데이터 정제하기
-
데이터 가공 시에 관측치 뿐만 아니라 누락된 결측치(missing value)나 이상치(outlier)가 있을 수 있음. 이로 인해서 데이터 분석 시에 오류 발생, 분석 결과 왜곡이 발생해 데이터 가공 단계에서 중요함. 이걸 처리하는 게 데이터 정제(data cleaning)
-
결측치 확인하기 (NA)
is.na(변수명) -> 결측치 확인 후 T/F로 반환
table(is.na(변수명) -> 결측치 빈도 확인
x <- c(1,2,NA,4,5)
x
sum(x)
is.na(x)
table(is.na(x))
- 결측치 제외하기
sum(x, na.rm=T) -> na.rm=T 결측치 제외하기 - 결측치 개수 확인하기
sum(is.na()) -> 데이터 세트에 결측치 총 몇 개
colSums(is.na()) -> 각 컬럼의 결측치 개수 확인
data(airquality)
is.na(airquality)
sum(is.na(airquality) -> 결측치 전체 개수 확인- 결측치 제거하기
na.omit(변수명)
data(airquality)
na.omit(airquality)- 결측치 대체하기 (다른 값을로 대체함)
변수명[is.na(변수명)] <- 대체할 값
data(airquality)
airquality[is.na(airquality)] <- 0
colSums(is.na(airquality)-> 변수명에는 데이터 세트 넣고, 대체 값에 대체하고자 하는 값을 넣음. 만약 결측치를 0으로 대체하고 싶다면 대체값에 0을 입력함.
- 이상치 확인하기 -> 상자그림을 활용해서 보면 편함
data(mtcars)
boxplot(mtcars$wt)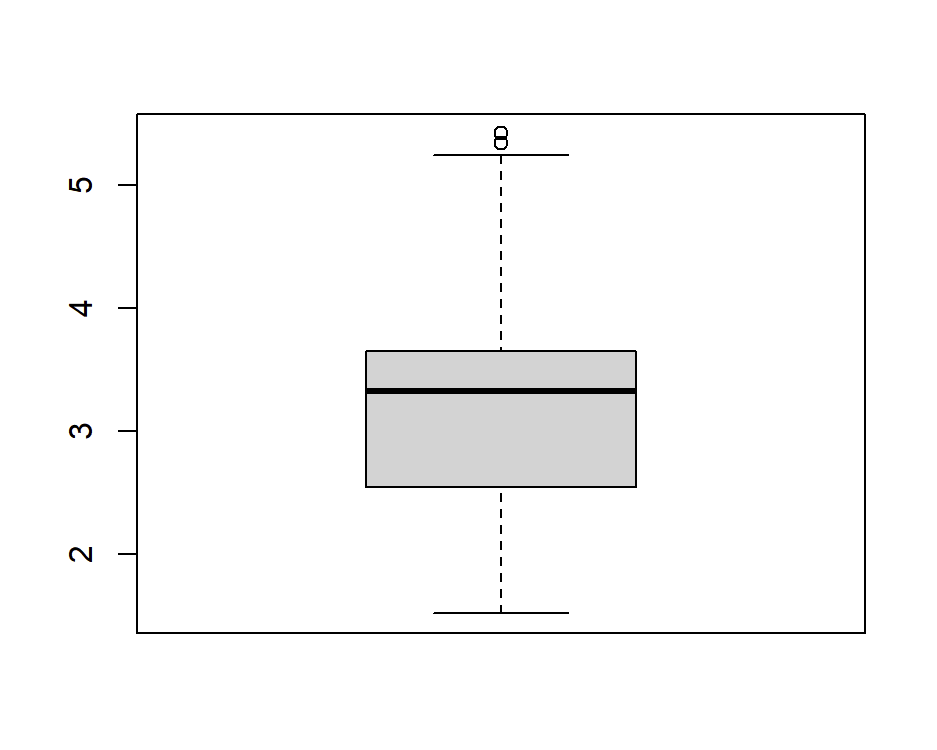
이렇게 이상치가 나타난다.
- 이상치 처리하기
ifelsa(조건문, 조건문이 참일때 실생, 거짓일때 실행)
-> 조건에 대해 값을 반환하는 함수임.
mtcars$wt > 5.25 -> wt세트에서 5.2500을 초과하는 값을 찾는 경우
mtcars$wt <- ifelse(mtcars$wt > 5.25, NA, mtcars$wt) - 핵심 함수 정리
is.na() 결측치 확인
sum(is.na()) 결측치 개수 확인
colSums(is.na()) 컬럼 결측치 개수 확인
na.omit() 결측치 제거
boxplot() 상자그림, 이상치 확인
ifelse() 조건에 따라 값 반환
