
MySQL Replication은 데이터베이스의 트래픽 부하를 분산하여
가용성을 향상시켜주는 기술이다.
개념
하나의 Master(source) 데이터베이스의 데이터를 n개의 Slave(replica) 데이터베이스로 비동기 방식, 반동기 방식으로 전체 또는 일부 데이터를 복제한다.
Master와 Slave
Master와 Slave에는 Replication을 처리하기 위한 쓰레드가 존재한다.
Master
- Binary Dump Thread
- slave에서 요청이 들어오면
생성 - slave 요청의
위치 정보(GTIDor로그파일명, position)를 가지고 바이너리 로그를 읽어서 변경사항을전달 - 변경사항이 없다면 변경사항 발생할 때까지 Dump Thread는
대기(heartbeat 로 연결 유지)
- slave에서 요청이 들어오면
Slave
- I/O Thread
- Slave 시작시
생성 - Master 정보로 연결, 현재
복제 위치 정보를 요청 - Master로 부터 이벤트 수신시
Relay Log에 기록 - 이벤트 처리 완료 후 현재
복제 위치 정보업데이트
- Slave 시작시
- SQL Thread
- Slave 시작시
생성 - 현재
이벤트 위치 정보를 읽음 I/O Thread가 작성한Relay Log를 읽어 이벤트 유형(DML,DDL등)을 식별- 파싱된 이벤트를 Slave Storage에 적용(쿼리 실행)
- 트랜잭션 이벤트를 만나면 적절히 처리(필요시
commit,rollback) - 이벤트 처리 완료시 현재 이벤트 위치 정보 업데이트
- 지연 복제시 설정된 시간만큼 Lazy 후 처리
- Slave 시작시
프로세스 순서
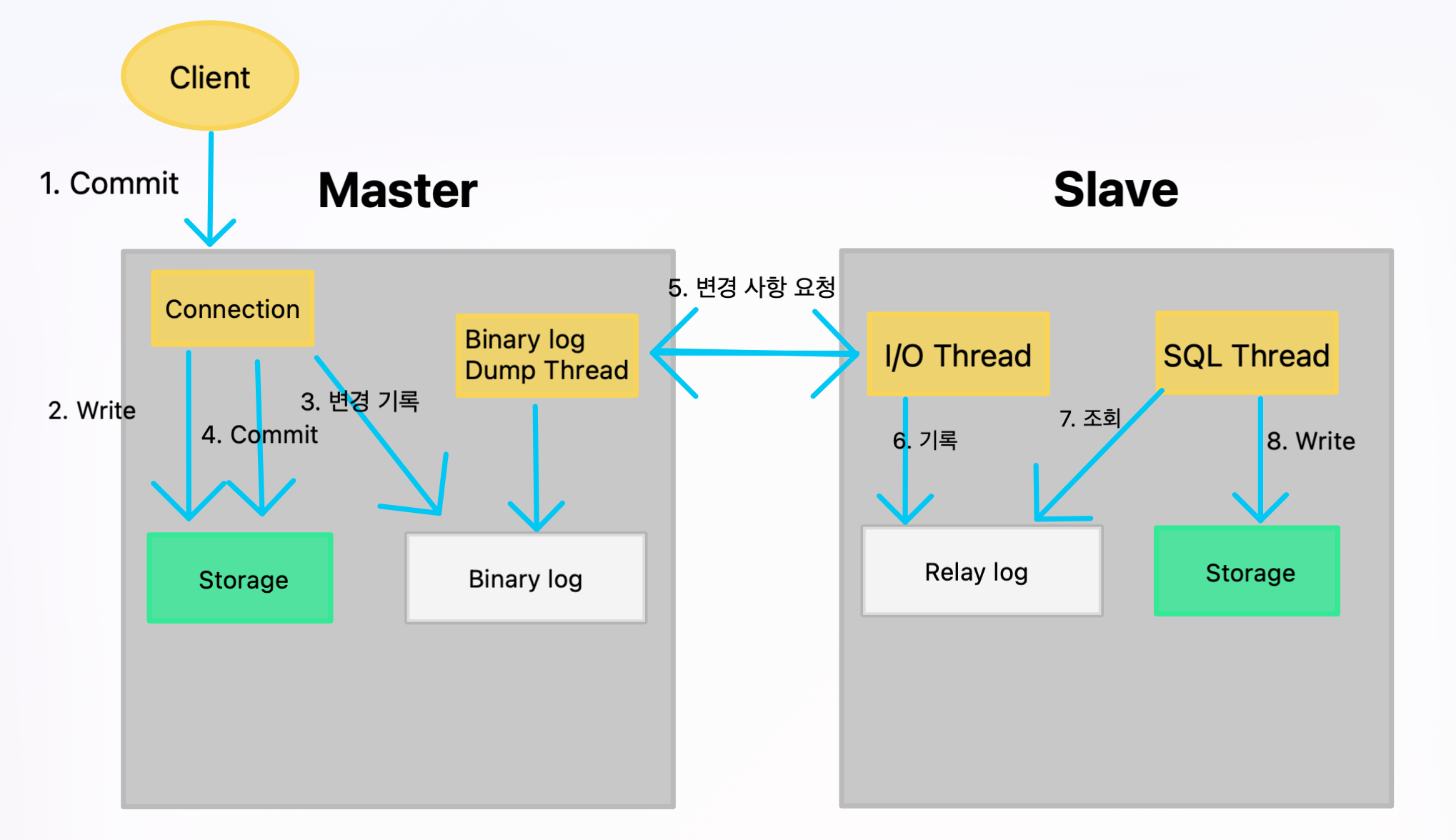
- 클라이언트가
Master에 Commit 요청 - Storage에 Write
- Binary log에 변경 사항을 기록
- Storage Commit (이때 binary log도
Flush)
여기 까지가 Client 요청 I/O Thread가Binary Log Dump Thread에 변경사항을 요청- Relay log에 기록
SQL Thread가 Relay log의 변경사항을 조회- Storage에 Write
Binary 방식
바이너리 로그 파일 위치 기반 복제 방식
소스에서만 유효한 식별 방법
위치정보 형식
binary log file:position
binary-log.000002:145
장단점
장점
-
버전 호환성
전통적인 방식인 만큼 거의 모든 MySQL 버전에서 사용 가능하여 호환성이 높다. -
설정이 단순하다
바이너리 로그 파일과 위치만 설정하면 끝이라 구성이 단순하다. -
유연성
특정 데이터베이스나 테이블에 대한 복제 필터링이 가능하다.
replicate-do-db,replicate-ignore-db,replicate-do-table,replicate-ignore-table등등
단점
-
수동 조작
slave를 추가하거나 복구시binary log파일과position의 정확한 위치를 수동으로 설정해야한다. -
자동화
만약 master의 서버 장애로 slave를 master에 승격시켜야 하는 경우 네트워크,replica 처리속도 등 외부적인 요인으로 master와 slave간 position이 다를 수 가 있다.
이러한 상황에서binary log와position의 수동 작업이 필요하기 때문 -
추적
저장 단위가 트랜잭션 단위가 아니기 때문에 트랜잭션에 비해 추적이 어렵다.
장애 복구시 정확한 위치를 찾아야 한다. -
일관성 보장
binary log의position을 기반으로하기 때문에 일관성 보장이 어려울 수 있다.- 네트워크 등 외부요인으로 Master는 A,B,C 의 요청에 대한 내용을 갖고 있지만 slave1는 A,B slave2는 A,C 만 복제된다면 후에 해당 요청의 누락을 찾기가 다소 힘듬
-
topology(DB간 복제 구조) 변경 복잡성
binary log와position을 수동으로 해야하기 때문
GTID 방식
기존 binary log 위치기반 방식의 단점을 보완하기 위해
5.6.5버전부터GTID모드가 출시되었다.
글로벌 트랜잭션 아이디 기반 복제 방식
차이점
- 서버 고유 UUID 발급
서버에 고유한 UUID를 사용하여 식별 - 트랜잭선 단위 로깅
요청에 고유한 트랜잭션ID를 부여해서 이를 사용한 복제 - 자동 위치 설정
MASTER_AUTO_POSITION=1;옵션을 사용하여 자동 위치 설정 가능
위치정보 형식
server_UUID:Transaction_ID
c6aec179-7370-4927-8e1a-e249ac278d14:11
장단점
장점
-
트랜잭션 단위 로깅
각 트랜잭션 단위로 고유 ID를 부여되어 자동추적이 가능
이로인해추적이 쉬워짐 -
일관성
트랜잭션 ID로 일관성을 보장하여 누락된 트랜잭션을 보다 쉽게 식별가능- Master와 Slave 각각 트랜잭션 목록을 가지고 있기 때문
-
자동화
자동 추적 옵션을 사용하면binary log및position을 수동으로 찾을 필요가 없음
이로인해자동화,포톨로지 변경등이 쉬워짐
단점
-
호환성
GTID모드는5.6.5이상의 버전부터 사용가능 -
유연성
트랜잭션 단위로 묶이는 만큼 유연성은 다소 떨어짐
replicate-do-db,replicate-ignore-db등의 옵션을 직접 사용 불가
8.0이상은CHANGE REPLICATION FILTER로 유사한 기능 구현 가능 -
성능
기본방식에 트랜잭션을 추가하는 만큼의 오버헤드가 있음
토폴로지(Topology)
- 단일 소스 복제 - 왼쪽처럼
1:N개로 각 레플리카가master를 바라보게 구성 - 체인 복제 - 오른쪽처럼
master를 바라보는slave1를slave2가 바라보게 구성
물론 이 두 가지를 섞어서 사용도 가능하다.
당연하게도 해당 구조의slave는readOnly여야한다. (master로는 slave의 데이터가 가지않으니)
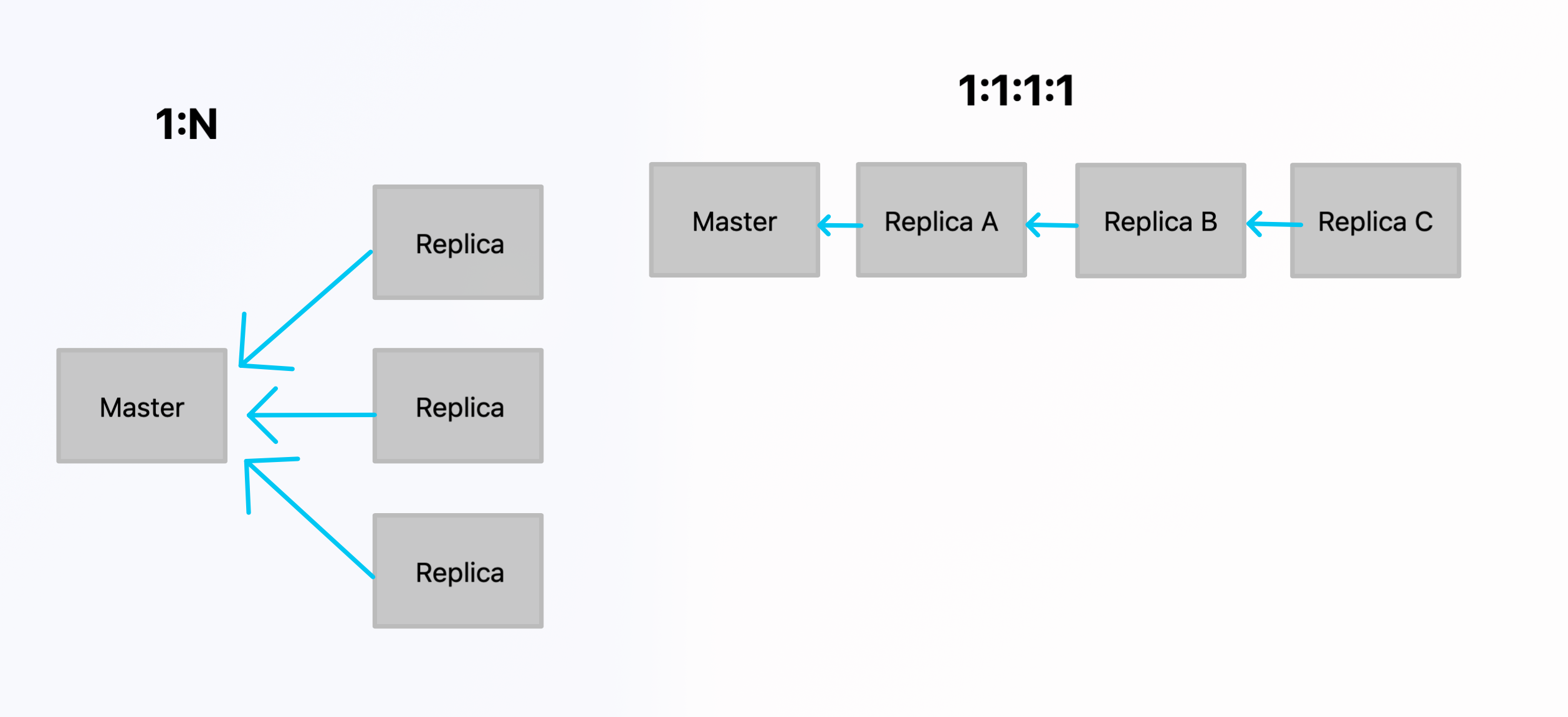
토폴로지 유형
단일 소스 복제(Single-Source Replication)
하나의Master와 여러 개의Slave로 구성다중 소스 복제(Multi-Source Replication)
하나의Slave와 여러 개의Master로 구성
쓰기 트래픽 분산 혹은 각기 다른 환경의 데이터를 통합하여 관리, 분석하기 위해 사용- 다양한 애플리케이션 통합
- 테스트 환경 통합
- 글로벌의 경우 각 리전별 데이터 베이스 통합
체인 복제 (Chained Replication)
Master->Slave1->Slave2->Slave3같이 구성
Master의 부하를 분산하기 좋음(단계가 있는 만큼 복제에 시간차가 발생)순환 복제 (Circular Replication)
A->B->C->A같이 구성마스터-마스터 복제 (Master-Master Replication)
Master<->Master같이 구성계층형 복제 (Hierarchical Replication)
MasterSlave1Slave1-1Slave1-2
Slave2Slave2-1
Slave3
그룹 복제 (Group Replication)
여러 DB 인스턴스를 그룹화해서 사용(복잡하지만 강력한 기능)
정리
구성
- 여러 바이너리 로그 파일과 인덱스로 구성
- 각 파일은 각각의
이름및숫자 확장자가 존재
바이너리 로그의 정의
- 바이너리 로그는 데이터베이스의 변경 사항을 기록하는 일련의 파일
데이터 변경및테이블 구조변경도 포함
기록되는 내용
CREATE,ALTER,INSERT,UPDATE,DELETE등 데이터에 영향을 주는 명령을기록SELECT,SHOW와 같이 데이터에 영향을 주지않는 명령은기록되지 않음
방식
- 트랜잭션의 각 명령이 성공하면
바이너리 로그에 기록 - 동작순서
- InnoDB
prepare로그 작성 및동기화 - 바이너리 로그
기록및커밋마크 추가,fsync()호출 - InnoDB
커밋 로그 작성및동기화
- InnoDB
바이너리 로그 형식
binlog_format환경 변수로 형식 제어
GlobalorSession범위 설정 가능세 가지바이너리 로그 형식 지원:- 행 기반(
Row-Based) 로깅 (RBR):- 개별 테이블 행의 변경 사항을 기록
--binlog-format=ROW- MySQL 8.0
기본 설정
- 문장 기반(
Statement-Based) 로깅 (SBR):- SQL 문장 그대로 기록
--binlog-format=STATEMENT
- 혼합(
Mixed) 로깅:- 상황에 따라 문장 기반과 행 기반을 자동으로 전환하여 기록
--binlog-format=MIXED
- 행 기반(
형식 선택 시 고려사항
Row-Based- 안전하고 정확하지만, 로그 크기가 커짐- 레플리카는
행 기반바이너리 로그 항목을문장 기반 형식으로 변환할 수 없음
- 레플리카는
Statement-Based- 로그 크기가 작지만, 비결정적 문장(실행시마다 다른 결과가 나오는 SQL문)에서 소스와 레플리카의 불일치 가능성 있음
보안
민감한 정보를 포함할 수 있으므로 적절한 보호가 필요- 바이너리 로그 기반 복제는
데이터 일관성 유지,백업,복구에 중요한 역할
주의사항
디스크의 I/O 작업이 증가하여 서버 성능에 영향을 줄 수 있음- 동시 트랜잭션 커밋 시
prepare_commit_mutex로 인한 직렬화가 발생할 수 있음
