Research paper review
1.[DL] Deep Sparse Rectifier Neural Networks 논문 리뷰
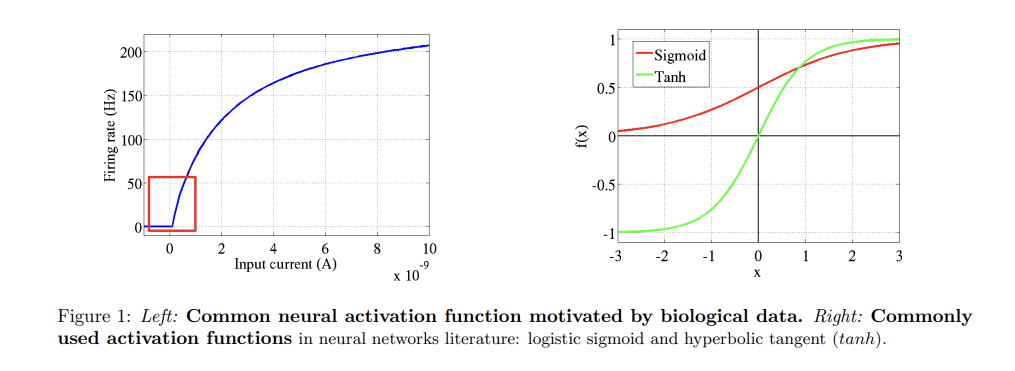
Abstract sigmoid, hyperbolic tangent 함수보다 더 좋은 rectifying neuron에 대해 소개한다. 두 활성함수에 비해, > multi-layer neural network에서도 학습이 잘 됨 생물학적 뉴런을 더 잘 표현한 모델 sp
2.[논문 리뷰] Enriching Word Vectors with Subword Information
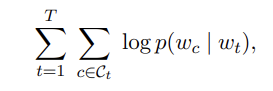
skipgram model(기존) + 각 단어가 n-gram의 합으로 표현(추가)장점 1 ) 빠르다장점 2 ) training data 에 없던 단어도 계산이 가능연속적인 단어들을 학습하는 연구의 역사: co-occurence statistics 를 기반으로 시작 (단
3.[논문 리뷰] Attention Is All You Need

그동안의 sequence transduction modele들은 복잡한 RNN/CNN의 encoder-decder 모델로 구성되어왔다. 이 논문은 오직 attention mechanism만을 사용한 Transformer 라는 새로운 신경망을 제안한다.두 개의 기계 번역
4.[논문 리뷰] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
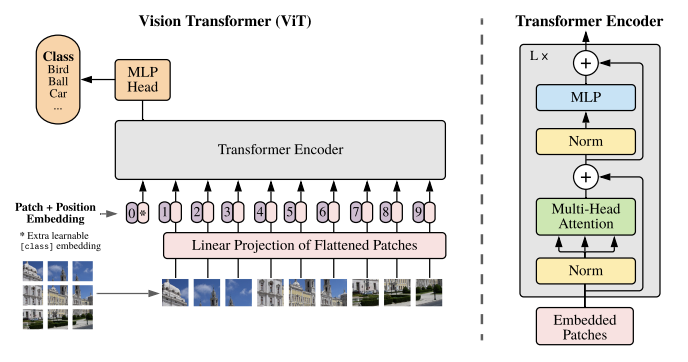
cv에서 transformer의 사용이 제한적image classification에서 transformer만 사용했을 때 높은 성능을 보였음CNN없이 Transformer만 사용한 ViT(Vision Transformer)는 최신 CNN과 비교했을 때 우수한 결과를 달
5.[논문 리뷰] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
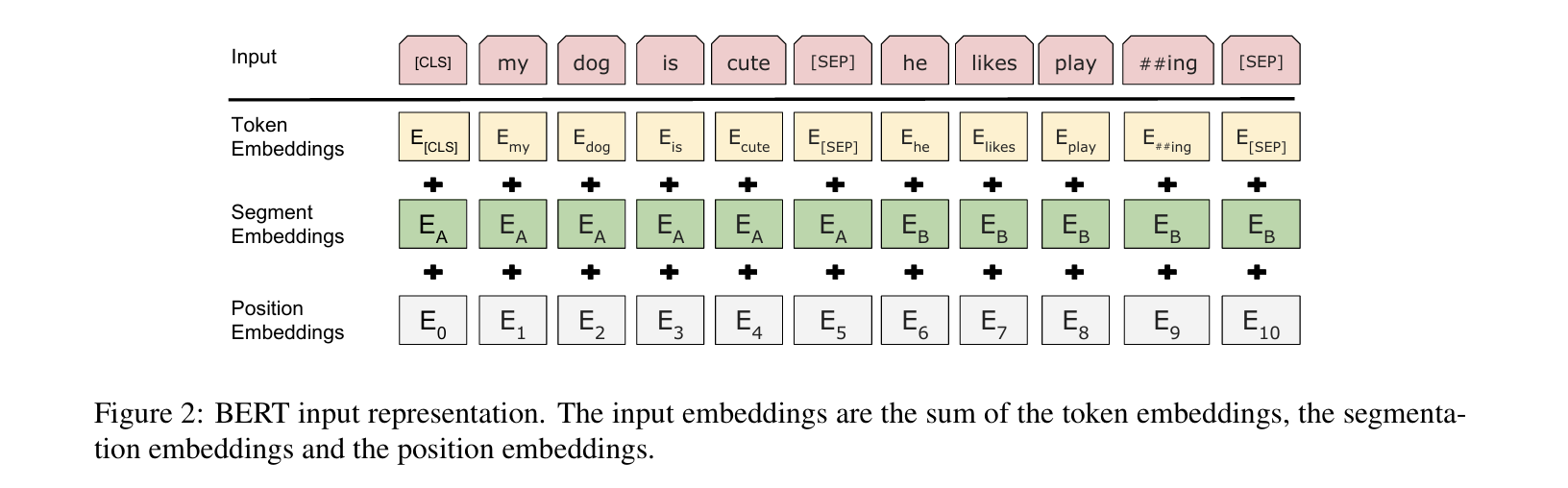
Abstract BERT(Bidirectional Encoder Representations from Transformers) >unlabeled data로 모든 layer에서 양방향 학습을 진행 -> 모델이 각 토큰에 대해 전후 맥락을 동시에 고려하도록 함 Int
6.[논문 리뷰] U-Net : Convolutional Networks for Biomedical Image Segmentation

Abstract CNN 같은 모델은 여러 층과 수백만 개의 파라미터를 가진다. 모델이 복잡할수록, 학습을 잘 하기 위해서는 많은 라벨링 데이터가 필요하다. 이 논문에서는 data augmentation을 활용하는 새로운 네트워크 아키텍처와 학습 전략을 제시하고 있다.
7.[논문 리뷰] A Survey on Large Language Model based Autonomous Agents
1. Introduction 대규모 언어 모델(LLM)을 기반으로 한 자율 에이전트의 연구 배경 및 필요성 기존 에이전트는 제한된 환경에서 작동하며, 인간과 유사한 의사결정을 내리기 어려움 LLM은 광범위한 데이터와 매개변수를 활용하여 인간 수준의 지능을 보여줌
8.[논문 리뷰] DeepCache: Accelerating Diffusion Models for Free
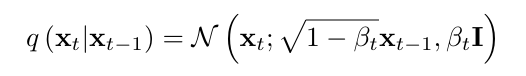
denoising 과정에서 반복적으로 계산되는 결과들을 caching 하여 저장하고 재사용하는 것 => 연산 줄임최근 생성형 모델에서 diffusion model이 큰 주목을 받음텍스트, 이미지, 오디오, 비디오등 다양한 분야에서 활용됨기존 연구들의 문제점느린 추론 속