
여느때처럼 미디엄을 살펴보다가 스포티파이를 이용한 재미있는 분석을 보고 고대로 따라해보기로 했습니다.
📌 저의 독창성이라고는 하나도 들어가지 않았습니다.
1. 준비
우선은 스포티파이 웹사이트에서 가입을 하고 Spotify for Developers에서 로그인을 해줍니다. 그리고 Create an app 버튼을 클릭하면 굉장히 간단한 과정을 통해 클라이언트 아이디와 비밀번호를 발급받을 수 있습니다.
그럼 api 패키지를 설치해주겠습니다.
!pip install spotipy그리고 발급받은 아이디와 비밀번호를 이용해 접속해줍니다.
import spotipy
from spotipy.oauth2 import SpotifyClientCredentials
client_credentials_manager = SpotifyClientCredentials(client_id='발급받은 아이디', client_secret='발급받은 비번')
sp = spotipy.Spotify(client_credentials_manager=client_credentials_manager)2. 데이터 가져오기
2.1. 트랙 데이터
먼저 트랙 데이터부터 가져와 보겠습니다. search 함수를 사용해 2021년 트랙만 검색합니다. 트랙은 어차피 한번에 50개밖에 서치가 안되므로 limit으로 50개로 확실히 한정해주고, 중첩 루프를 사용해 0-49, 50-99, ... , 950-999씩 가져와 저장하도록 합니다. 트랙의 아티스트, 제목, 아이디, 인기 등의 정보를 각각의 리스트에 저장합니다.
artist_name =[]
track_name = []
track_popularity =[]
artist_id =[]
track_id =[]
for i in range(0,1000,50):
track_results = sp.search(q='year:2021', type='track', limit=50, offset=i)
for i, t in enumerate(track_results['tracks']['items']):
artist_name.append(t['artists'][0]['name'])
artist_id.append(t['artists'][0]['id'])
track_name.append(t['name'])
track_id.append(t['id'])
track_popularity.append(t['popularity'])이렇게 만들어진 리스트를 데이터프레임으로 변환하겠습니다.
import pandas as pd
track_df = pd.DataFrame({'artist_name' : artist_name, 'track_name' : track_name, 'track_id' : track_id, 'track_popularity' : track_popularity, 'artist_id' : artist_id})
print(track_df.shape)
track_df.head()
2.2. 아티스트 데이터
앞서 가져온 트랙 데이터에는 아티스트의 이름과 아이디까지만 나와있는데요. 이제 아티스트 데이터를 받아와 각 아티스트 아이디에 추가 정보를 삽입해보겠습니다. 스포티파이의 artist 함수는 아티스트의 url, 팔로워수, 장르, 이미지, 이름, 타입, 인기 등의 정보를 받을 수 있습니다. 그중에서 인기, 장르, 팔로워수만 저장하겠습니다.
artist_popularity = []
artist_genres = []
artist_followers =[]
for a_id in track_df.artist_id:
artist = sp.artist(a_id)
artist_popularity.append(artist['popularity'])
artist_genres.append(artist['genres'])
artist_followers.append(artist['followers']['total'])이제 이 정보를 아까 만들었던 데이터프레임에 추가해줍니다.
track_df = track_df.assign(artist_popularity=artist_popularity, artist_genres=artist_genres, artist_followers=artist_followers)
track_df.head()
📌 이쯤되었다면 한 5분 정도 쉬어줍니다. 데이터를 한꺼번에 많이 받지 못하게 제한이 되어 있어서 아마 바로 밑의 코드를 실행하면 오류가 뜰 수 있습니다.

2.3. 오디오 데이터
스포티파이는 트랙에 대해 17개의 Audio features를 제공합니다. 특히 tempo, danceability, acousticness와 같이 음악의 특징을 정량적인 지표로 구분해놓고 있으므로, 이를 분석에 유용하게 사용할 수 있습니다.
track_features = []
for t_id in track_df['track_id']:
af = sp.audio_features(t_id)
track_features.append(af)
tf_df = pd.DataFrame(columns = ['danceability', 'energy', 'key', 'loudness', 'mode', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence', 'tempo', 'type', 'id', 'url', 'track_href', 'analysis_url', 'duration_ms', 'time_signature'])
for item in track_features:
for feat in item:
tf_df = tf_df.append(feat, ignore_index=True)
tf_df.head()
3. 전처리
최종적으로 만들어진 데이터프레임에서 url과 같은 필요없는 열은 제거해주겠습니다.
cols_to_drop2 = ['key','mode','type', 'url','track_href','analysis_url']
tf_df = tf_df.drop(columns=cols_to_drop2)
print(track_df.info())
print(tf_df.info())다음에는 데이터프레임의 info를 보고 데이터 타입을 바꿔주겠습니다.
track_df['artist_name'] = track_df['artist_name'].astype("string")
track_df['track_name'] = track_df['track_name'].astype("string")
track_df['track_id'] = track_df['track_id'].astype("string")
track_df['artist_id'] = track_df['artist_id'].astype("string")
tf_df['duration_ms'] = pd.to_numeric(tf_df['duration_ms'])
tf_df['instrumentalness'] = pd.to_numeric(tf_df['instrumentalness'])
tf_df['time_signature'] = tf_df['time_signature'].astype("category")
print(track_df.info())
print(tf_df.info())4. 간단한 분석
4.1. 가장 인기있는 2021년 트랙 Top 20
가장 간단하게 2021년 발매된 트랙 중 가장 인기있는 트랙이 무엇이었는지 보도록 하겠습니다. 트랙을 popularity를 기준으로 내림차순으로 정렬해줍니다.
track_df.sort_values(by=['track_popularity'], ascending=False)[['track_name', 'artist_name']].head(20)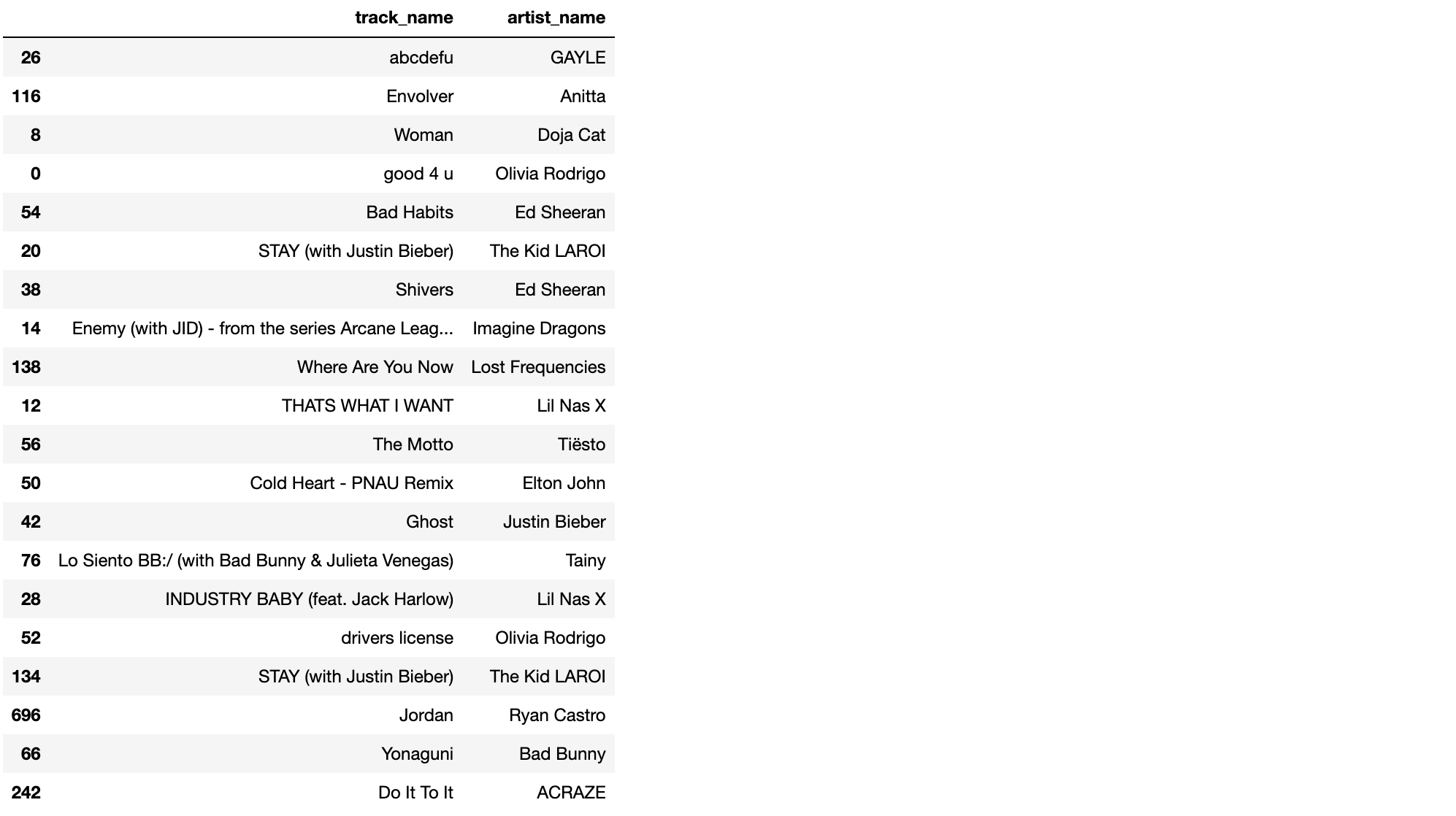
가장 인기있는 트랙은 abcdefu네요. 인스타그램과 틱톡 등 SNS에서 인기를 끈 것으로 알고 있습니다. 그런데 The Kid LAROI와 저스틴 비버의 Stay가 중복되어 나온 걸 볼 수 있습니다. 싱글로 발매되었다가 앨범에 수록되어 두개의 트랙이 있는 게 아닐까 싶네요. 그런데도 두 트랙 모두 20위 안에 들었다는 건...
📌 참고로, 아웃풋은 제 거나 미디엄 글의 결과와 다르게 나올 수 있습니다. 인기, 팔로워수 등은 데이터를 가져오는 현재 시점의 수치이기 때문입니다.
4.2. 가장 팔로워가 많은 아티스트 Top 20
이번에는 가장 팔로워가 많은 아티스트 20위를 보도록 하겠습니다. 마찬가지로 아티스트 팔로워수를 기준으로 내림차순으로 정렬해줍니다. 이때 데이터프레임은 아티스트 관련 열만 남겨 새로 생성해주겠습니다. 중복된 아티스트는 하나만 남깁니다.
by_art_fol = pd.DataFrame(track_df.sort_values(by=['artist_followers'], ascending=False)[['artist_followers','artist_popularity', 'artist_name','artist_genres']])
by_art_fol.astype(str).drop_duplicates().head(20)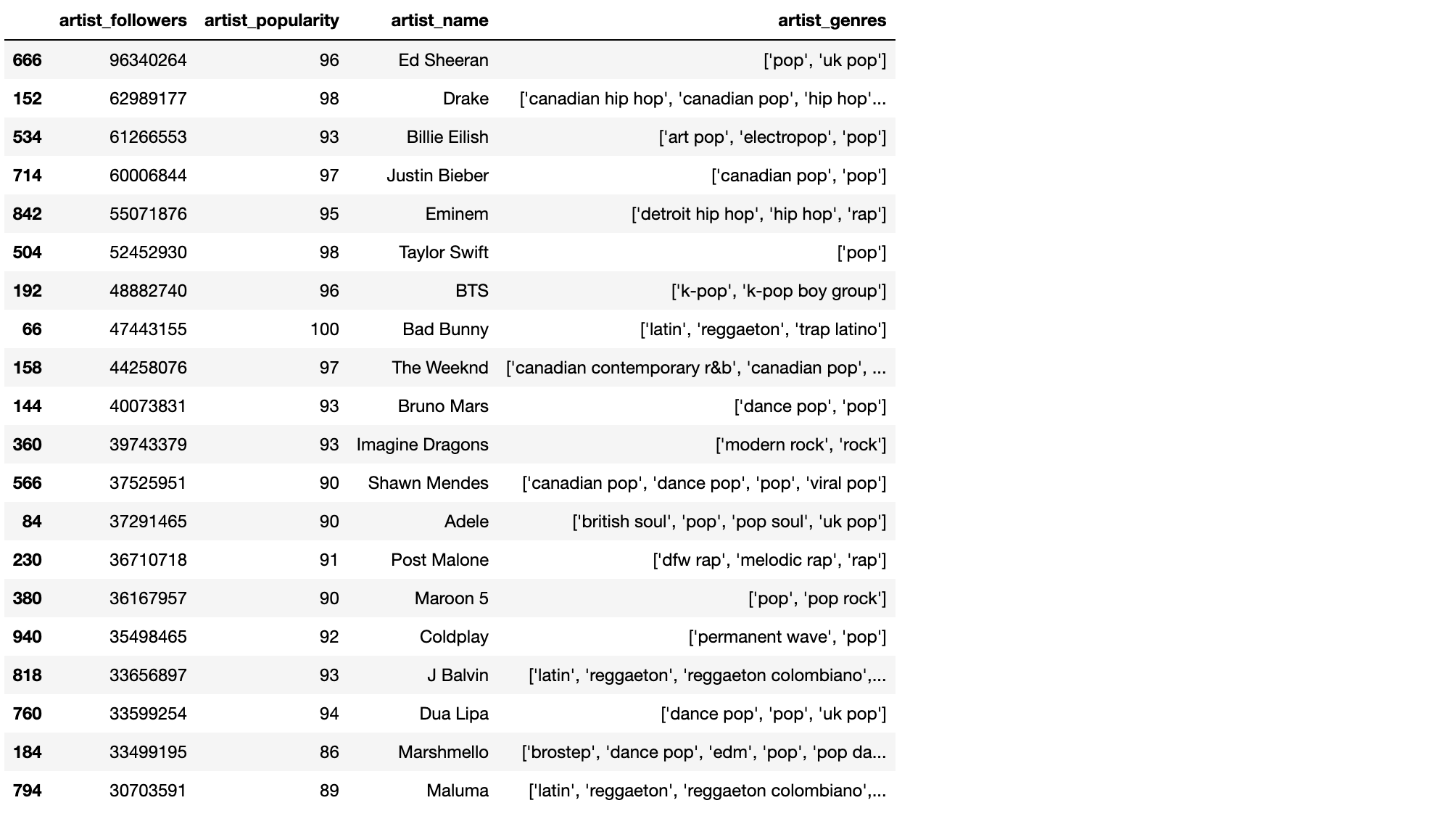
에드 시런이 9천만의 팔로워를 보유하며 가장 팔로워가 많은 것으로 나타났고, 그 뒤를 드레이크, 빌리 아일리시, 저스틴 비버가 따릅니다. BTS도 7위에 올랐네요.
4.3. 장르별 관계된 아티스트 수
아티스트 팔로워수를 보니 artist_genres도 눈에 띕니다. 스포티파이는 트랙별로 장르를 구분하지 않고 아티스트의 장르를 구분하는데요. 한 아티스트 당 여러개의 장르가 있는데 어떤 장르에 관련된 아티스트가 많은지 숫자를 확인해보겠습니다.
def to_1D(series):
return pd.Series([x for _list in series for x in _list])
to_1D(track_df['artist_genres']).value_counts().head(20)progressive house 198
trance 173
pop 154
uplifting trance 139
edm 133
progressive trance 133
pop dance 119
rap 103
dance pop 61
hip hop 60
contemporary country 54
trap 53
rock 47
mellow gold 42
art rock 42
folk rock 41
roots rock 39
new wave pop 38
power pop 38
pub rock 38
dtype: int64이것을 그래프로 나타내 보겠습니다.
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize = (14,4))
ax.bar(to_1D(track_df['artist_genres']).value_counts().index[:10],
to_1D(track_df['artist_genres']).value_counts().values[:10])
ax.set_ylabel("Frequency", size = 12)
ax.set_title("Top genres", size = 14)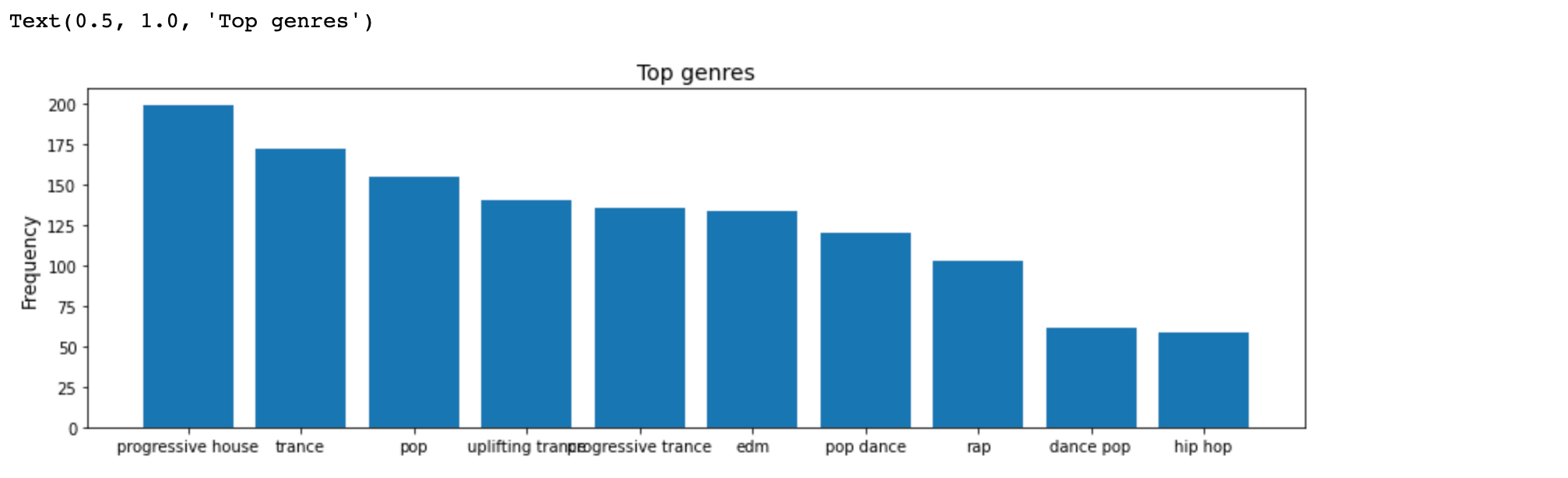
4.4. 각 Top 10 장르에서 팔로워가 가장 많은 아티스트
이번에는 위에서 나온 Top 10 장르 중, 각 장르에서 팔로워가 가장 많은 아티스트를 추출해보겠습니다.
top_10_genres = list(to_1D(track_df['artist_genres']).value_counts().index[:10])
top_artists_by_genre = []
for genre in top_10_genres:
for index, row in by_art_fol.iterrows():
if genre in row['artist_genres']:
top_artists_by_genre.append({'artist_name':row['artist_name'], 'artist_genre':genre})
break
pd.json_normalize(top_artists_by_genre)
4.5. 각 Top 10 장르에서 가장 인기있는 트랙
아티스트를 확인했다면 트랙도 확인해봐야겠죠.
by_track_pop = pd.DataFrame(track_df.sort_values(by=['track_popularity'], ascending=False)[['track_popularity','track_name', 'artist_name','artist_genres', 'track_id']])
by_track_pop.astype(str).drop_duplicates().head(10)
top_songs_by_genre = []
for genre in top_10_genres:
for index, row in by_track_pop.iterrows():
if genre in row['artist_genres']:
top_songs_by_genre.append({'track_name':row['track_name'], 'track_popularity':row['track_popularity'],'artist_name':row['artist_name'], 'artist_genre':genre})
break
pd.json_normalize(top_songs_by_genre)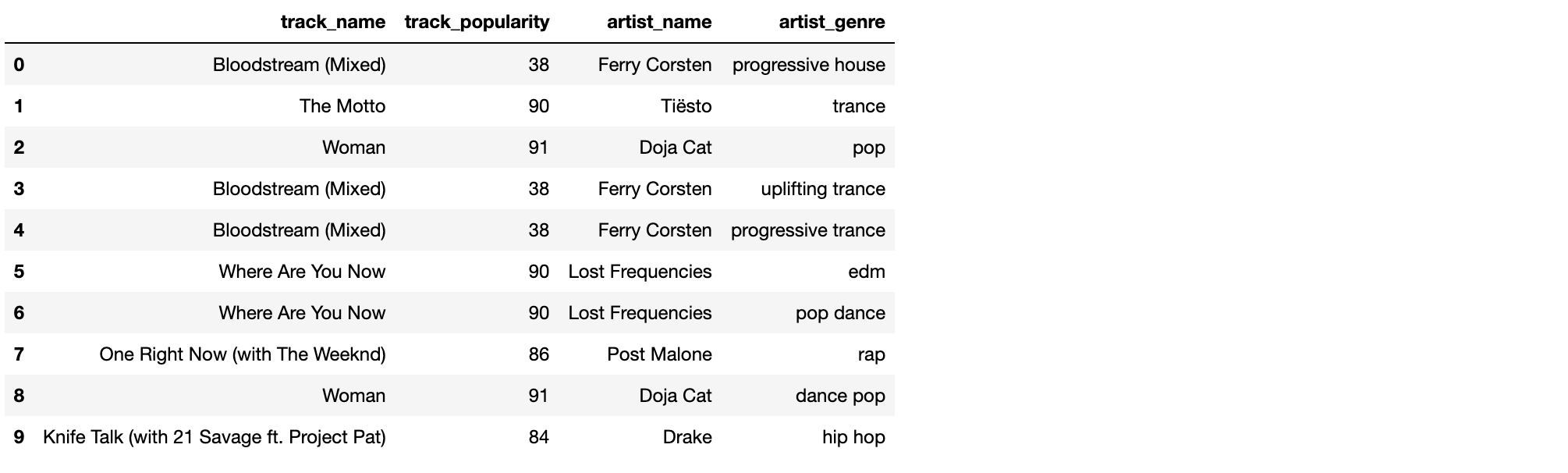
해당 장르에서 아티스트 팔로워도 가장 많으면서 가장 인기있는 트랙도 발매했던 사람은 힙합의 드레이크 뿐이네요. 많은 팔로워가 있으면서도 당해 가장 인기있는 트랙을 내기는 쉽지 않은가 봅니다.

5. 음악 분석
5.1. 특징 간 상관관계
이제는 좀 더 본격적으로 음악의 특성을 가지고 분석해보도록 하겠습니다. 우선 각각의 특징 간에는 어떤 상관관계가 있을까요? 히트맵으로 보도록 하겠습니다.
import seaborn as sn
sn.set(rc = {'figure.figsize':(12,10)})
sn.heatmap(tf_df.corr(), annot=True)
plt.show()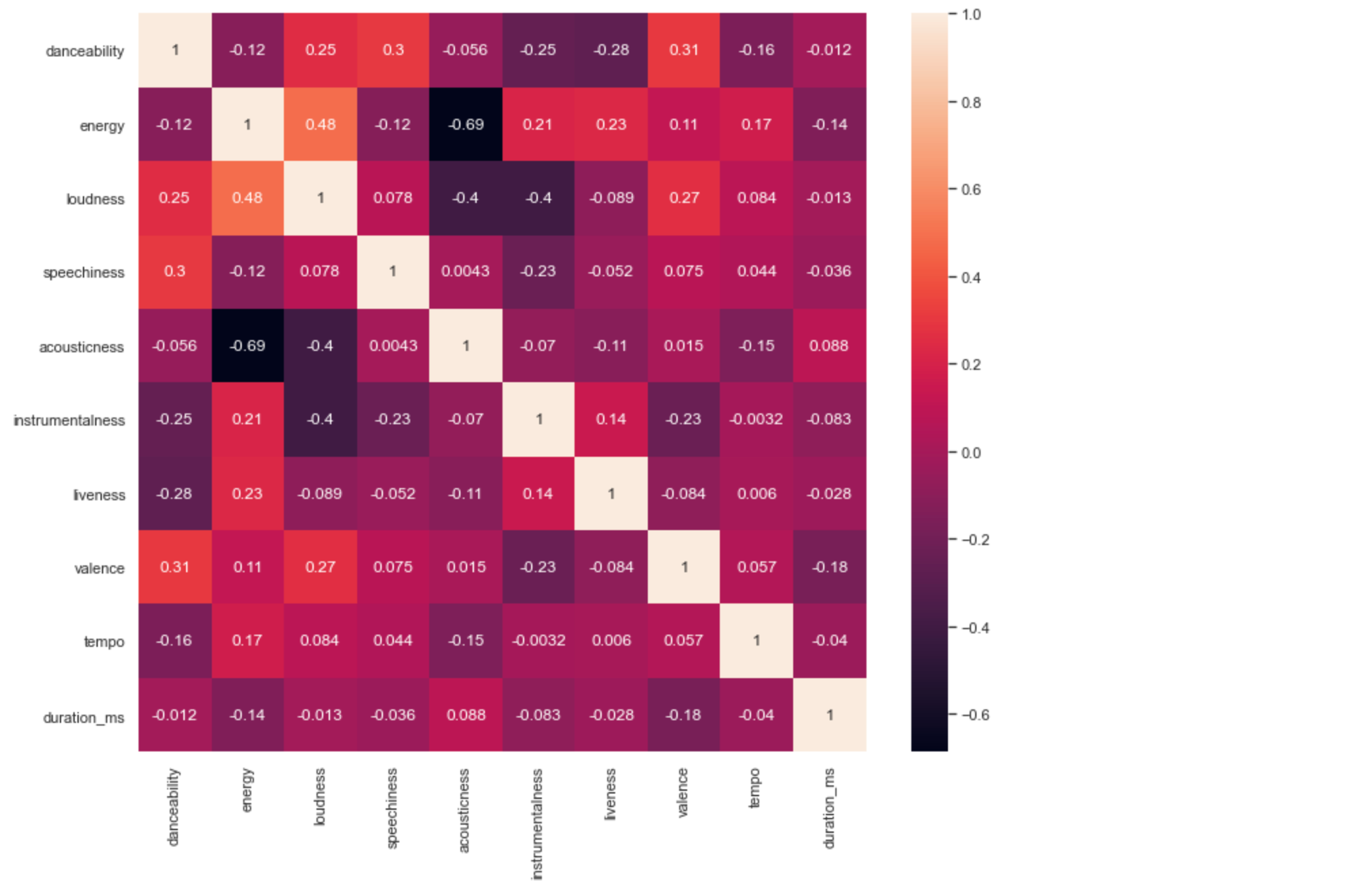
예상할 수 있듯이 loundness와 energy와 같이 상관관계가 높은 특징들이 있고, acousticness와 energy처럼 상관관계가 낮은 특징들도 있습니다. 이중 가장 높은 상관관계를 가진 loudness와 energy를 좀 더 살펴보겠습니다.
sn.set(rc = {'figure.figsize':(20,20)})
sn.jointplot(data=tf_df, x="loudness", y="energy", kind="kde")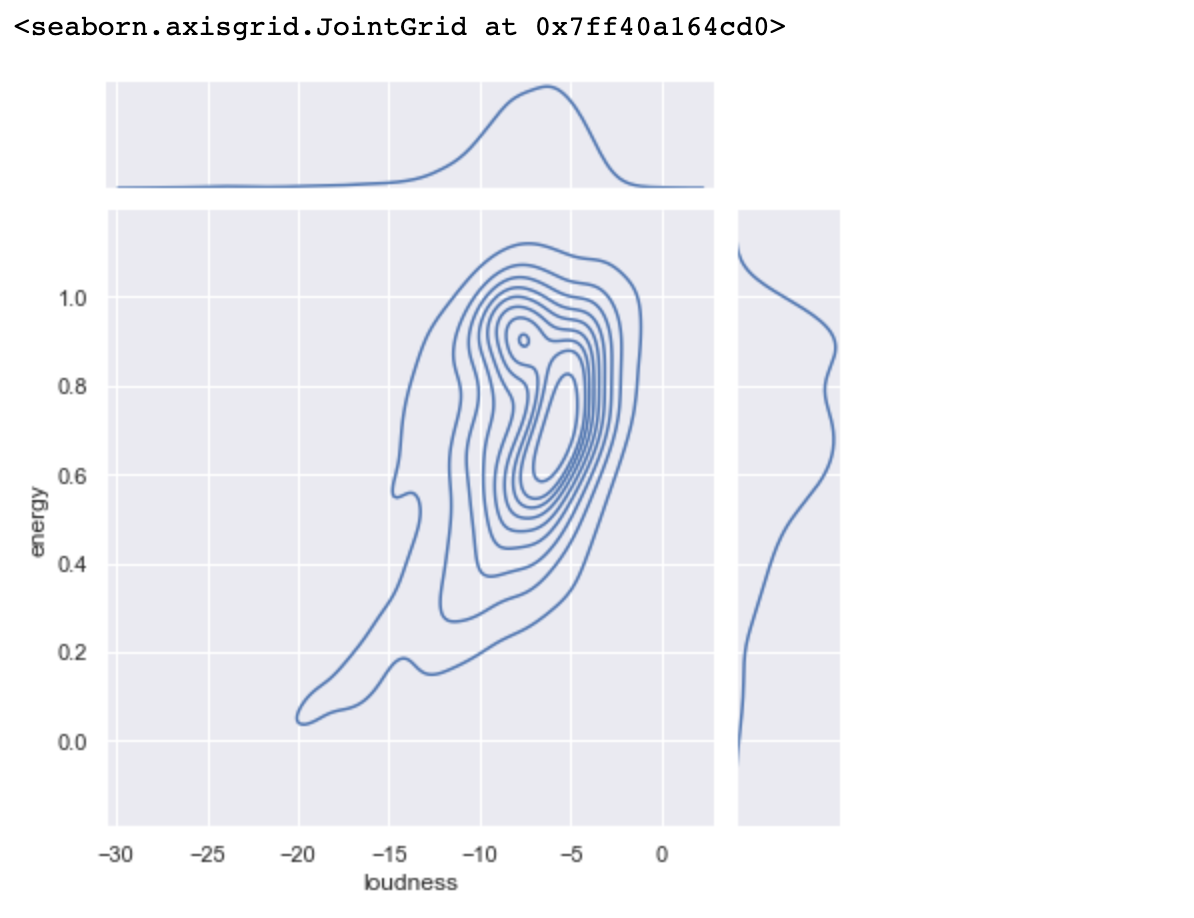
5.2. Top 100 트랙 vs. 전체 평균
이번에는 Top 100에 든 트랙은 과연 다른 음악들과 뭐가 달랐을지 알아보도록 하겠습니다.
'danceability', 'energy', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence'의 특징을 기준으로, Top 100 트랙의 평균과 전체 평균을 스타맵을 그려 비교해보겠습니다.
feat_cols = ['danceability', 'energy', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence']
top_100_feat = pd.DataFrame(columns=feat_cols)
for i, track in by_track_pop[:100].iterrows():
features = tf_df[tf_df['id'] == track['track_id']]
top_100_feat = top_100_feat.append(features, ignore_index=True)
top_100_feat = top_100_feat[feat_cols]
from sklearn import preprocessing
mean_vals = pd.DataFrame(columns=feat_cols)
mean_vals = mean_vals.append(top_100_feat.mean(), ignore_index=True)
mean_vals = mean_vals.append(tf_df[feat_cols].mean(), ignore_index=True)
print(mean_vals)
# 그래프 그리기
import plotly.graph_objects as go
import plotly.offline as pyo
fig = go.Figure(
data=[
go.Scatterpolar(r=mean_vals.iloc[0], theta=feat_cols, fill='toself', name='Top 100'),
go.Scatterpolar(r=mean_vals.iloc[1], theta=feat_cols, fill='toself', name='All'),
],
layout=go.Layout(
title=go.layout.Title(text='Feature comparison'),
polar={'radialaxis': {'visible': True}},
showlegend=True
)
)
#pyo.plot(fig)
fig.show()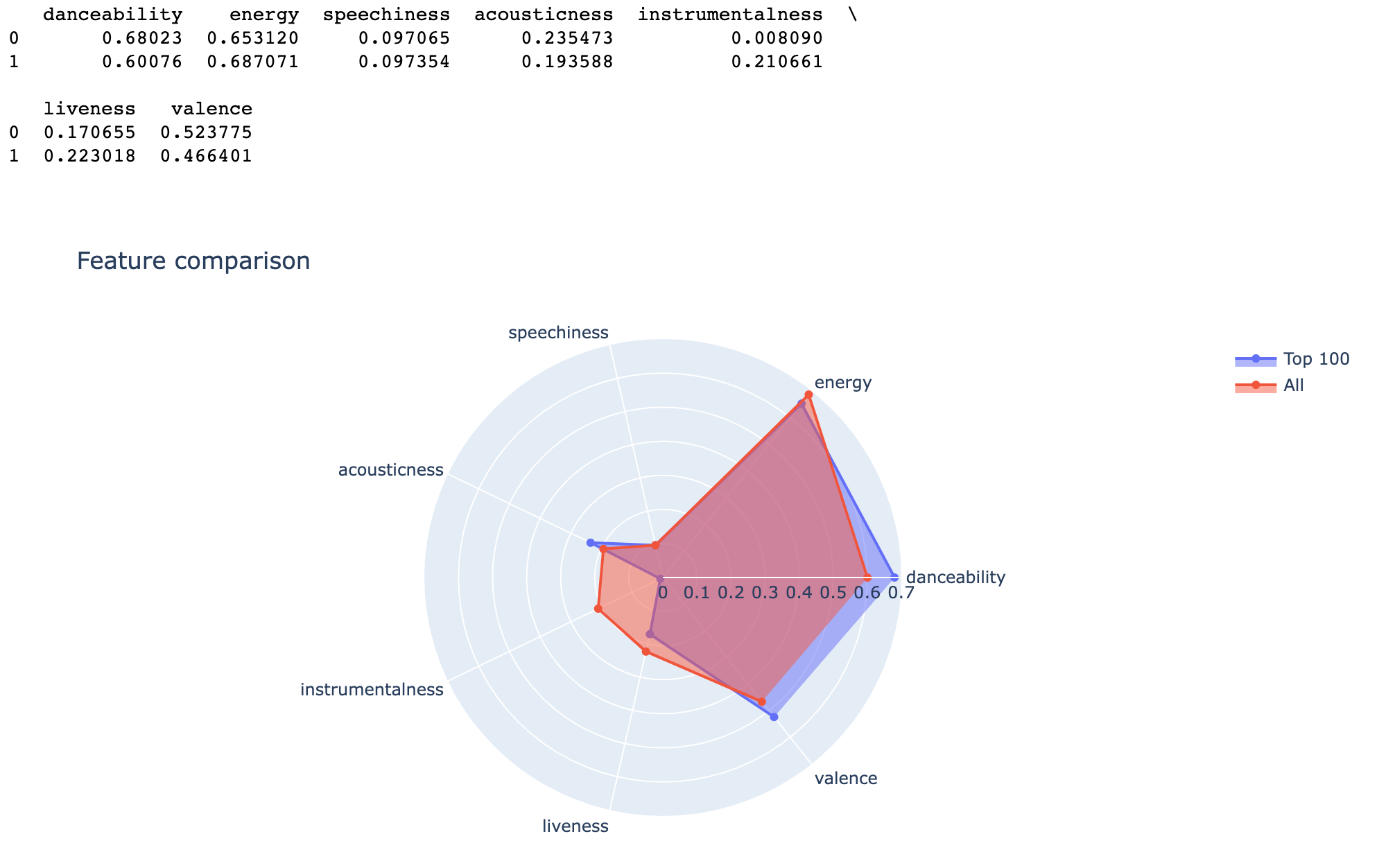
이런 깔끔한 결과가 얻어집니다. Top 100은 전체 평균에 비해 danceability와 valence, acousticness가 높지만 energy, liveness, 특히 instrumentalness는 낮은 것을 볼 수 있네요.
5.3. 추천 받기
마지막으로 스포티파이 api는 추천 목록도 제공합니다. recommendations 함수를 이용해 아티스트와 장르, 트랙, 음악 특징 등을 입력하면 그와 비슷한 음악을 추천받을 수 있습니다.
rec = sp.recommendations(seed_artists=["3PhoLpVuITZKcymswpck5b"], seed_genres=["pop"], seed_tracks=["1r9xUipOqoNwggBpENDsvJ"], limit=10)
for track in rec['tracks']:
print(track['artists'][0]['name'], track['name'])Twenty One Pilots Stressed Out
The Cars Just What I Needed
Maroon 5 What Lovers Do (feat. SZA)
Yusuf / Cat Stevens Wild World
Imagine Dragons Demons
BoyWithUke Two Moons
Lorde Perfect Places
Supertramp Give A Little Bit
Skillet Surviving The Game
Ed Sheeran Tenerife Sea
2년 전 내용이지만 큰 도움이 되었습니다.
질문이 있어서 남겨봅니다. 확인하실지 모르겠네요...
위에서 top100곡을 'danceability', 'energy', 'speechiness', 'acousticness', 'instrumentalness', 'liveness', 'valence'을 기준으로 하셨는데 100곡 순위가 부여되는 방식이 뭔지 궁금합니다.
감사합니다.