
들어가며
SQLD를 공부할 땐, 실제 DB를 사용해보지 않고 눈으로만 문법을 익혔던지라 실제로 DB를 사용하며 SQL을 익히는 건 새로운 느낌입니다. 오늘은 SQL을 공부하며 제일 복잡했고 재밌었던 서브쿼리에 대해 정리하는 포스트를 작성하겠습니다.
포스트 작성을 위해 다음과 같은 테이블을 만들었습니다.
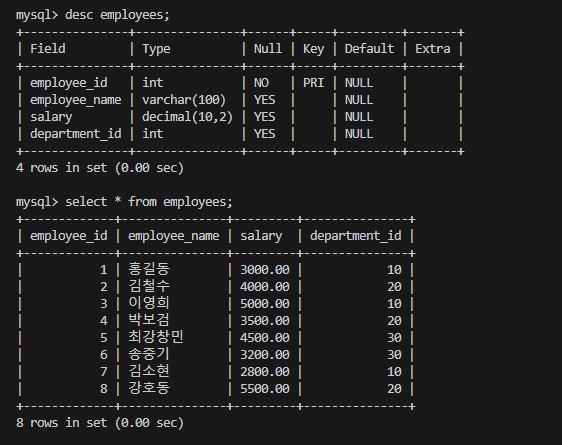
아래에선 이 테이블을 활용해 서브쿼리를 사용하도록 하겠습니다.
서브쿼리 사용법
서브쿼리란 다른 SQL 쿼리 내에 포함되는 쿼리입니다. 이는 하나의 SQL 문 내에서 여러 단계의 데이터 처리를 수행할 수 있게 해줍니다. 가장 간단한 형태의 서브쿼리는 단일 행 또는 단일 열의 데이터를 반환하는 데 사용됩니다. 예를 들어, 특정 조건을 만족하는 데이터를 찾는 경우에 서브쿼리를 사용할 수 있습니다.
다중 행 서브쿼리
다중 행 서브쿼리는 한 번에 여러 행을 반환할 수 있는 서브쿼리입니다. 이러한 서브쿼리는 IN, ANY, ALL과 같은 연산자와 함께 사용되어, 주어진 값들 중 하나 이상을 만족하는 레코드를 찾는 데 사용됩니다.
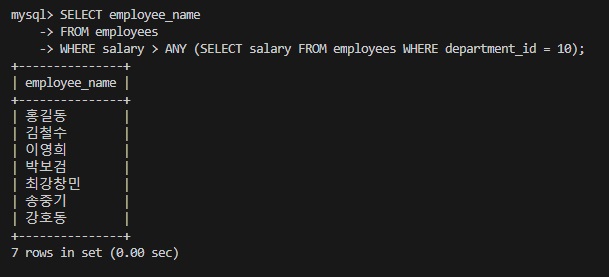
예시 1: 특정 부서에 속한 직원들의 급여보다 많은 급여를 받는 직원 찾기
SELECT employee_name
FROM employees
WHERE salary > ANY (SELECT salary FROM employees WHERE department_id = 10);이 쿼리는 부서 ID가 10인 부서의 직원들 중 어느 하나보다도 높은 급여를 받는 모든 직원의 이름을 반환합니다. ANY 키워드는 서브쿼리에서 반환된 값들 중 하나 이상과 비교하여 조건을 만족하는지 확인합니다.
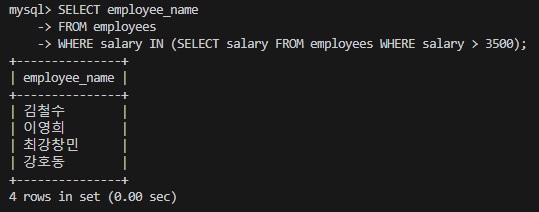
예시 2: 특정 급여 이상을 받는 직원들의 이름 찾기
SELECT employee_name
FROM employees
WHERE salary IN (SELECT salary FROM employees WHERE salary > 3500);이 쿼리는 급여가 3500 이상인 직원들의 급여와 일치하는 모든 직원의 이름을 반환합니다. IN 연산자는 서브쿼리에서 반환된 여러 값 중 하나와 일치하는 레코드를 찾는 데 사용됩니다.
다중 행 서브쿼리는 특정 조건을 만족하는 여러 행을 찾거나, 여러 테이블 간의 관계를 탐색하는 데 유용합니다.
알겠습니다. 서브쿼리 중에서 스칼라 서브쿼리(Scalar Subquery)와 인라인 뷰(Inline View)에 초점을 맞춰 내용을 작성하겠습니다.
스칼라 서브쿼리
스칼라 서브쿼리는 단일 값을 반환하는 서브쿼리입니다. 이 서브쿼리는 일반적으로 SELECT 문의 필드 리스트, WHERE 절, HAVING 절 등에서 사용되며, 하나의 열 값을 반환합니다.
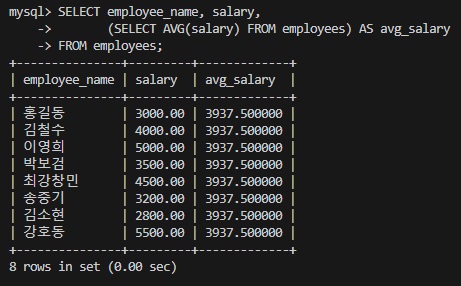
예시: 각 직원의 급여 대비 평균 급여 비교
SELECT employee_name, salary,
(SELECT AVG(salary) FROM employees) AS avg_salary
FROM employees;이 쿼리는 각 직원의 이름, 급여, 그리고 전체 직원의 평균 급여를 반환합니다. 스칼라 서브쿼리는 전체 직원의 평균 급여를 계산하여 각 행에 반환하는 데 사용됩니다.
마무리
간단한 테이블을 활용한 예시에서도 볼 수 있듯이, 서브쿼리를 사용하면 쿼리문 구성이 복잡해지고 해석하기 어려워질 수 있습니다. 실제 업무나 프로젝트에서 데이터를 다룰 때, 서브쿼리를 적절하고 효율적으로 사용하려면 데이터에 대한 깊은 이해와 테이블 간의 관계, SQL 문법에 대한 철저한 이해가 필요합니다. 앞으로의 학습 과정에서 이러한 측면들에 더욱 익숙해질 수 있도록 노력해야겠습니다. 이 학습 과정을 이 블로그에 기록하며, 제 경험이 다른 이들에게도 도움이 되기를 바랍니다.
