스터디노트
1.제로베이스 데이터스쿨 20기 OT 후기

데이터분석가로 취업을 결심하고 KDT과정으로 교육을 받았다. KDT 과정을 통해 파이썬을 처음 배우고, 데이터분석가의 일에 대해서도 진지하게 고민하게 된 건 큰 수확이었지만, 교육과정은 기대만큼 만족스럽진 못했다. 학원측의 사정으로 정상적인 강의 진행이 어렵게 되어 결
2.[제로베이스 데이터스쿨] 스터디노트 - 2주차 마무리
제로베이스 스쿨의 과정이 진행되면서 점차 코딩의 세계에 깊이 담그게 되었다. 얕게 알고 있던 것들을 좀 더 확실히 이해하게 되는 중이다. 특히 어제, 오늘은 클래스와 예외처리 문제를 다루면서 느낀 점들이 많았다.요즘 코드를 작성하며 가장 신경 쓰는 부분은 객체를 별도로
3.파이썬 리스트 - insert, sort, bisect 비교
Python에서 리스트에 요소를 추가하고 정렬하는 방법은 다양합니다. 이 포스트에서는 insert, append &sort, 그리고 bisect 세 가지 방법을 살펴보겠습니다.insert()는 리스트에 요소를 특정 인덱스에 삽입하는 메서드입니다. 이미 정렬된 리스트에
4.[스터디노트] lambda를 이용한 정렬, 최대값, 최소값 찾기
이번 포스트에선 람다 함수를 이용하여 리스트를 정렬하고, 최대값, 최소값을 찾는 방법에 대해 알아보겠습니다.람다(lambda) 함수는 이름이 없는 익명 함수입니다. lambda 키워드를 사용하여 간단한 로직을 한 줄로 표현할 수 있습니다. 람다 함수는 간결하고 코드의
5.[스터디노트] 딕셔너리: 주요 메소드와 활용 방법
딕셔너리는 키-값 쌍으로 데이터를 저장하며, 데이터 검색과 수정이 빠르다는 장점이 있습니다. 이 포스트에서는 딕셔너리에서 자주 사용하는 메소드들을 살펴보고, 각 메소드가 어떤 상황에서 유용한지, 그리고 실제 코드 예제를 통해 메소드의 활용법을 알아보겠습니다.get()
6.[스터디노트] 파이썬 - 예외 처리
에러는 프로그램이 실행되지 않도록 막는 심각한 문제를 의미합니다. 주로 프로그래머의 실수나 오류로 인해 발생하며, 에러가 발생하면 프로그램은 중단되고 더 이상 진행되지 않습니다. 예를 들어, 문법 오류(Syntax Error)는 코드에 문법적인 오류가 있을 때 발생하는
7.하노이의 탑과 재귀 알고리즘
하노이의 탑은 세 개의 기둥과 여러 개의 크기가 다른 원반으로 구성된 퍼즐 게임입니다. 게임의 목표는 첫 번째 기둥에 있는 모든 원반을 세 번째 기둥으로 옮기는 것입니다. 단, 다음의 규칙을 따라야 합니다.한 번에 하나의 원반만 옮길 수 있습니다.큰 원반은 작은 원반
8.퀵정렬 알고리즘 (Quick Sort) - 파이썬 예제
퀵정렬은 효율적인 정렬 알고리즘 중 하나로, 다음과 같은 기본 아이디어에 기반하여 동작합니다:피벗 선택: 배열에서 하나의 요소를 선택합니다. 이 요소를 피벗이라고 합니다.분할: 배열을 두 개의 부분 배열로 분할합니다. 첫 번째 부분 배열에는 피벗보다 작은 모든 요소가
9.vscode에서 가상환경 활성화가 안 되는 경우
Anaconda에서 가상환경을 생성하고 vscode를 실행했는데 가상환경이 활성화되지 않는 경우가 있습니다. 원인은 여러가지일 수 있는데, 그 중 한 가지는 Anaconda의 경로가 시스템 환경 변수 PATH에 올바르게 추가되지 않았을 때입니다. conda의 실행 파일
10.vscode에서 가상환경 활성화가 안 되는 경우
Anaconda에서 가상환경을 생성하고 vscode를 실행했는데 가상환경이 활성화되지 않는 경우가 있습니다. 원인은 여러가지일 수 있는데, 그 중 한 가지는 Anaconda의 경로가 시스템 환경 변수 PATH에 올바르게 추가되지 않았을 때입니다. conda의 실행 파일
11.[Pandas] pivot_table과 멀티인덱스
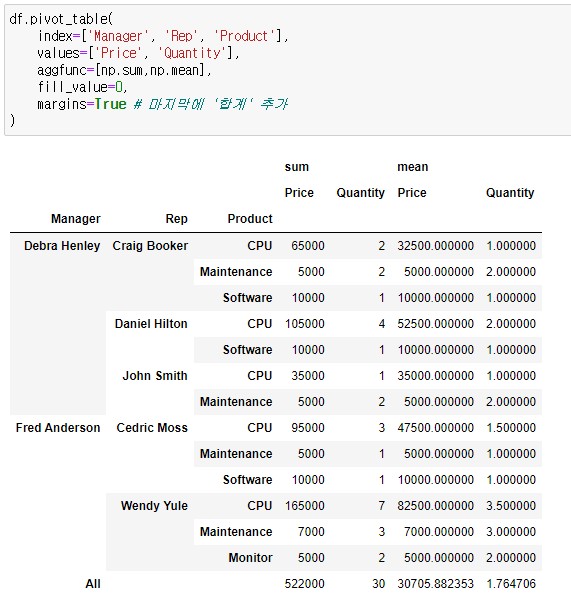
pivot_table은 판다스(Pandas) 라이브러리의 중요한 기능 중 하나로, 데이터를 재구성하고 요약하는 데 매우 유용합니다. 주어진 데이터를 정리하여 데이터를 쉽게 확인할 수 있도록 도와줍니다. 본문에서 사용한 데이터와 예제들은 '제로베이스 데이터스쿨'의 강의를
12.파이썬에서의 메모리 관리: 파괴적 vs. 비파괴적 연산 이해하기
1. sort vs. sorted 파이썬에서는 리스트의 정렬에 두 가지 주요 방법이 있습니다: sort() 메서드와 sorted() 함수. list.sort(): 리스트 객체의 메서드로, 원본 리스트 자체를 정렬합니다. 원본데이터가 보존되지 않고 변경
13.folium 지도 시각화 - 서울시 인구 데이터
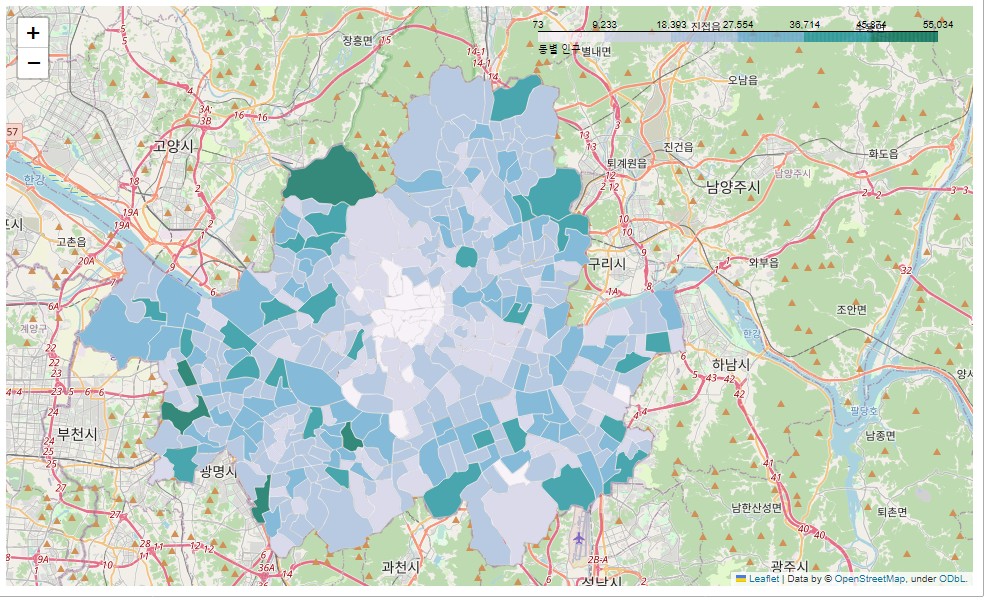
파이썬에서 지도시각화를 위해 주로 사용하는 folium을 이용해 서울시 지하철 데이터와 서울시 인구 데이터를 지도에 시각화하는 방법을 정리하겠습니다. 서울시 동별 인구 데이터 '서울시 열린광장'을 통해 얻은 서울시 동별 인구 데이터를 불러옵니다. 이후 작업을 위해
14.folium 지도 시각화 - 서울시 인구 데이터
파이썬에서 지도시각화를 위해 주로 사용하는 folium을 이용해 서울시 지하철 데이터와 서울시 인구 데이터를 지도에 시각화하는 방법을 정리하겠습니다. 서울시 동별 인구 데이터 '서울시 열린광장'을 통해 얻은 서울시 동별 인구 데이터를 불러옵니다. 이후 작업을 위해
15.folium 지도 시각화 - 서울시 지하철 데이터
지난 포스트에 이어 folium을 이용한 시각화에 대해 포스트 하겠습니다.지난 포스트에서 서울시 동별 인구를 folium.Choropleth를 이용해 시각화했습니다. 이제 이 지도 위에 서울시 지하철 역을 folium.CircleMarker를 이용해 나타내 보겠습니다.
16.이터러블 vs 이터레이터: 파이썬의 반복 가능한 객체들
이전에 이터레이터(Iterator)와 제너레이터(Generator)에 대해 정리한 적이 있습니다. 이터레이터는 '반복 가능한 객체'를 순회하는 도구로, 이러한 객체의 요소를 하나씩 접근할 수 있게 해줍니다. 제너레이터는 이터레이터를 더 쉽게 생성할 수 있는 방법을 제공
17.[스터디 노트] 웹 스크래핑을 위한 기초 - HTTP GET과 POST, 그리고 파이썬의 urlopen 사용법
웹 스크래핑을 위한 기초적인 지식으로 HTTP의 기본 개념들에 대해 공부하고, 파이썬의 urllib 라이브러리를 사용하는 방법에 대해 정리해 보았습니다. 아래서 정리한 것들은 realpython.com(https://realpython.com/urllib-re
18.[스터디 노트] 웹 스크래핑을 위한 기초 - requests 라이브러리
이전 포스트에서 웹 스크래핑을 공부하면서 기초를 다지기 위한 내용들을 정리했습니다. HTTP 요청을 위한 두 가지 방식, get방식과 post방식에 대해 알아보고, urllib.urlopen()을 사용해 웹페이지에 접근해 원하는 정보를 얻는 방법도 살펴보았습니다. 오늘
19.BeautifulSoup을 사용해 Yes24에서 책 정보 스크랩하기
이전 포스트들에서 requests 라이브러리와 urllib 라이브러리를 이용해 웹에 접근하는 방법에 대해 정리했습니다. 오늘은 BeautifulSoup을 이용해 'yes24.com' 사이트에서 책 정보를 웹 스크래핑 하는 방법에 대해 정리하도록 하겠습니다.웹스크래핑을
20.Selenium을 이용한 웹 스크래핑
웹 스크래핑은 웹 페이지에서 데이터를 추출하는 자동화된 방법입니다. 일반적으로 웹 스크래핑은 정적인 HTML 콘텐츠를 대상으로 하며, 지난 포스트에서 살펴보았다시피 BeautifulSoup은 매우 효과적으로 웹 스크래핑 작업을 수행했습니다. BeautifulSoup는
21.딕셔너리를 이용한 카테고리 매핑

데이터 분석에서 카테고리 매핑은 데이터를 미리 정해진 범주에 맞게 분류하는 과정입니다. 예를 들어, 음식을 아시안, 패스트푸드, 디저트 같은 유형별로 구분하는 것이 카테고리 매핑의 예시입니다. 이 과정은 데이터를 분석하기 쉽게 만들고, 더 깊은 이해를 가능하게 합니다.
22.네이버 API를 이용해 원하는 상품을 검색하고 결과를 엑셀로 저장하는 방법
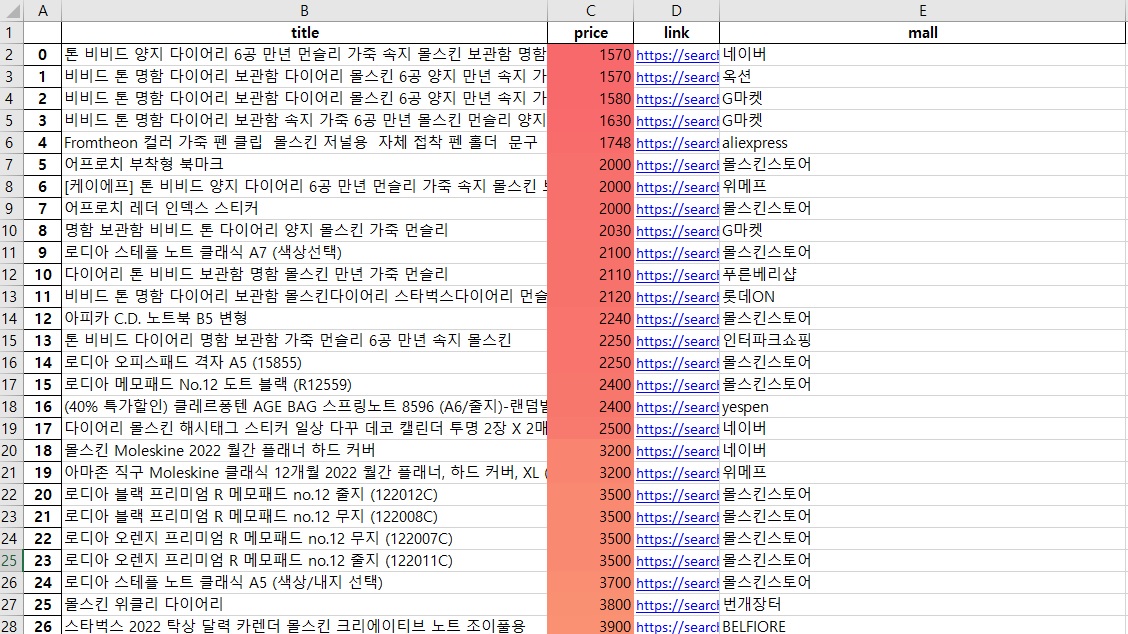
웹 스크래핑을 통한 데이터 수집에 대해 공부하였고 그 연장선상에서 API를 이용해 데이터를 수집하고 저장하는 방법에 대해 공부하고 그 결과를 포스트로 정리하도록 하겠습니다. 1. 들어가며 온라인 쇼핑 데이터는 시장 동향 분석, 소비자 행동 연구, 경쟁사 분석 등에
23.스타벅스 매장 정보 웹 스크래핑하기
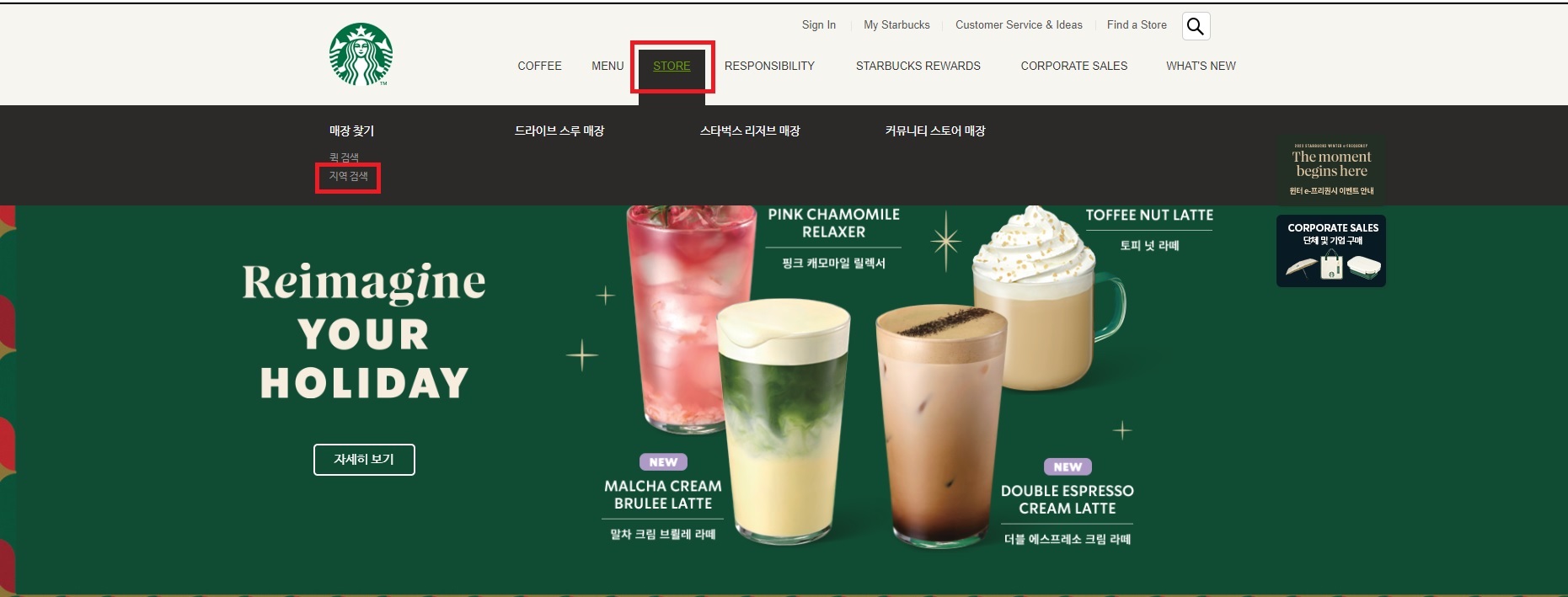
'제로베이스 데이터스쿨'의 첫번재 EDA 과제는 서울지역 스타벅스와 이디야 매장의 위치에 대한 분석이었습니다. 이번 포스트에서는 그 중에서 스타벅스의 매장정보를 웹 스크래핑하는 코드를 살펴보고 , 제가 공부한 내용을 정리해보겠습니다.데이터 분석을 시작하기 전에, 먼저
24.이디야 매장 정보 웹 스크래핑 하기

이전 포스트에서는 서울 지역 스타벅스 매장 정보를 웹 스크래핑하는 과정을 자세히 살펴보았습니다. 오늘은 그 연장선상에서 이디야 커피 매장 정보를 수집하는 fetch_ediya 함수에 대해 알아보겠습니다. 이 함수는 이디야 커피 매장의 위치 정보를 효율적으로 수집하기 위
25.연도별 한국 인구 분포의 동적 시각화 - matplotlib 그래프에 애니메이션 효과 넣기
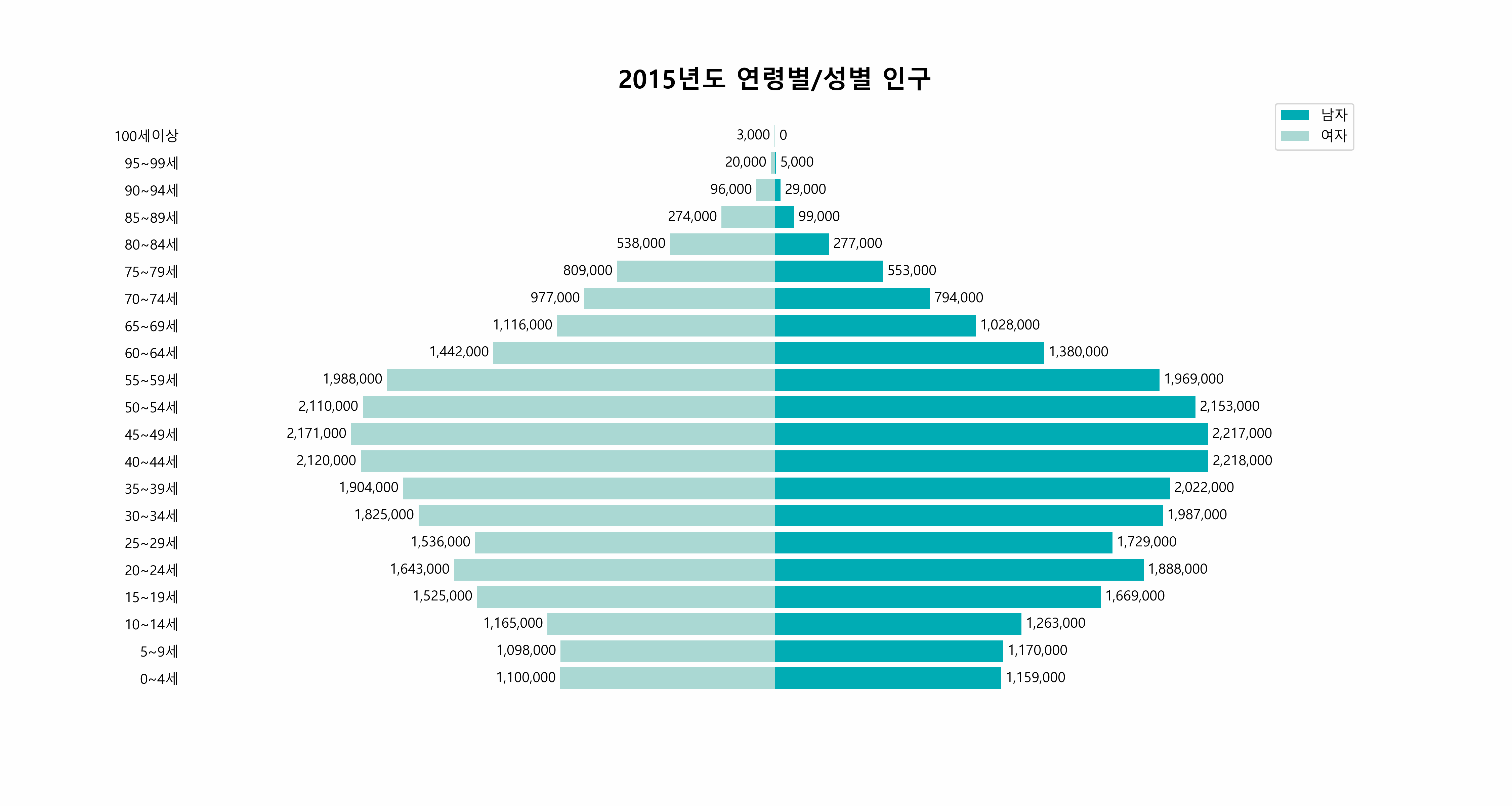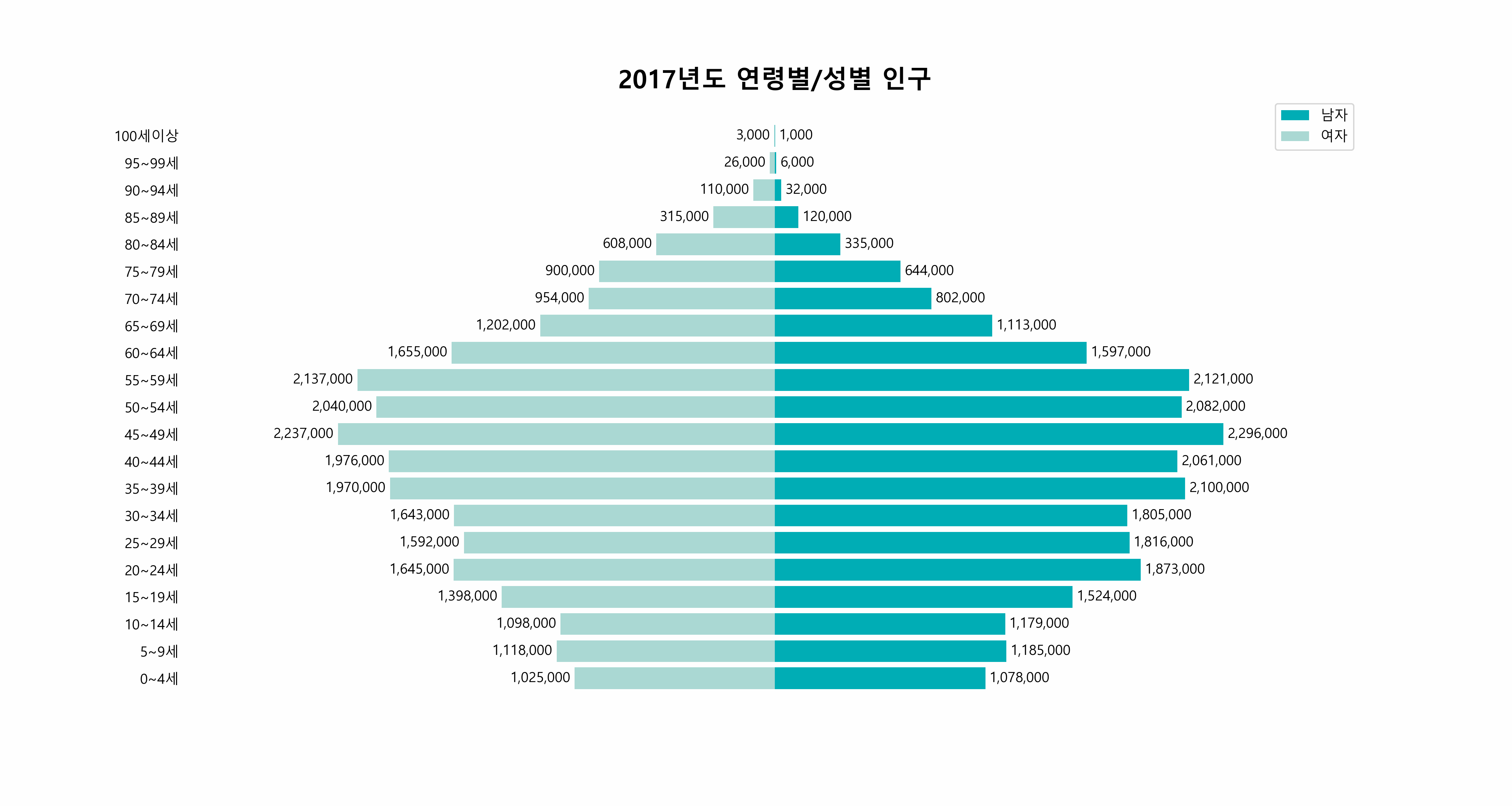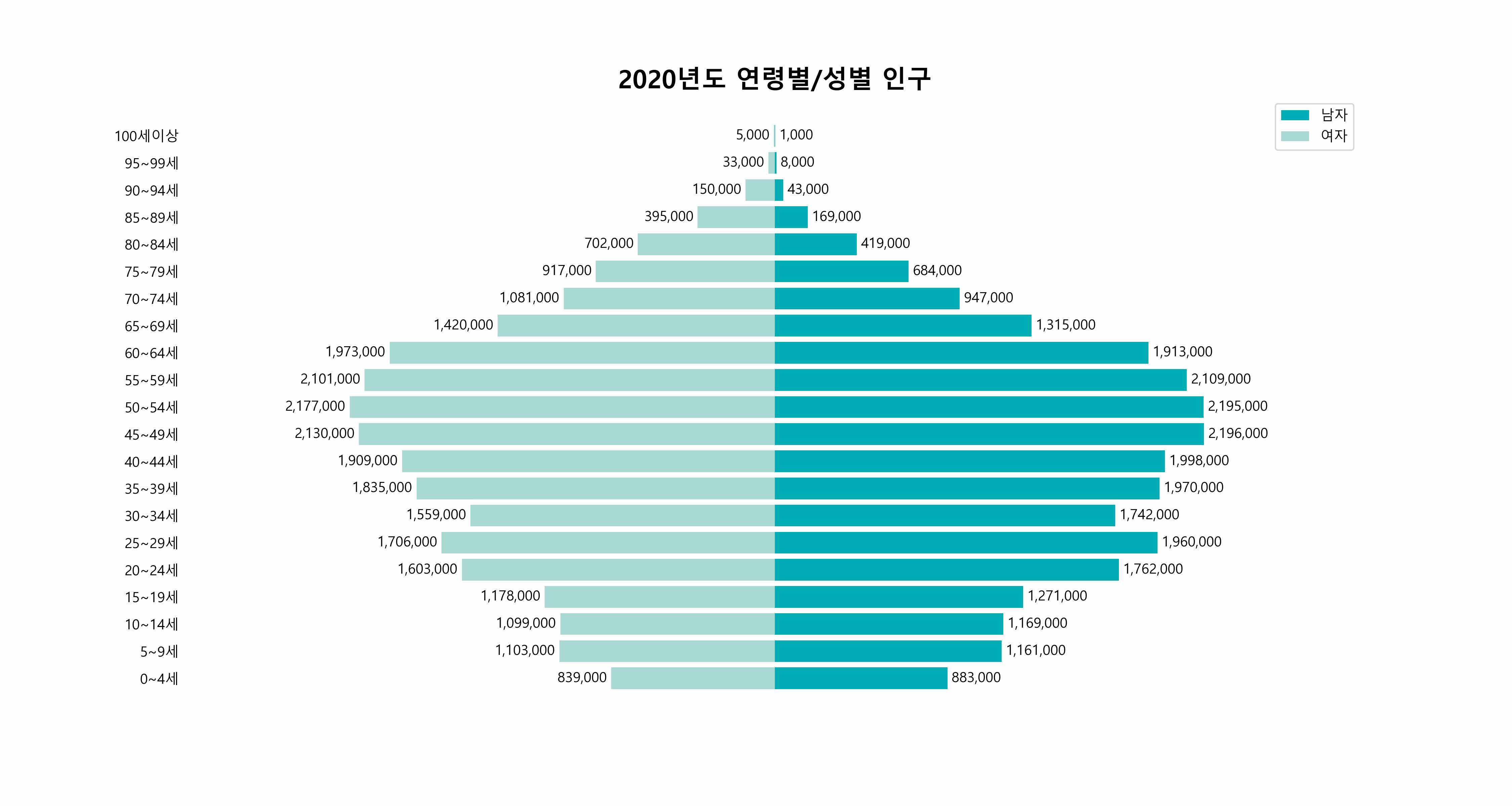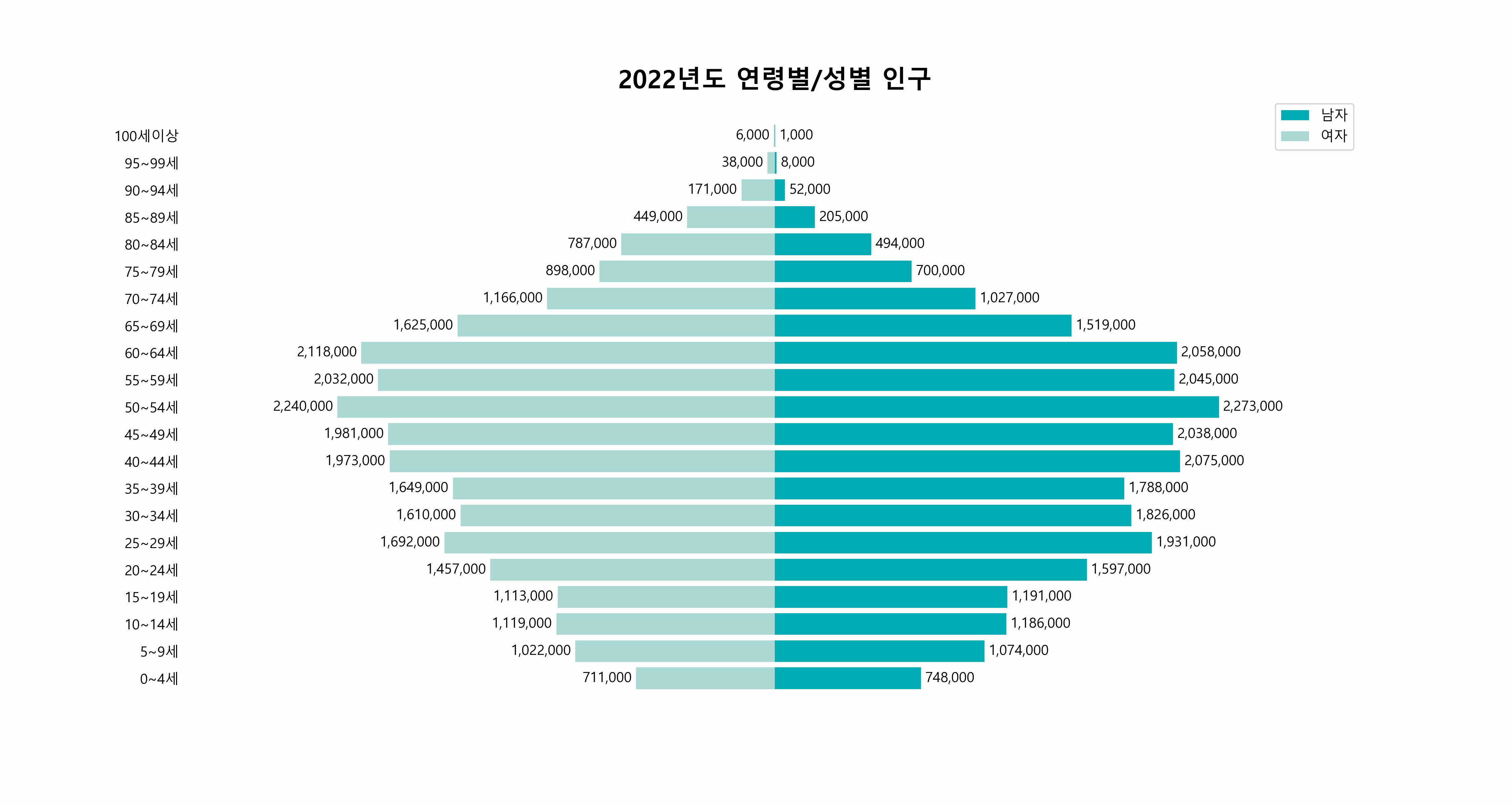
오늘의 목표는 간단합니다. 아래와 같은 그래프를 그리는 것입니다.한국의 2015년부터 2022년까지의 연령별, 성별 인구 분포를 담은 이 애니메이션은, 데이터가 단순히 숫자의 나열이 아닌, 시간의 흐름 속에서 변화하는 모습을 보여줍니다.이 시각화 과정은 유튭 영상을 보
26.AWS RDS에서 겪은 인코딩 문제 해결기

'제로베이스 데이터스쿨'에서 AWS RDS에 대해 배우고 있습니다. 처음 AWS RDS를 사용하면서 겪었던 한글 인코딩 문제와 그 해결 과정에 대해 정리해보겠습니다. 처음 인코딩 문제를 인식한 것은 특정 SQL 파일을 사용하여 데이터베이스 테이블에 데이터를 입력했을 때
27.판다스의 read_html을 활용한 웹 페이지 데이터 수집
웹 스크래핑에 대해 배우고 다양한 케이스로 연습하고 있습니다. 웹 스크래핑을 위해 보통 뷰티풀숲(BeautifulSoup)이나 셀레니움(Selenium)과 같은 도구를 사용해 HTML 데이터를 파싱하고 필요한 정보를 추출했습니다. 이 방법들은 강력하지만, 때로는 코드가
28.이디야는 스타벅스 옆에 있을까?
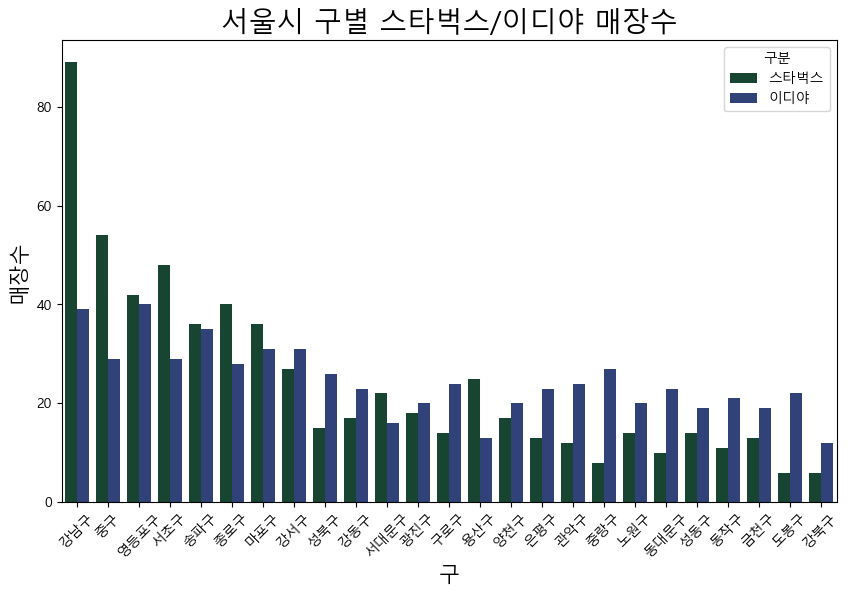
지난 포스트에서 스타벅스와 이디야 홈페이지에서 각각의 매장정보를 스크랩하는 방법을 정리했습니다. 이번엔 수집한 정보를 바탕으로 간단한 시각화와 함께 '이디야가 스타벅스 매장 주변에 위치하는가'란 주제로 데이터를 살펴보겠습니다.수집했던 정보를 먼저 불러오겠습니다.분석을
29.서울시 구별 경계 GeoJson 만들기
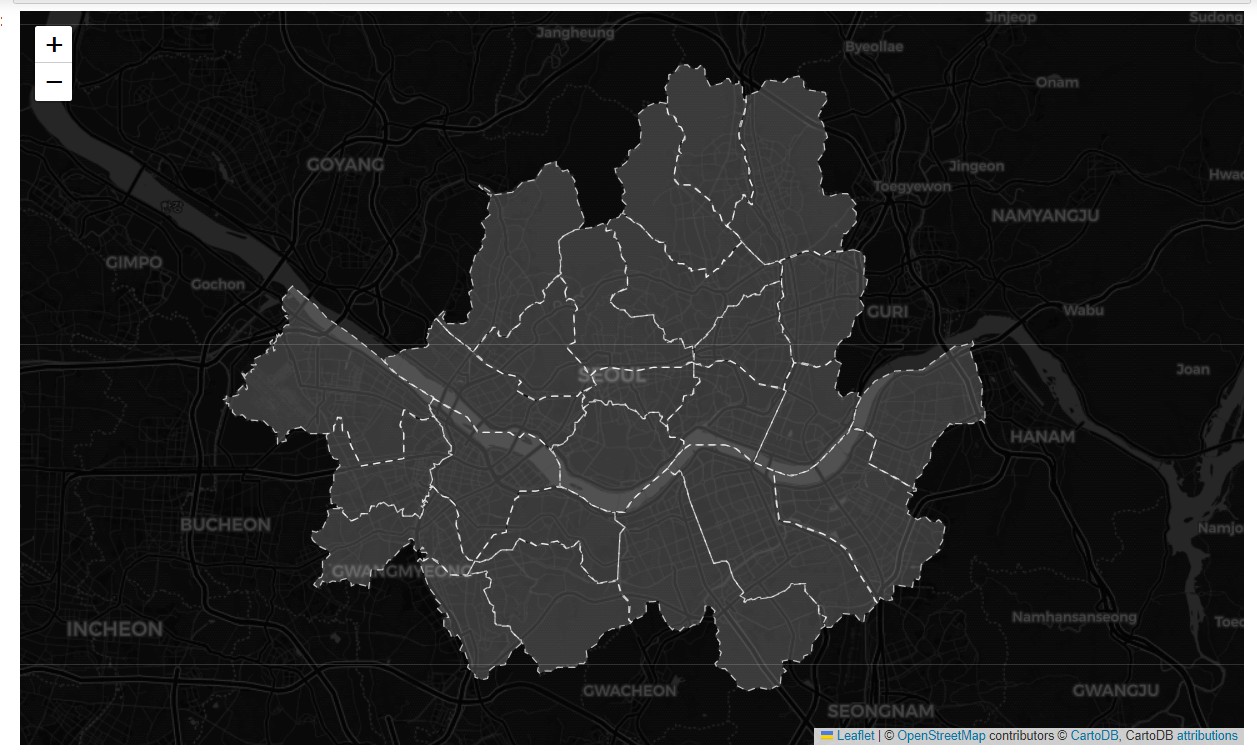
API 사용에 익숙해지기 위해 쓸데 없는 걸 만들며 연습하고 있습니다. 그 중에서 V-World API를 활용하여 서울시 각 구의 경계 데이터를 수집하고, 이를 통합하여 GeoJSON 파일을 생성하는 과정을 진행해보겠습니다. 또한, 생성된 GeoJSON 파일을 이용하여
30.Matplotlib의 GridSpec과 Seaborn의 JointPlot 활용하기
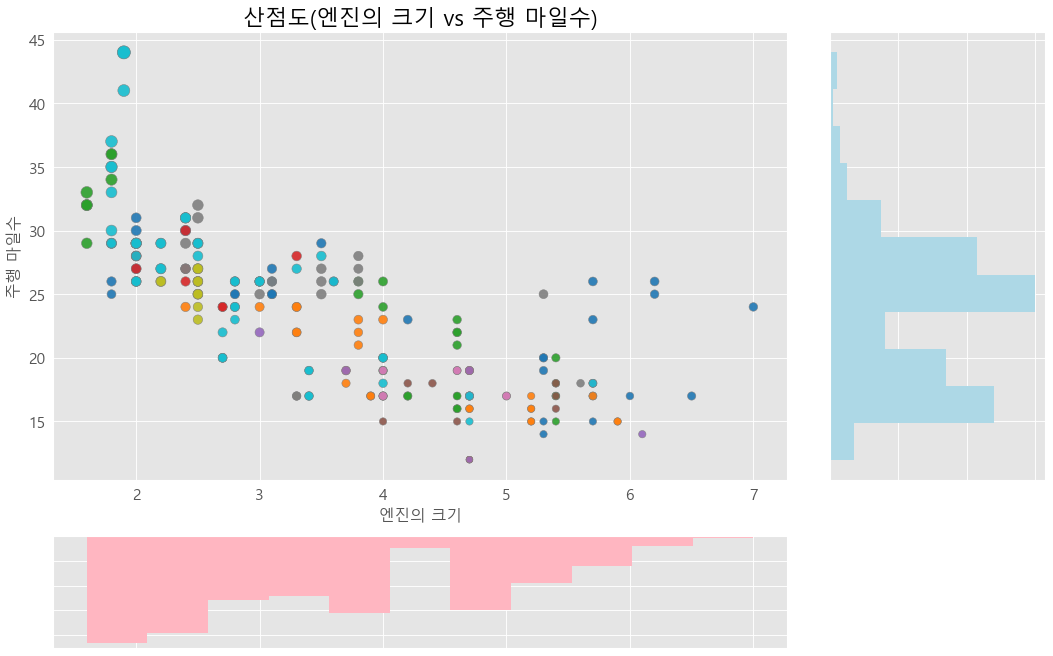
오늘의 포스트에서는 복잡한 데이터를 한눈에 파악할 수 있는 다양한 그래프를 효과적으로 그리는 방법에 대해 이야기해보려 합니다. 서로 다른 유형의 정보를 단일 시각화 내에서 통합적으로 표현할 수 있다면, 데이터의 이해도가 한층 높아질 것입니다.이번 포스트에서는 Matpl
31.Plotly를 이용해 히트맵과 막대차트 시각화하기
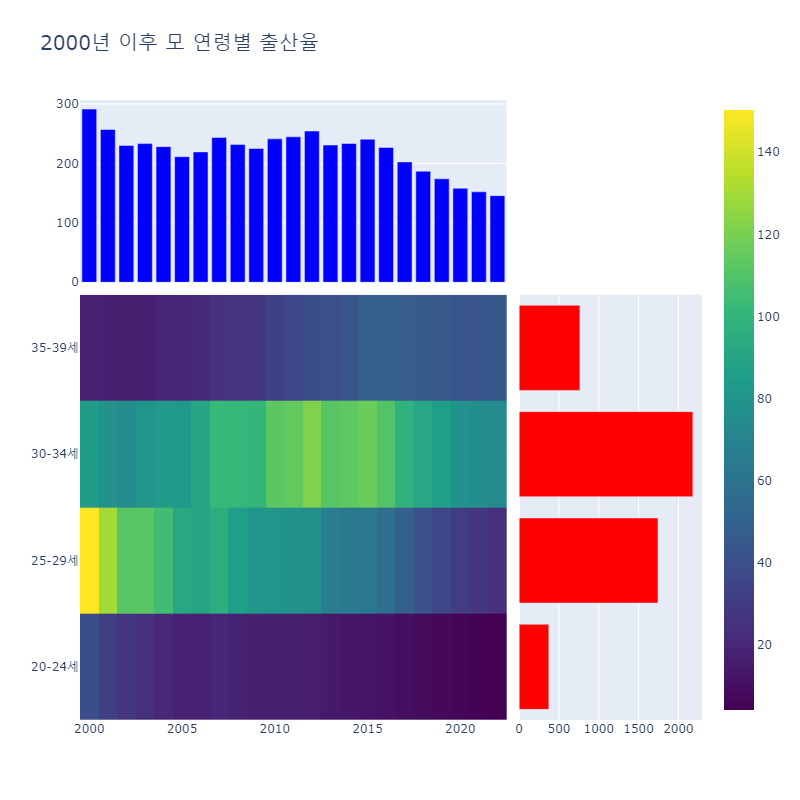
오늘은 Plotly를 이용한 시각화를 연습했습니다. 2000~2022년 한국의 연령별 출산율 데이터를 이용해 히트맵과 막대차트를 시각화하는 과정을 포스팅하도록 하겠습니다.데이터 분석과 시각화를 위해 필요한 모듈들을 불러옵니다. pandas는 데이터 처리를, plotly
32.Tableau를 SQL로 이해하고 설명해보기
'제로베이스 데이터스쿨'에서 Tableau에 대한 강의가 시작되었습니다. 최근 데이터 시각화에 대해 흥미가 커져가고 있었고, 특히 대시보드 작성 기술을 배우고자 하는 마음이 컸어서 강의과정이 재미있었씁니다.Tableau를 처음 접하면서, 많은 새로운 개념들과 마주하게
33.카이제곱분포, t분포, F분포에 대해
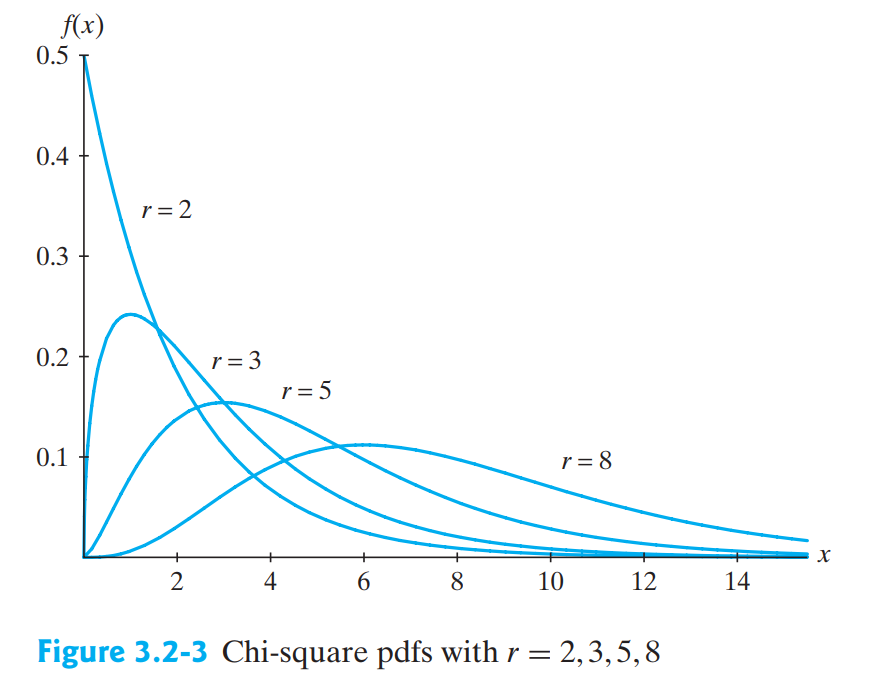
제로베이스 데이터스쿨에서 통계학 강의가 시작됐습니다. 오늘은 그 중에서 세 가지 카이 제곱 분포, t 분포, F 분포에 대해 정리하는 포스트를 작성해 보겠습니다. 이러한 분포들은 데이터의 분산, 평균, 그리고 두 변수 간의 관계를 이해하는 데 필수적이며, 통계적 추론과
34.이원분산분석(Two way ANOVA) 정리하기
분산분석(ANOVA)은 셋 이상의 집단을 비교할 때 사용하는 가설검정방법입니다. t-test는 두 집단간의 비교에서 사용하는데, 다수 집단의 비교에서 t-test를 여러번 사용하게 되면 1종 오류가 증가하게 되는 문제가 발생합니다. 그래서 셋 이상의 집단간에 비교를 위
35.협업을 위해 Git 사용하기
Git연습을 할 겸, 팀 스터디를 위한 리포지토리를 만들기로 했습니다. 개인적 목적으로 리포지토리를 만들고 사용한 적은 있지만, 협업을 위해 사용한 적은 없어서 Git 사용에 익숙해지기 위해 팀스터디를 위한 리포지토리를 만들고 팀 자료를 공유하기로 했습니다. 1. 깃
36.판다스의 .str.contains()와 .isin() 비교
판다스의 .str.contains()와 .isin() 메소드는 특정값의 포함여부를 확인할 때 사용합니다. 막연하게 느낌만 가지고 사용하고 있어서 사용할 때마다 조금씩 헷갈리는 부분이 있어서 정리해보려고 합니다. .str.contains() 메소드는 문자열 열에서 정규
37.SQL 쿼리를 주피터 노트북에서 사용하기 위한 매직커맨드
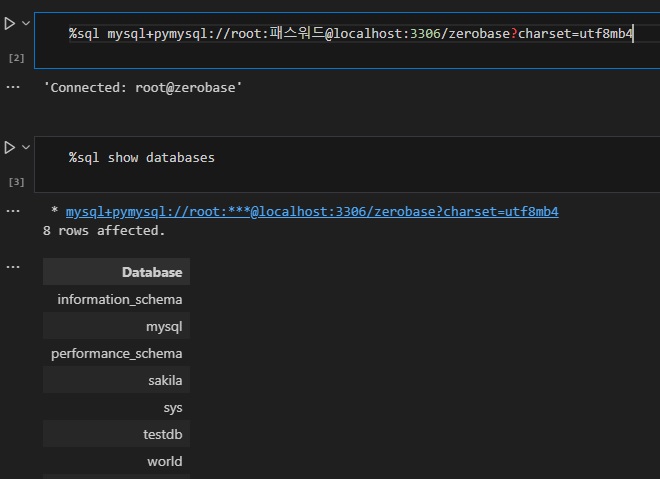
주피터 노트북에서 SQL 커리를 사용하면서 불편했던 점이 한 가지 있었습니다. SELECT문을 사용해 데이터를 조회하더라도 결과를 바로 볼 수 없고 결과를 출력하는 코드를 별도로 작성해줘야 한다는 것이었습니다. 이러한 불편함을 해소할 수 있는 방법이 있는데 매직 커맨드
38.BeautifulSoup에서 텍스트 추출하는 법 : text, string, get_text() 비교
웹 스크래핑을 통해 데이터 수집을 할 때, BeautifulSoup 라이브러리의 string, text, get_text() 메소드를 사용합니다. 이들은 때로는 갖은 결과를 보여주고 때로는 다른 결과를 보여주기도 합니다. 이번 포스트에서는 이 세 가지 메소드를 사용하는
39.스케일러 3종 비교: Min-Max, Standard, Robust Scaler
'제로베이스 데이터스쿨'에서 머신러닝 강의가 시작되었습니다. 오늘은 강의에서 다룬 3가지 스케일러에 대해 따로 정리하는 포스트를 작성하려고 합니다. 머신러닝에서 데이터를 다룰 때, 다양한 변수들이 서로 다른 스케일을 가지고 있는 경우가 많습니다. 예를 들어, 한 변수는
40.상수항이 R²와 AIC에 미치는 영향 - OLS를 통해 설명하기
오늘은 회귀모델을 평가하는 지표인 $R^2$와 AIC에 대해 정리해 보도록 하겠습니다. 회귀 분석에서 R-squared, 또는 R²는 분석의 핵심 지표 중 하나입니다. 이 지표는 모델이 얼마나 데이터의 변동성을 잘 설명하는지를 나타내는 값으로, '결정 계수'라고도 불립
41.타이타닉 데이터 세트로 라벨 인코딩과 원핫인코딩 설명하기
오늘은 머신 러닝을 위한 데이터 전처리 과정 중 2가지 인코딩 방식 - 라벨 인코딩(Label Encoding)과 원-핫 인코딩(One-Hot Encoding)에 대해 정리하는 포스트를 작성하도록 하겠습니다. 머신 러닝을 위한 데이터 중 많은 것들은 범주형 데이터로 분
42.로지스틱 회귀 모델 최적화: 타이타닉 데이터를 이용한 Convergence Warning 해결과 성능 향상
타이타닉 데이터를 이용해 데이터 분석과 머신 러닝을 연습하고 있습니다. 그 중에서 로지스틱 회귀(Logistic Regression) 모델은 분류 문제에 사용되는 알고리즘입니다. 이번 포스트에서는 제가 로지스틱 회귀 모델을 사용하는 과정에서 경험한 Convergence
43.DataConversionWarning의 원인과 해결 방법
앙상블 모델 중 RandomForest 수업 중에 DataConversionWarning이라는 경고 메시지를 접하게 되었습니다. 이 포스트를 통해 DataConversionWarning의 원인과 해결 방법에 대해 자세히 알아보고자 합니다.DataConversionWar
44.그리드 서치로 찾은 하이퍼 파라미터가 최고가 아닐 수 있다
머신 러닝 모델의 성능은 사용된 데이터, 모델의 구조, 그리고 모델을 구성하는 하이퍼파라미터에 의해 결정됩니다. 특히 하이퍼파라미터의 설정은 모델의 성능을 최적화하는 데 매우 중요한 역할을 합니다. 하이퍼파라미터 튜닝을 위해 많이 사용되는 방법 중 하나가 바로 그리드
45.2020 ~ 2022 콘텐츠 이용률 분석: Seaborn의 FacetGrid를 활용한 시각화
Seaborn 라이브러리의 FacetGrid는 복잡한 데이터를 다양한 각도에서 시각화할 수 있게 해줍니다. FacetGrid는 하나의 그래프에 여러 서브 플롯을 만들어 각각 다른 변수의 조합을 시각적으로 표현할 수 있게 해줍니다. 예를 들어, 다양한 범주형 변수에 따
46.자연어처리에서 유클리디안 거리와 코사인 유사도
들어가며 '제로베이스'에서 자연어처리(Natural Language Processing, NLP) 부분 강의를 듣고 있습니다. 자연어처리는 텍스트 데이터를 분석하여 유용한 정보를 추출하고, 이를 다양한 응용 분야에 활용하는 것을 목표로 합니다. 데이터를 다루는데 조
47.missingno 모듈의 'keyword grid_b is not recognized' 에러 해결

missingno 모듈은 데이터 시각화를 통해 결측치를 쉽게 파악할 수 있게 해줍니다. 이 모듈은 판다스와 연동되어 작동하기 때문에, 판다스의 버전과 호환성이 중요합니다. 때때로 판다스의 업데이트로 인해 내부 알고리즘이 변경되고, 이로 인해 missingno 모듈에서
48.머신러닝과 PCA - 데이터의 차원과 복잡성
머신러닝을 공부하면서 처음으로 골머리를 앓았던 부분이 주성분 분석(Principal Component Analysis, PCA)를 이해하는 것이었습니다. 머신러닝과 딥러닝의 많은 개념들이 선형대수학과 미적분학에 기초하고 있는데, 그에 대한 이해가 부족해서 처음 PCA에