SQL 데이터 분석
Chapter1. 공공 데이터를 통한 시장 동향 이해
미니 프로젝트 방식으로 진행
- 분석가는 도메인, 시장/트렌드, 경쟁사 등 넓은 관심사를 가져야 함
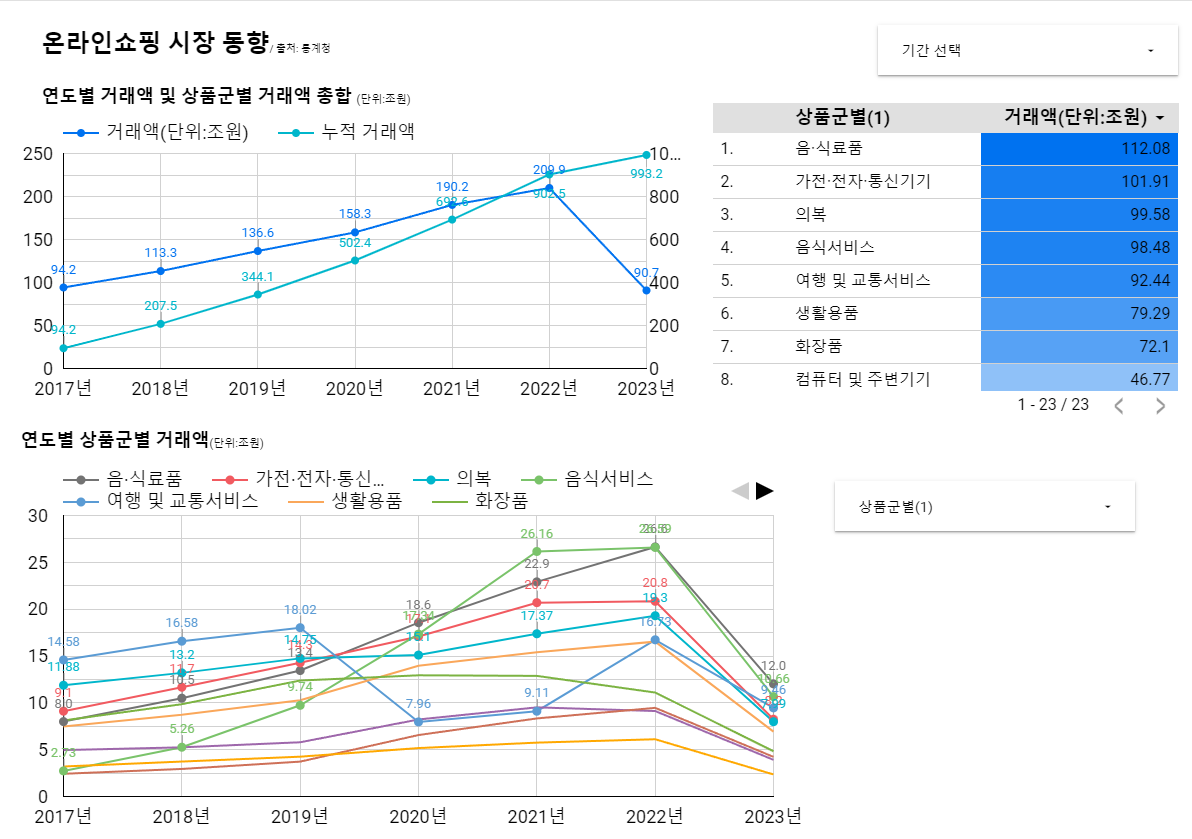
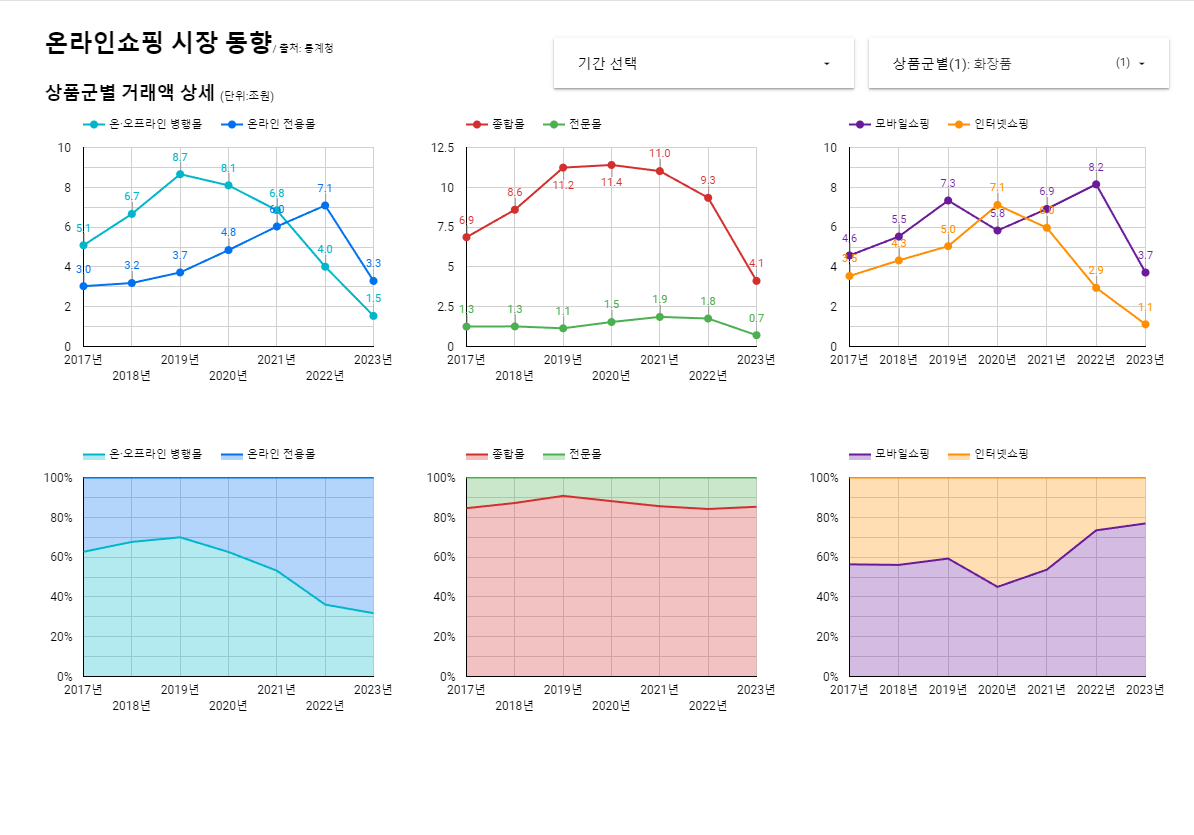
- 통계청은 온라인 쇼핑 동향 데이터 셋 사용
온라인 쇼핑 거래액 -> 판매매체(모바일/인터넷), 취급범위(종합몰/전문몰), 운영형태(온라인/온오프라인 복합) - 해당 데이터를 그대로 사용 불가 문제점은?
--> 이미 집계가 완료된 형태
--> 총합, 중간 집계값 존재
--> 가전, 전자, 통신기기 카테고리 세분화
--> 날짜 컬럼 양식 불일치
데이터 재구조화(전처리)
import pandas as pd
route1 = r'경로\파일이름.csv'
df = pd.read_csv(route1, encoding='cp949')
result = df.melt(id_vars = ['상품군별(1)', '상품군별(2)', '운영형태별(1)']
, var_name = '날짜'
, value_name = '거래액')
# 문자열 -> 정수
def strtoint(x):
if type(x) == str:
x = x.replace("-", "0")
x = int(x)
else:
pass
return x
result["거래액"] = result["거래액"].apply(strtoint)
result = result[result["상품군별(1)"] != "합계"]
result = result[result["운영형태별(1)"] != "계"]
result = result[result["상품군별(2)"] == "소계"]
result.drop("상품군별(2)", axis = 'columns', inplace = True)
result["날짜"] = result["날짜"].apply(lambda x: x.replace(" p)", ""))
result["날짜"] = result["날짜"].apply(lambda x: x.replace(".", "/"))
result.to_csv("preprocess.csv", encoding = "cp949", index = False)-
처리해야 할 파일이 많은 경우
-> python에서 파일 불러오기 -> 파일 처리하기 -> 저장하기
-파일을 차례로 불러와서, 원하는 방식으로 재구조화 하고, 목적지(dst)에 저장 -
import os 활용
import os
os.getcwd()
os.listdir(r'.경로/파일이름.csv')
os.mkdir(r'.처리완료 데이터 주소/data_result')
src = r'.기존 데이터 주소'
dst = r'.처리완료 데이터 저장 주소'
file_ls = os.listdir(r'기존 데이터 주소')
os.path.join(src, file_ls[0])
for f in file_ls:
print(f'{f}를 처리하고 있습니다')
df = pd.read_csv(os.path.join(src, f), encoding = 'cp949')
result = df.melt(id_vars = df.columns[:3]
, var_name = '날짜'
, value_name = '거래액')
result["거래액"] = result["거래액"].apply(strtoint)
result = result[result[result.columns[0]] != "합계"]
result = result[result[result.columns[2]] != "계"]
result = result[result[result.columns[1]] == "소계"]
result.drop("상품군별(2)", axis = 'columns', inplace = True)
result["날짜"] = result["날짜"].apply(lambda x: x.replace(" p)", ""))
result["날짜"] = result["날짜"].apply(lambda x: x.replace(".", "/"))
result.to_csv(os.path.join(dst, f), encoding = 'cp949', index = False)
print(f'{f} 완료')
Tableau
-
시트로 각각의 그래프를 만들고 대시보드에 쌓는 방식
-
대시보드에 꽉 차게 배치 됨 (바둑판형)
-
응용할 시각화 방법이 많음
-
DATEPARSE('날짜형식', '바꿀 문자열')
ex) 2000-01-01: yyyy-MM-dd
2000.01.01: yyyy.MM.dd
000101: yyMMdd
Jan.00: MMM.yy
Looker Studio
- 페이지에 바로 표를 만듬
- 배치가 자유로움
- 시각화 형태가 준비되어 있음
- PARSE_DATE('날짜 형식', '바꿀 문자열')
-> 날짜 형식
ex) Dec 5 2008: %b %e %Y
2008.12.05: %Y.%m.%d
05/12/08: %d/%m/%y
Jan.00: %b.%y
이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다
