본 포스트에서 리뷰할 논문의 제목은 Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection 입니다.
한국어로 표현하기 모호한 부분은 논문에서 쓰인 표현으로 작성되었으니 양해바랍니다.
2020년 당시 Object Detection Task에서 SOTA를 달성한 모델입니다. 최근에는 Swin Transformer 논문에서 Swin Transformer의 우수성을 검증하는 과정에서 사용되기도 했습니다.
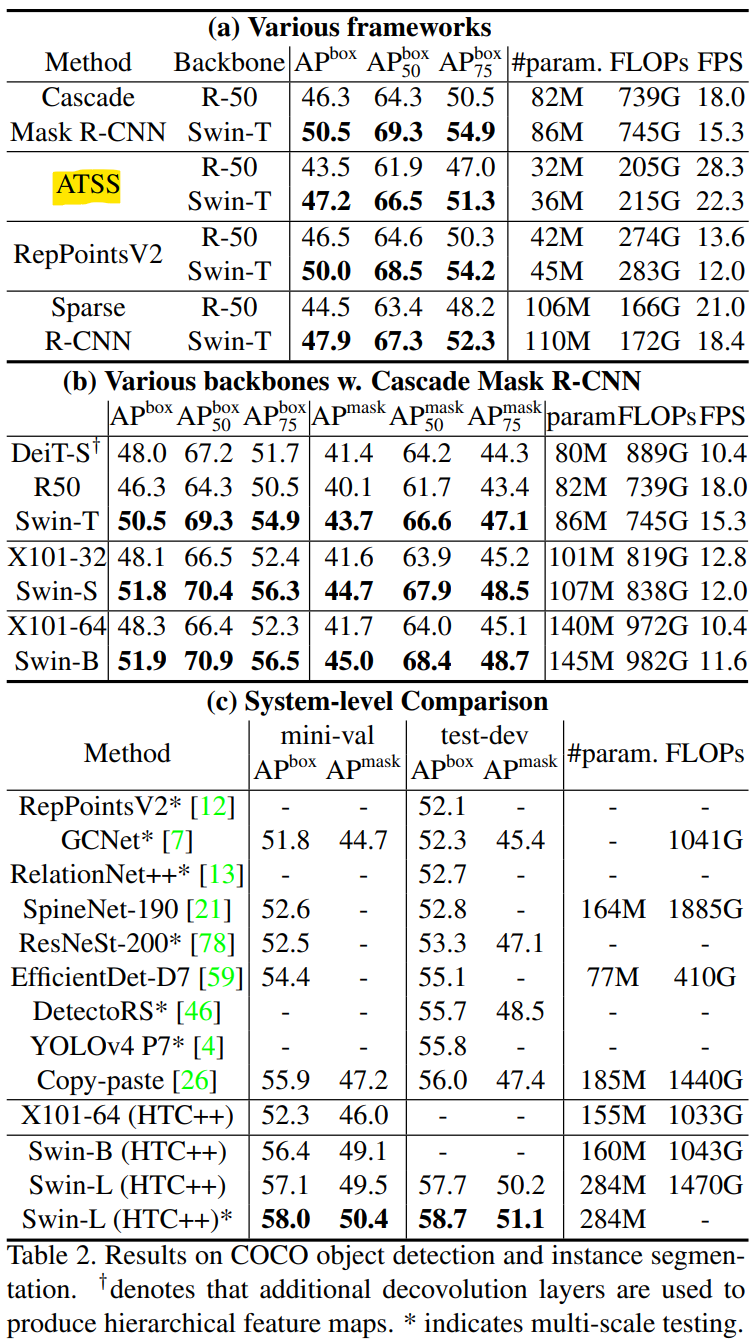
이 논문(이하 ATSS)에서는 anchor-based object detector와 anchor-free object detector 간의 essential difference는 positive sample 과 negative sample을 나누는 기준이라고 주장합니다. 여기서, positive sample이란 추론 과정에서 해당 sample이 foreground 로 예측되길 바라는 대상이며, negative sample은 background로 예측되길 바라는 대상입니다.
즉, 이 논문은 label assignment와 관련된 논문이고, 제안하는 label assignment 방법을 이용하여 대표적인 anchor-free object detector 중 하나인 FCOS 를 학습시켜 SOTA를 달성하였습니다. 이 당시만해도 anchor-free 방법이 anchor-based 방법에 비해 성능이 낮은 것이 조금 당연하게 여겨졌기 때문에, 무엇이 이러한 차이를 만드는지에 관한 관심을 가질 수 밖에 없었을 거 같습니다.
그렇다면, 어떻게 저자는 anchor-based object detector와 anchor-free object detector 간의 essential difference가 positive sample 과 negative sample을 나누는 기준이라고 생각했을까요?
먼저, 이를 실험적으로 증명하려했습니다.
Inconsistency Removal
먼저 저자는 anchor-based object detector에 속하는 RetinaNet과 anchor-free object detector에 속하는 FCOS를 택하고, anchor-based object detector와 anchor-free object detector간의 좁힐 수 있는 차이를 최대한 좁힐 수 있도록 RetinaNet을 재설계하였습니다.
수정된 내용은 다음과 같습니다. 첫째로 FPN(Feature pyramid Networks)의 각 Level별 레이어에 할당되는 앵커 박스 수를 1로 낮추었습니다. 이때, anchor box의 사이즈는 앵커박스가 할당되는 레이어의 인풋 피쳐맵의 stride된 정도 S 에 8을 곱한 사이즈로 설정하였습니다. 이는 저자분께서 공유해주신 official implementation의 모델 config 파일에서도 확인할 수 있었습니다.
이렇게 수정하였을때 RetinaNet의 AP는 32.5(on COCO) 를 기록했습니다. FCOS와 비교해보면 꽤 낮은 수치입니다. 여기에 RetinaNet에는 적용되지 않았지만, FCOS에서는 사용된 갖가지 기법을 하나씩 추가하였습니다. GroupNorm, GIoU Loss, In GT Box(GT Box안 쪽에 속하는 sample들만 positive sample candidate로 보는 것), Centerness(IoU를 예측하는 몇몇 모델처럼 foreground를 검출할때 foreground라고 예측한 지점이 실제 ground truth 박스 기준으로 얼마나 center에 가깝냐를 예측하는 기법, FCOS 논문에서 나옵니다.), Scalar는 객체의 크기를 예측할때 learnable한 scalar 값을 이용하는 기법(이것도 FCOS 논문에서 나옵니다).
이렇게 갖가지 기법을 level 별 anchor size를 1로 설정한 RetinaNet에 적용시켰을때, 성능이 크게 향상되는 것을 저자는 확인했습니다.
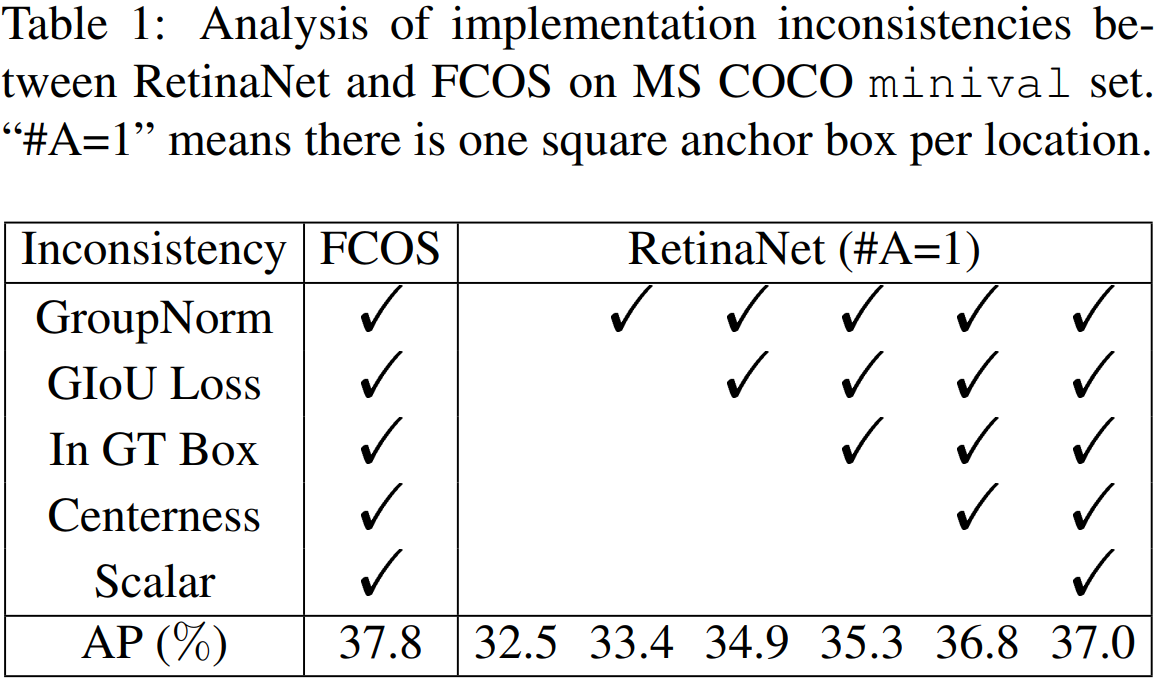
실험 결과를 보면 anchor-based object detector의 성능의 요인이 anchor의 개수가 아닐 수 있음을 확인할 수 있습니다.
Essential Difference
이제 anchor-based object detector와 anchor-free object detector 사이에는 두 가지 차이점이 존재합니다.
첫째는 positive sample과 negative sample 나누는 기준입니다.
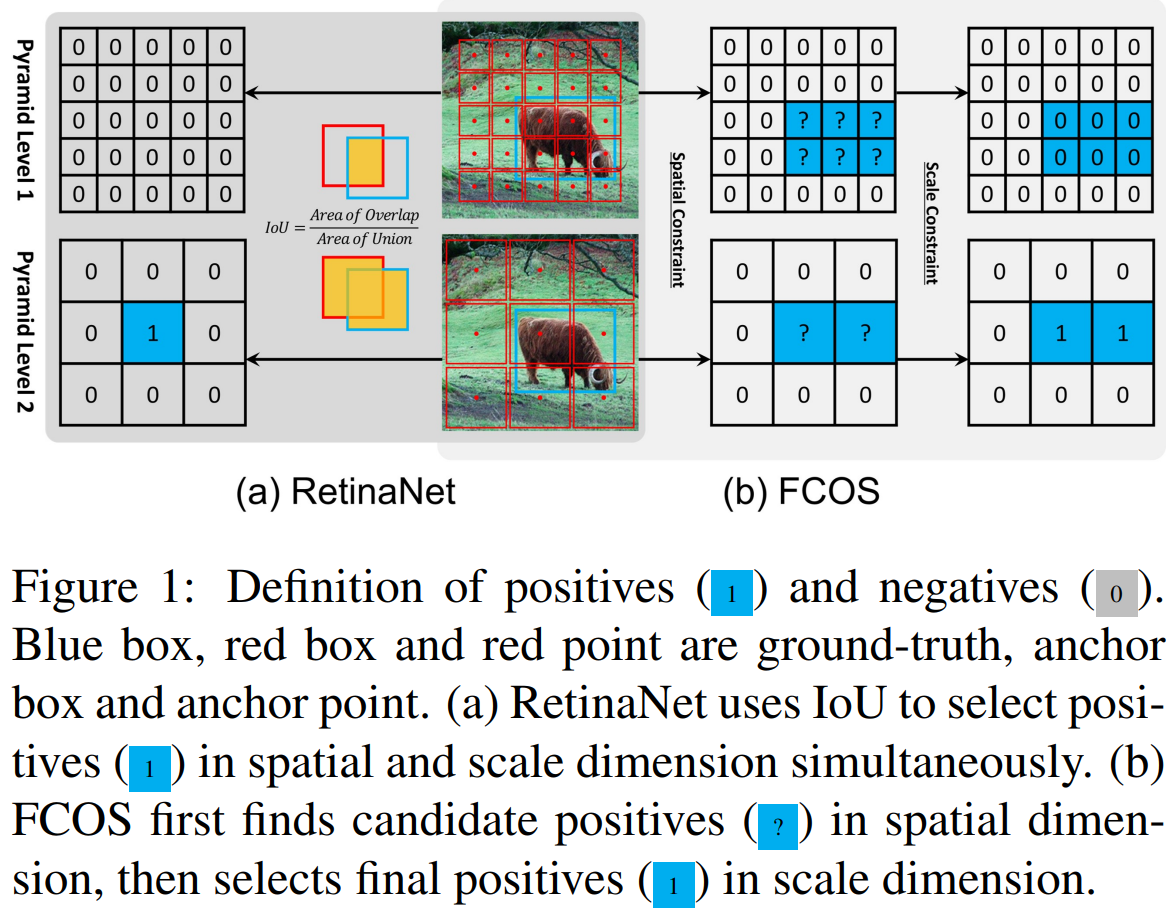
anchor-based object detector는 anchor box와 GT Box간에 IoU에 따라 positive/negative가 결정됩니다. 반면에, anchor-free object detector는 먼저 Spatial Constraint(sample 이 GT Box 안에 있냐)를 확인하고 Scale Constraint(해당 샘플이 GT Box의 Scale을 예측하는 샘플이 맞냐)에 의하여 결정됩니다. 어쨌든 두 방법 모두 Spatial, Scale 정보를 이용하지만 완전히 일치하는 방법은 아님을 알 수 있습니다.
두번째는 사이즈를 예측하는 regression 방식입니다.
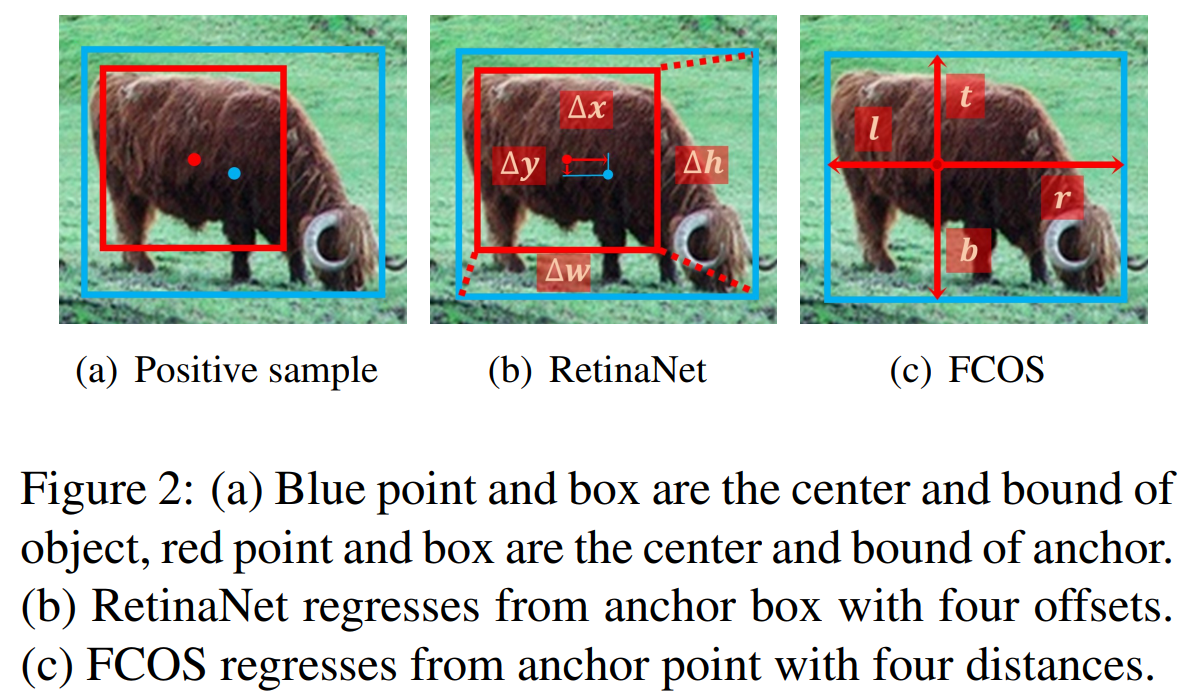
anchor-based object detector는 anchor box의 위치를 세밀히 조정하기 위한 offset을 예측하고, anchor box의 너비와 높이를 베이스로 Ground Truth 박스의 사이즈를 예측합니다. 반면에, anchor-free object detector는 현재 위치로 부터 Ground Truth 박스의 Boundary 까지의 거리를 예측하는 방법으로 객체의 사이즈를 예측합니다.
저자는 이 두개의 차이또한 제거해보는 실험을 진행하였습니다.

Classification 은 label assignment방법을 의미합니다. IoU는 anchor-based object detector에서 쓰인 assignment 방법을 의미하고 Spatial and Scale Constraint는 anchor-free object detector에서 쓰인 label assignment 방법을 의미합니다. Regression의 Box는 anchor box이고 Point는 Boundary 까지의 거리를 예측하는 anchor-free object detector의 regression 방법을 의미합니다.
Table 2를 보면 Regression 방법보다 label assignment 방법(Intersection over Union vs Spatial and Scale Constraint)이 다를때 detector간의 성능이 크게 차이남을 알 수 있습니다.
지금까지 진행한 실험결과를 보면 anchor-based object detector와 anchor-free object detector간의 성능차이는 label assignment 방법에 의해 발생하는 것으로 추측해볼 수 있다.
Adaptive Training Sample Selection
위 실험결과를 통해 label assignment 방법이 object detector의 성능을 결정하는 요인 중 하나라는 것이 확인되었습니다. 그럼 이제 해야할 건 더 좋은 label assignment 방법을 개발하는 것입니다. 저자는 아래와 같은 label assignment 방법 ATSS(Adaptive training sample selection)을 제안합니다.

먼저 feature pyramid의 각 level별로 GT Box로 부터 가장 가까운 sample k개를 선택합니다. 그리고 선택된 모든 sample과 GT Box간의 IoU를 측정합니다. 그리고, 모든 sample과 GT Box간의 IoUs의 평균과 표준편차를 계산합니다. 마지막으로, 평균(IoUs) + 표준편차(IoUs) 이상의 IoU를 가지며 GT Box 안에 존재하는 sample들을 positive로 그 외는 모두 negative로 판단합니다.
즉, IoU 가 어느정도 높은 sample이 이 GT를 잘 예측하고 있는 sample이니 positive sample로 간주하겠다는 아주 직관적인 방법인데 "어느정도 높은"을 adaptive하게 계산해내는 방법을 제안하였습니다. 여기서, IoU 가 정규분포를 따른다고 조심스럽게 가정해보면,
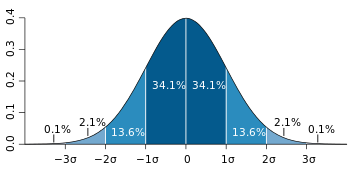
https://ko.wikipedia.org/wiki/68-95-99.7_%EA%B7%9C%EC%B9%99
평균(IoUs) + 표준편차(IoUs) 이상의 IoU를 갖는 sample은 뽑힌 sample들 중에서 약 상위 16%에 속하는 sample들을 high-quality sample로 보고, positive sample로 판단하는 것으로 이해할 수 있습니다.
위 알고리즘에서 유일한 하이퍼파라미터는 k이고, threshold값이 하나 있지만 이값도 adaptive하게 계산됨을 알 수 있습니다. 그리고 뒤이어 나올 실험 결과를 보면 k에 값에 의한 성능변화가 크지 않는데 이러한 결과로 저자는 제안하는 label assignment 방법이 almost hyperparameter-free하다고 주장합니다.
위 label assignment 방법을 갖고 anchor-based object detector와 anchor-free object detector를 학습시켰을때 결과는 아래와 같습니다. 모두 기존의 label assignment 방법을 통해 학습되었을때 보다, 높은 성능을 기록함을 확인할 수 있습니다.
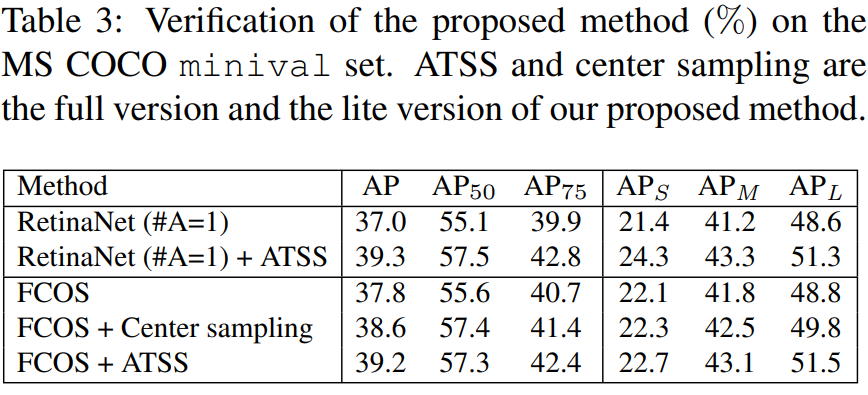
Analysis

유일한 하이퍼라미터 k에 따른 결과입니다. k가 3일때는 positive sample의 수가 충분치 않아 성능이 drop된 것으로 짐작할 수 있고, k가 19일때부터는 positive sample의 수가 너무 많아지고 이에따라 low-quality sample들이 positive sample로 학습됨으로써 성능이 감소된 것으로 짐작할 수 있습니다.
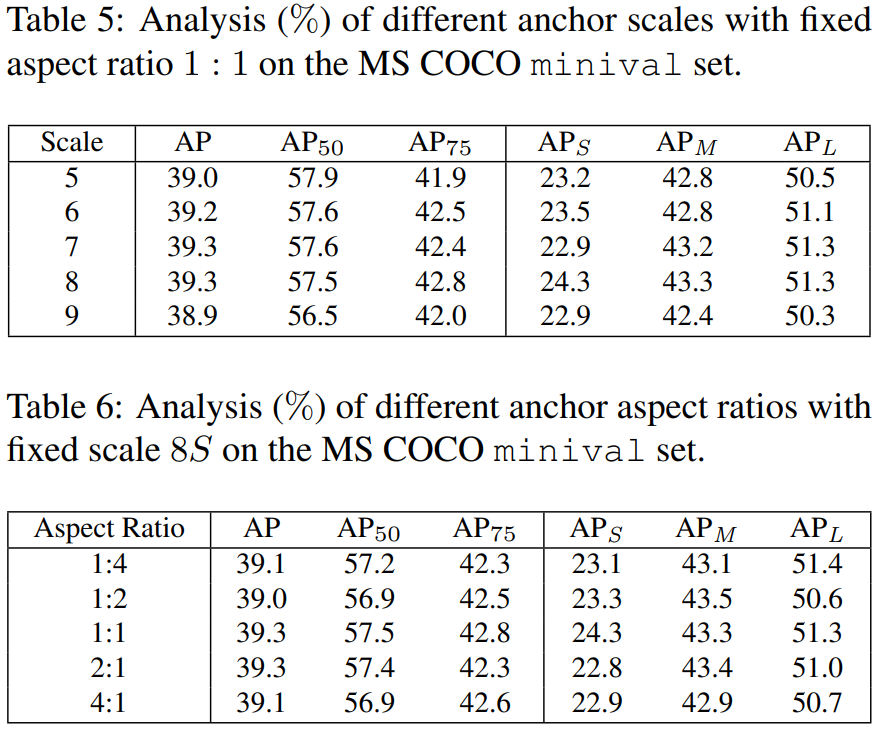
Table 5. 은 anchor scale을 8S가 아닌 5S, 6S, ... 9S로 설정하였을때의 결과이고, Table 6. 은 anchor의 aspect ratio를 달리 설정하였을때의 결과이다. 큰 차이가 없는 것을 확인할 수 있습니다.
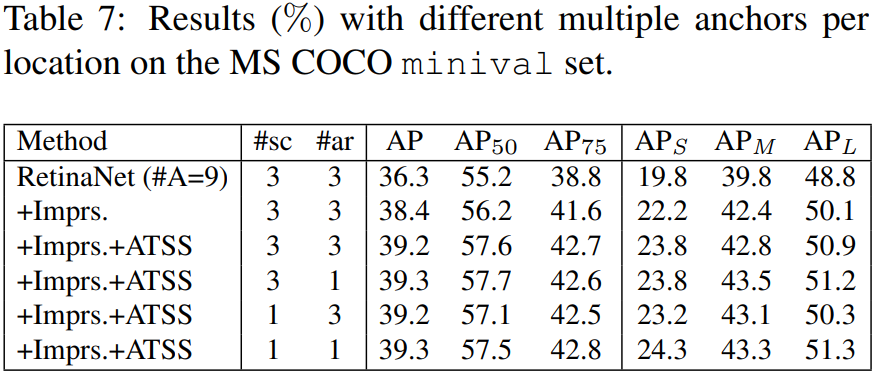
Table 7은 Original RetinaNet에 FCOS에서 Improvement를 보인 여러 방법들(=Imprs)을 RetinaNet에 적용하고 ATSS를 이용해 학습시켰을때의 결과입니다. anchor의 개수(#sc x #ar)가 1일때와 9일때 큰 차이가 없는 것을 확인할 수 있습니다. 이러한 결과를 보고 저자는 anchor-based object detector에서 한 location에 여러개의 sample을 예측하는 것은 useless 하다고 주장합니다.
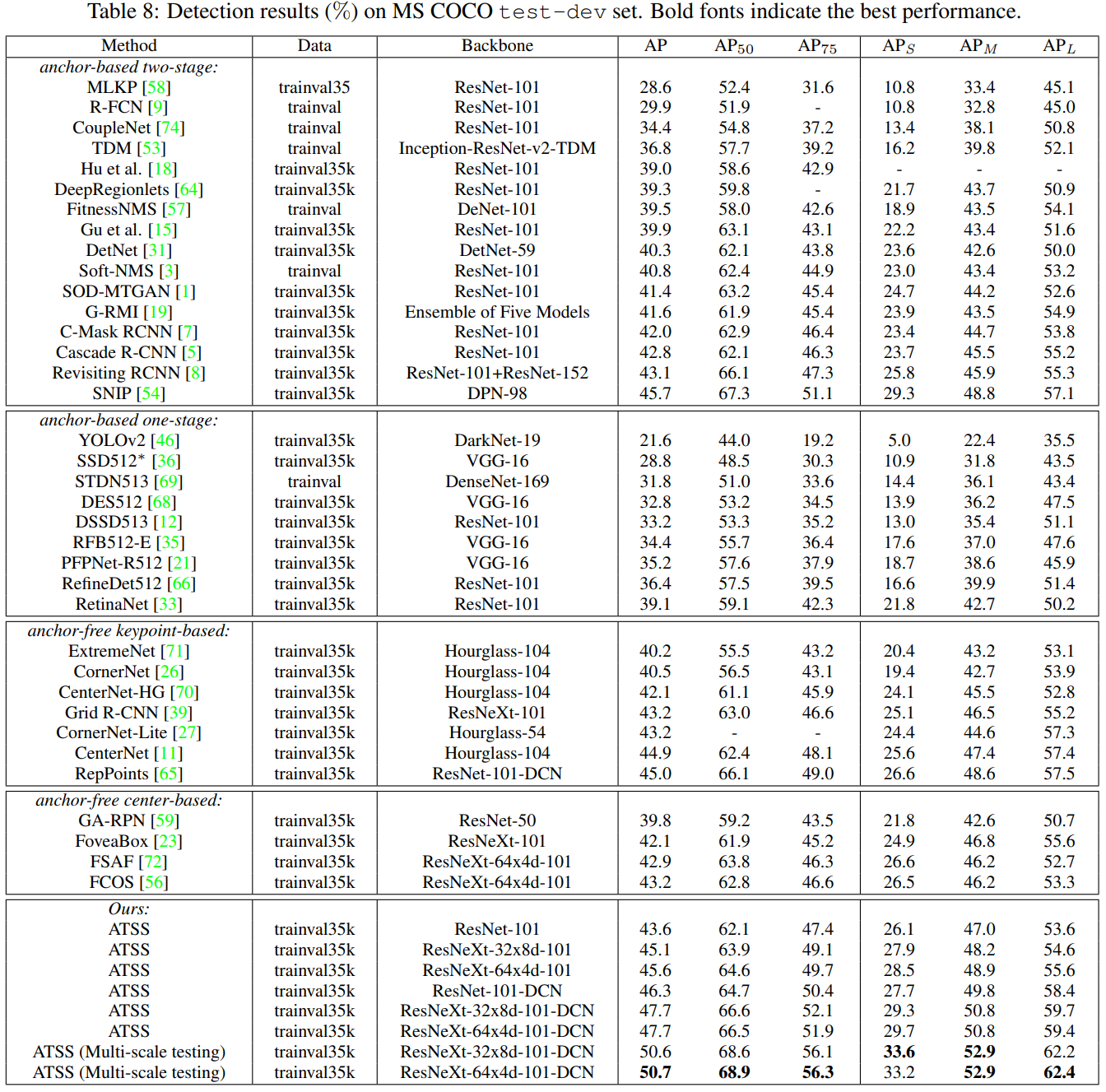
마지막으로 성능 좋은 Backbone과 Test time augmentation을 이용하여 SOTA의 성능을 달성함을 보입니다. 개인적으로 ATSS + ResNet-101 과 ATSS + ResNet-101-DCN(Deformable Convolution) 의 성능차가 참 인상적입니다.
MARKANY_둘러보기
