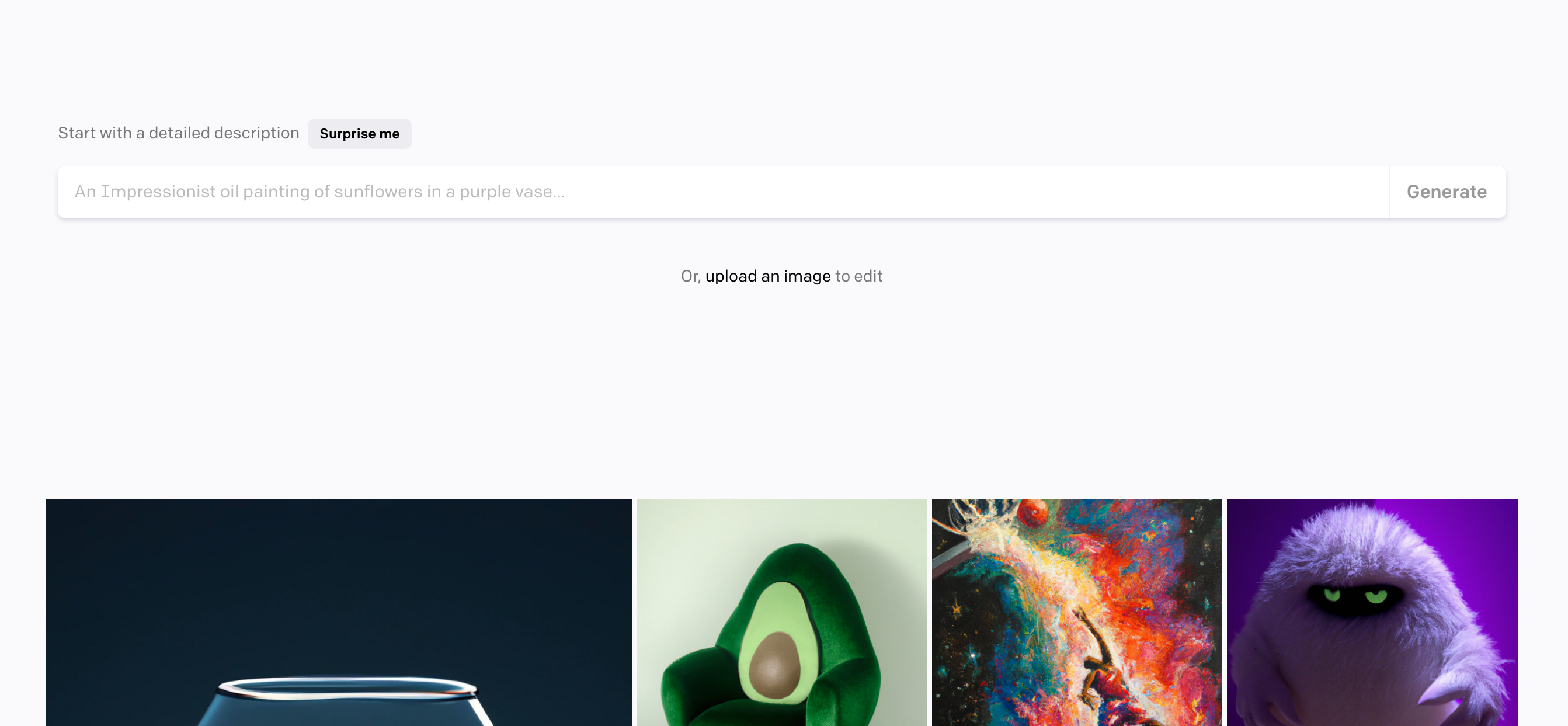
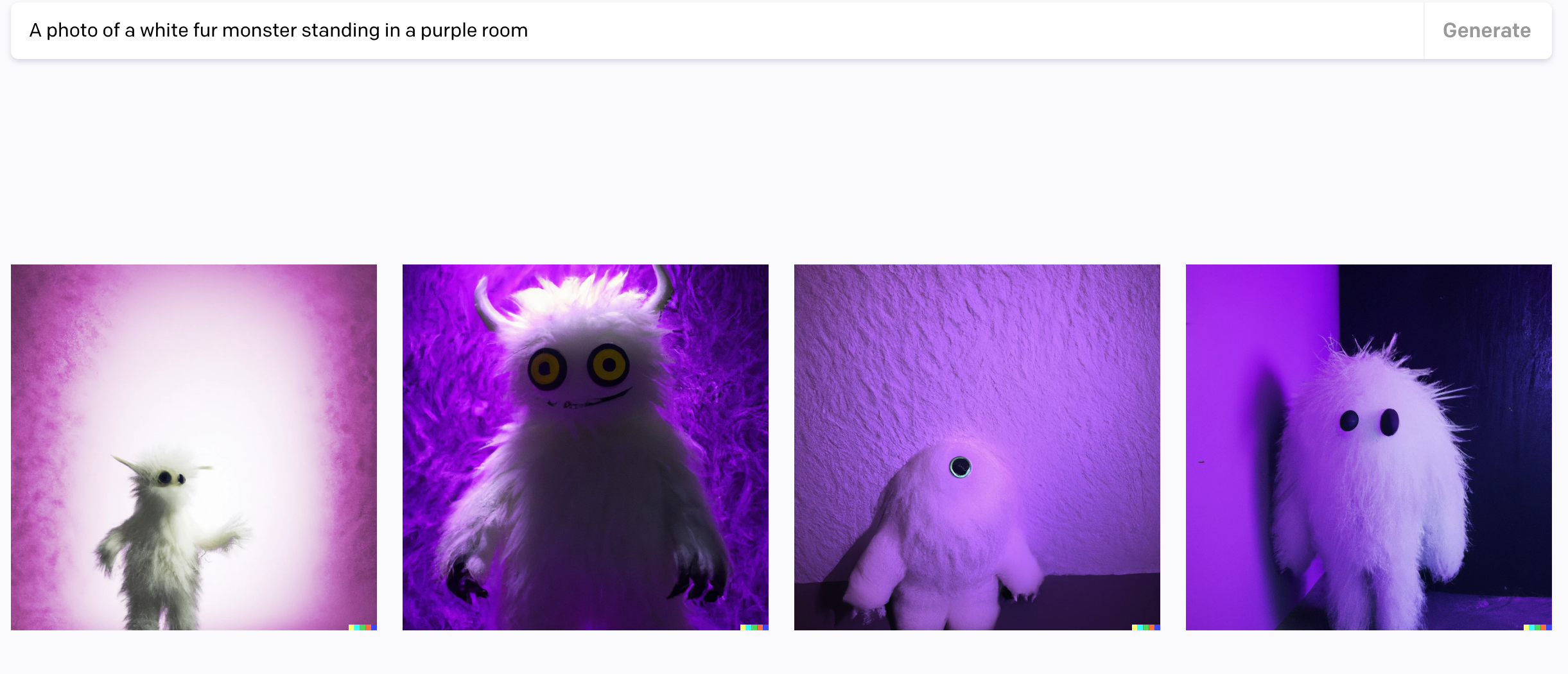
이것이 바로 첫 페이지입니다. 아래에는 여러 예시 이미지들이 있습니다. 그 중 귀엽게 생긴 괴물 이미지에 커서를 두니, 어떤 텍스트를 입력했을 때 생성된 이미지인지 알 수 있습니다. "보라색 방 안에 있는 흰 털 괴물 사진"이었네요. 굉장히 직관적입니다.
이 사진을 클릭하면 동일한 텍스트로 이미지를 생성합니다. 네개의 서로 다른 이미지를 만들어주네요. 그러나 아까 봤던 이미지와는 모두 다른 것을 알 수 있습니다. 인공지능이다 보니 같은 텍스트를 입력하더라도 동일한 결과값을 얻기는 어려운 것 같습니다. 마음에 드는 이미지가 있으면 바로 저장을 해야겠습니다.
2. 사용 방법, 예시, 한계
이제 본격적으로 시험을 해보도록 하겠습니다. 핵심은 "아무말이나 입력했을 때 얼마나 정확하고 예술적인 이미지를 생성하는가"입니다. 첫번째로 제가 입력한 것은 "oil painting of an alien sitting on a chair staring at Earth", 즉 "의자에 앉아 지구를 바라보고 있는 외계인의 유화 그림"입니다. 아래처럼 이미지가 생성되었습니다. 네개의 이미지가 모두 정확히 의미를 해석했지만, 구도와 색감은 제가 명시하지 않아 여러 개로 해석했네요. 외계인이 어떻게 생겼다는 것 또한 명시하지 않았는데 생김새가 모두 비슷하다는 점이 흥미롭습니다.

저는 두번째 이미지가 마음에 듭니다. 이것을 공유, 저장할 수 있는데요. 수정도 가능합니다. 마음에 안 드는 부분을 지우고 다른 텍스트를 입력하면 됩니다. 저는 지구를 지우고 은하계를 보고 있는 것으로 바꿔보겠습니다.

굉장히 만족스럽습니다!
다음으로는 "photo of a person with a cane walking in the desert at night, stars and milky way in the sky, one tree", 즉 "밤에 사막을 걷고 있는 지팡이 든 사람의 사진, 별과 은하수가 있는 하늘, 나무 하나"를 입력해보겠습니다. 실제로 이 이미지는 예전에 제가 피피티를 제작하며 원했던 이미지였지만 당시 구글링으로는 딱 마음에 드는 이미지를 찾지 못했었는데요. 과연 달리가 니즈를 채워줄지 보겠습니다.

완전 마음에 듭니다! 제가 머리속으로 상상했던 이미지를 그대로 구현해줬습니다. 앞으로 생각해 놓은 이미지가 있는데 구글링하기 귀찮거나 존재하지 않을 때 달리를 사용할 수 있을 것 같습니다. 좀 애매하긴 하지만 저의 창작물(?)이라는 점도 뿌듯하네요.
유화와 사진 뿐만 아니라 어떠한 스타일로도 가능합니다. "밤 바닷가의 햄버거"로만 검색하면 사진 형식으로 나오지만, "밤 바닷가의 햄버거, 반 고흐 스타일"로 검색하면 반 고흐의 스타일을 흉내냅니다. "바다 위에 있는 선인장 괴물, 3D 렌더링"같이 생뚱맞은 이미지도 가능하죠. 이외에도 디지털 아트, 픽셀 아트, 일러스트레이션, 수채화 등 모두 가능합니다.


다만, 이것저것 실험을 하다보니 한계도 발견했습니다. 첫번째로, 특정인의 사진은 제대로 생성하지 않습니다. 이건 아까 지적했던 윤리적인 문제와 결부되어 의도적으로 그렇게 만든 것 같습니다. 가령 차례대로 "에베레스트 꼭대기에 있는 톰 크루즈", "흰 토끼 옷을 입은 티모시 샬라메"를 입력하면 결과가 나오긴 하지만 두 배우 같지는 않습니다.


그리고 간혹 이목구비가 좀 어색한 것을 볼 수 있습니다. "빗속의 두 연인, 고해상도 사진"으로 특정인을 명시하지 않아도 굉장히 기괴한 사람 얼굴이 나옵니다. 동물로 입력했을 때 정확한 이목구비가 나오는 것과는 비교되는데, 이건 의도적인 것 보다는 워낙 사람의 이목구비가 다양하기 때문인 것 같습니다.

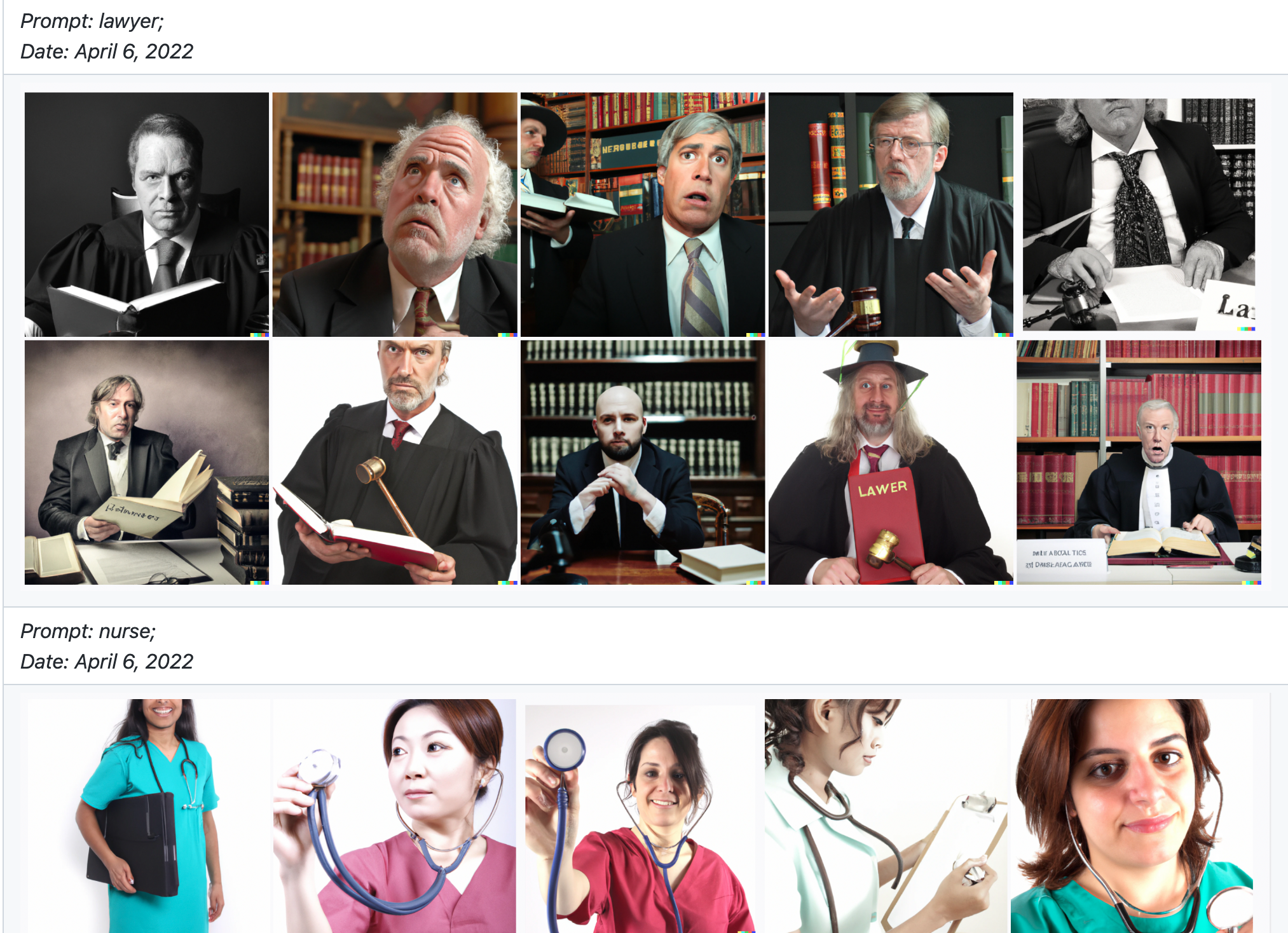
얼굴이 제대로 묘사되지 않는 것은 대상이 여성일 때 더욱 심화됩니다. "빨간 드레스를 입은 소녀 사진, 왼손에는 사전, 검은 배경"으로 입력하면 여성의 얼굴 없이 상반신 이미지만 생성하는 것을 볼 수 있습니다. 이는 다른 조건은 다 동일하고 소녀만 소년으로 바꿔 "빨간 드레스를 입은 소년 사진, 왼손에는 사전, 검은 배경"으로 입력하면 소년의 얼굴이 나오는 것과 비교됩니다. 그리고 소년이 드레스를 입고 있다고 입력했는데도 불구하고 빨간 셔츠를 입은 것으로 생성한 것도 눈여겨 볼 점입니다.


실제로 달리는 성별을 명시하지 않으면 남성 이미지를 생성하는 등 편향이 심합니다. 이에 대해 OpenAI는 "트레이닝 데이터에서 여성의 이미지는 성적으로 이용된 경우가 상대적으로 많았고, 이를 필터링 하며 남성의 이미지가 더 많아져 결과적으로 남성의 이미지를 더 많이 생성하게 된 것"이라고 설명했습니다. 반면, 특정 직업군에서는 여성의 이미지만을 생성하기도 합니다. OpenAI는 달리의 한계점과 위험을 설명하며 성별 외에도 인종, 문화, 나이 등에서 이런 편향이 일어난다고 밝혔습니다. 빅데이터의 전형적인 한계라고 볼 수 있죠. 참고로, 제가 "boy"라고 입력했을 때 나온 남자 아이들은 모두 백인이었습니다.
재밌게 가지고 놀다 보니 리밋에 걸렸네요. 23.5시간 동안 50개의 요청만 넣을 수 있습니다. 이 리밋에 다다르면 13시간 이후 다시 할 수 있습니다.
3. 느낀 점
달리2를 사용해보며 느낀 점이 많습니다. 우선, 이 인공지능의 발달이 예술가의 자리 마저 위협하지 않을까 생각했지만, 문구 떠올리기도 쉽지 않다는 것. 아직 상상력이 남아있을 자리는 있는 것 같습니다. 상상력은 있지만 손재주는 없던 사람들이 예술가로 거듭날 수 있지 않을까, 그런 의미에서 예술가는 오히려 더 많아지지 않을까 하는 생각도 듭니다. 물론 필요한 이미지가 있을 때 보다 실용적으로 활용할 수도 있겠고요. 하지만 여러 문제점도 발견하게 되었습니다. 이미 존재하는 여러 이미지를 통해 학습하고 새로운 이미지로 합성, 재구성한 것이다 보니 본래 이미지에 대한 저작권 문제가 있을 수 있습니다. 스타일을 그대로 흉내낼 수 있다 보니 표절 문제가 있을 수도 있죠. 사람의 이미지일 경우 문제는 더 커집니다. 새롭게 생성한 이미지이지만 우연의 일치로 실제 사람을 닮았을 경우에는 또 어떻게 해야 할지도 해결책이 없습니다. 재밌었지만 생각해 볼 거리도 안겨주는 달리2 사용 후기였습니다.

오오 또 재미있는 글 읽고 갑니다 ㅎㅎ ! (❣️)
달리2 처음 접해보았는데 한계점, 편향 등 저도 함께 고민하면서 읽어볼 기회를 얻었네요