1. Introduction
- 대규모 언어 모델(LLM)을 기반으로 한 자율 에이전트의 연구 배경 및 필요성
- 기존 에이전트는 제한된 환경에서 작동하며, 인간과 유사한 의사결정을 내리기 어려움
- LLM은 광범위한 데이터와 매개변수를 활용하여 인간 수준의 지능을 보여줌
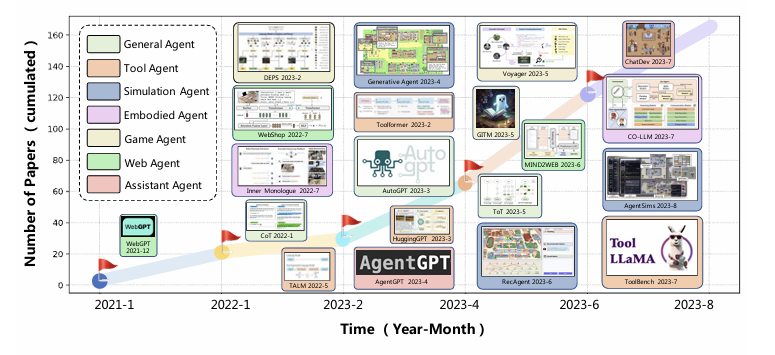
- 초기에는 도구 에이전트와 같이 비교적 단순한 역할을 수행하는 연구가 많았으나, 이후 시뮬레이션 에이전트, 멀티모달 에이전트 등 더 복잡하고 다양한 환경에서의 연구가 등장.
- 이는 LLM이 단순한 질의응답에서 벗어나 점점 더 인간과 유사한 행동을 시뮬레이션하고 학습하는 방향으로 발전하고 있음을 보여줌.
본 논문에서는 LLM based Autononmous Agent의 구조, 응용, 평가 전략을 포괄적으로 검토하고 주요 도전과제와 향후 연구 방향을 제시
2. LLM-based Autonomous Agent Construction
2.1 Agent Architecture Design
2.1.1 Profiling Module
- 에이전트의 역할을 정의하여 행동에 영향을 줌
- 역할(예: 코더, 교사)과 프로필(연령, 성격, 사회적 관계 등)을 명시
- 생성 방법:
- Handcrafting Method: 명시적으로 프로필 작성
- LLM-generation Method: 규칙 기반으로 프로필 생성
- Dataset Alignment Method: 실제 데이터로부터 프로필 생성
2.1.2 Memory Module
- 메모리 모듈은 에이전트가 환경에서 얻은 정보를 저장하고 이를 활용하여 향후 작업과 행동을 지원하는 중요한 구성 요소
- 인간의 기억 구조에서 영감을 받아 설계되었으며, 에이전트가 경험을 축적하고 스스로 진화하며 더 일관성 있고 효과적으로 행동할 수 있도록 지원
Memory Structures
- Unified Memory
- 인간의 단기 기억(short-term memory)에 해당
- 모든 기억 정보를 프롬프트에 직접 작성하여 사용 - 장점: 최근 정보에 집중하여 작업 수행 가능
- 단점: LLM의 제한된 문맥 윈도우 때문에 메모리 크기가 제한적
- 인간의 단기 기억(short-term memory)에 해당
- Hybrid Memory
- 인간의 단기 및 장기 기억(short-term & long-term memory)을 모두 모델링
- 단기 기억: 최근 인식을 일시적으로 저장
- 장기 기억: 시간이 지나도 중요한 정보를 저장
- 예:
Generative Agent: 상황 정보를 단기 기억으로 저장하고, 과거 행동과 사고는 장기 기억으로 저장
AgentSims: 벡터 데이터베이스를 활용하여 장기 기억 저장 및 검색
Reflexion: 최근 피드백을 단기 기억에 저장하고 요약된 정보를 장기 기억에 저장 - 장점: 장기적 추론과 경험 축적 가능
- 단점: 설계 및 구현의 복잡성 증가
- 인간의 단기 및 장기 기억(short-term & long-term memory)을 모두 모델링
Memory Formats
-
Natural Language : 기억 정보를 자연어로 저장하여 유연성과 풍부한 의미 제공
-
Embeddings : 기억 정보를 임베딩 벡터로 변환하여 검색과 읽기 효율성 향상
-
Databases : SQL 쿼리를 통해 정보를 저장하고 조작
-
Structured Lists : 기억을 리스트나 계층적 트리 구조로 저장하여 효율적 관리.
Memory Operations
-
Memory Reading : 과거 행동에서 유용한 정보를 추출하여 현재 행동을 지원
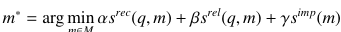
q: query, M : memory의 집합 -
Memory Writing : 환경에서 얻은 정보를 저장
- Memory Duplicated: 비슷한 정보를 통합
- Memory Overflow: 저장 용량이 초과되면 오래된 정보를 제거
-
Memory Reflection : 과거 기억을 요약하고 고차원적인 insight 생성
2.1.3 Planning Module
-
복잡한 작업을 더 간단한 하위 작업으로 나누어 해결하는 능력을 제공
-
인간의 사고 방식을 모델링하여 에이전트가 더 합리적이고 강력하며 신뢰성 있게 행동하도록 함
- Planning without Feedback: CoT, ToT
- Single-path Reasoning : 작업을 여러 단계로 나누어 직선적인 방식으로 진행 (CoT)
- Multi-path Reasoning : 작업을 트리 구조로 확장하여 여러 경로를 탐색하며 최적의 계획을 선택하게 함 (ToT)
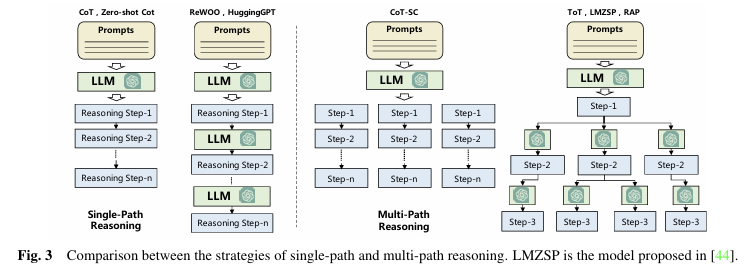
- Planning with Feedback:
- Environmental Feedback: 가상 또는 물리적 환경으로부터 피드백을 받아 계획을 수정 (ReAct, Voyager, SayPlan, DEPS)
- Human Feedback: 인간 사용자가 제공하는 피드백을 반영하여 계획 수정 (Inner Monologue)
- Model Feedback: 에이전트 자체 또는 다른 모델이 제공하는 피드백을 활용 (Self-Refine, Reflexion, ChatCoT)
2.1.4 Action Module
- 에이전트의 의사결정을 실제 행동으로 변환
- 에이전트 설계의 가장 하위 단계에 위치하며, 환경과 직접 상호작용하는 구성 요소
- 위의 3가지 모듈의 영향을 받아 행동을 결정
- Action Goal: 에이전트의 행동이 이루고자 하는 의도
- Task Completion, Communication, Environment Exploration
- Action Production: 에이전트가 행동을 결정하는 방식
- Action via Memory Recollection, Action via Plan Following
- Action Impact: 에이전트의 행동이 환경과 내부 상태에 미치는 결과
2.2 Agent Capability Acquisition
- 에이전트의 구조(하드웨어)가 잘 설계되었다고 하더라도, 특정 작업 수행에 필요한 능력(소프트웨어)이 없다면 효율적인 작업이 어렵
- 에이전트가 작업 관련 기술, 경험, 학습된 지식을 얻는 과정
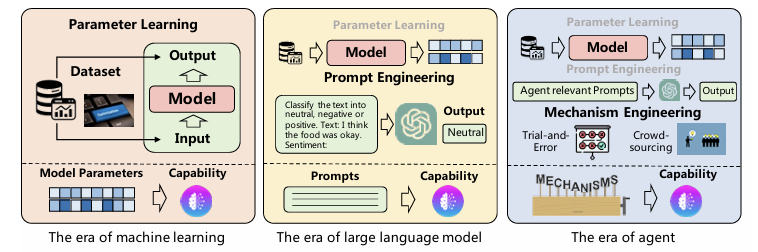
- model fine-tuning:
- Human Annotated Datasets(인간 주석 데이터): 예) EduChat은 다양한 교육 시나리오 데이터로 학습.
- LLM-Generated Datasets: 예) ToolBench는 API를 기반으로 LLM이 생성한 데이터로 학습.
- Real-world Datasets: 예) MIND2WEB은 실제 웹 데이터로 학습하여 성능 개선.
(2,3은 파인튜닝 없이)
- prompt engineering: 자연어로 원하는 작업 능력을 프롬프트에 기술하여 모델 성능을 향상(예: CoT, ToT).
- mechanism engineering: 설계된 규칙과 모듈을 활용하여 에이전트의 능력을 강화
- Trial-and-Error: 실패 후 피드백을 반영하여 계획 수정
- Experience Accumulation: 이전 작업 데이터를 메모리에 저장해 재사용
- Self-driven Evolution: 에이전트가 스스로 목표 설정과 학습을 통해 능력 향상
3. Applications of LLM-based Autonomous Agents
3.1 Social Science
- 인간 행동 및 사회적 상호작용의 시뮬레이션
- RecAgent: 인간의 영화 선호도를 시뮬레이션.
- Social Simulacra: 여러 에이전트를 활용해 사회적 행동 모델링.
3.2 Natural Science
- 과학적 연구 지원 및 도구 역할.
- ChemCrow: 유기 합성, 약물 개발, 소재 설계.
- Voyager: 환경 탐험과 코드 생성을 통해 새로운 기술 실행.
3.3 Engineering
- 소프트웨어 개발 및 시스템 설계 지원.
- ChatDev: 협업형 소프트웨어 개발 도구
- ToolFormer: API 활용으로 복잡한 작업 해결
- AutoGPT: 자동으로 목표를 설정하고 작업을 수행
3.4 기타
- 게임 및 시뮬레이션: 에이전트가 가상 환경에서 작업 수행
- 예: DEPS는 Minecraft 환경에서 작업 계획 및 실행
- 멀티모달 시스템: 텍스트, 이미지, 음성 등 다양한 데이터를 통합 처리
- 예: MM-REACT는 비디오 요약, 이미지 생성, 오디오 처리
4. Evaluation of LLM-based Autonomous Agents
LLM-based autonomous agents를 평가하는 데는 주관적 평가와 객관적 평가를 포함한 다양한 방법이 사용한다.
4.1 Subjective Evaluation
- 사용자가 에이전트의 행동이나 성능에 대해 정성적 피드백을 제공.
- 주요 평가 항목:
- 참여도(Engagement): 에이전트가 얼마나 상호작용적인가?
- 명확성(Clarity): 출력이 쉽게 이해되는가?
- 정렬성(Alignment): 에이전트의 행동이 인간의 기대나 윤리적 기준에 부합하는가?
- 주요 평가 항목:
4.2 Objective Evaluation
- 정량적인 성능 지표를 기반으로 평가.
- 주요 지표: 정확도(accuracy), 효율성(efficiency), 작업 성공률(task success rate).
- 예: 특정 작업에서 에이전트가 목표를 얼마나 잘 달성했는지 측정.
- 피드백 통합(Feedback Integration)
- 환경, 인간, 모델로부터의 피드백을 결합하여 에이전트 성능을 평가.
- 예: 환경 기반의 성공 신호와 인간의 피드백을 함께 사용하여 에이전트의 계획을 개선.
- Feedback Sources
-
환경 피드백(Environmental Feedback)
- 가상 또는 물리적 환경으로부터의 피드백.
- 예: 게임의 작업 완료 신호, 실행 오류 메시지.
-
인간 피드백(Human Feedback)
- 사용자나 평가자로부터 직접 제공되는 피드백.
- 예: 사용자가 에이전트의 추천이나 응답 품질에 대해 점수를 매김.
-
모델 피드백(Model Feedback)
- 에이전트 자체 또는 보조 모델이 생성한 피드백.
- 예: 모델이 자신의 출력이나 행동을 평가하고 수정 방안을 제시.
- Challenge
- 인간 피드백의 주관성
- 인간의 평가가 주관적이며, 평가자마다 차이가 있음.
- 평가 확장성(Scalability)
- 다양한 작업과 도메인에 대해 체계적으로 평가하기 어려움.
- 동적 환경(Dynamic Environments)
- 실시간 변화하는 환경에서 일관된 평가를 수행하는 데 어려움.
- 적응성 테스트(Adaptability Testing)
- 새로운 작업이나 예상치 못한 상황에 대한 에이전트의 적응 능력을 평가하기 복잡함.
5. Challenges and Future Directions
5.1 주요 도전 과제
LLM의 한계:
문맥 윈도우 제한(Context Window Limitations): LLM이 한 번에 처리할 수 있는 정보량의 한계.
- 데이터 편향(Data Bias): 훈련 데이터의 불균형으로 인해 특정 결과가 왜곡될 가능성.
- 평가 문제:
에이전트가 복잡한 작업에서 얼마나 적응하고 학습했는지를 평가하는 표준화된 방식 부족. - 환경의 복잡성:
동적이고 예측 불가능한 환경에서 에이전트가 안정적으로 작동하도록 설계하는 것이 어려움. - 자원 효율성:
LLM 기반 에이전트는 계산 비용이 높고 리소스 소모가 큼. 이를 최적화해야 함.
5.2 미래 연구 방향
- 인간-에이전트 상호작용 강화:
에이전트가 인간의 의도를 더 잘 이해하고 협력할 수 있도록 설계.
예: 사용자 맞춤형 인터페이스와 직관적인 명령어.
-Multimodal Learning :
텍스트 외에 이미지, 음성 등 다양한 데이터 소스를 처리할 수 있는 에이전트.
예: MM-REACT는 비디오, 이미지, 음성을 활용. - 장기적 메모리와 학습:
에이전트가 지속적으로 학습하고, 장기적인 기억을 활용해 더 나은 결정을 내릴 수 있도록 설계.
예: Generative Agent는 장기 메모리를 통해 과거 행동에서 통찰을 도출. - 적응적 에이전트 설계:
환경 변화에 따라 에이전트가 계획을 수정하고 새로운 상황에 적응할 수 있도록 강화. - 에너지 효율성 향상:
에이전트의 계산 비용과 에너지 소모를 줄이기 위한 경량화된 모델 개발.
6. Conclusion
- LLM 기반 자율 에이전트는 인간 수준의 지능을 모방하고 다양한 환경에서 효율적으로 작업을 수행할 잠재력을 보여줌
- 에이전트는 프로파일링, 메모리, 계획, 액션 모듈을 통해 복잡한 작업을 수행
- 다양한 도메인에서 성공적으로 응용되고 있지만, 성능 평가 및 지속적 발전에는 여전히 도전 과제가 존재

컴공댕이의 기록