Chapter3 단일 class Object detection 모델 학습
풍선 데이터 학습하기 - Object Detection
- 데이터 가져오기
!wget -c https://github.com/matterport/Mask_RCNN/releases/download/v2.1/balloon_dataset.zip- 데이터 압축 해제하기
!unzip balloon_dataset.zip -d ./balloondatasets/
- 이미지 장 수 확인하기
import glob
print(f'train : {len(glob.glob("./balloondatasets/balloon/train/*.jpg"))}')
print(f'val : {len(glob.glob("./balloondatasets/balloon/val/*.jpg"))}')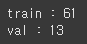
- 예제 데이터 확인하기
import mmcv
import matplotlib.pyplot as plt
img = mmcv.imread('./balloondatasets/balloon/train/10464445726_6f1e3bbe6a_k.jpg')
plt.figure(figsize=(15,10))
plt.imshow(mmcv.bgr2rgb(img))
plt.show()
어노테이션
-
사전적 의미로 주석
-
데이터를 설명해주는 데이터
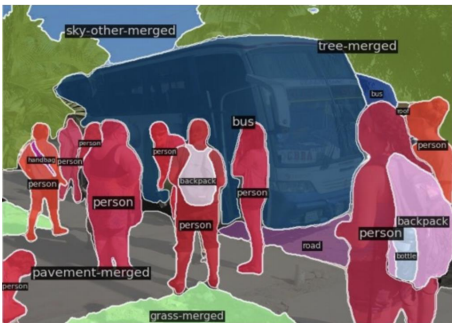
-
사람이 사진을 보고 판단하는 것과 같음
-
학습용 데이터셋은 항상 정답이 포함되어야 함 (무엇이 정답이고 무엇이 오답인지 알려주어야 함)
-
풍선 데이터의 어노테이션 파일
COCO 데이터 형식
-
COCO 포맷의 데이터 셋에만 mAP를 제공
-> mAP: 객체 탐지 모델의 성능 평가 지표 중 하나 -
COCO 데이터 포맷

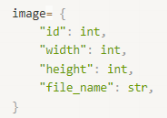
-> images: 모든 이미지에 대한 정보
--> id: 각 이미지의 고유번호
--> width: 너비
--> height: 높이
--> file_name: 이미지의 파일이름
-> annotatio: ns: 각각의 객체에 대한 정보
--> id: 각 객체의 고유번호
--> image_id: 이미지의 고유번호
--> category_id: 카테고리의 고유번호
--> segmentation: segmentation의 좌표
--> area: 넓이
--> bbox: 바운딩박스 좌표
--> iscrowd: segmentation에서 RLE가 사용되면1, ploygon이라면 0 (1인 경우는 거의 없음)

-> categories: 카테고리에 대한 정보
--> id: 각 카테고리의 고유번호
--> name: 카테고리의 이름
--> supercategory: 상위 카테고리 이름

COCO 데이터셋 형식으로 변환
- 어노테이션 파일
import mmengine
annotation = mmengine.load('./balloondatasets/balloon/train/via_region_data.json')
anno_example = annotation['34020010494_e5cb88e1c4_k.jpg1115004']
anno_example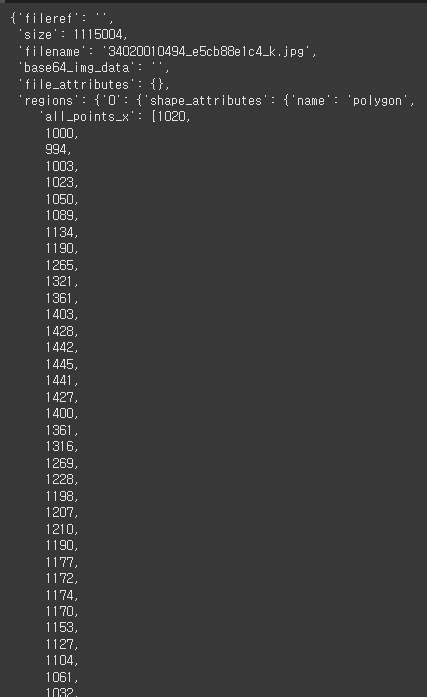
- COCO 데이터로 포맷 변경
import os.path as osp
def convert_balloon_to_coco(ann_file, out_file, image_prefix) :
data_infos = mmengine.load(ann_file)
annotations = []
images = []
obj_count = 0
for idx, v in enumerate(mmengine.track_iter_progress(list(data_infos.values()))) :
filename = v['filename']
img_path = osp.join(image_prefix, filename)
height, width = mmcv.imread(img_path).shape[:2]
images.append(dict(
id = idx,
file_name = filename,
height = height,
width = width
))
bboxes = []
labels = []
masks = []
for _, obj in v['regions'].items():
assert not obj['region_attributes']
obj = obj['shape_attributes']
px = obj['all_points_x']
py = obj['all_points_y']
poly = [(x+0.5, y+0.5) for x, y in zip(px, py)]
poly = [p for x in poly for p in x]
x_min, y_min, x_max, y_max = (min(px), min(py), max(px), max(py))
data_anno = dict(
image_id = idx,
id = obj_count,
category_id = 0,
bbox = [x_min, y_min, x_max-x_min, y_max-y_min],
area = (x_max - x_min) * (y_max - y_min),
segmentation = [poly],
iscrowd = 0
)
annotations.append(data_anno)
obj_count += 1
coco_format_json = dict(
images = images,
annotations = annotations,
categories=[{'id':0, 'name':'balloon'}]
)
mmengine.dump(coco_format_json, out_file)-> 3개 경로 입력 받음(ann_file:현재 어노테이션 파일 경로, out_file: COCO 포맷으로 변환된 파일 경로, image_prefix: 이미지 데이터가 저장된 경로)
-> 현재 어노테이션 파일을 읽어와서 data_infos라는 변수로 지정
-> annotations, image라는 빈 리스트 생성 obj_count = 0으로 설정
-> 현재의 어노테이션 파일의 값을 v라는 변수로 하나씩 불러옴
-> filename = 현재 어노테이션의 filename
-> img_path = 이미지데이터의 경로 + 파일이름
-> 이미지 데이터의 shape은 높이, 너비, 채널로 이루어지므로, 각 이미지의 높이 너비는 각 이미지 데이터의 shape의 [:2]
-> images 리스트에 앞에서 저장해둔 변수들을 dict()으로 딕셔너리의 형태로 입력
-> bboxes, labels, masks라는 빈 리스트 생성
-> 현재 어노테이션의 ‘regions’의 값들을 obj라는 변수로 하나씩 불러옴
-> region_attributes가 빈 튜플이 아니면, 오류를 발생시킴 (디버깅 하는 용도)
-> obj = 현재의 어노테이션의 shape_attributes, px = shape_attributes에 있는 ‘all_points_x’값, py = shape_attributes에 있는 ‘all_points_y’값 각 객체의 좌표값을 px, py 리스트에 입력
-> poly = px, py에 입력된 각 좌표 값에 0.5를 더함 그렇게 만들어진 poly의 각각의 값을 x, y라는 변수로 나씩 불러옴 poly = [(x+0.5,y+0.5),…..] 그런 x를 p라는 변수로 하나씩 불러와서 리스트로 묶음 poly = [x+0.5, y+0.5, …..] 즉, x,y 좌표 + 0.5를 poly라는 리스트에 입력
-> x_min, y_min, x_max, y_max값은 방금 읽은 x와 y좌표의 min값과 max값으로 지정
-> data_anno라는 변수에 딕셔너리의 형태로 각각의 값들을 입력
바운딩 박스는 x,y좌표의 min, max값을 활용하여 계산
area는 넓이이므로 x와 y좌표를 활용하여 사각형의 넓이를 계산
segmentation형태가 polygon이므로 iscrowd = 0
-> annotations라는 리스트에 data_anno 딕셔너리 입력, obj_count에 1을 더해줌
-> coco_format_json = 딕셔너리 형태로 최종 coco 포맷 데이터
images, annotations, categories로 이루어짐 images = images(리스트)
annotations = annotations(리스트)
categories = [{'id':0, 'name': 'balloon'}]
현재의 데이터는 객체가 풍선 하나이므로 카테고리를 직접 딕셔너리로 입력
-> 완성된 coco_format_json을 out_file의 경로에 어노테이션의 형태로 만들어 저장
convert_balloon_to_coco(
'./balloondatasets/balloon/train/via_region_data.json',
'./balloondatasets/balloon/train/annotation_coco.json',
'./balloondatasets/balloon/train/'
)
convert_balloon_to_coco(
'./balloondatasets/balloon/val/via_region_data.json',
'./balloondatasets/balloon/val/annotation_coco.json',
'./balloondatasets/balloon/val/'
)
- 변환된 COCO 포맷의 어노테이션 파일
annotation_coco = mmengine.load('./balloondatasets/balloon/train/annotation_coco.json')
annotation_coco.keys()
Chapter4 단일 class Segmentation 모델 학습
config 설정
- config 파일: 매개변수 및 기본 설정을 구성하는 파일, 학습할 model의 구성 파일
!mim download mmdet --config faster-rcnn_r50_fpn_1x_coco --dest ./checkpoints
from mmengine.runner import set_random_seed
cfg.metainfo = {
'classes' : ('balloon',),
'palette' : [
(220, 20, 60),
]
}
cfg.data_root='./balloondatasets/balloon'
cfg.train_dataloader.dataset.ann_file = 'train/annotation_coco.json'
cfg.train_dataloader.dataset.data_root = cfg.data_root
cfg.train_dataloader.dataset.data_prefix.img = 'train/'
cfg.train_dataloader.dataset.metainfo = cfg.metainfo
cfg.val_dataloader.dataset.ann_file = 'val/annotation_coco.json'
cfg.val_dataloader.dataset.data_root = cfg.data_root
cfg.val_dataloader.dataset.data_prefix.img = 'val/'
cfg.val_dataloader.dataset.metainfo = cfg.metainfo
cfg.test_dataloader = cfg.val_dataloader
cfg.val_evaluator.ann_file = cfg.data_root + '/' + 'val/annotation_coco.json'
cfg.test_evaluator = cfg.val_evaluator
cfg.model.roi_head.bbox_head.num_classes = 1
cfg.model.roi_head.mask_head.num_classes = 1
cfg.load_from = './checkpoints/mask_rcnn_r50_caffe_fpn_1x_coco_bbox_mAP-0.38__segm_mAP-0.344_20200504_231812-0ebd1859.pth'
cfg.work_dir = './work_dir/balloon/seg'
cfg.train_cfg.val_interval = 3
cfg.default_hooks.checkpoint.interval = 3
cfg.optim_wrapper.optimizer.lr = 0.02 / 8
cfg.default_hooks.logger.interval = 10
cfg.seed = 0
cfg.visualizer.vis_backends.append({"type":'TensorboardVisBackend'})
with open('./checkpoints/balloon_seg.py', 'w') as f:
f.write(cfg.pretty_text)
학습하기
!python tools/train.py ./checkpoints/balloon_seg.py- tensorboard를 활용한 학습결과 시각화
import tensorboard
%load_ext tensorboard
%tensorboard --logdir './work_dir/balloon/seg' --port=7777- 학습된 모델로 Object Detection
import mmcv
from mmdet.apis import init_detector, inference_detector
img = mmcv.imread('./balloondatasets/balloon/train/7178882742_f090f3ce56_k.jpg', channel_order='rgb')
checkpoint_file = './work_dir/balloon/seg/epoch_12.pth'
model = init_detector(cfg, checkpoint_file, device='cuda:0')
new_result = inference_detector(model, img)
print(new_result)from mmengine.visualization import Visualizer
from mmengine.registry import VISUALIZERS
visualizer_cfg = dict(type='DetLocalVisualizer',
vis_backend=[dict(type='WandbVisBackend')],
name='visualizer')
VISUALIZERS.build(visualizer_cfg)
visualizer_now = Visualizer.get_current_instance()
visualizer_now.dataset_meta = model.dataset_meta
visualizer_now.add_datasample(
'new_result',
img,
data_sample = new_result,
draw_gt = False,
wait_time = 0
)
visualizer_now.show()
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
