
- 다음 글의 Pattern matching 이랑 헷갈리면 안됨!!
정규표현식
| 식 | 효과 | 예제 |
|---|---|---|
| . | 임의의 한 문자 있어야함 없는건 X |    grep "exercise.." -> 'exericse.sh' grep "exercise.." -> 'exericse.sh' |
| [ ] | 문자 클래스 | |
| [^ ] | 부정 문자 클래스 | |
| ^ | 문자열이나 행의 시작 | ^linux = linux로 시작하는 문자열 grep "^-" -> -rwxr--r-- 1 user user 69 3 22 23:24 file grep "^-" -> -rwxr--r-- 1 user user 69 3 22 23:24 file |
| $ | 문자열이나 행의 끝 | x$ = x로 끝나는 문자열 grep "x$" -> templet.pptx grep "x$" -> templet.pptx |
{n} | 앞 요소가 n개 반복 | te{2}n -> teen |
{n, m} | 앞 요소 n <= 앞요소 <= m | te{1,2}n -> ten, teen |
| ( ) | 하위 식. 정규식 안에 하위 패턴을 지정해 사용할 경우 | |
| \n | 일치하는 n번째 패턴 | |
\b | 단어와 공백 사이의 위치를 찾는다. | er\b -> naver, verb(x) |
\B | \b를 제외한 전부를 찾는다. | er\B -> verb, naver(x) |
\cx | x로된 제어 문자를 찾는다. | \cM: Control-M or 캐리지 리턴문자를 찾는다. |
\d | 숫자를 찾는다. | ==[0-9] |
\D | 숫자가 아닌 문자를 찾는다. | ==[^0-9] |
\f | 용지 공급 문자를 찾습니다. | == \xOc, \cL |
\n | 줄 바꿈 문자를 찾습니다. | == \xOa, \cJ |
\r | 캐리지 리턴 문자를 찾습니다. | == \xOd, \cM |
\s | 공백, 탭, 용지 공급 등을 비롯한 모든 공백 문자를 찾습니다. | == [\f\n\r\t\v] |
~\S | 공백이 아닌 문자를 찾습니다. | == [^\f\n\r\t\v] |
\t | 탭 문자를 찾습니다. | == \x09, \cL |
\v | 새로 탭 문자를 찾습니다. | == \x09, \cK |
\w | 밑줄을 비롯한 모든 문자를 찾습니다. | == [A-Za-z0-9_] |
\W | 비단어 문자를 찾습니다. | == [^A-Za-z0-9_] |
\xn | n을 찾는데, 여기서 n은 16진수 이스케이프 값입니다. (ASCII 코드가 정규식에 사용될 수 있습니다.) | \x41 -> A\x041 -> \x04 & 1 |
^[ \t]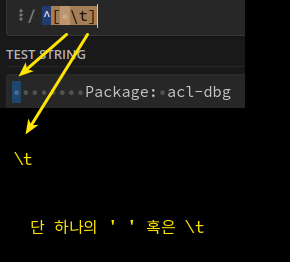
^[ \t]*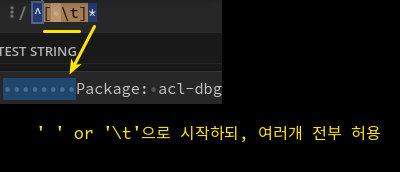
^[ \t]*(*)Error
- 아무 것도 매칭되지 않음
^[ \t]*(.*)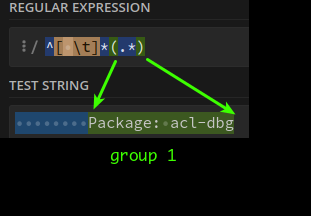
^[ \t]*(.*)#(.*)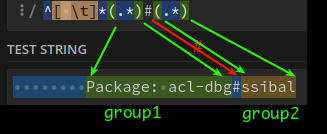
확장정규표현식
| 연산자 | 효과 | 예 |
|---|---|---|
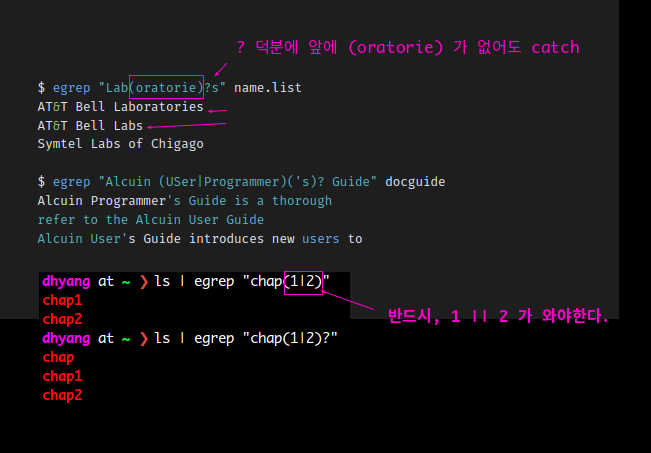
| ? | 바로 앞의 문자가 하나 있거나 없거나 | 'lo?ve' = o가 하나 있거나 없거나love, lve |
| + | +앞의 문자 중 하나 이상이 매칭 | '[a-z] + linux' = alinux, mylinux, sulinux ... |
| a|b | a 또는 b | 'love | hate' = love (or) hate가 포함되는 라인 |
grep
- 기본은 'Regex'만 사용가능하다. (BRE)
-E옵션: Extended Regex (ERE)-P옵션: Perl-compatible regular expression (PCRE)-F옵션: Regex를 사용하지 않고 문자를 그대로 매칭
$ grep [option] 'expression' <FILE>-E, -F 사용 예
1. sample.txt 내용
string (f|g)ile in the file,
\(f\|g\)ile in the file,$ grep '\(f\|g\)ile' sample.txt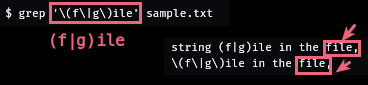
$ grep -E '(f|g)ile' sample.txt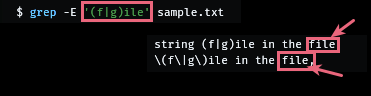
$ grep -F '(f|g)ile' sample.txt
$ grep -F '\(f\|g\)' sample.txt
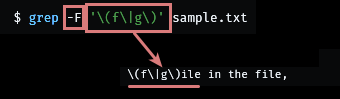
그냥 egrep을 주력으로 사용하자...
주요 옵션
\ : regex 와 겹치는 문자 찾을 때
.는 regex에서 아무 '한 문자'가 있는 것. 따라서,.자체를 매칭하기 위해서는\.로 사용해야함
$ ls | egrep '\.'
hello.sh
world.c-i : 대소문자 구분 X
$ ls | egrep -i 'W'
world.c
webos.h-v : 매칭 X (inverse)
$ ls | egrep -v 'w'
hello.c-n : line number
- 찾을 대상 파일 내용
# ===== simple_script.sh ===== #
#!/bin/bash
ARR=(DST1 DST2 DST3)
echo $ARR[2]
echo ${ARR[2]}
- egrep 으로 검색
$ egrep -n 'echo' ./simple_script.sh
-r : 특정 디렉토리 이하 모든 파일 대상 매칭
- egrep -n 'echo' ./simple_script.sh
$ egrep -n 'echo' ./simple_script.sh- egrep -nr 'echo' ./workspace
$ egrep -nr 'echo' ./workspace ./workspace 이하 수많은 'echo'들이 egrep 된다.
./workspace 이하 수많은 'echo'들이 egrep 된다.
-H : 파일 이름 보여줌
egrep ./ -nrH "FILE(_|S)?"
egrep ./ -nrHi "FILE(_|S)?"
egrep ./ -nrHv "FILE(_|S)?"
.file : hidden file
ls -al | awk '{print($NF)}' | egrep '^\.'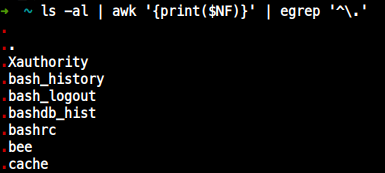
기타 옵션과 참고사이트
grep [OPTION...] PATTERN [FILE...]
-E : PATTERN을 확장 정규 표현식(Extended RegEx)으로 해석.
-F : PATTERN을 정규 표현식(RegEx)이 아닌 일반 문자열로 해석.
-G : PATTERN을 기본 정규 표현식(Basic RegEx)으로 해석.
-P : PATTERN을 Perl 정규 표현식(Perl RegEx)으로 해석.
-e : 매칭을 위한 PATTERN 전달.
-f : 파일에 기록된 내용을 PATTERN으로 사용.
-i : 대/소문자 무시.
-v : 매칭되는 PATTERN이 존재하지 않는 라인 선택.
-w : 단어(word) 단위로 매칭.
-x : 라인(line) 단위로 매칭.
-z : 라인을 newline(\n)이 아닌 NULL(\0)로 구분.
-m : 최대 검색 결과 갯수 제한.
-b : 패턴이 매치된 각 라인(-o 사용 시 문자열)의 바이트 옵셋 출력.
-n : 검색 결과 출력 라인 앞에 라인 번호 출력.
-H : 검색 결과 출력 라인 앞에 파일 이름 표시.
-h : 검색 결과 출력 시, 파일 이름 무시.
-o : 매치되는 문자열만 표시.
-q : 검색 결과 출력하지 않음.
-a : 바이너리 파일을 텍스트 파일처럼 처리.
-I : 바이너리 파일은 검사하지 않음.
-d : 디렉토리 처리 방식 지정. (read, recurse, skip)
-D : 장치 파일 처리 방식 지정. (read, skip)
-r : 하위 디렉토리 탐색.
-R : 심볼릭 링크를 따라가며 모든 하위 디렉토리 탐색.
-L : PATTERN이 존재하지 않는 파일 이름만 표시.
-l : 패턴이 존재하는 파일 이름만 표시.
-c : 파일 당 패턴이 일치하는 라인의 갯수 출력.
Pattern maching
- 위 다른글의 regex 와는 다른 쉘에서 Pattern maching에 대해 알아본다.
- regex는
[[ ]]에서 제한적으로 사용할 수 있지만*,?,[A-Z]같은 패턴매칭은 쉘 전반에서 사용할 수 있다.
| Pattern matching | Description | e.g. |
|---|---|---|
* | '빈'것을 포함한 모든 문자와 매칭 | find /path/* |
? | '임의'문자 '한 개'와 매칭된다. 한 개 없으면 매칭 안됨 | find /path/??결과: /path/ab /path/ff |
???* | 최소 3글자 이상 | find ???*결과: /path/universal /path/180 |
[XYZ] | X || Y || Z 조건의 '한' 문자 매칭 | find /path/[XYZ]결과: /path/X |
[Y]* | 맨 앞 '한' 문자는 Y이며 Y도 되고 Yasd같은 것두 매칭 | find /path/[Y]*결과: /path/Y /path/Y-2021-22 |
[A-Z,a-z]* | 맨 앞 '한' 문자가 A~Z || a~z 이고 나머진 상관 없음 | find /path/[A-Z,a-z]*결과: /path/A path/Zoo |
[^A-Z]* | 맨 앞 '한' 문자가 A~Z 면 안된다. |

/^[a-z0-9]([a-z0-9-]*[a-z0-9])?$/<U([0-9A-Fa-f]{1,4})>

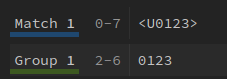
# Handle unicode codepoints encoded as <U0123>, as in glibc locale files. s = re.sub(r'<U([0-9A-Fa-f]{1,4})>', fixutf, s)
[0-9A-Fa-f]: 단일문자 매칭 리스트{1,4}: 이전 토큰의 1~4 번 매치한다. 가능한 많이도 가능하다.- 즉,
[0-9A-Fa-f]는 하나 매칭하는데, 이걸1~4문자까지 확장하는 것
- 즉,
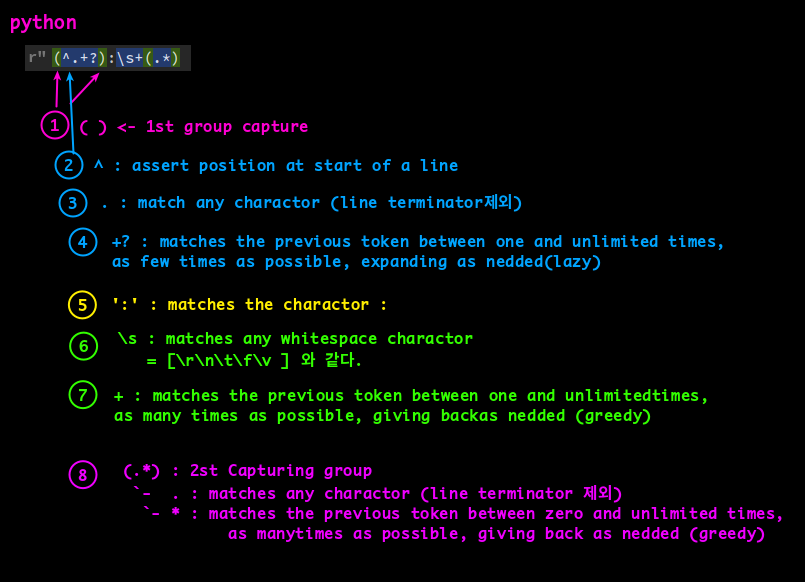
(^.+?):\s+(.*)
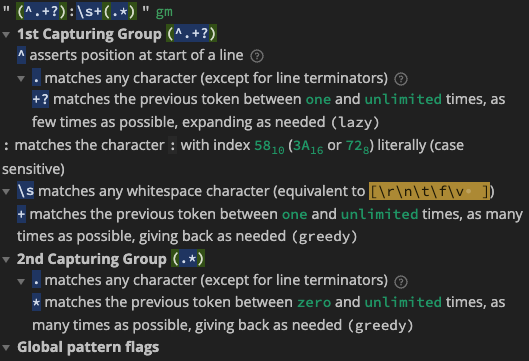
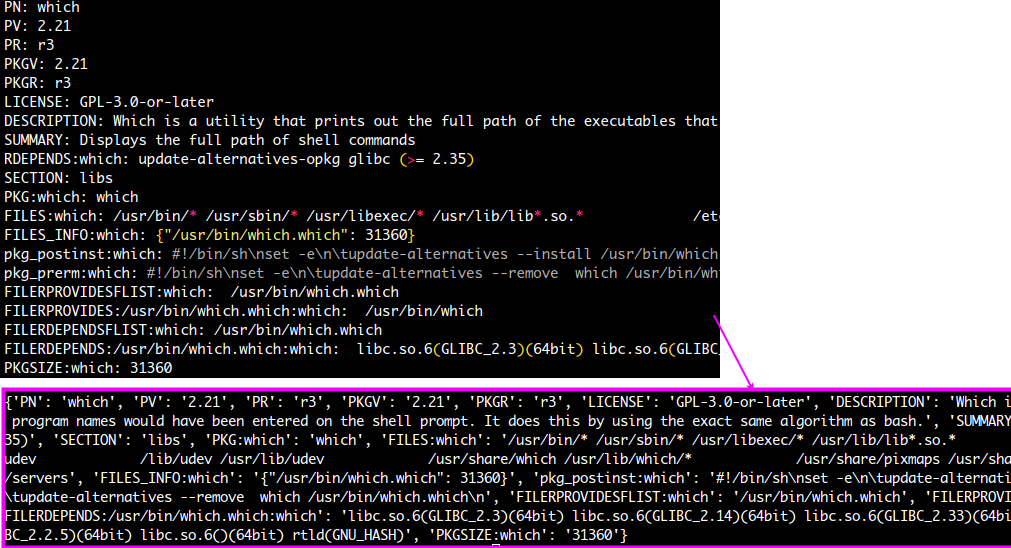
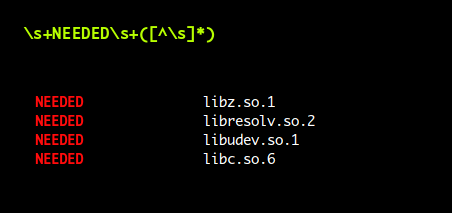
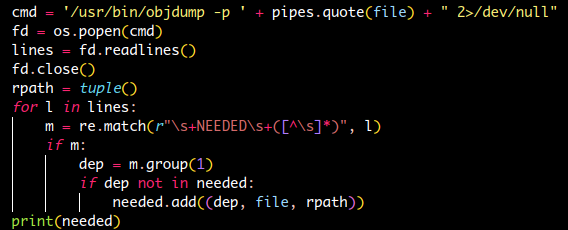
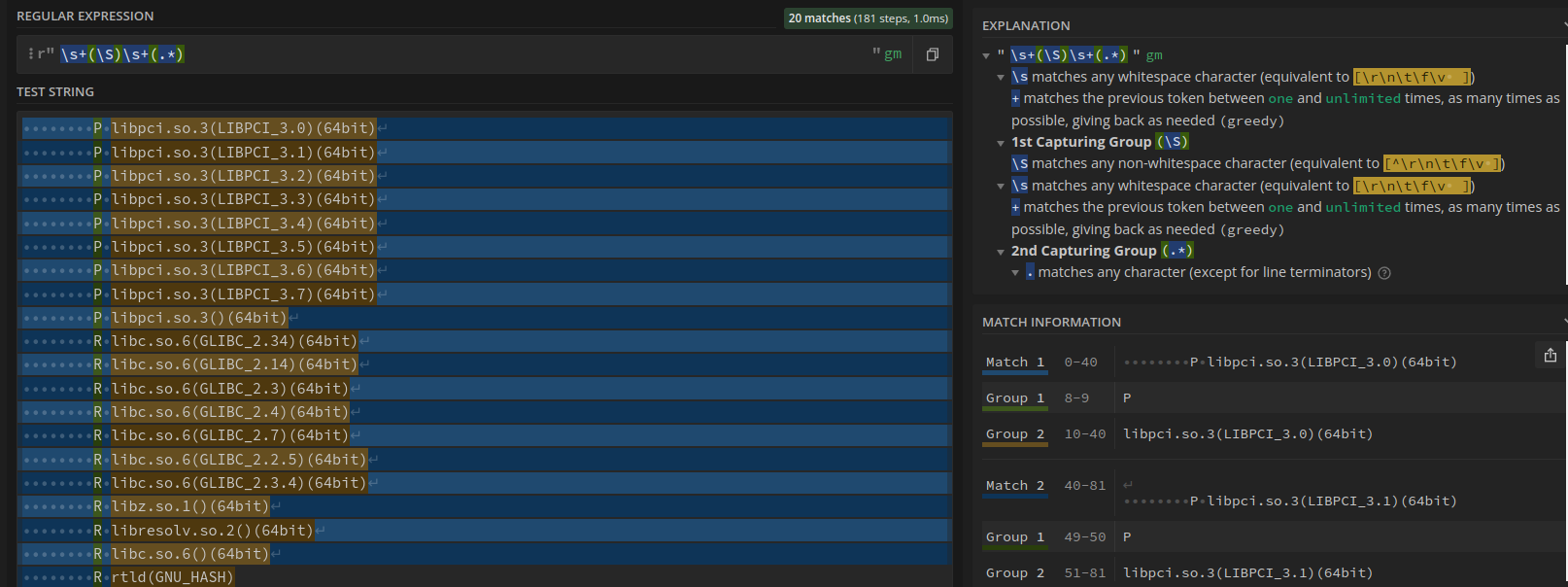
\s+NEEDED\s+([^\s]*)
\s+(\S)\s+(.*)
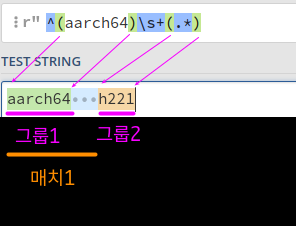
^(aarch64)\s+(.*)
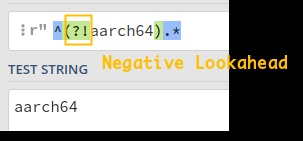
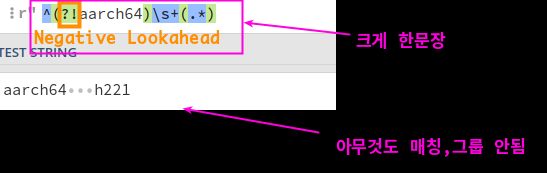
^(?!aarch64).*
^(?!aarch64)\s+(.*)
패스워드 예제
최소 8 글자, 적어도 1개는 문자 && 숫자
grep -oP "^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d].{8,}$"
최소 8 글자, 적어도 1개는 문자 && 숫자 && 특수문자
grep -oP "^(?=.*[A-Za-z])(?=.*\d)(?=.*[@$!%*#?&])[A-Za-z\d@$!%*#?&].{8,}$"
최소 8글자, 적어도 1개는 대문자 && 소문자 && 숫자
grep -oP "^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d].{8,}$"최소 8글자, 적어도 1개는 대문자 && 소문자 && 숫자 && 특수문자
grep -oP "^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&].{8,}$"최소 8글자, 최대 10글자, 적어도 1개는 대문자 && 소문자 && 특수문자
grep -oP "^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)(?=.*[@$!%*?&])[A-Za-z\d@$!%*?&].{8,10}$"table



pllpokko@alumni.kaist.ac.kr