[논문 리뷰] U-Net : Convolutional Networks for Biomedical Image Segmentation
Research paper review
Abstract
CNN 같은 모델은 여러 층과 수백만 개의 파라미터를 가진다. 모델이 복잡할수록, 학습을 잘 하기 위해서는 많은 라벨링 데이터가 필요하다. 이 논문에서는 data augmentation을 활용하는 새로운 네트워크 아키텍처와 학습 전략을 제시하고 있다.
Architecture = contracting path + expanding path
- contracting path : context 학습
- expanding path : localization 학습
이 network는 적은 이미지 수로 학습이 가능하며, 이전의 sliding-window convolutional network보다 더 나은 성능을 보임 + 빠르다
1. Introduction
이전의 연구들
Alexnet
- 기존의 신경망 네트워크는 많은 visual recognition task에서 성능 향상을 보였으나, 그러나 training set의 크기와 network의 크기에 제한을 받았다.
=> Alexnet : 더 깊은, 그리고 큰 네트워크의 학습이 가능함을 보였다.
sliding-window
- 많은 Convolutional networks는 주로 분류 문제에 사용되는데, 하나의 클래스 label을 출력한다. 그러나 특히 생체의학 영상 처리에서는 localization, 즉, 지역적 정보를 가지고 있는 것이 중요하다. 모든 픽셀마다 class label값이 할당되어야 하는 것이다. 생물 의학에서는 수천 개의 훈련 이미지를 확보하는 것이 어렵다.
=> sliding-window : 이미지에서 작은 패치(patch)를 슬라이딩 윈도우처럼 이동시켜, 각 픽셀을 예측할 때 주변 지역을 입력으로 사용
- localize (위치 정보 고려)
- Dataset 확장 (하나의 이미지에서 여러 패치를 잘라내어 그 패치들을 각각 훈련 샘플로 사용할 수 있기 때문)
그러나 단점이 존재:
- 느림 : 각 패치에 대해 각각의 네트워크를 돌려야 했고, 패치마다 중복되는 부분이 많았음.
- context와 localization의 trade-off : 큰 패치는 지역정보를 정확히 반영하지 못하였고, 작은 패치는 작은 context내의 정보만 파악할 수 있기 때문
=> 최근 여러층의 정보를 한꺼번에 고려하는 classifier가 제안됨. 이는 좋은 지역 정보와 context를 합칠수 있었음.
이 논문에서는
- fully-convolutional network 구조를 기반
- pooling -> upsampling
: 전통적인 CNN에서는 pooling을 사용하여 이미지 크기를 축소시키며 특징을 추출- 해상도가 입력 이미지보다 낮음(pooling 때문),
: FCN에서는 upsampling을 사용하여 이미지 크기를 복원하고 해상도를 높임.
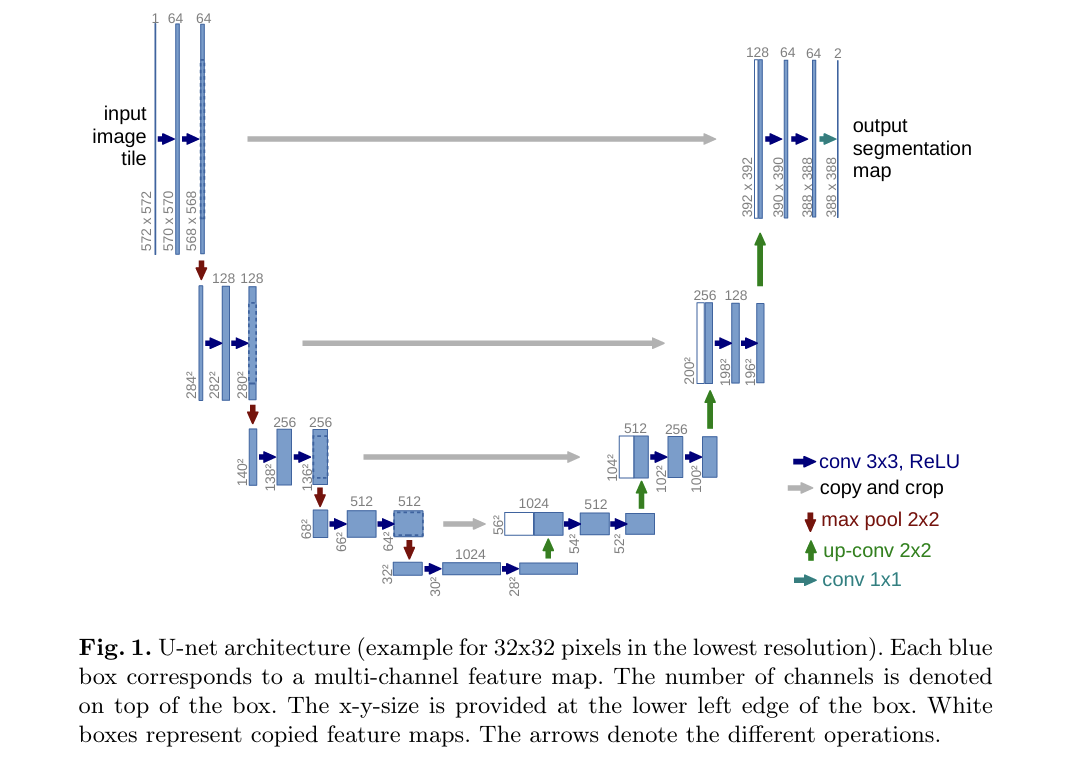
- contracting path에서 추출한 고해상도 특징을 upsampling된 출력과 결합하여 정확한 localization 수행
- 그 후 연속적인 컨볼루션 레이어가 이 정보를 조합하여 더 정밀한 출력을 생성
architecture의 주요 특징
-
upsampling시 많은 feature channel을 사용
: 이 feature channel들이 업샘플링된 레이어에 context 정보를 전달하게 됨.
따라서 expansive path와 contractive path가 u-shaped 구조를 이룸. -
fully connected layer 사용 X
: 필요한 부분들만 사용 -
overlap-tile
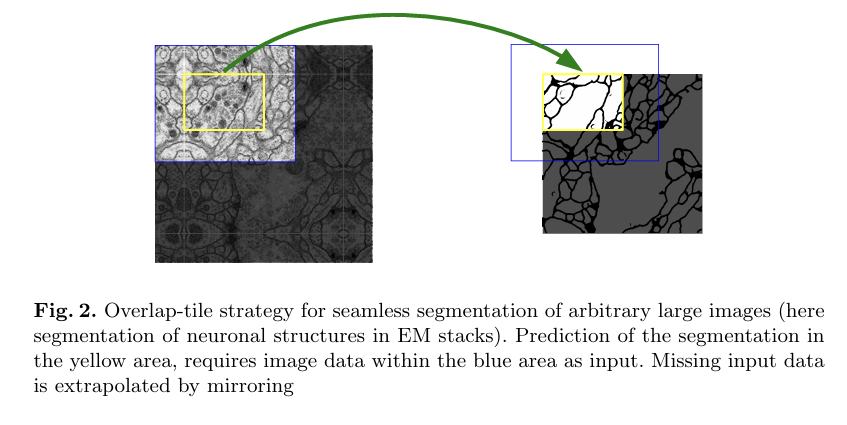
: 해상도는 GPU memory 떄문에 제한적임. 특히 큰 이미지같은 경우 어떻게 감당하냐?
=> 이미지를 작게 나누어 segmentation 처리하고자 하는 방식이 overlap-tile strategy
: segmentation에서 missing context는 대칭적으로 생성하여 학습 데이터로 이용. 위의 그림에서 노란색 영역의 예측을 위해서는 파란색 영역을 input으로 필요로 함. 따라서 파란 부분 중 비어있는 부분은 mirroring을 해 사용. -
excessive data augmentation
: training dataset의 수가 적기 때문
: 훈련셋에 elastic deformation을 적용하여 인위적으로 개수를 늘림
: 이런 방식으로 데이터를 증강하면, 네트워크가 변형에 대한 불변성(invariance)을 학습할 수 있게 됨. 즉, 네트워크는 실제 데이터에 변형된 이미지를 보지 않아도 다양한 변형에 대해 잘 일반화 함
*탄성 변형은 이미지를 구불구불하게 늘리거나 찌푸리는 방식으로 변형시켜, 다양한 변형된 버전을 생성 -
weighted loss
: 세포 세그멘테이션에서는 종종 같은 클래스에 속하는 객체들이 서로 접촉하는 문제가 발생합니다. 예를 들어, 두 개의 세포가 서로 겹치거나 붙어 있을 때, 이를 정확히 분리하는 것이 큰 도전 과제
=> 세포들이 접촉하는 부분을 분리하는 배경 레이블(background labels)에 큰 가중치를 부여하여, 네트워크가 이 부분을 더 중요하게 학습하도록 유도 (세포들을 정확히 분리하는데 초점을 둘 수 있음)
결과
- segmentation of neuronal structure in EM stacks : sota 뛰어넘음
- ISBI cell tracking challenge 2015 : 두 개의 2D 투과광 데이터셋에서 큰 차이로 우승
2. Network Architecture
- stochastic gradient descent
- output image가 input image 보다 작음 (padding이 없어서)
- 큰 input tile 사용
- batch size : 1
- momentum : 0.99
soft-max
- 각 클래스에 대한 확률을 계산
- 픽셀 위치 𝑥에 대해, 각 feature channel 𝑘에 대한 활성화 값 𝑎𝑘(𝑥)를 사용하여 각 채널의 확률 𝑝𝑘(𝑥)를 구함.
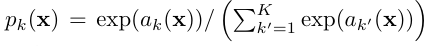
-𝑝_𝑘(𝑥)는 approximated maximum-function (가장 큰 활성화 값을 선택하는 함수), 이 값이 1에 가까울수록 유사, 0에 가까울수록 다름.
cross-entropy
- 예측된 확률 분포와 실제 값(정답 분포) 간의 차이를 측정
- l : 실제 각 픽셀의 라벨값
- w : weight map - 몇몇의 픽셀에 중요성을 부여하기 위해
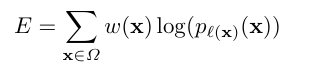
weight map
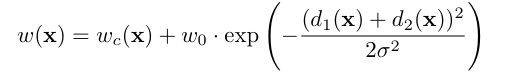
-
실제 segmentation 데이터의 가중치 맵을 먼저 계산함
-
훈련 데이터셋에서 클래스별로 픽셀의 빈도가 다르기 때문에 이를 보정. 예를 들어, 한 클래스는 다른 클래스보다 더 자주 등장할 수 있습니다. 이 경우, 덜 자주 등장하는 클래스의 픽셀에 더 큰 가중치를 부여하여 네트워크가 이러한 클래스를 더 잘 학습할 수 있도록 도움.
-
w_c : 클래스 빈도의 밸런스를 위한 가중치맵
-
d_1 : 가장 가까운 cell의 경계까지의 거리
-
d_2 : 두번째로 가까운 cell의 경계까지의 거리
=> 실험적 결과로 해당 논문에서는 w_0 =10 δ≈5 f로 설정 -
초기화 값 : 이상적으로, 초기 가중치는 네트워크의 각 feature map이 단위 분산(unit variance: 분산이 1)을 갖도록 조정되어야 합니다. 즉, 각 뉴런의 출력 값들이 적절히 분산되도록 해야 학습이 안정적으로 이루어짐.
=> 네트워크의 가중치는 가우시안 분포에서 표준편차가 2/√𝑁인 값으로 초기화
𝑁 : 각 뉴런으로 들어오는 입력 노드의 수
3.1 Data Augmentation
적은 학습 데이터를 가지고, 불변적인 특징을 학습하는데 유용함.
random elastic deformation을 진행함
- smooth deformation : 무작위 이동 벡터(Random displacement vectors)를 3x3 크기의 격자에서 샘플링. 이 벡터는 가우시안 분포에서 샘플링되며, 표준편차는 10 pixel.(픽셀을 이동시키는 정도가 평균적으로 10픽셀 내외로 이루어진다) 이 분포에서 선택된 값에 따라 이미지를 변형
*displacement vectors : 이미지를 변형할 때, 각 픽셀에 대해 얼마나 이동할지를 결정하는 벡터. 이동된 위치에 원래 픽셀의 값을 복사하고, 그 자리는 새로운 값으로 덮어쓰여지거나 빈 공간으로 처리됨.
-Bicubic Interpolation (양방향 보간법) :
각 픽셀의 이동(displacement)을 계산한 후, 빈공간에 4x4 영역을 참고하여 해당 위치의 값을 계산. 자연스럽게 변형이 이루어지도록 함.
-Drop-out layers: 네트워크의 일반화 능력을 높이기 위해 일부 뉴런을 랜덤으로 비활성화하여 간접적인 데이터 증강 효과를 제공
4. Experiments
U-Net 모델을 3가지 다른 segmentation task에 적용하여 실험
- 전자 현미경에서 신경 구조 분할

- EM 세분화 챌린지의 데이터셋
- U-net의 성능 : 7가지 회전된 입력 데이터 버전에 대해 학습
후처리 없이 warping error 0.0003529, Rand error 0.0382를 달성 - sliding-window convolutional network보다 나은 성능을 보임
- 빛 현미경 이미지를 사용한 Cell segmentation
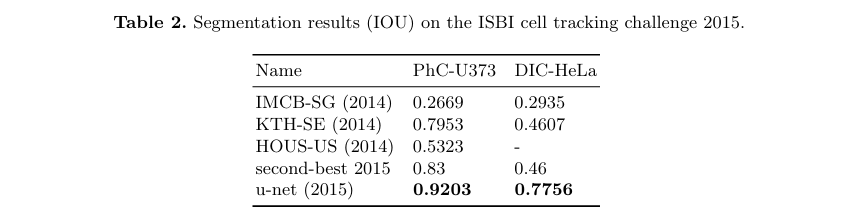
-
Dataset 1 : PhC-U373
PhC-U373 데이터셋에서 U-Net은 92%의 IOU, 두 번째로 좋은 알고리즘(83%)보다 9% 더 높은 성능을 보임 -
Dataset 2 : DIC-HeLa
DIC-HeLa 데이터셋에서는 U-Net이 77.5%의 IOU, 두 번째로 좋은 알고리즘(46%)을 크게 앞섬
*IOU는 예측된 분할과 실제 정답 간의 겹치는 부분과 차지하는 비율을 측정하는 지표, 분할 성능을 평가
5. Conclusion
U-Net 아키텍처는 매우 다양한 생물의학적 분할(segmentation) 작업에서 뛰어난 성능을 보여줌. Elastic deformations을 활용한 data augmentation 덕분에, 아주 적은 수의 주석이 달린 이미지로도 좋은 성능을 보여주었다
