pivot_table은 판다스(Pandas) 라이브러리의 중요한 기능 중 하나로, 데이터를 재구성하고 요약하는 데 매우 유용합니다. 주어진 데이터를 정리하여 데이터를 쉽게 확인할 수 있도록 도와줍니다. 본문에서 사용한 데이터와 예제들은 '제로베이스 데이터스쿨'의 강의를 참고하였습니다.
pivot_table() 사용법
import pandas as pd
# 예제 데이터 생성
data = {
'Name': ['John', 'Anna', 'Peter', 'Linda', 'James'],
'Subject': ['Math', 'Science', 'Math', 'Science', 'Math'],
'Score': [88, 92, 85, 90, 95]
}
df = pd.DataFrame(data)
# pivot_table 생성
pivot_table = df.pivot_table(values='Score', index='Subject', columns='Name', aggfunc='mean', fill_value=0)
print(pivot_table)이 코드는 주어진 데이터 프레임을 사용하여 pivot_table을 생성합니다. 여기서 values는 요약할 데이터 열을 지정하고, index는 행 인덱스로 사용할 데이터 열을 지정하며, columns는 열 인덱스로 사용할 데이터 열을 지정합니다. aggfunc는 데이터를 요약할 때 사용할 함수를 지정하며, 기본값은 'mean'입니다. fill_value는 결측값을 대체할 값으로, 이 예에서는 0으로 설정되어 있습니다.
pivot_table()의 주요 인자들
values: pivot_table에서 집계하려는 열을 지정합니다.index: pivot_table의 행 인덱스로 사용될 열을 지정합니다.columns: pivot_table의 열 인덱스로 사용될 열을 지정합니다.aggfunc: 집계 함수를 지정하며, 기본값은 'mean'입니다. 다양한 함수를 지정할 수 있으며, 예를 들어sum,min,max,count,median등이 있습니다.fill_value: pivot_table에서 결측값을 대체할 값으로, 이 인자를 통해 결측값을 쉽게 처리할 수 있습니다.margins: True로 설정하면, 행과 열의 총계를 추가합니다.dropna: True로 설정하면, 모든 항목이 NA인 열을 제거합니다.
앞서 설명한 주요 기능들을 활용해 주피터 노트북에서 피봇테이블을 생성한 화면입니다.
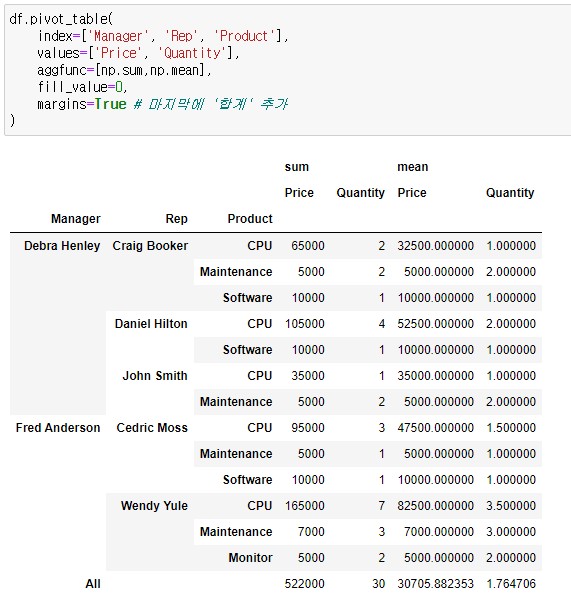
마치 엑셀의 셀병합처럼 여러개의 인덱스와 컬럼이 묶여 있는 걸 볼 수 있습니다. 이런 것을 '멀티 인덱스'라고 합니다.
멀티인덱스 - droplevle()
멀티 인덱스는 데이터 프레임의 구조를 복잡하게 만들 수 있으며, 특히 피벗 테이블을 생성할 때 이러한 현상이 발생할 수 있습니다. 멀티 인덱스는 인덱스가 여러 레벨로 구성되어 있음을 의미하며, 이를 조작하거나 시각화할 때 어려움을 겪을 수 있습니다. 이 문제를 해결하기 위해 drop_level 메서드를 사용하여 멀티 인덱스의 레벨을 줄일 수 있습니다. 이 메서드는 특정 레벨의 인덱스를 제거하여 데이터 프레임을 더 단순하게 만들어 줍니다.
이어지는 코드 예제에서는 pivot_table의 결과로 만들어진 멀티 인덱스를 갖는 데이터 프레임에 drop_level 메서드를 사용하는 방법을 보여줍니다.
import pandas as pd
# 예제용 데이터를 사용합니다.
data = {
'Name': ['John', 'Anna', 'Peter', 'Linda', 'James'],
'Subject': ['Math', 'Science', 'Math', 'Science', 'Math'],
'Score': [88, 92, 85, 90, 95]
}
df = pd.DataFrame(data)
# pivot_table 생성, 멀티 인덱스를 갖도록 설정합니다.
pivot_table = df.pivot_table(values='Score', index=['Subject', 'Name'], aggfunc='mean')
print("Before drop_level:")
print(pivot_table)
# droplevel을 사용하여 멀티 인덱스의 레벨을 줄입니다.
pivot_table.index = pivot_table.index.droplevel(1)이 코드에서 pivot_table 메서드를 사용하여 'Subject'와 'Name' 열을 인덱스로 설정하고, 멀티 인덱스를 생성합니다. 그런 다음 drop_level 메서드를 사용하여 'Name' 레벨의 인덱스를 제거합니다. 이렇게 하면 데이터 프레임이 더 단순하고 조작하기 쉬워집니다.
droplevle() 관련 예제

컬럼을 보면 컬럼이 여러 층으로 쌓여 있는게 보입니다. 위의 데이터 프레임의 컬럼을 확인해보면 아래와 같습니다.
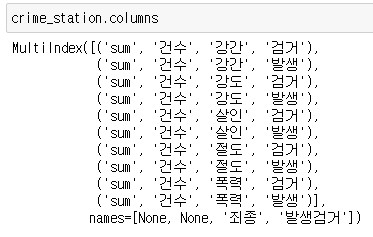
위의 데이터 프레임에서 확인했다시피 crime_station 데이터 프레임은 4개의 층으로 이뤄진 멀티인덱스를 갖고 있습니다. 앞서 설명한 droplevlel을 활용해 컬럼의 구조를 단순화 해보겠습니다.

[0, 1] 레벨을 제거해 컬럼을 단순화 하였습니다. 이렇게 하면 crime_station 데이터 프레임의 컬럼 구조가 더 단순해지고, 데이터 조작이 더 쉬워집니다. droplevel 메서드는 인덱스 레벨을 제거하여 데이터 프레임의 복잡도를 줄이고, 이해하고 조작하기 쉽게 만드는데 도움이 됩니다.
사소한 팁을 추가하겠습니다.

앞서 설명한 것과 동일한 피벗테이블입니다. aggfunc에 집계함수를 np.sum을 [ ] 없이 적었을 때, sum이 멀티인덱스의 레벨로 추가되지 않습니다.
