
For my third month at WeCode Bootcamp, I got the opportunity to intern at Brandi, one of Korea's fastest growing women's fashion e-commerce websites. Interning at Brandi for a month felt like I was being thrown into the fire headfirst--everything about it was new, from learning flask for the first time to using raw SQL queries to using the data access object (DAO) pattern for data retrieval. The first two weeks were especially rough, since I was learning everything from scratch in a "trial by fire" manner.

As hard as it was learning and using a bunch of new tools and skills for the first time, I'm extremely grateful that I was able to complete a month-long project using an entirely different technical stack. I was able to learn and improve as a developer proportionate to how hard and challenging the internship was.

🙌 Team:

김채현
장성준
이지윤
송빈호
김하성 (me!)
🛠 Tools Used:
- python
- flask
- AQueryTool
- MySQL (MySQL workbench)
- PyMySQL
- git/github
- AWS
- S3
- Postman (API endpoint testing and API documentation)
Project Overview
Our month-long assignment was to clone Brandi's service website (https://www.brandi.co.kr/) and Brandi's admin website (https://sadmin.brandi.co.kr/login). Brandi's service website (used by consumers) is more or less a typical ecommerce website where users can browse through products, add items to their cart, and purchase items.
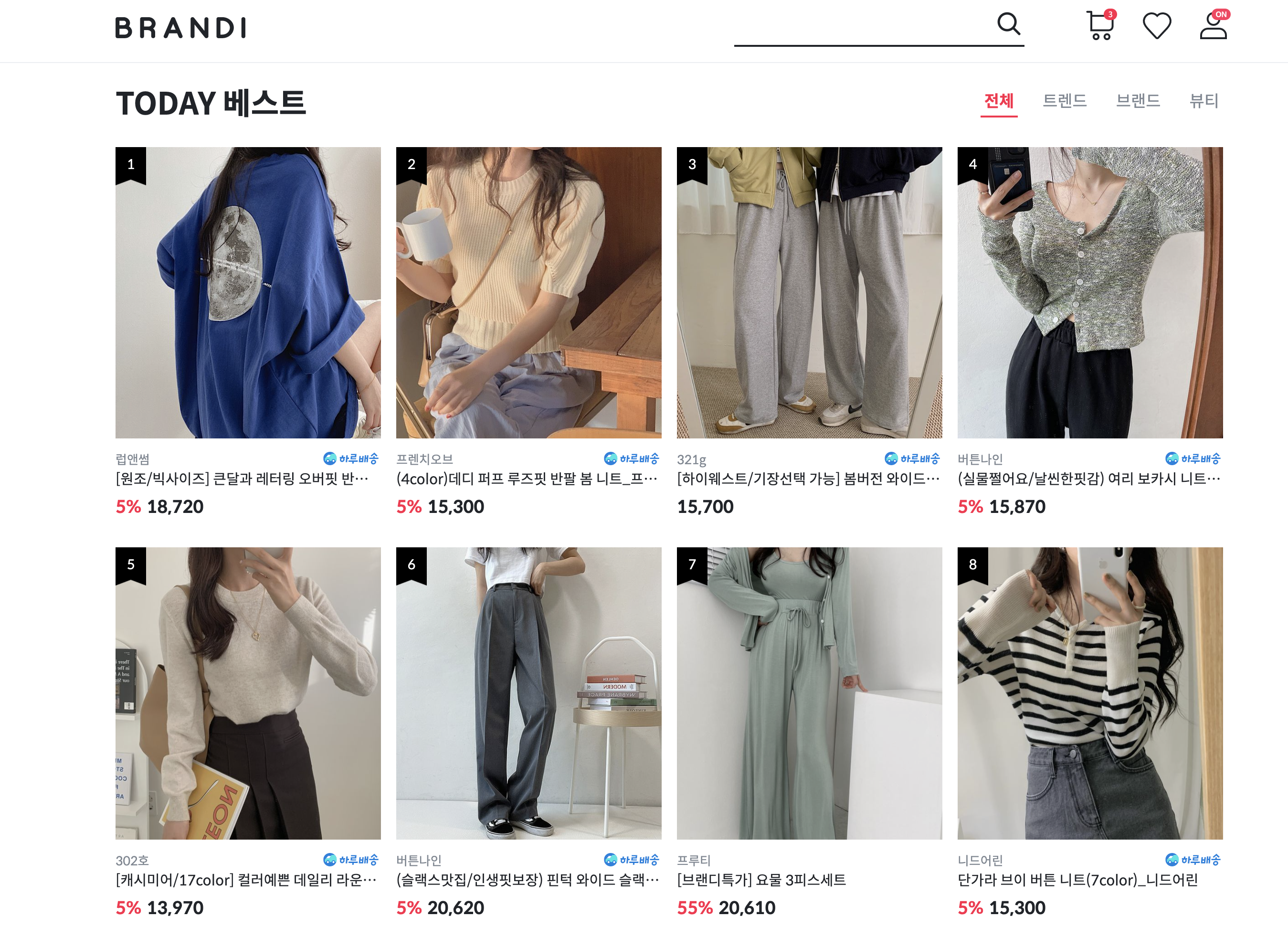
Brandi's admin website is used by sellers and "master" users. Sellers are different brands and companies that register and post fashion items to sell using the admin website, while "master" users are Brandi admin staff members who manage sellers, products, shipping orders, etc.
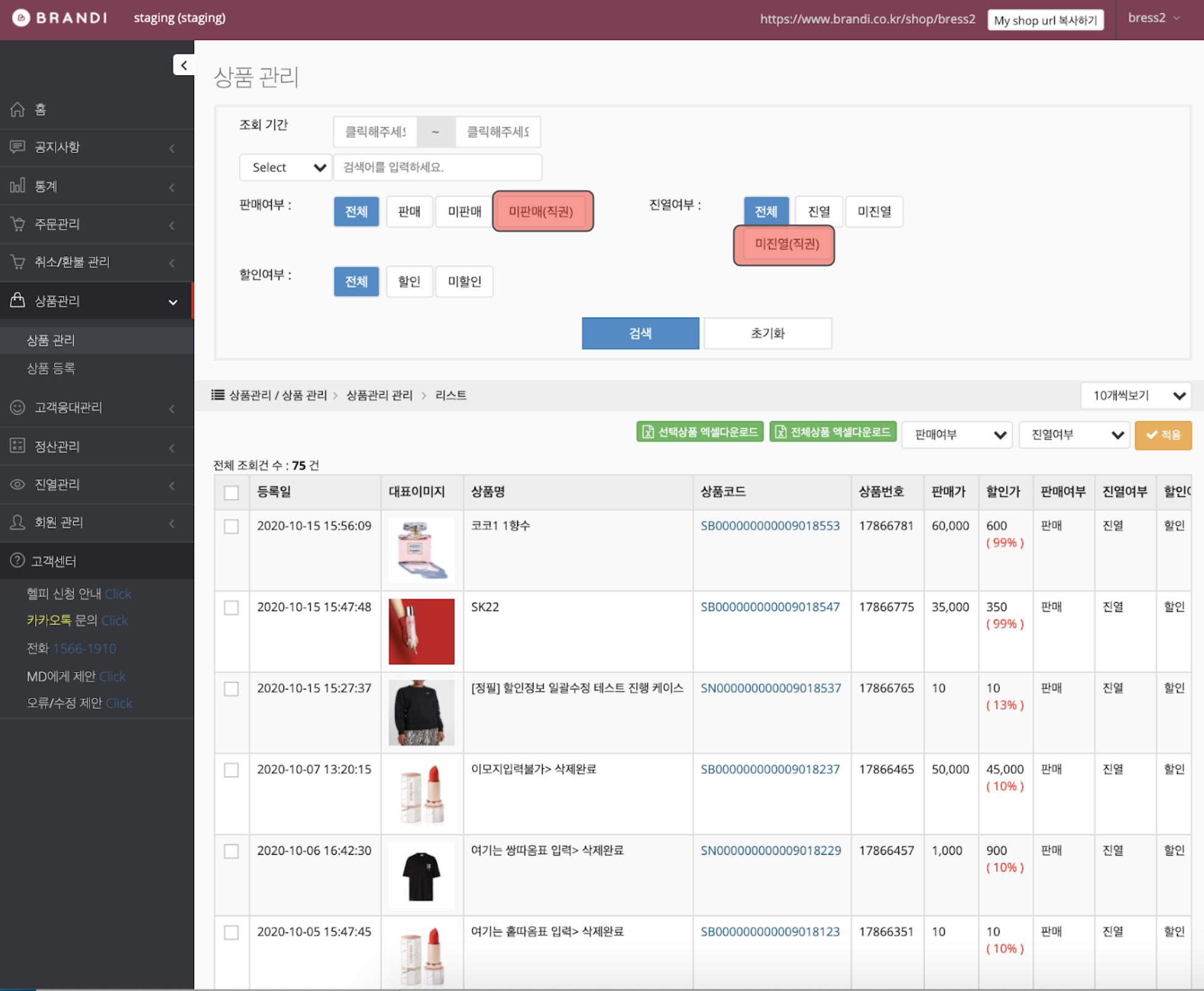
Compared to past groups that interned at Brandi, our group was a bit of of an anomaly. Intern groups typically consisted of both frontend and backend developers, but our team consisted only of backend developers. Hence, for the frontend portion of the two websites, we used past interns' work and focused instead on developing the backend side of the websites. One of our group members also had some prior frontend experience, so he operated as a fullstack member who handled some of the frontend API. Our project manager, a senior developer at Brandi, also helped out by writing some frontend API endpoints for us.
Project Workflow (SCRUM)
- weekly SPRINT meetings
- daily standup meetings
- Trello for keeping track of work being done (backlog, this week, doing, and done)
- Slack for open communication with team
- Notion for organizing meeting notes and keeping track of assignments
Software Architecture (Multi-Tier/Layered)
For this project, we chose to use a multi-tier/layered architecture pattern. Using a layered architecture pattern has the benefits of code readability and service expansion potential, since each layer is independent and has a distinct role. It's therefore easy to add or modify code in one layer without affecting code in other layers.
Presentation Layer (View)
For our backend API, the presentation layer contains the API endpoints. We labeled the presentation layer as View, since it contains code that accepts requests from the client (top-most layer of software).
Business Layer (Service/Controller)
We labeled the business layer as Service. This layer contains all of the business logic. For example, if a user enters a password that is less than 8 characters, then the business layer contains the logic that tells the user that the password must be at least 8 characters long.
Persistence Layer (Model/DAO)
We labeled the persistence layer as Model. This layer serves as a data access object (DAO) that is used to access the database. When prompted by the business layer, the persistence layer creates, updates, reads, and deletes information from the database.
Data Modelling


Modelling Brandi's service and admin sites was a challenge in itself. We modelled the service and admin sites together, since the two sites are directly related (sellers post products, manage orders, and signup on the admin site, and service users purchase items that sellers post through Brandi's service site). Since there are multiple types of users, we created a separate user_info table with another user_types table to identify the three types of users: service user, seller, and master.
One of the most important things I learned while modelling Brandi's service and admin sites was the concept of keeping records for effective database management. Moreover, all of these records serve as useful data for future data analysis, which could ultimately provide invaluable insight on consumer behavior, preferences, habits, etc. For ecommerce sites in particular, almost every minor change must be recorded so that the business can keep track of changes and who made the changes. For example, if a service user changes their account information multiple times (i.e. their username and password) and later requests access to their previous usernames and passwords to log on to the website, the business should have a log of the user's prior usernames and passwords as well as change_dates for each time the user changed his/her account information. For record-keeping purposes, we created log tables (i.e. order_logs, product_logs, qna_logs) for almost every table in our database.
Another interesting thing I learned regarding record-keeping was the different ways of keeping records. You can keep records using an effective date (change_date) or separate start and end dates. We chose to use effective dates, since this makes it easier from a developer's perspective to update information stored in the database, since you only have to update the effective change_date every time a change is made. In contrast, if you use start and end dates, you have to update both the start and end dates of when the change was made. If there's even one error or typo in the start/end dates, then it's impossible to know when the exact change was made. Although retrieving records from the databse using effective dates is arguably harder than it is using start/end dates, since you have to query through all of the effective dates until you reach the desired change_date (using SQL's MAX function), we went with effective dates for the purposes of development speed and efficiency.
What I Contributed:
- User login/signup (service users and sellers), login decorator: from Brandi's service and admin websites, both service users and sellers can signup and login
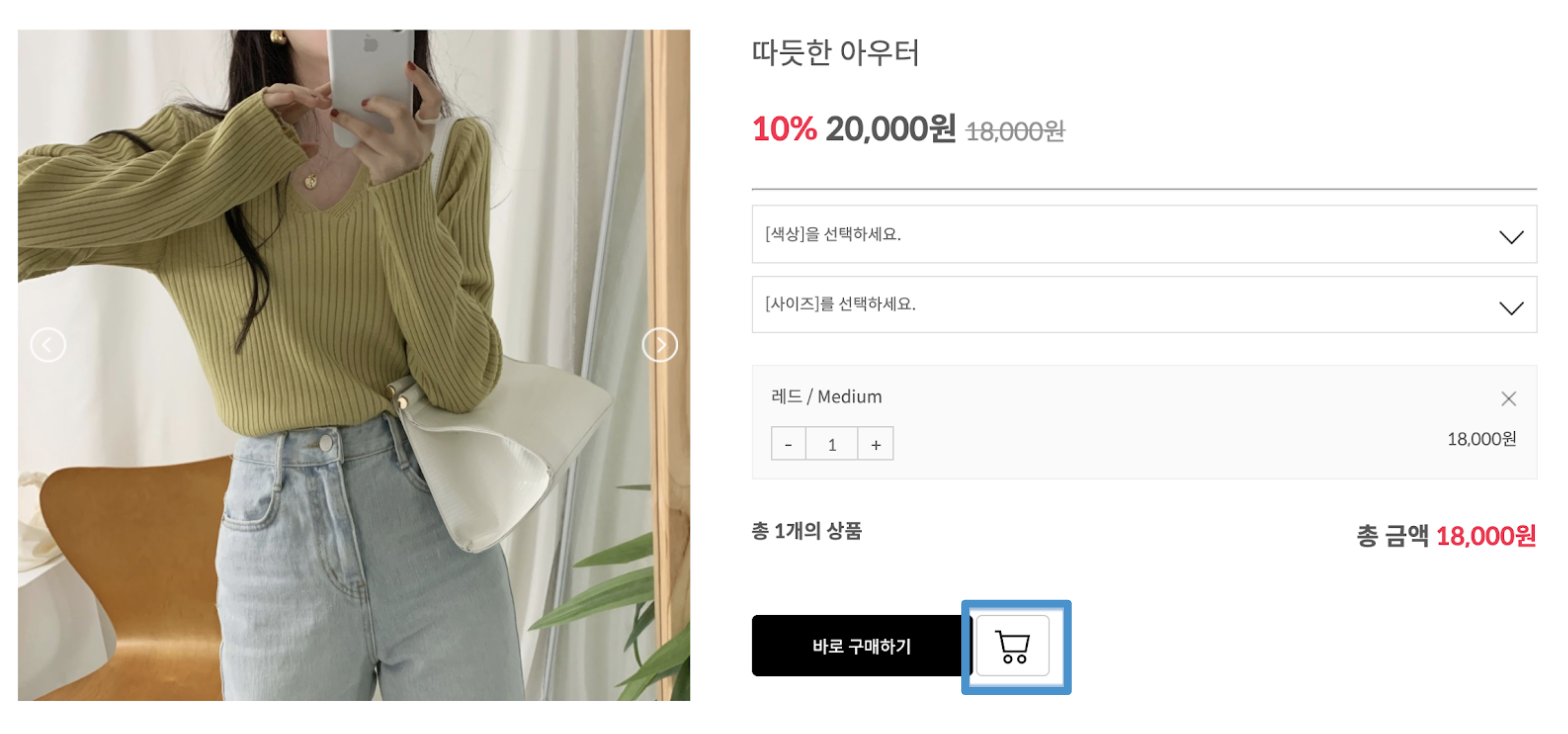
- Cart (GET, POST, DELETE): from Brandi's service website, users can add and delete items
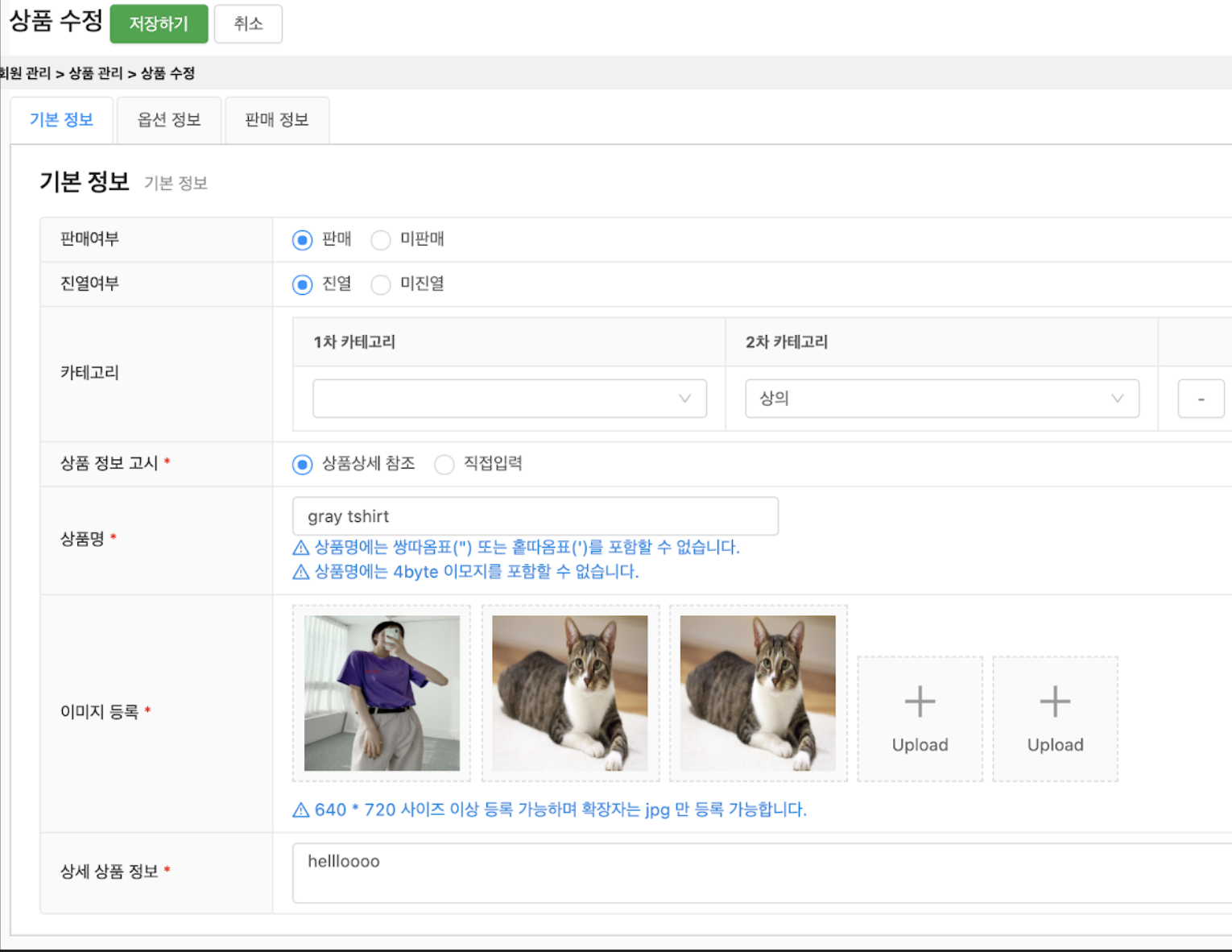
- Seller register product (GET, POST): from Brandi's admin website, sellers can register new products
- Seller edit product (GET, PATCH): from Brandi's admin website, sellers can edit product information
Key Takeaways:
- Compared to using Django's ORMs, I found that using raw SQL queries was easier and more intuitive to retrieve database objects. For simple tasks, Django's ORMs are much faster at accessing database objects, but raw SQL queries are better for more complex tasks.
- Flask and Django are two completely different frameworks! Learning Flask for the first time made me realize the benefits of using Django. Django acts as the controller and comes with built-in features that do a lot of the work for you. Flask is almost like an empty workbench--you have much more control over what libraries/tools you want to use, but you're also responsible for doing the dirty work and incorporating these libraries/tools into your service. I think there are pros and cons to using both frameworks. Personally, I think I learned more about web development using Flask, since I was forced to really learn what each component/feature is responsible for.
- Use PyCharm!! I don't know why I was using VIM for my past two projects. PyCharm's built-in debugger is so helpful in catching errors while you're writing code.
