어느덧 3주차..
1. 데이터 입력
-
데이터 입력: INSERT
-> INSERT INTO 테이블 [(열1, 열2, ...) VALUES (값1, 값2, ...)]
테이블 이름 다음에 나오는 열 생략 가능, 생략시 VALUES 다음에 나오는 값들의 순서 및 개수는 테이블 정의 시 열 순서 및 개수와 동일해야 함. -
자동증가 AUTO_INCREMENT: 열 정의 시 1부터 증가하는 값입력. -=> PRIMARY KEY로 지정해줘야 함.
-
다른 테이블 데이터 한 번에 입력 INSERT INTO ~ SELECT
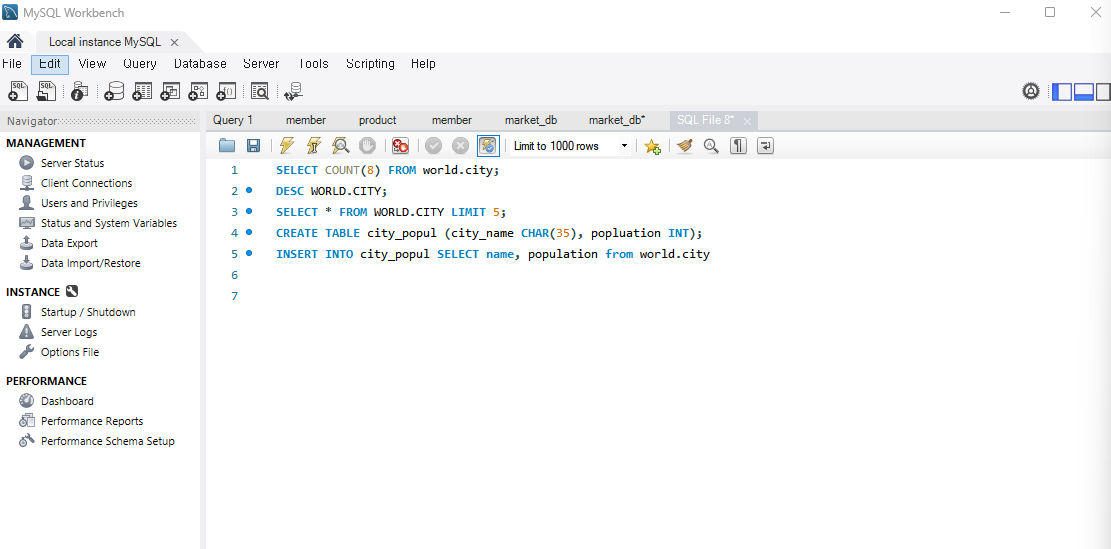
-> MYSQL 기본 데이터인 world.city를 활용해서 풀기.
SELECT FROM world.city;
SELECT FROM world.city LIMIT 5; -> 5건 정도 살펴봄
여기서 이름과 인구를 가져오려면 먼저 테이블을 만들고 추출
CREATE TABLE city_popul (city_name CHAR(35), popluation INT);
INSERT INTO city_popul SELECT name, population from world.city
- 데이터 수정: UPDATE -> 데이터 변경 시 행 데이터 수정 필요시 사용
2. SQL 고급 문법
(1) 데이터 형식
- 정수형: 소수점이 없는 숫자(인원수, 가격, 수량 등)
-> TINYINY(-128~127), SMALLINT(-32.768~32.767), INT(약 -21억~+21억), BIGINT(-900경~+900경)- 숫자 입력하다가 OUT OF RANGE는 입력 값의 범위가 나타났다는 뜻으로, 범위에 맞게 정수형 입력하기
- 문자형: 글자 저장을 위해 사용, 입력 글자의 최대 수 지정
-> CHAR(개수) 바이트 1~255, VARCHAR(개수) 바이트 1~16383
CHAR는 고정길이 문자형임. VARCHAR는 가변길이 문자형.-> VARCHAR가 CHAR보다 공간 효율적으로 운영 가능하나, MYSQL 내부 성능(속도) 면에서는 CHAR로 설정하는 게 좀 더 편함
- 실수형: 소수점이 있는 숫자 저장용
-> FLOT(4BYTE: 소수점 아래 7자리까지 표현)
DOUBLE(8BYTE: 소수점 아래 15자리까지 표현)
- 날짜형: 날짜 및 시간 저장
DATE(3): 날짜만, YYYY-MM-DD 형식 -> 그냥 데뷔 일자 정도
TIME(3): 시간만, HH:MM:SS 형식
DAYTIME(8): 날짜 및 시간 저장, YYYY-MM-DD HH:MM:SS ->물건 구매 시간까지 알고 싶으면
- 변수 앞에는 @를 붙임
- 데이터 형식 변경하는 형 변환 함수에는 CAST(), CONVERT()가 있음.
(2) 데이터 조인
- 두 개의 테이블을 서로 묶어서 하나의 결과를 만들어내는 경우, 두 테이블을 엮어야만 원하는 형태가 나오는 경우도 많기 대문. -> 인터넷 마켓 데이터베이스 회원 테이블+구매 테이블
- DB는 하나의 테이블 보다 여러 정보를 주제에 따라서 다로 분리해서 저장하는 게 효율적임. -> 이 때 분리된 테이블은 서로 relation이 있음. 예시가, market_db의 회원 테이블과 구매 테이블임.
=> 이때 회원테이블과 구매 테이블에서 기본키primary key, PK는 회원 ID임. 아이디를 기준으로 엮음.
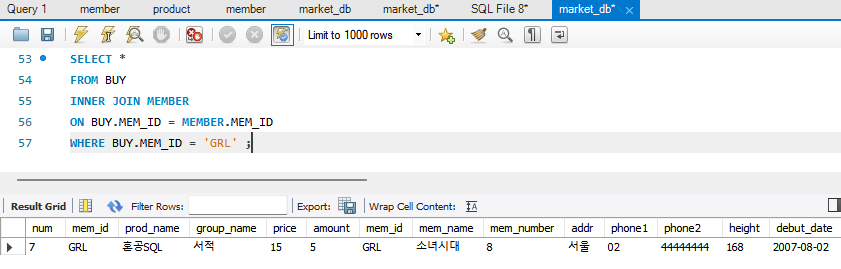
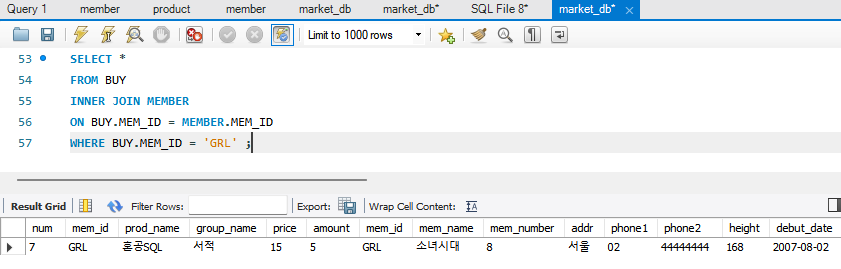
내부조인의 기본
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인될 조건>
[WHERE 검색 조건] ;
->INNER JOIN을 그냥 JOIN으로 써도 INNER로 인식함.
이거 예시
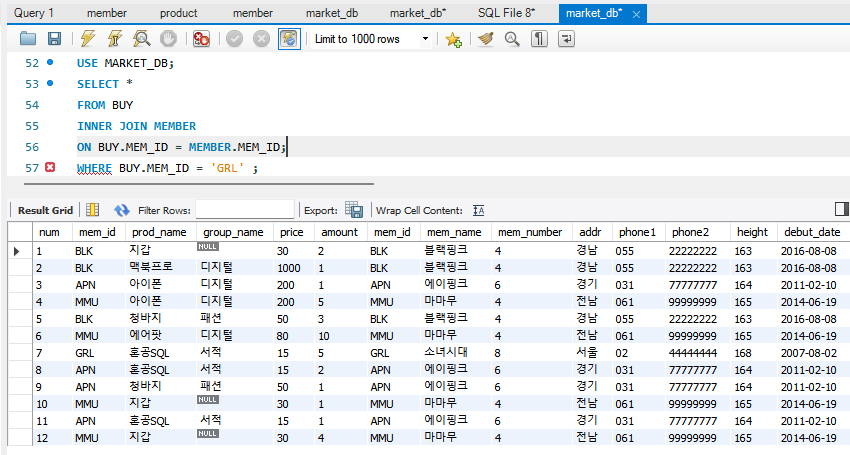
WHERE 조건 생략하면 전체 내부조인된 표가 나옴.
내부 조인은 두 테이블에 모두 데이터가 있어야만 결과가 나옴. 반면, 외부 조인은 한 쪽에만 데이터가 있어도 결과가 나옴.
외부조인의 기본
SELECT <열 목록>
FROM <첫 번째 테이블(LEFT 테이블)>
<LEFT | RIGHT | FULL> OUTER JOIN <두번째 테이블(RIGHT 테이블)>
ON <조인될 조건> -> 그냥 LEFT JOIN이라고만 적어도 인식함.
[WHERE 검색 조건] ;
3. 기본숙제 (p.194 확인문제 4번 풀기)
SELECT DISTINCT M.med_id, B.prod_name, M.men_name, M.addr
FROM member M
LEFT OUTER JOIN buy B
ON M.med_id = B.men_id
[ ]
ORDER BY M.men_id;
=> SQL은 회원가입만 하고 한번도 구매한 적 없는 회원의 목록임. 빈칸에 들어갈 적합한 구문은?
(1) JOIN B.prod_name IS NULL
(2) LIMIT B.prod_name IS NULL
(3) HAVING B.prod_name IS NULL
(4) WHERE B.prod_name IS NULL
(선택) 4번 (외부조인의 활용)
(정답) 4번 (이유: 회원 가입하고 멤버 ID랑 이름, 구매 물건을 ID 기준으로 합침. 근데 물건은 한번도 산 적이 없으니, 검색 조건인 prod_name에는 NULL로 나올 수 밖에 없음.
- LIMIT OUTER JOIN 왼쪽 테이블의 모든 값이 출력
- HAVING
- JOIN 두개의 테이블을 서로 묶어서 하나의 결과를 만들어 냄
4. 추가숙제 (p.183 좀 더 알아보기 손코딩 실행 결과)
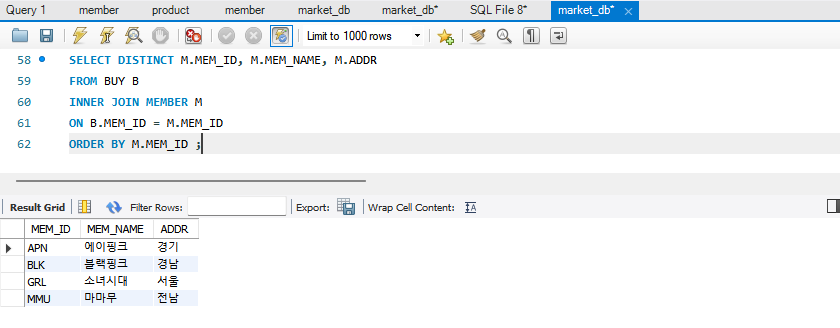
=> 우리 사이트에서 구매한 기록이 있는 횐님 찾기 완료!
3주차 공부 완료
-> SQL 문법은 R이랑 비슷한 거 같다.. R에서 JOIN 활용하던 기억을 더듬어서 이번 주 숙제 마무리. 1-2주차는 지각했다는 사실에 쫓겨서 제대로 못 풀었지만, 이번주는 차분하게 하니 숙제도 잘 풀 수 있었다. 다음주도 화이팅..
