- 데이터 가공: 데이터 분석 시에 변수 생성, 데이터 추출, 변경, 정렬, 병합 하는 일련의 과정 모두를 의미함 (= 데이터 전처러, 핸들링, 마트 등 유사한 용어 사용)
-> 실제 데이터 분석 과정보다 데이터 준비 과정이 어렵고 시간도 오래 걸림.
1. 데이터 추출하기
(1) 필요한 데이터 추출하기
library(dplyr)
library(readxl)
exdata1 <-read_excel("C:/Users/dasun/Downloads/source/Sample1.xlsx")
exdata1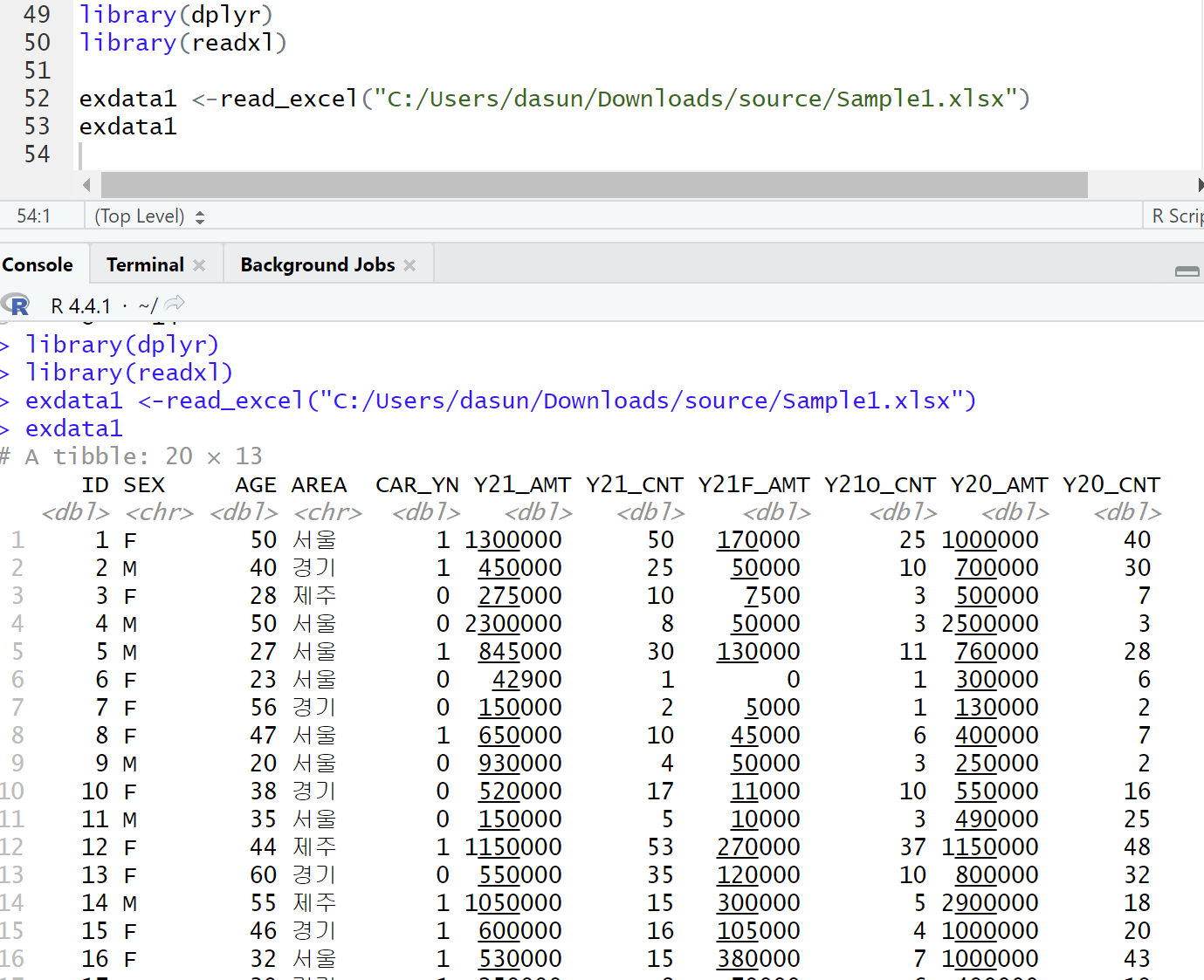
-> 성별, 나이, 지역에 따른 20년/21년 이용 금액, 이용 건수가 있음
(2) 선택 변수만 추출하기
exdata1 %>% select(ID)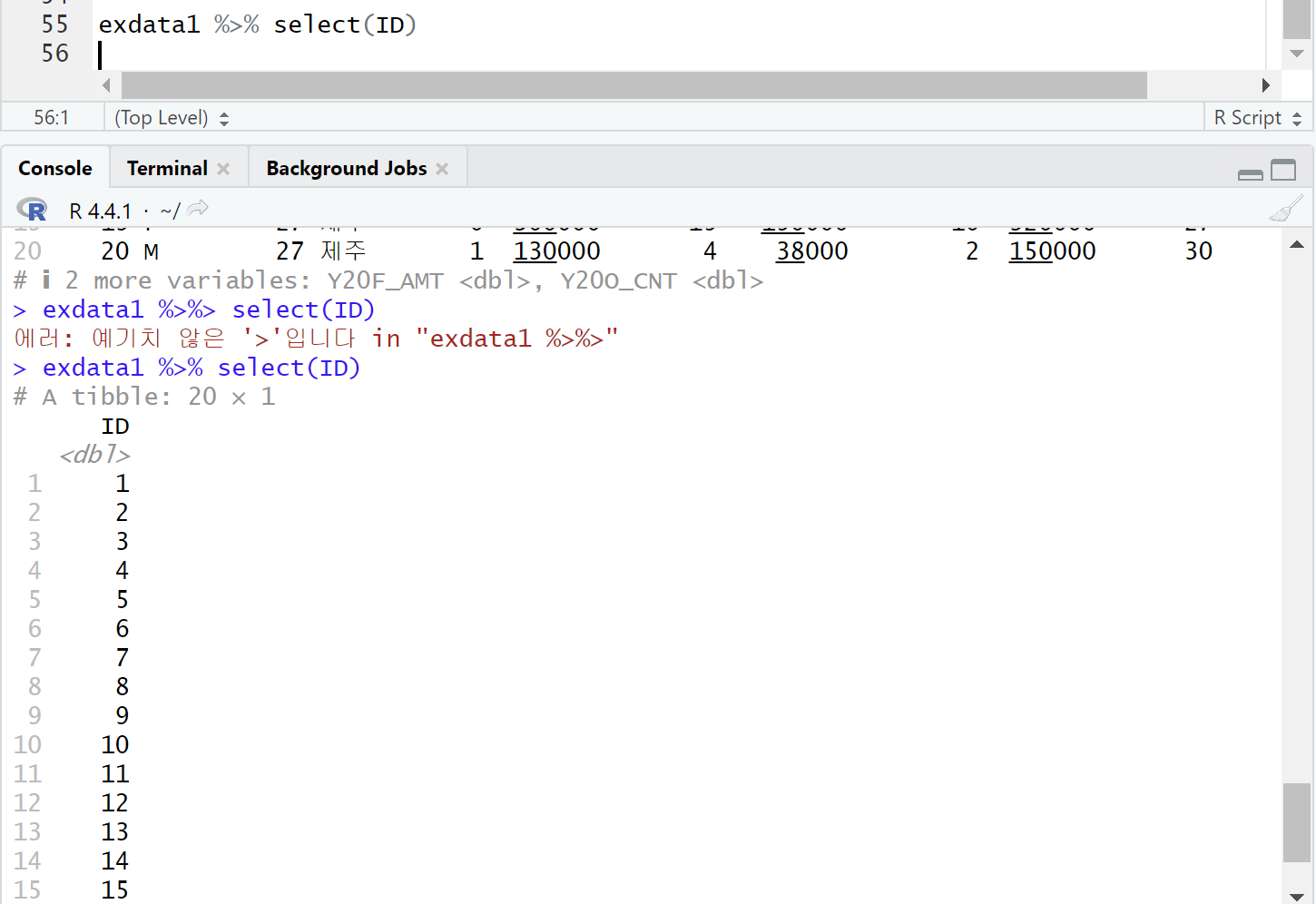
주의!!! %>%>가 아니라 %>%임. 뒤에 깍쇠 없음.
-> 변수 여러개 추출
-> 특정 변수 제외
exdata1 %>% select(ID, AREA, Y21_CNT)
exdata1 %>% select(-AREA)주의!!!! 특정 변수를 제외하는 경우에는 앞에 마이너스('-') 부호를 붙이자
(3) 필요한 데이터만 추출하기
exdata1 %>% filter(AREA=='서울'& Y21_CNT >= 10)
filter를 활용해서 하고 , 여러개 하려면 &해서 연산자 활용
- 데이터 정렬하기
(1) 오름차순 & 내림차순 정렬하기
exdata1 %>% arrange(AGE)
exdata1 %>% arrange(desc(Y21_CNT))주의!!!! 오름차순은 그냥 쓰고, 내림차순은 desc를 적기
중첩 정렬할 경우에는 AGE, decs(Y21_CNT)이렇게 해서 쉼표 사용
- 데이터 요약하기
- summarise()와 group_by() 함수 사용하기
exdata1 %>% summarise(TOT_Y21_AMT=sum(Y21_AMT))
exdata1 %>% group_by(AREA) %>% summarise(SUM_Y21_AMT=sum(Y21_AMT))-> 여기서 TOT~는 새 변수명, AREA는 그룹기준, SUM~새변수명임
- 데이터 결합하기(join)
- 세로결합: 변수명을 기준으로 결합
- 가로결합: 세로에 비해 복잡. 테이블 결합 기준이 되는 by="변수명"에 사용할 변수가 있어야 함.
left_join(테이블1, 테이블2, by="변수명") -> 테이블 1 기준으로 2에 있는 나머지 변수 결합
inner_join(테이블1, 테이블2, by="변수명) -> 테이블 1과 2에서 기준으로 지정한 변수 값이 같을때
full_join(테이블1, 테이블2, by="변수명) -> 테이블 1과 2에서 기준으로 지정한 변수 값 전체- 연습문제 풀이 (p.244 문제 2)
exdata2 <-exdata1 %>% filter(AGE<=30 & Y20_CNT>=10)
exdata2AGE가 30세 이하면서, Y20_CNT가 10건 이상인 데이터를 exdata2로 생성
-> 여기서 오류가 두 번 남

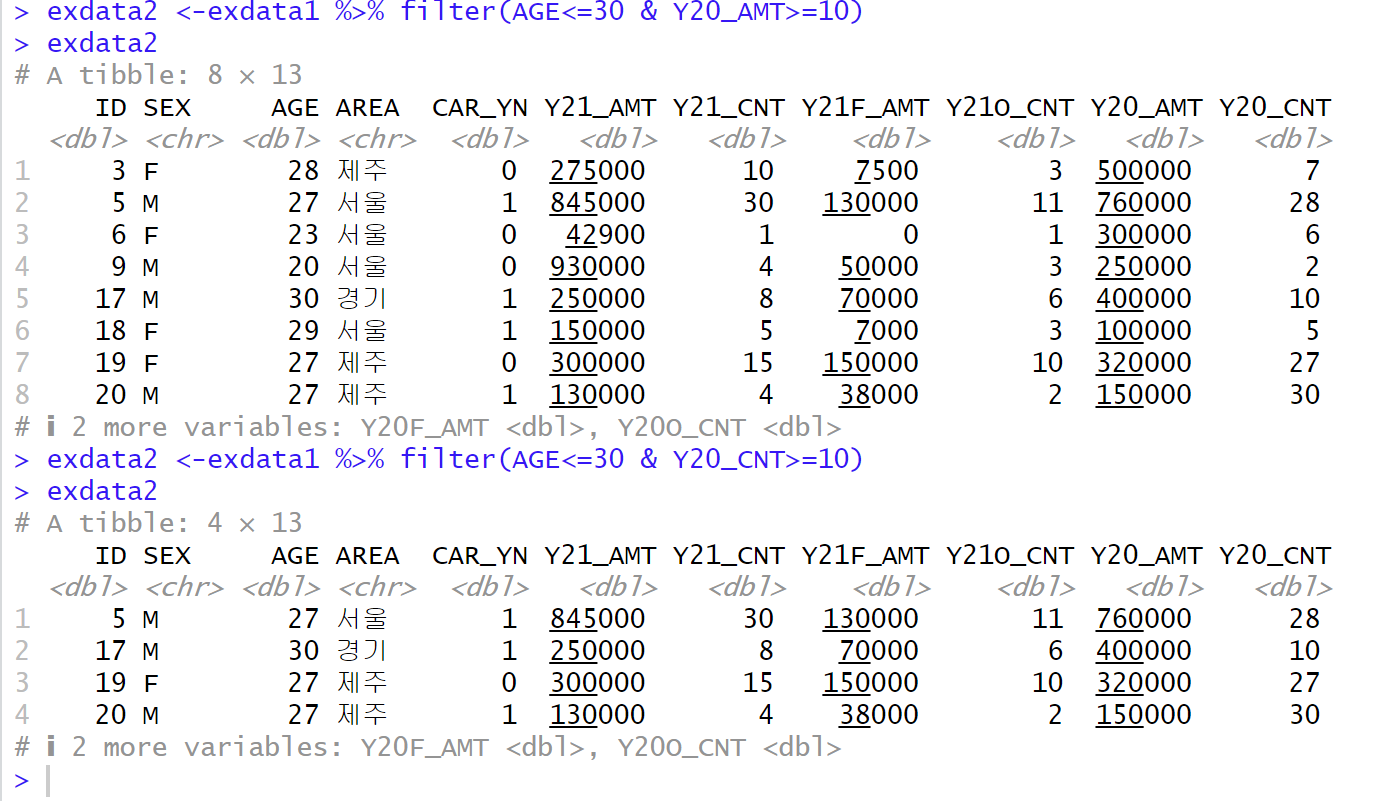
- exdata1을 앞으로 빼고 연산자 활용, 30세 이하는 <=이고, 10건 이상은 >=임 ==두번 사용해서 틀림
- 두번째로는 Y20_CNT가 아니라 AMT로 함. -> 가끔 변수 자동완성 되는 경우가 있는데 이런 경우를 조심해서 보자
- 추가문제 풀이(p.261번 4번 문제)

viesms View 로 대문자 활용해서 적어야 함
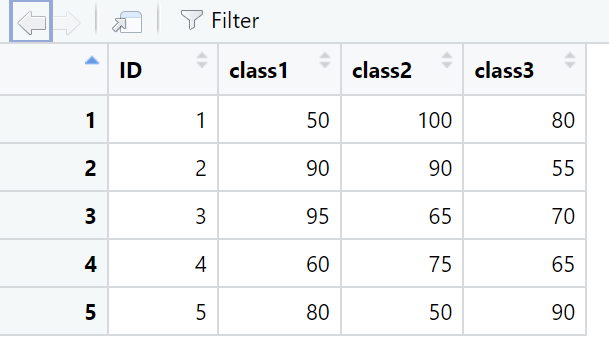
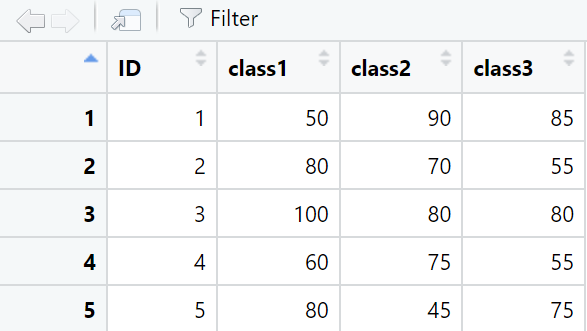
수학 결과창
영어 결과창
middle_mid_exam <- read_excel("C:/Users/dasun/Downloads/source/middle_mid_exam.xlsx")
View(middle_mid_exam)
library(dplyr)
library(reshape2)
MATHEMATICS <- middle_mid_exam %>% select(CLASS, ID, MATHEMATICS)
MATHEMATICS <- dcast(MATHEMATICS, ID ~ CLASS)
View(MATHEMATICS)
ENGLISH <- middle_mid_exam %>% select(CLASS, ID, ENGLISH)
ENGLISH <- dcast(ENGLISH, ID ~ CLASS)
View(ENGLISH)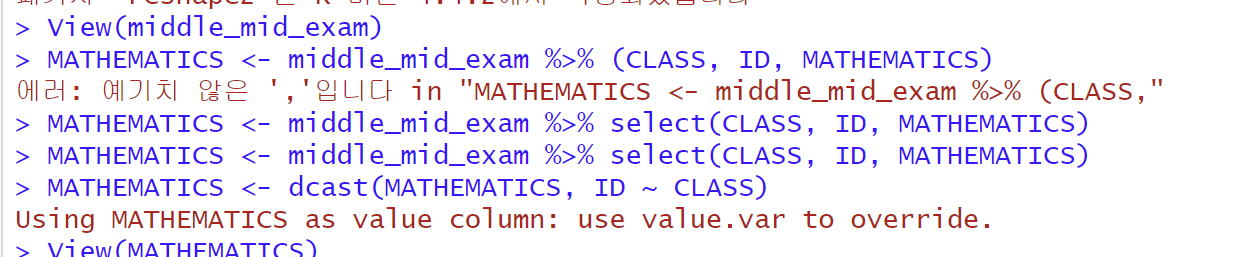
여기서 select 빼고 적어서 처음에 오류남
