제로베이스
1.데이터 취업 스쿨을 시작하면서

대학교를 졸업하고 대학원을 진학했으나 개인적인 사유로 인해 학업을 중단하게 되었고, 취업을 준비하면서 물류센터에서 근무하고 있습니다.향후 진로에 대한 고민을 가지고 있는 상황에서 데이터와 관련된 직무는 인공지능 기술이 발전하고 상용화 될 수록 무궁한 발전가능성을 가지고
2.파이썬 기초

01\_파이썬소개 및 설치02\_처음 만들어 보는 프로그램03\_프로그램 실행 과정 \- 컴파일 언어는 소스 전체를 실행 파일로 만든 후 기계에서 실행 -> 번역 (C, C++, java) \- 인터프린터 언어는 필요한 소스만 그때그때 실행 -> 동시 통역 (py
3.파이썬 중급

01\_함수란? \- 파이썬의 함수는 수학의 함수와 동일 \- 내장 함수: 파이썬이 기본적으로 제공해주는 함수 ex) print \- 사용자 함수: 사용자가 직접 선언 \- 함수는 특정기능을 재사용 하기 위해 사용함02\_함수 선언과 호출 \- 함수는
4.수학
Part2 수학 Chapter1 기초 수학 01_약수와 소수 약수: 어떤 수를 나누어 떨어지게 하는 수 소수: 1과 자신만을 약수로 가지는 수 (1은 제외) 03_소인수와 소인수분해 소인수: 약수 중에서 소수인 숫자 소인수 분해: 1보다 큰 정수
5.자료구조 & 알고리즘 with Python (1)

Part3 자료구조 & 알고리즘 with Python Chapter1 자료구조 01_자료구조란? 자료구조: 컨테이너 자료형의 데이터 구조 컨테이너 자료형: 여러개의 데이터가 묶여있는 자료형 자료구조는 각각의 컨테이너 자료형에 따라서 차이가 있으며,
6.자료구조 & 알고리즘 with Python (2)

01\_선형 검색 \- 선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는 것 \- 보초법: 마지막 인덱스에 찾으려는 값을 추가해서 찾는 과정 간략화 \-> 마지막에 찾으면 검색실패 \-> 중간에서 찾으면 검색성공03\_이진 검색 \
7.SQL 데이터 분석 (1)
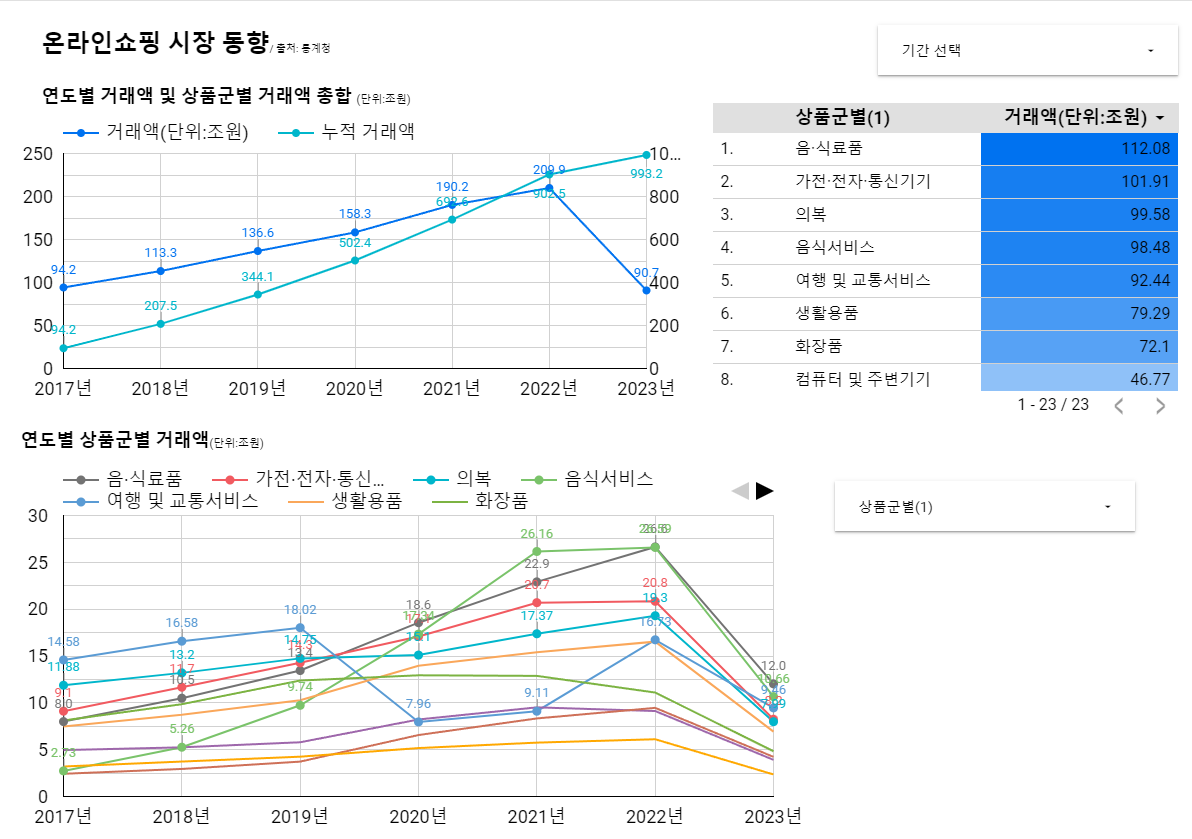
분석가는 도메인, 시장/트렌드, 경쟁사 등 넓은 관심사를 가져야 함통계청은 온라인 쇼핑 동향 데이터 셋 사용온라인 쇼핑 거래액 -> 판매매체(모바일/인터넷), 취급범위(종합몰/전문몰), 운영형태(온라인/온오프라인 복합)해당 데이터를 그대로 사용 불가 문제점은?\-->
8.통계 (1)
변수: 정해지지 않은 임의의 값을 표현하기 위해 사용된 기호, '변하는 숫자', 조사 목적에 따라 관측된 자료 값질적 자료: 몇개의 범주로 구분하여 표현할 수 있는 데이터양적 자료: 숫자 형태의 관측된 데이터, 숫자의 크기가 의미 가짐EDA(Exploratory Dat
9.Pandas 기초

파이썬의 데이터 분석 라이브러리'PANel DAta'의 앞 글자를 따서 지어짐특징\-> 간편한 문법 (낮은 진입 장벽)\-> 다양한 기능\-> 뛰어난 성능 (대용량 데이터 처리 가능)\-> 다양한 포맷/DB 연동 지원\-> 지속적인 개선, 업데이트Pandas가 제공하는
10.Pandas 기초 실습(Series)

이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
11.Pandas 실습 (DataFrame)

결과결과결과결과결과결과결과결과결과결과결과이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
12.통계 (2)
확률: 모든 경우의 수에 대한 특정 사건이 발생한는 비율확률의 고전적 정의: 그것이 일어날 수 있는 경우의 수 대 가능한 모든 경우의 수의 비표본 공간: 어떤 실험에서 나올 수 있는 모든 가능한 결과들의 집합합사건: 사건A 또는 사건B가 일어날 확률곱사건: 사건A와 사
13.통계 (3)
확률분포: 확률변수 X가 취할 수 있는 모든 값과 그 값을 나타낸 확률을 표현한 함수이산형 균등분포: 확률 변수 X가 유한개이고, 모든 확률 변수에 대하여 균일한 확률을 갖는 분포$$f_x(x) = P(X = x) = \\frac{1}{N}, \\quad \\text{
14.머신러닝 (1)
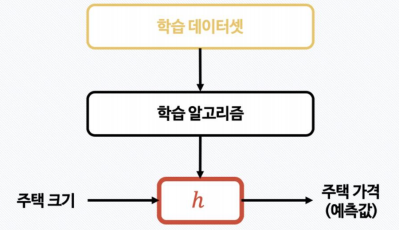
내가 준 데이터로 나 대신 공부하고 나 대신 대답하는 것Iris 품종 분류에서는 Versicolor, Virginica, Setosa 3종류가 있음꽃잎과 꽃받침의 길이, 넓이 정보를 제공하여 주고 이를 통해 3종의 품종을 분류함Iris 데이터셋에서 Sepal lengt
15.머신러닝 (2)

Chapter3 (회귀) 1. 지도 학습과 비지도 학습 머신러닝의 종류: 지도학습, 비지도학습, 강화학습 지도학습: 정답을 알려주고 학습시키는 것 1) 분류 Classification (0/1 방식으로 구분되는 것) 2) 회귀 Regression (정답, 라벨이 연
16.머신러닝 (3)

Wine 데이터: 분류 문제에서 많이 사용하는 예제레드와인/화이트와인 두 종류의 데이터셋 존재두개의 데이터를 합칠때 각각을 구분할 수 있는 부분이 필요함Boxplot을 통해 와인 데이터 항목들을 그렸을 때, 컬럼들의 최대, 최소 범위가 각각 다르고 평균과 분산이 각각
17.머신러닝 (4)
글자를 만나면 숫자로 바꿔준다$$x' = \\frac{x - \\min(x)}{\\max(x) - \\min(x)}$$$$z = \\frac{X - \\mu}{\\sigma}$$$$\\frac{x_i - Q_2}{Q_3 - Q_1}$$아웃라이어에 강하다는 특징이 있음어
18.머신러닝 (5)

모델 자체를 좋다/나쁘다로 평가할 방법은 없음대부분 다양한 모델, 파라미터를 두고 상대적으로 비교회귀 모델은 실제 값과의 에러치를 가지고 계산함분류 모델은 평가 항목이 많음이진 분류 모델 평가Accuracy 정확도: 전체 데이터 중 맞게 예측한 것 비율$$\\text{
19.머신러닝 (6)
이름은 regression이지만 실제로는 분류기분류: 연속적이지 않은 값회귀: 연속된 값모든 회귀문제가 선형만 있는 것은 아니지만, 회귀 문제 중 가장 쉬운 것이 선형직선상에 있지 않은 세 점을 직선으로 표현하려면 에러가 발생할 수 밖에 없음직선으로만 표현하려고 한다면
20.머신러닝 (7)
특별한 학술적이거나 수학적 분포를 찾기 어려운 상태에서 변화시켜야 할 파라미터과적합: 모델이 학습데이터에만 과도하게 최적화된 현상으로, 일반화된 데이터에서는 예측 성능이 과하게 떨어짐Holdoutk-fold cross validation\-> validation의 역할
21.머신러닝 (8)
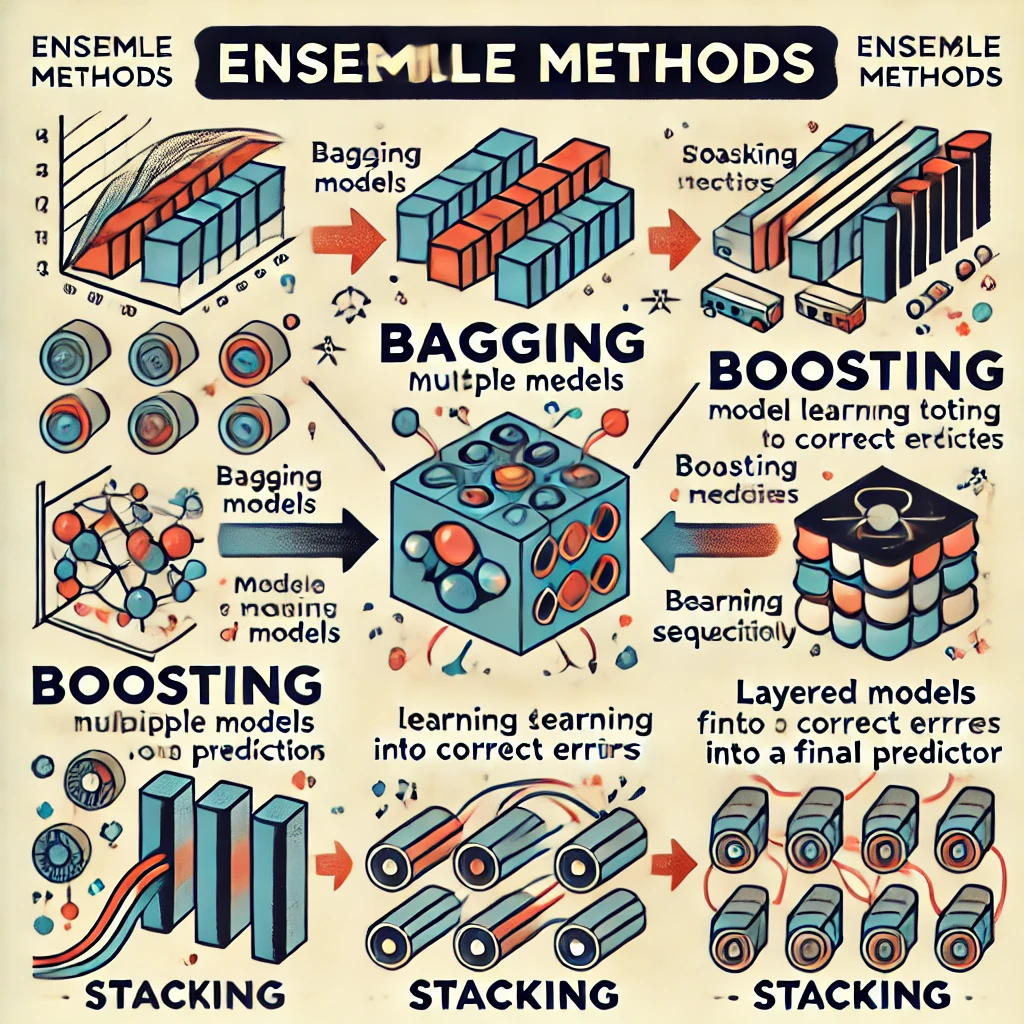
앙상블: 다양한 모델을 사용하여 예측 성능을 보다 더 높이는 것voting: 전체 데이터셋에 각각의 다른 기법을 사용하는 것bagging: data set을 샘플링해서 같은 기법을 사용하는 것\-> bagging에서는 데이터 중복을 허용해서 샘플링\-> 각각의 분류기에
22.머신러닝 (9)

신용카드 부정 사용자 검출 데이터금융 데이터이고 기업의 기밀 보호를 위해서 대다수 특성의 이름이 삭제되어 있음데이터의 불균형이 심각데이터의 불균형이 심해서 'stratify = y'를 사용Boosting\-> 여러 개의 약한 분류기(성능을 낮지만 빠른 것)가 순차적으로
23.머신러닝 (10)
PCA: 정보를 최대한 보존하면서 새로운 축을 찾아, 고차원을 저차원으로 변환차원축소와 변수추출 기법으로 많이 쓰이는 주성분 분석데이터를 어떤 벡터에 정사영시켜 차원을 낮출 수 있음새로운 특성을 찾아서 표현하는 것Iris 데이터는 특성이 4개라 한번에 그릴 수 없음(1
24.머신러닝 (11)
Olivetti 데이터olivetti_faces.npy/olivetti_faces_target.npy 파일400개의 이미지와 40개의 label로 구성얼굴 인식용으로 사용가능한 데이터지만 특정 인물의 데이터(10장)만 사용해서 PCA 실습 진행주성분분석을 하면 원점과
25.Git (1)
형상 관리 시스템(Configuration Management Systems)버전 관리 시스템(Version Control System)Source Data + History협업, 작업 추적, 복구 등이 가능Local Version Control Systems\-> 내
26.Git (2)
Tracked 안으로 들어가면 그때부터 git이 해당 파일을 관리하기 시작함Git Status\-> Working Directory와 Staging Area의 상태를 표시\-> 파일의 상태 확인 시 사용Git Add\-> Working Directory 에서생성된파일을
27.Git (3)
Local과 Remote는 서로 push, pull 하면서 버전 공유Remote 저장소 추가Remote 저장소 주소 수정이름 수정삭제정보 확인상세보기Pull\-> Remote Repository의 작업내용을 Local Repository에 동기화\-> 사실은 Fetch
28.OpenCV (1)

OpenCV 소개 Open Computer Vision Library 실시간 이미지 처리부터 머신러닝 까지 얼굴인식, 객체탐지, 영상추적, 특징 추출 등.. 작업 수행 가능 이미지, 영상에 대한 다양한 처리 가능 Chapter1 OpenCV 기초 이미지 읽기 jpg,
29.OpenCV (2)
Pixel: Picture Element (화소)한 픽셀은 RGB로 구성되어 있음해상도: 화소 수배열로 표현해서 가로, 세로가 뒤집혀서 나올 수 있음이미지에서 원점은 좌측 상단ROI 추출 (Region of Interest, 관심 영역)색상공간: 색을 표현하는 방법을
30.OpenCV (3)
캔버스 준비하기: 아무 값도 없기에 검은색으로 나옴사각형 그리기속이 꽉찬 직사각형 그리기원 그리기타원 그리기Angle을 조절해서 타원은 다 그리지 않을 수도 있음삼각형 그리기도형을 그릴때는 순서가 중요함선 그리기점 그리기: 원의 속을 채워서 사용그림 불러와서 텍스트 입
31.OpenCV (4)
Bitwise 연산: 같은 픽셀에 있는 것들끼리 연산 해 주는 것Bitwise - and 연산Bitwise - or, xor, not 연산컬러 이미지 Bitwise 연산색상 검출HSV 색상 검출: Hue를 두개 구간으로 나누어서 연산두 장의 이미지 합성이 글은 제로베이
32.OpenCV (5)

이미지의 밝기 분포를 시각적으로 나타내는 도구가로축: 밝기 레벨(0~255)세로축: 해당 밝기 레벨을 가진 픽셀의 수이미지의 전반적인 밝기 분포와 대비를 한눈에 파악 가능그레이스케일 이미지 히스토그램컬러 이미지 히스토그램이미지의 밝기 히스토그램을 조절하여 전체적인 대비
33.OpenCV (6)

이진화를 하는 이유\-> 데이터 용량 감소: 데이터 크기를 줄여 저장공간과 전송 시간 절약\-> 처리 속도 향상: 흑백으로 되어 있어, 복잡한 연산 없이 빠르게 이미지 처리 가능\-> 특징 강조: 특정 요소나 형상을 두드러지게 만들어, 패턴 인식이나 객체 감지에 유용\
34.OpenCV (7)
엣지: 이미지 내에서 밝기가 갑자기 변하는 지점, 객체의 경계, 형태의 변화, 텍스쳐의 변화 등과 관련있음, 이미지의 기본적 특징 추출 시 사용엣지의 주요 특성\-> 밝기의 급격한 변화: 픽셀 간의 밝기가 급격하게 변하는 지점\-> 방향성: 수직, 수평, 대각선 등 특
35.OpenCV (8)

45도 회전회전 중심을 다른 곳으로이미지 상하좌우 반전배율 조절Interpolation 타입\-> cv2.INTER_NEAREST: 최근접 이웃 보간법, 가장 빠르지만 품질 낮음\-> cv2.INTER_LINEAR: 선형 보간법, 이미지 확대 시 좋은 결과 제공\->
36.MMDetection (1)
Chapter0 MMDectection 소개 중국의 openMMlab을 중심으로 만든 Pytorch기반의 오픈소스 패키지 다양한 object detection, instance segmentation, panoptic seqmentation 알고리즘을 패키지로 제공
37.MMDetection (2)
데이터 가져오기데이터 압축 해제하기이미지 장 수 확인하기예제 데이터 확인하기사전적 의미로 주석데이터를 설명해주는 데이터사람이 사진을 보고 판단하는 것과 같음학습용 데이터셋은 항상 정답이 포함되어야 함 (무엇이 정답이고 무엇이 오답인지 알려주어야 함)풍선 데이터의 어노테
38.MMDetection (3)
Chapter5 다중 class Object 모델 학습 데이터 준비 사용할 데이터셋 아쿠아리움 데이터 아쿠아리움 데이터 다운받기 로컬 PC에 다운로드 후 구글드라이브에 업로드 코랩 환경에서 데이터 가져오기 예제 데이터 확인 데이터 학습 8개 class가 데이터에
39.MMDetection (4)

import모듈 동작 확인데이터셋 (아쿠아리움 데이터)변환함수데이터 셋 관련 함수데이터 전처리 및 확인모델 준비학습 결과 이미지로 확인이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
40.MMDetection (5)

Panoptic segmentation = Semantic segmentation(Class별 구분, 모든 이미지에 대해서) + Instance segmentation(개별 객체별로 구분, 배경에 대해서는 예측하지 않음)Panoptic Segmentation의 구성Th
41.MMDetection (6)
사용 데이터: AI Hub에서 제공하는 로봇 관점 주행 영상필요 모듈 import필요 파일 경로 정의이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
42.YOLO (1)
Chapter0 YOLO소개 You Only Look Once 한번에 class와 boundingbox에 대한 정보를 얻음 YOLO v2 YOLO v3 
Chapter 2 Classification
44.YOLO (3)
데이터셋 확보Aquarium Dataset구글 코랩 환경에서 데이터 셋 저장할 폴더 생성 후 다운로드데이터 셋 압축 해제YOLO 설치학습 시작학습 진행 시 정상적으로 실행되지 않고 error발생하면 data.yaml 파일 내용에 path 추가코랩에서 학습시킨 모델 파일
45.YOLO (4)

YOLOv8에서는 총 17개의 Keypoint를 활용해서 동작 감지데이터 셋 준비 (샘플데이터)실내 구매행동 데이터이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
46.Tableau (1)

DATA LITERACY: 개별 구성원들에게 요구 되는 것\-> share/understand/insight/communication/explore/see/collaboration데이터 시각화: 데이터에 색상과 모양 그리고 사람들의 시선을 끌 수 있는 요소를 배치해 데
47.Tableau (2)

사용 데이터: SuperStore_KR.xlsx테이블막대 차트: 특정 집계에 대한 절대적인 크기를 시각적으로 표현하기에 적합라인 차트: 일련의 값에 대한 시간적 추세 확인, 미랫값 예측하는 경우 사용파이 차트: 점유율 등을 쉽게 이해할 수 있게 만듬, 보고용 자료에 많
48.Tableau (3)
사용 데이터: SuperStore_KR.xlsx특정 데이터에 대한 설명 확인: 특정한 데이터에 대한 설명을 통해 해당 데이터를 이해하기 쉬움콤비네이션/라인+영역: 두개의 서로 다른 정보를 하나의 축에 놓고 보면 생각하지 못했던 부분에서 인사이트를 얻을 수 있음라인 영역
49.Tableau (4)

사용 데이터: SuperStore_KR.xlsx워드 클라우드: 실제 사용빈도는 낮지만 시각적으로 관심을 집중시키기 좋아서 대시보드에 사용됨달력형 히트맵 차트여러개의 시트를 하나의 화면에 만들어 시각화 하는 것대시보드 동작: 필터, 하이라이트, URL로 이동, 시트로 이
50.통계 (4)
Chapter2 기초통계-심화과정 가설 검정과 유의수준 정의 가설 검정 = 가설(Hypothesis) + 검정(Testing) 가설: 주어진 사실 또는 조사하려고 하는 사실에 대한 주장 또는 추측 통계학에서는 특히 모수를 추정 할 때 모수가 엉떠하다는 증명하고 싶은 추
51.통계 (5)
Chapter 2 기초통계-심화과정 범주형자료분석 적합도 검정 범주형 자료: 관측된 결과를 어떤 속성에 따라 몇 개의 범주로 분류 시켜 도수로 주어진 데이터 범주형 자료 분석(categorical data analysis) -> 범주형 자료에 대한 통계적 추론 방법
52.통계 (6)
셋 이상의 모집단으로부터 추출한 양적 데이터를 비교하는 통계적 분석 방법t-test: 두개의 모집단의 평균 차이를 검정분산분석의 이해실험계획법(experimental design): 모집단의 특성에 대하여 추론하기 위해 특별한 목적성을 가지고 데이터를 수집하기 위한 실
53.Tableau (5)

Chapter 3 Tableau for Business Analytics 퀵 테이블 계산 누계 차이
54.딥러닝 (1)
Chapter 1 딥러닝 개요 딥러닝이란? 머신러닝: 데이터를 활용하여 작업의 성능 지표(퍼포먼스)를 향상시키는 연구 인공신경망: 머신러닝 알고리즘 중에 하나 딥러닝: 인공신경망 중 특정한 알고리즘 군, 50년대 부터 연구되어 온 인공신경망 모델의 연장선에있음 머신러
55.딥러닝 (2)

탠서플로우 (Tensorflow)\-> 구글에서 유지/보수하는 오픈소스 딥러닝 프레임워크\-> 파이썬을 기본으로 자바스크립트, 모바일, 에지 디바이스, REST API 등 다양한 개발 및 배포 환경 제공\-> 퍼포먼스와 사용성 겸비한 프레임워크\-> C++과 CUDA
56.딥러닝 (3)

Chapter 3 인공신경망 인공신경망 (Artificial Neural Network) 소개 인간 두뇌의 신경망 구조를 모방하여 구현한 머신 러닝 모델 -> 신경이 서로 연결된 강도(시냅스 연결 강도시냅스 연결 강도)에 따라 논리적인 동작이
57.딥러닝 (4)

가능한 모든 해 중 최적의 해를 찾는 문제를 해결하는 이론제약 조건(constraint conditions)을 지키면서 목적 함수(objective function)가 최소가 되게 하는 최적의 해(optimal solution)를 찾는 문제최소화 문제와 최대화 문제는
58.딥러닝 (5)
화이트박스 모델과 블랙박스 모델\-> 화이트박스(white box) – 모델의 동작 원리와 근거를 명확히 파악할 수 있는 모델로, 전통적인 머신 러닝 모델이 이에 해당\-> 블랙박스(black box) – 모델의 내부 동작을 이해하기 어렵
59.딥러닝 (6)
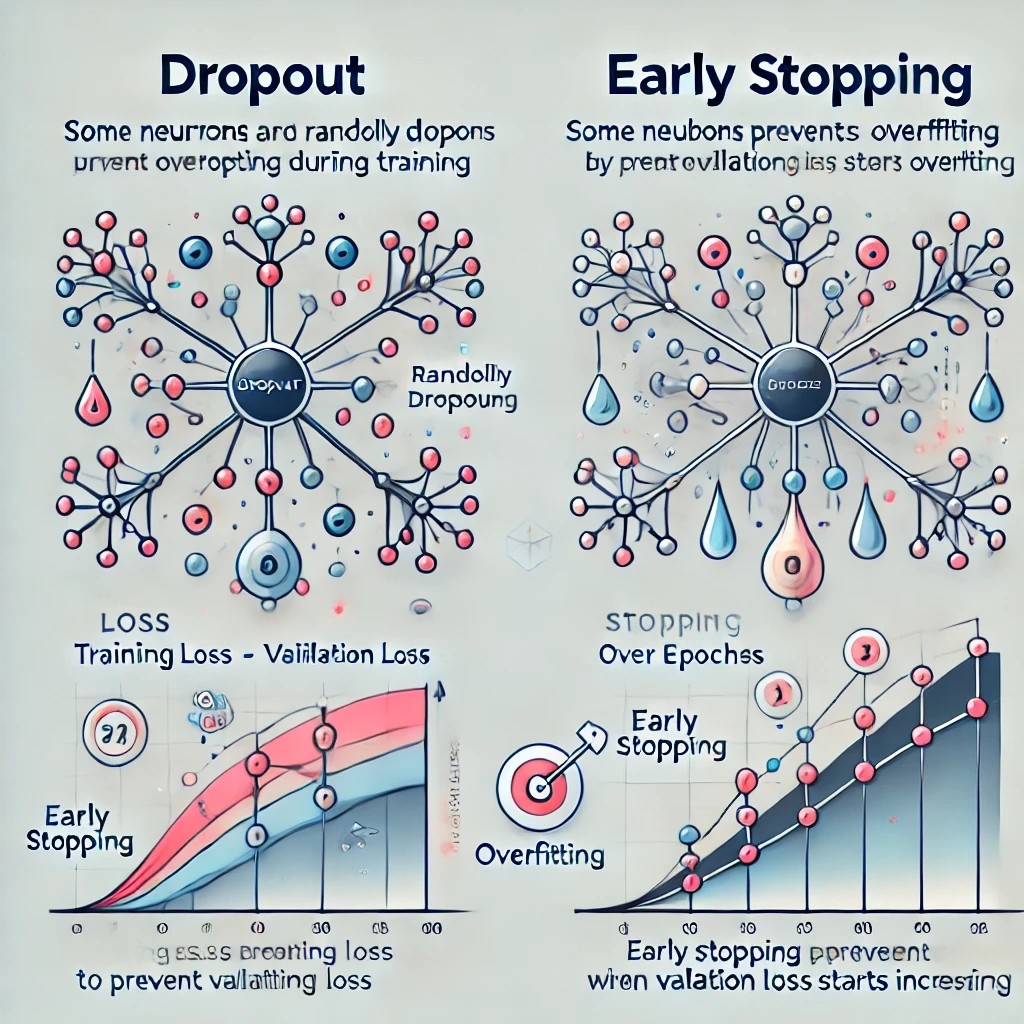
모델의 학습이 적절하게 이루어지지 않아, 성능이 하락하는 문제\-> 과소적합(underfitting) – 모델이 학습 데이터를 충분히 표현하지 못하는 경우 (높은 분산)\-> 과대적합(overfitting) – 모델이 학습 데이터를 표현하는
60.딥러닝 (7)
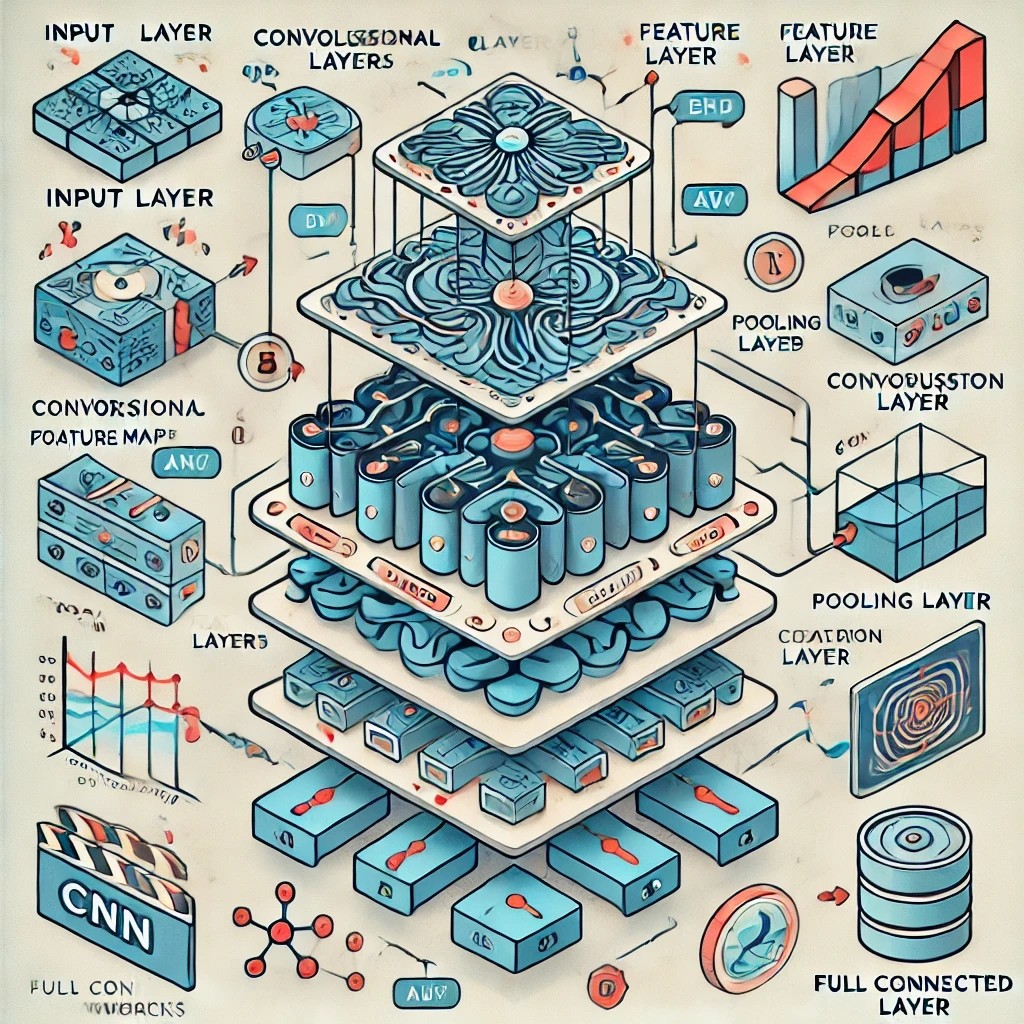
필터(filter)를 학습하여 합성곱 연산을 기반으로 하는 인공신경망주로 영상(image)을 입력으로 하며, 다양한 기능을 구현할 수 있다.\-> 영상 분류: 영상의 내용을 분석하여 어떤 클래스인지 분류 (합성곱은 특징 추출에 사용)\->
61.딥러닝 (8)
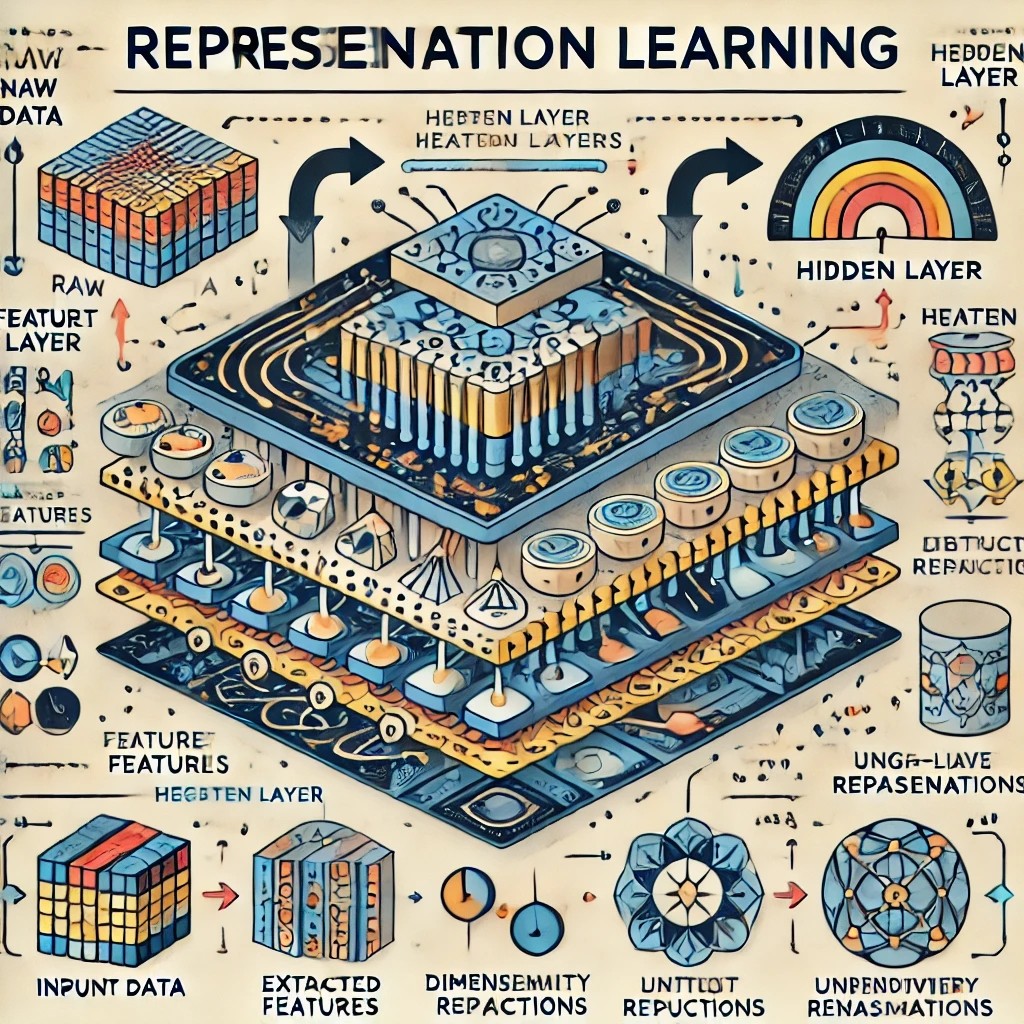
샘플을 의미 있는 데이터로 만드는 변환(transform)을 학습하는 방법가공되지 않은 입력(raw input)보다 주어진 작업에 더 유용한 표현(representation)을 구하고자 할 때 사용\-> 입력을 변환한 결과를 특징(fea
62.딥러닝 (9)

순서가 의미가 있으며, 순서가 달라지면 의미가 손상되는 데이터시간적 순서 데이터(temporal sequence data) – 순차 데이터 중, 특별히 순서가 시간과 연관이 있는 경우시계열(time series) – 시간적 순서 데이터가
63.딥러닝 (10)
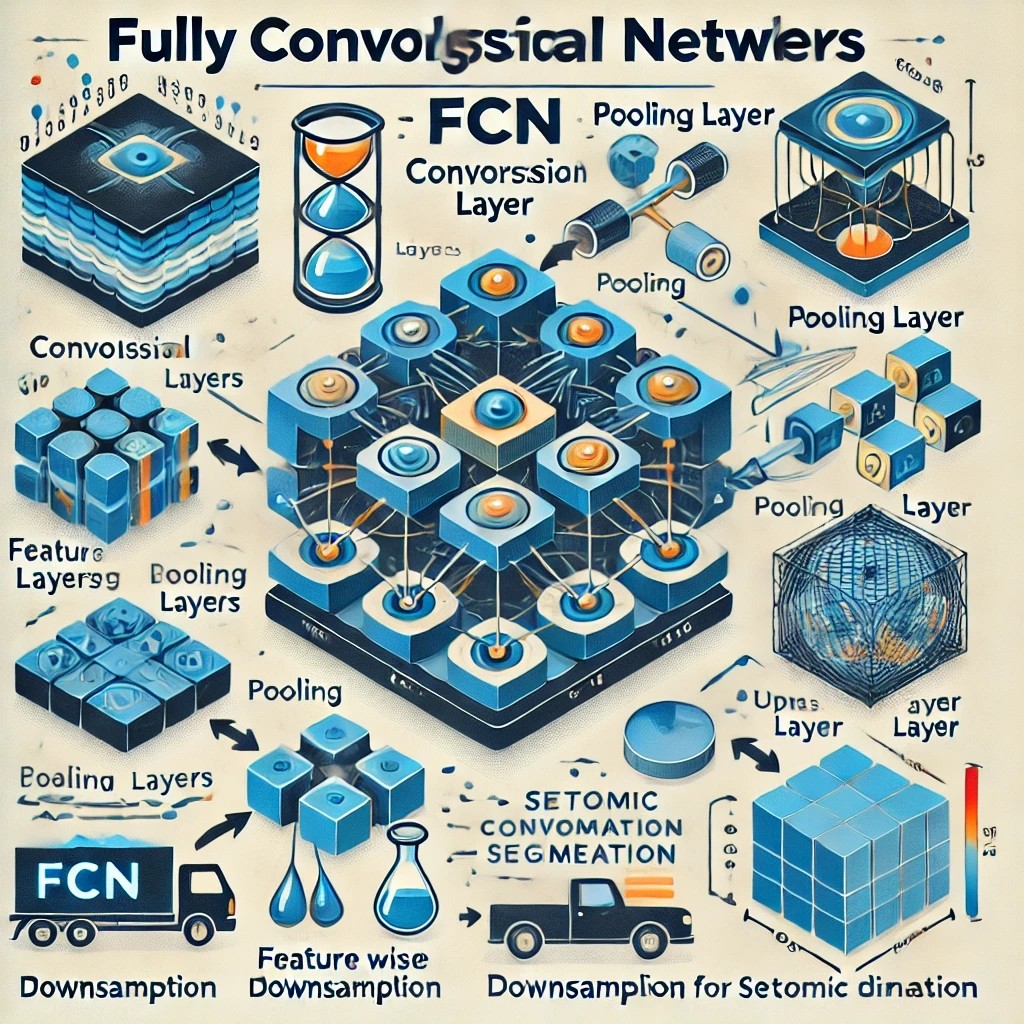
Chapter 11 현대적인 인공신경망 Fully-Convolutional Networks (FCN) 전결합계층 없이 합성곱 계층만을 이용한 네트워크 의미론적 영상 분할을 위한 딥러닝 모델로, 픽셀 단위로 레이블을 분류하는 문제 해결 일반적인 합성곱
64.LSTM (1)
이미지 분류얼굴 방향동작 감지학습이 완료된 efficientnet이라는 모델을 이용해서 분류기 세팅mediapipe의 solution에서 pose를 받아오는 함수pose 찾기영상에서 pose를 추출하고 다시 영상에 입히는 함수이 글은 제로베이스 데이터 취업 스쿨의 강의
65.딥러닝 (11)
Generative: 생성적Adversarial: 적대적기계 학습 역사상 가장 독창적인 아이디어로 평가받는 생성 기법인공지능이 비로소 예술적인 결과물을 만들기 시작한 효시영상을 출력하는 다양한 기존 네트워크에 적용되어 시각적 성능
66.LSTM (2)

Chapter 2 Face Pose Detection 랜드마크를 활용하여 코 위치 찾기 데이터 특징 추출하기 얼굴 각도 찾기 [사용데이터셋](https://www.kaggle.com/datasets/mohamedadlyi/aflw2000-3d ) 이미지 가져오기
67.LLM (1)
Chapter 1 Huggingface Tutorials 허깅페이스 코랩 환경에서 설치 -> transformers: 트랜스포머 모델과 토크나이저 사용 -> datasets: 라이브러리와 데이터셋을 쉽게 사용 -> huggingface_hub: 허깅페이스 허브와 연
68.LLM (2)

LLaMa3\-> LLaMa(Large Language Model Meta AI) 모델은 Meta(옛 페이스북)에서 개발한 대규모 언어 모델 시리즈\-> 기존에 널리 사용되던 거대 언어 모델(예: GPT 계열, BERT, RoBERTa 등)은 주로 클로즈드 소스 형태로
69.LLM (3)

LLM: 다양한 매개변수를 사용해 레이블이 없는 방대한 양의 텍스트를 학습하는 딥러닝 기반의 모델tokenizer: 문장을 token으로 분해하는 과정embedding: 토큰을 숫자로 된 벡터로 변환하는 과정처음에는 RNN으로 접근했지만 한계에 부딪힘transforme
70.머신러닝v2 (1)
인공지능이 가장 넓은 범주에 속함머신 러닝의 핵심은 데이터와 규칙의 학습 유무\-> IF-THEN 규칙으로 직접 행동 조건을 프로그래밍 하는 것은 머신러닝이 아님인공지능(Artificial Intelligence): 컴퓨터가 사람의 행동을 모방하도록 하는 연구
71.머신러닝v2 (2)

모집단(Population): 통계적인 정보를 얻고자 하는 대상이 되는 전체 집단으로 관심이 있는 전체 집단이므로, 전체 집합으로 표현\-> 모집단은 우리가 실제 분포를 알 수 없으며, 통계 추정의 대상이 됨\-> 모집단 분포를 이미
72.머신러닝v2 (3)

빈도주의 통계(frequentist): 실험을 시행했을 때, 전체 횟수에 확률 값을 곱한 숫자만큼 해당 사건이 발생한다고 보는 관점베이지안 통계(Bayesian): 임의의 표본을 하나 선택했을 때, 해당 표본이 해당 사건이라는 주장의
73.머신러닝v2 (4)
분류 모델(Classification Model): 범주형 변수(categorical variable)를 구분하는 머신 러닝 모델\-> 입력 받은 데이터가 어떤 범주에 속하는지 구분하는 모델\-> 일반적으로 입력은 길이가 정해진 벡터를 사용한다.\
74.머신러닝v2 (5)

Chapter 5 회귀 모델 회귀 모델과 학습 회귀분석(Regression Analysis): 연속적인 출력 값을 예측하는 통계 분석 방법 -> 1886년 프랜시스 골턴의 연구에서, 세대가 흘러도 자녀의 키는 전체의 평균으로 ‘회귀’하는 것을 관찰한
75.머신러닝v2 (6)
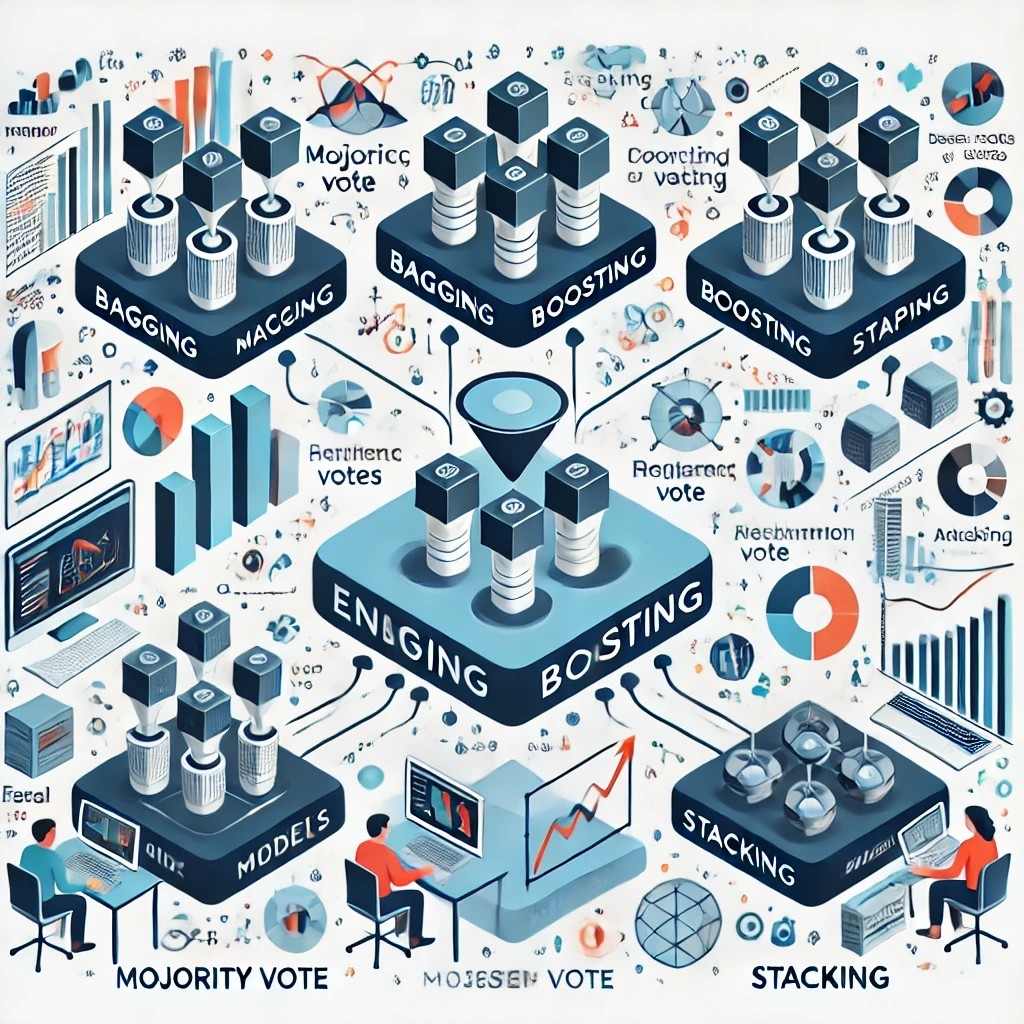
다양한 모델을 학습한 후 이것을 모아 더 좋은 예측을 얻는 기법\-> 여러 모델의 장단점을 상호 보완적으로 결합하여 사용\-> 약한 학습기(weak learner)를 충분히 많이 결합할 경우 강한 학습기(strong learner)로 동작투표를 이용
76.머신러닝v2 (7)

학습 알고리즘에 의해 학습되지 않는 매개변수\-> 대표적인 초매개변수로 의사결정나무의 깊이, SVM의 소프트마진 매개변수 등이 있음\-> 그 외 모델을 생성할 때 결정해 주는 모든 매개변수를 초매개변수라고 할 수 있음\-> 초매개변수는 모델의 학습
77.머신러닝v2 (8)
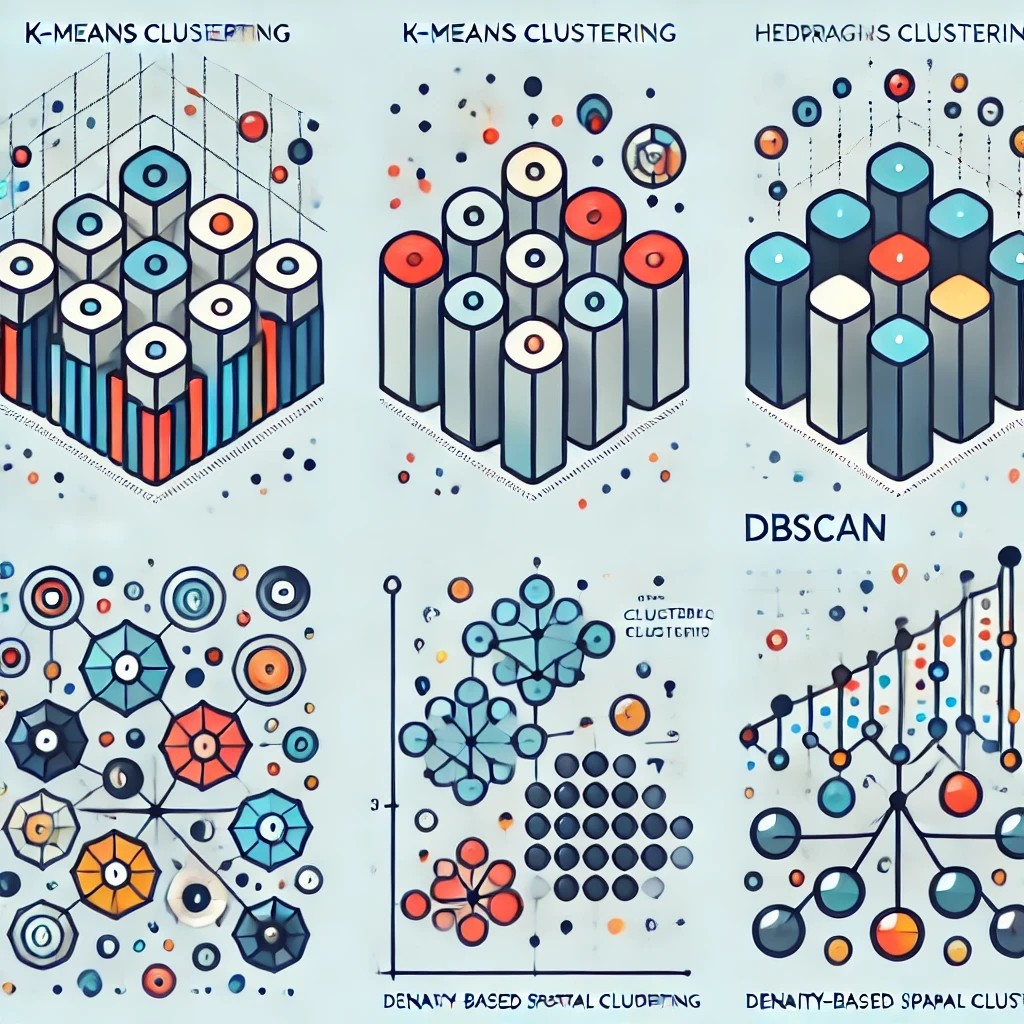
대표적인 비지도 학습 방법으로, 데이터셋의 구조를 파악하는 기법\-> 학습 데이터셋에서 유사한 특징끼리 군집(cluster)를 구성\-> 군집: 특정 기준으로 묶여진 특징. 자동 레이블이라고도 부름\-> 대표적으로 k-평균 군집화(k-means cl
78.머신러닝v2 (9)
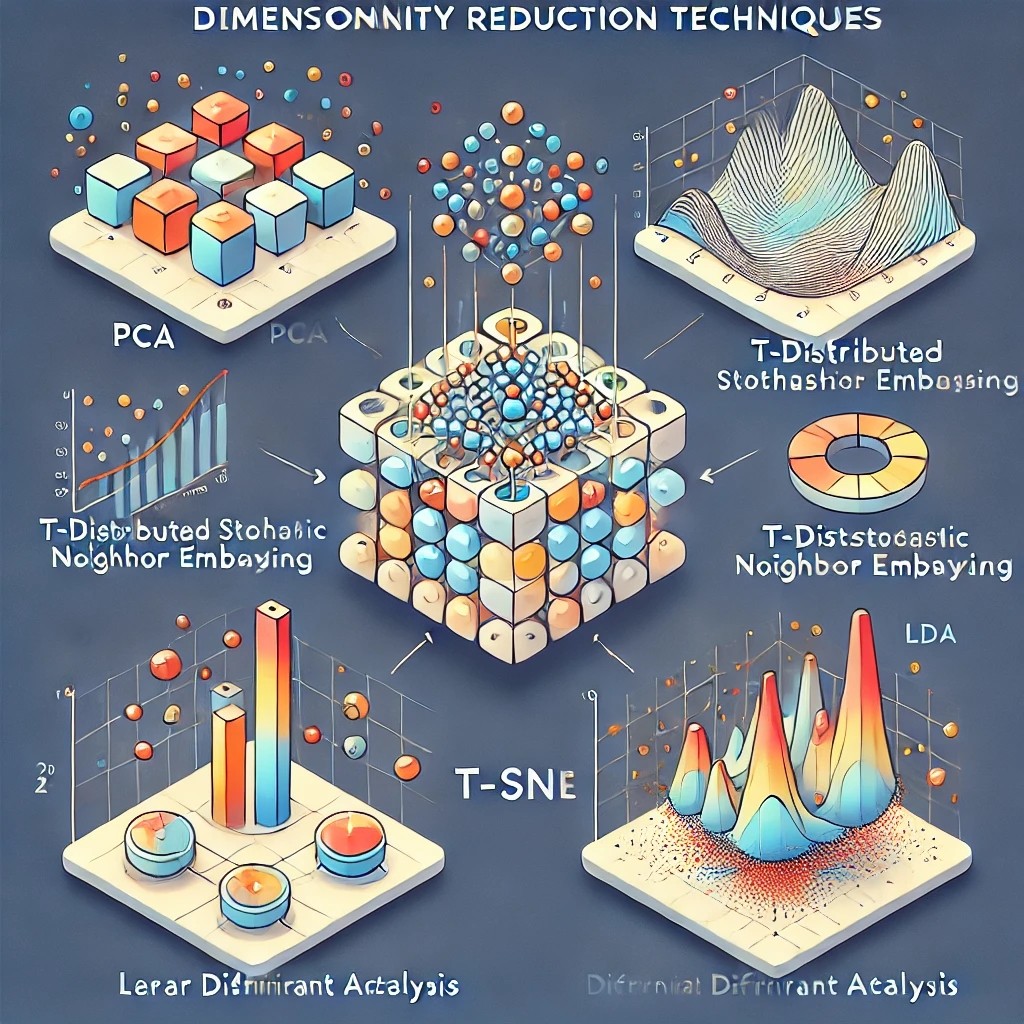
특징 벡터의 정보를 유지하면서 차원을 감소시키는 기법\-> 머신 러닝 알고리즘에서 다룰 차원을 감소시켜 연산량 감소\-> 차원의 저주(curse of dimensionality) 문제를 개선= 주로 비지도 학습법으로 차원 축소 수행\-> 데이터
79.머신러닝v2 (10)

학습 데이터 또는 테스트 입력을 원하는 형태로 변형하는 기술\-> 입력이 벡터가 아닌 경우, 벡터로 표현하는 방법 (벡터화, 임베딩)\-> 입력의 분포나 범위가 머신 러닝 모델에 적합하지 않은 경우 (정규화, 표준화)\-> 범주
80.Tensorflow (1)

Chapter 1 딥러닝 - The Beginning 퍼셉트론 이야기 1958년 로젠블랫이 '퍼셉트론'이라는 논문 발표 퍼셉트론을 통해 기계까 학습하는 것을 시연하는 데 성공함 퍼셉트론과 아달라인은 학습이라는 것을 성공 함 민스키의 기호주의: 전문가의 경험을 녹여들게
81.Tensorflow(2)
Chapter 3 딥러닝 시작하기 Tensorflow 머신러닝을 위한 오픈소스 플랫폼: 딥러닝 프레임워크 구글이 주도적으로 개발: 구글 코랩에 기본 장착 Keras라는 고수준 API 병합 Tensor: 벡터나 행렬 Graph: 텐서가 흐르는 경로 Tensorflow:
82.Tensorflow(3)

각 픽셀에서 255값이 최댓값이라 0~1사이 값으로 조정틀린 내용 확인틀린 내용 확인이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
83.Tensorflow(4)
Convolutional FilterConvolutional 필터 결과Conv 필터의 의미풀링: 점점 더 멀리서 보는 법, 그림을 줄여도 된다MaxPoolingConv Layer의 의미Zero paddingDropout: 융통성을 기르게 하는 것이 글은 제로베이스 데이
84.Tensorflow(5)
imagenet으로 학습한 VGG net의 라벨은 1000개출력의 형태를 바꾸기 위해서는 전이학습 활용이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
85.알고리즘과 복잡도

자료 값의 모임, 자료 간의 관계, 자료에 적용할 수 있는 함수나 명령만능인 자료구조는 없으며, 상황에 맞는 자료 구조를 사용해야 함자료: 현실 세계로부터 수집한 사실이나 개념의 값 또는 이들의 집합\-> 정보: 자료를 특정 용도로 사용하기 위해 처리/가공한 것추상자료
86.파이썬과 코딩테스트

range를 이용한 for문과 인덱싱반복자를 이용한 for문enumerate를 이용한 인덱싱 + 반복자zip을 이용한 여러 반복자 동시 반복기본적인 함수 정의for문에 비해 빠르게 동작하는 장점이 있음\-> for문과 append(가장 나쁜 방법)\-> Pre-allo
87.자료구조-선형 자료 구조 (1)
많은 수의 데이터를 다룰 때 사용하는 자료구조각 데이터를 인덱스와 1:1 대응하도록 구성데이터가 메모리 상에 연속적으로 저장됨크기(Element의 개수)가 정해져 있음자료구조에 기능(메소드)이 포함되어 있지 않음자료가 메모리상에 빈틈 없이 연속적으로 위치해 있음인덱스를
88.자료구조-선형 자료 구조 (2)
리스트와 달리 기능을 제한하는 추상자료형후입선출 (Last In First Out: LIFO)의 특성자료가 입력된 역순으로 처리되어야 할 때 사용 ex) 함수 콜 스택, 인터럽트 처리, 수식 계산 등자료를 top 위에 삽입하는 연산자 (push())자료를 top에서
89.자료구조-비선형 자료구조 (1)
부모와 자식 관계로 이어진 노드의 집합으로 이루어진 자료구조계층적 구조를 나타낼 때 주로 사용\-> 폴더 구조, 조직도, 가계도 ..노드(Node): 트리 구조의 자료 값을 담고 있는 단위 에지(Edge): 노드 간의 연결선 (=link, branch)
90.자료구조-비선형 자료구조 (2)

객체 간에 짝을 이루는 가장 유연한 자료 구조정점(vertex, node, point)와 이를 잇는 간선(edge)로 구성간선은 무향(undirected) 또는 유향(directed)일 수 있음간선에는 가중치(weight)가 있을 수 있으며, 이는 연결의 강도나 간선의
91.알고리즘-기초 알고리즘 (1)
함수가 자기 자신을 호출하는 것분할 정복(Divide & Conquer), 점화식 등을 구현하는 데에 많이 사용재귀 구현은 항상 반복(Iteration) 구현으로 변환될 수 있음재귀식(Recursion relation)이라고도 부르며, 수열의 항 사이의 관계를 나타냄점
92.알고리즘-기초 알고리즘 (2)

자료구조에서 원하는 조건에 맞는 자료를 찾는 것선형 자료구조의 경우, 크게 세 가지 알고리즘이 있음\-> 정렬되지 않은 자료: 선형 탐색\-> 정렬된 자료: 이진 탐색\-> 해싱된 자료: 해시 탐색순차 탐색(Sequential search)라고도 부르며, 가장 단순한
93.알고리즘-기초 알고리즘 (3)
매 순간 현재 기준으로 최선의 답을 선택해 나가는 기법\-> 빠르게 근사치를 계산할 수 있음\-> 결과적으로는 최적해가 아닐 수도 있음탐욕 알고리즘의 결과가 최적해인 경우를 알아야 함N 개의 활동과 각 활동의 시작/종료 시간이 주어졌을 때, 한 사람이 최대한 많이 할
94.알고리즘-심화 알고리즘 (1)

큰 문제를 부분 문제로 나눈 후 답을 찾아가는 과정에서, 계산된 결과를 기록하고 재활용하며 문제의 답을 구하는 방식중간 계산 결과를 기록하기 위한 메모리가 필요한 번 계산한 부분을 다시 계산하지 않아 속도가 빠름분할 정복과의 차이\-> 분할 정복은 부분 문제가 중복되지
95.알고리즘-심화 알고리즘 (2)
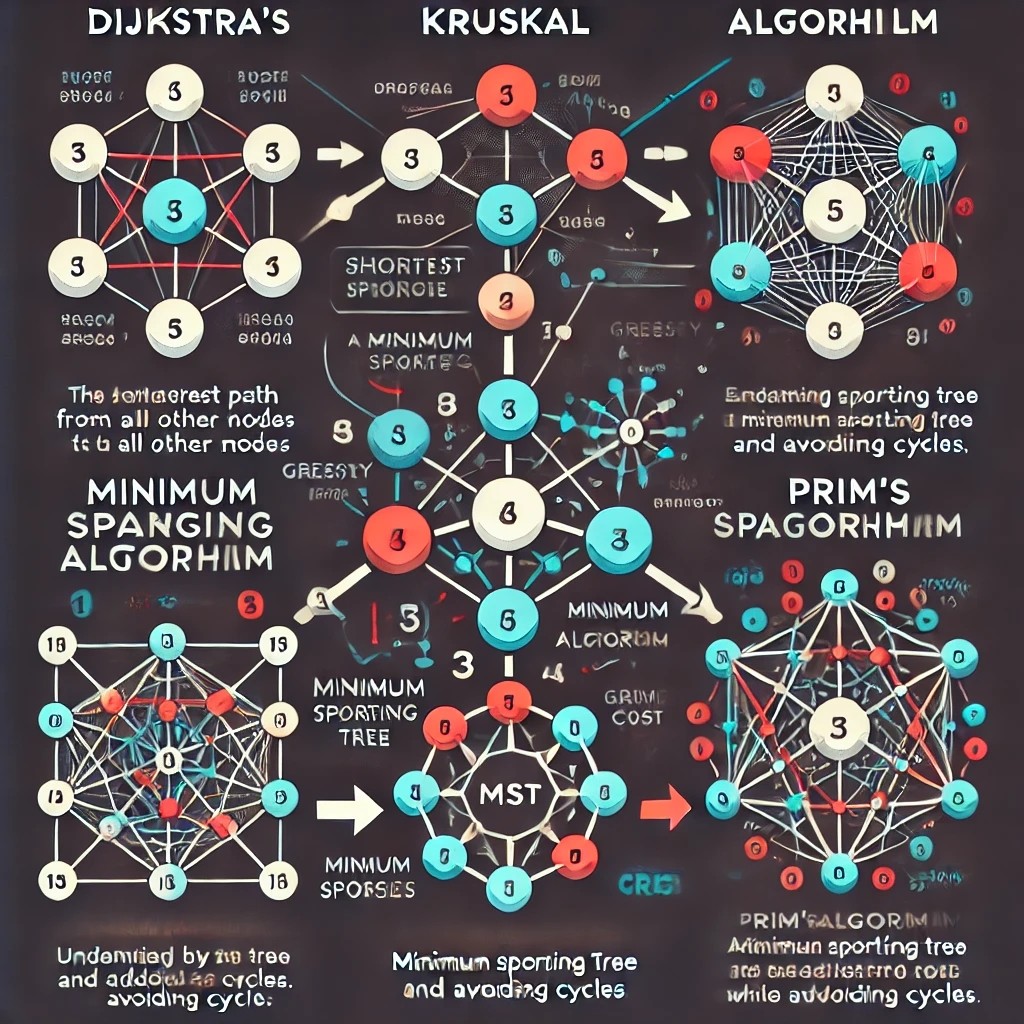
출발점에서 모든 노드로의 최단 경로를 구하는 알고리즘간선에 음의 가중치가 없어야 함탐욕 알고리즘과 DP를 결합한 알고리즘알고리즘 시간복잡도: $𝑂(𝐸 log 𝑉)$다음과 같이 노드와 간선 가중치 정보가 있을 때, A 노드에서 다른 노드들에 대한 최단 경로 구하기