
list->str
join(): 리스트 인자를 전달해 문자열 사이사이 삽입
str1=['a', 'b', 'c']
str1='#'.join(str1) # iterable이 와야함
print(str1)
# === 출력 === #
a#b#cstr1="/clean-img-arch-64-build/14169"
print('_'.join(str1.split('/')[-2:]))
# === 출력 ==== #
clean-img-arch-64-build_14169
string=''.join(<list>)
- list를 string으로 바꿔보자!
str( <list> )하면 되지 않나?


list표현 그대로 출력된다.
''.join(<list>)로 변환하면된다!
str method
len: 길이
line="hello"
print(len(line)) # 5 (idx는 0~4)multi line
str1= \
'''
string1
string2
'''
=== 출력 ===
string1
string2upper(): 대문자로 변경
name = name.upper()lower(): 소문자로 변경
name = name.lower()str.startswith(str | tuple) : 문자열 시작 검사
str.startswith(찾을 문자열 | tuple[][, start[, end]]) -> bool
str1="hello myname is mark"
print(str1.startswith("hello")) # True
str2="hellomyname is mark"
print(str2.startswith("hello")) # True
str3="hellomyname is mark"
print(str3.startswith("myname")) # False
search_tuple=("world", "hello")
print(str1.startswith(search_tuple)) # True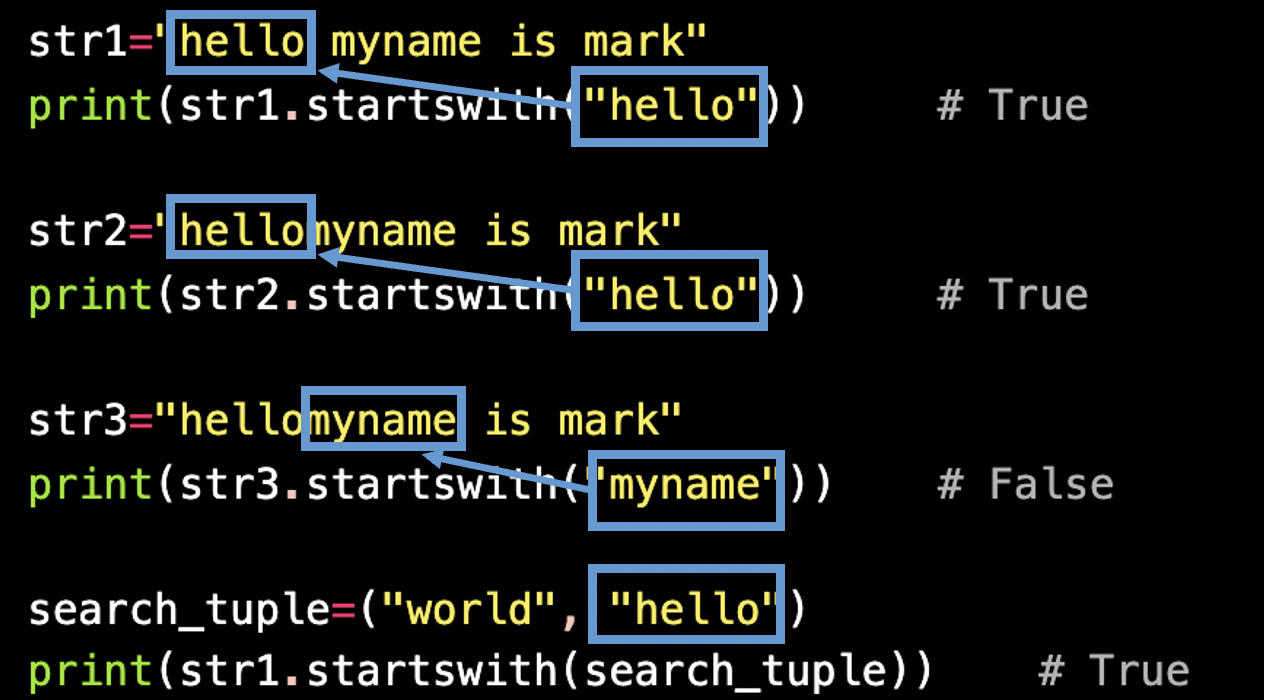
endswith(): 특정 단어로 끝나는지 확인
str1="abc"
print(str1.endswith('c'))
=== 출력 ===
Trueswapcase(): 대<->소문자 변경
capitalize(): 첫 문자만 대문자로
str1 = "aBc".capitalize()
print(str1)
=== 출력 ===
Abctitle(): 각 단어 첫문자만 대문자로
str1 = "aBc dEFG".title()
print(str1)
=== 출력 ===
Abc Defgstrip(): 지정한 문자로 양 끝 자른다
str1 = " hello ".strip() # 디폴트 공백
str2 = "____hello____".strip('_') # '_' 양 끝에 자르기
print(str1)
print(str2)
=== 출력 ===
hello
hellolstrip(): 왼쪽 자름
rstrip(): 오른쪽 자름
replace(): 문자열 특정 부분 변경
str1 = "abc"
str1 = str1.replace('a', 'b') # replace(x, y) then, x to y
print(str1)
=== 출력 ===
bbcpartition(): token(전달 인자)
- tokenizer 역할(1번만 찾음)
- 앞에서 부터 찾음
- 출력에 구분자 포함
tuple형태 출력
str1 = "pllpokko@alumni.kaist.ac.kr"
str1 = str1.partition('.')
print(str1)
=== 출력 ===
('pllpokko@alumni', '.', 'kaist.ac.kr')rpartition(): 뒤에서 부터 문자열 나눔(전달 인자)
- 뒤에서 부터 tokenizer 역할(1번만 찾음)
- 뒤에서 부터 찾음
- 출력에 구분자 포함
tuple형태 출력
str1 = "123-456-789"
str1 = str1.rpartition('-')
print(str1)
=== 출력 ===
('123-456', '-', '789')split(): token + (구분자 포함 x)
- tokenizer 역할(계속 찾음)
- 구분자 포함 x
list형태 출력
str1 = "pllpokko@alumni.kaist.ac.kr"
str1 = str1.split('.')
print(str1)
=== 출력 ===
['pllpokko@alumni', 'kaist', 'ac', 'kr']split('=',1) : 횟수 지정
var, arg = line.split('=',1)'\n' 기준으로 나눔
cmd_output
print(cmd_output)
Package libpsl5 (0.21.0-r0) is installed on root and has the following files:
/home/dhyang/local_workspace/rootfs/usr/lib/libpsl.so.5
/home/dhyang/local_workspace/rootfs/usr/lib/libpsl.so.5.3.2split('\n')처리
print(cmd_output.split('\n'))
['Package libpsl5 (0.21.0-r0) is installed on root and has the following files:', '/home/dhyang/local_workspace/rootfs/usr/lib/libpsl.so.5', '/home/dhyang/local_workspace/rootfs/usr/lib/libpsl.so.5.3.2', '']strip().split('\n')처리
print(cmd_output.split('\n'))
['Package libpsl5 (0.21.0-r0) is installed on root and has the following files:', '/home/dhyang/local_workspace/rootfs/usr/lib/libpsl.so.5', '/home/dhyang/local_workspace/rootfs/usr/lib/libpsl.so.5.3.2']rsplit(): 뒤에서 부터 문자열 나눔(전달 인자) (구분자 포함 x)
- 뒤에서 부터 tokenizer 역할(계속 찾음)
- 구분자 포함 x
list형태 출력
str1 = "pllpokko@alumni.kaist.ac.kr"
str1 = str1.rsplit('.')
print(str1)
=== 출력 ===
['pllpokko@alumni', 'kaist', 'ac', 'kr']splitlines(): 라인 단위로 문자열 나눔
list형태 출력
str1 = \
'''
Life too short
you need python
'''
print(str1.splitlines())
=== 출력 ===
['','Life is too shrot', 'you need python']count(): 특정 단어(문자열) 수 구함
- 없으면 0 반환
str1=\
'''
HELLO
hello
'''
print(str1.count('hello'))
=== 출력 ===
1find(): 특정 단어를 찾아 idx 리턴
- 특정 단어를 찾아 idx를 리턴한다.
- 없으면 -1 리턴
str1='hello world!'
print(str1.find('w'))
=== 출력 ===
6
hello worl
----------
0123456789 배열식 idx 형태로 재서 리턴str1='hello world!'
print(str1.find('ld!'))
=== 출력 ===
9
hello world!
------------
0123456789 찾은 문자열의 제일 앞 idx 리턴rfind(): 뒤에서 부터 특정 단어 찾아 idx 리턴
str1='hello world!'
print(str1.find('ld!'))
=== 출력 ===
9
hello world!
------------
0123456789 찾은 문자열의 제일 앞 idx 리턴removeprefix('대상') : prefix 제거
str1 = "lib32-starwars"
str1 = str1.removeprefix('lib32-')
# str1에 'lib32-' prefix가 없더라도 넘어감
print(str1)
# ==== 출력 ==== #
starwarsis 메서드
isalnum(): 알파벳 || 숫자로 다채워짐 ?
print('x'.isalnum()) # True
print('3'.isalnum()) # True
print('3.14'.isalnum()) # False '.'<-- 때문에 '.'는 알파멧 아님
print('3x'.isalnum()) # Trueisalpha(): 알파벳?
isdecimal(): 숫자(decimal,10진수)인가?
isdigit(): 숫자(digit, 10진수) 인가?
print('10'.isdecimal()) # True
print('0'.isdecimal()) # True
print('10.4'.isdecimal()) # False
print('10'.isdigit()) # True
print('0'.isdigit()) # True
print('10.4'.isdigit()) # Falseisidentifier(): 식별자로 사용 가능한가?
islower(): 전부 소문자?
isnumeric(): 숫자?
isspace(): 공백 있는가?
istitle(): title 형식인가?
isupper(): 전부 대문자 인가?

pllpokko@alumni.kaist.ac.kr