데이터 가공은 데이터 분석 과정에서 가장 많은 시간과 노력을 투입해야함 -> 정확한 결과를 위해서 해당 과정이 잘못 되면 처음 부터 다시해야 할 수도 있음.
- dplyr 패키지(데이터 가공을 위해서 주로 사용하는 함수)
install.packages("dplyr")
library(dplyr)(1) 데이터 추출 및 정렬하기
- dplyr 패키지에 포함된 행 추출: fillter() 함수
nrow(mtcars)
str(mtcars)
filter(mtcars, cyl==4)
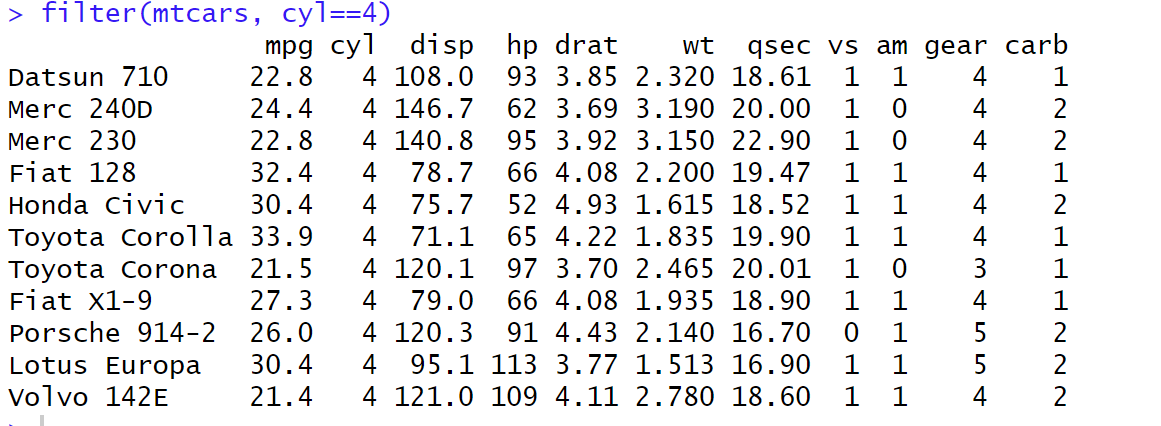
-> 조건에 맞는 데이터를 필터링 하는 함수임
- mtcars 데이터세트에는 연비(mpg), 실린더 개수(cyl) 등 연료 소비와 롼련된 11개 변수와 차종 32개가 있는 걸 확인 할 수 있음 -> 저 코드에서는 실린더 개수 4기통 짜리 추출함
- 이때, &연산자를 활용하면 더 많은 조건을 지정할 수 있음

filter(mtcars, cyl>=6&mpg>20)-> 6기통 이상의 자동차 중에서 연비가 20마일/갤런을 초과하는 차만 추출한 것임
- 열 추출하기: select() 함수
필터 함수가 행을 추출했다면 셀렉트 함수는 지정 변수만 추출할때 사용

head(select(mtcars, am, gear))-> 변속기(am)과 기어(gear) 데이터만 추출함.
-
정렬하기: arrange() 함수
데이터를 오름차순으로 정렬할 때 활용함, 내림차순은 desc()함수임 -
데이터 요약하기 summarise() 함수
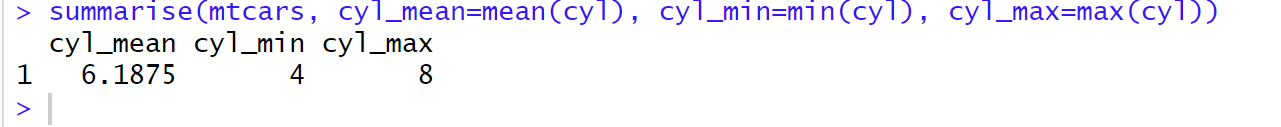
-
그룹별로 요약하기: group_by() 함수

-
샘플 추출하기: sample_n(), sample_frac()
-> n은 전체 데이터에서 샘플 데이터 개수 기준, frac는 샘플 데이터 비율 기준으로 추출 -
파이프 연산자: %>%> -> 연결하여 연산하는 연산자
-> 함수를 연달아 사용할때 함수 결괏값을 변수로 저장하는 과정을 거치지 않아도 되고 바로 함수를 이어 받아서 사용할 수 있음
