들어가며
오늘은 복잡한 데이터를 한눈에 파악할 수 있는 다양한 그래프를 효과적으로 그리는 방법에 대해 적어보겠습니다. 서로 다른 유형의 정보를 단일 시각화 내에서 통합적으로 표현할 수 있다면, 데이터의 이해도가 한층 높아질 것입니다. Matplotlib과 Seaborn 라이브러리를 사용하여, 하나의 그래픽 내에 여러 가지 그래프를 통합하는 방법을 정리해보겠습니다. 오늘의 포스트는 책 '데이터 시각화 with 파이썬'을 참고하였습니다.
1. Matplotlib의 GridSpec을 활용한 복합 그래프
Matplotlib의 GridSpec 기능은 복잡한 그래프 레이아웃을 구성하는 데 매우 유용합니다. 이를 사용하여 한 화면에 여러 그래프를 배열하고, 각각 다른 유형의 데이터를 시각화할 수 있습니다. 여기선 데이터분석 학습을 위해 많이 사용되는 mpg 데이터셋을 이용해 시각화 하도록 하겠습니다.
a. 그리드 설정과 축 정의
먼저, GridSpec을 사용하여 그래프의 기본 레이아웃을 설정합니다:
import matplotlib.pyplot as plt
import pandas as pd
# 데이터 로드
mpg = pd.read_csv('mpg.csv')
# 그래프의 기본 구조 설정
fig = plt.figure(figsize=(16, 10), dpi=80)
grid = plt.GridSpec(4, 4, hspace=0.5, wspace=0.2)
# 축 정의
ax_main = fig.add_subplot(grid[:-1, :-1])
ax_right = fig.add_subplot(grid[:-1, -1], xticklabels=[], yticklabels=[])
ax_bottom = fig.add_subplot(grid[-1, 0:-1], xticklabels=[], yticklabels=[])여기서 GridSpec(4, 4)는 4x4의 그리드를 생성합니다. ax_main, ax_right, ax_bottom은 각각 메인 그래프, 오른쪽 그래프, 아래쪽 그래프를 위한 축을 정의합니다.
b. 각 축에 그래프 그리기
각 축에 다른 유형의 그래프를 그립니다:
# 메인 산점도
ax_main.scatter('displ', 'hwy', s=mpg['cty']*4, c=mpg['manufacturer'].astype('category').cat.codes, alpha=.9, cmap='tab10', data=mpg)
# 하단 히스토그램
ax_bottom.hist(mpg['displ'], 11, histtype='stepfilled', orientation='vertical', color='lightpink')
# 오른쪽 히스토그램
ax_right.hist(mpg['hwy'], 11, histtype='stepfilled', orientation='horizontal', color='lightblue')여기서 scatter 메서드는 산점도를, hist 메서드는 히스토그램을 각각 그립니다. ax_main은 연비와 엔진 크기의 관계를 보여주는 산점도를, ax_bottom과 ax_right는 각각 엔진 크기와 고속도로 연비의 분포를 보여주는 히스토그램을 그립니다.
c. 데코레이션
마지막으로, 각 축에 대한 추가적인 설정을 합니다:
# 제목, 레이블, 폰트 설정
ax_main.set(title='산점도(엔진의 크기 vs 주행 마일수)', xlabel='엔진의 크기', ylabel='주행 마일수')
ax_main.title.set_fontsize(20)
ax_main.tick_params(left=False, bottom=False)
ax_bottom.tick_params(left=False, bottom=False)
ax_right.tick_params(left=False, bottom=False)
for item in ([ax_main.xaxis.label, ax_main.yaxis.label] + ax_main.get_xticklabels() + ax_main.get_yticklabels()):
item.set_fontsize(14)
plt.grid(True)
plt.show()이 부분에서는 각 축의 제목, 레이블 및 폰트 크기를 설정하여 그래프를 꾸며줍니다.
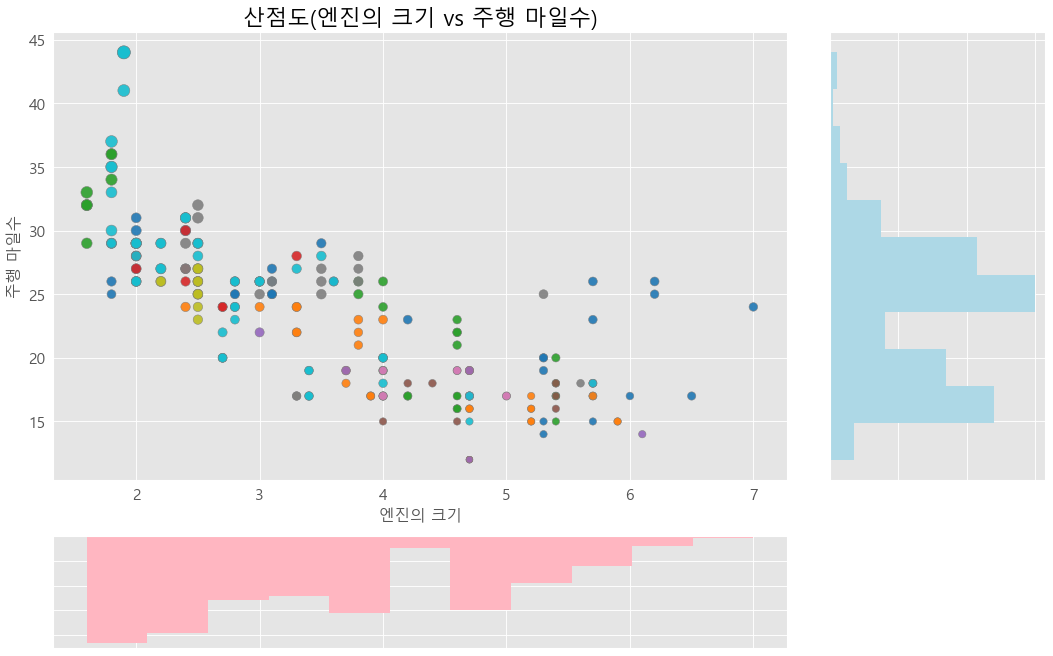
2. Seaborn의 jointplot을 활용한 데이터 시각화
Seaborn은 Matplotlib 기반의 고급 데이터 시각화 라이브러리로, jointplot은 산점도와 함께 히스토그램을 동시에 표현할 수 있는 편리한 방법을 제공합니다. Seaborn을 이용해 같은 형태의 그래프를 그릴 수 있습니다.
a. jointplot 생성
Seaborn의 jointplot을 사용하여 메인 산점도와 주변의 히스토그램을 함께 그립니다:
import seaborn as sns
# jointplot 생성
g = sns.jointplot(data=mpg, x='displ', y='hwy', kind='scatter', s=mpg['cty']*4)여기서 kind='scatter'는 산점도를 그리며, s=mpg['cty']*4는 각 점의 크기를 조정합니다.
b. 산점도와 히스토그램 커스터마이즈
jointplot 생성 후, 추가적인 커스터마이징을 할 수 있습니다:
# 메인 산점도에 레이블 추가
g.ax_joint.set_xlabel('엔진 크기')
g.ax_joint.set_ylabel('주행 마일수')
c. 데코레이션
마지막으로, 눈금 제거 및 기타 시각적 요소를 조정합니다:
g.ax_joint.tick_params(left=False, bottom=False)
g.ax_marg_x.tick_params(bottom=False)
g.ax_marg_y.tick_params(left=False)
plt.show()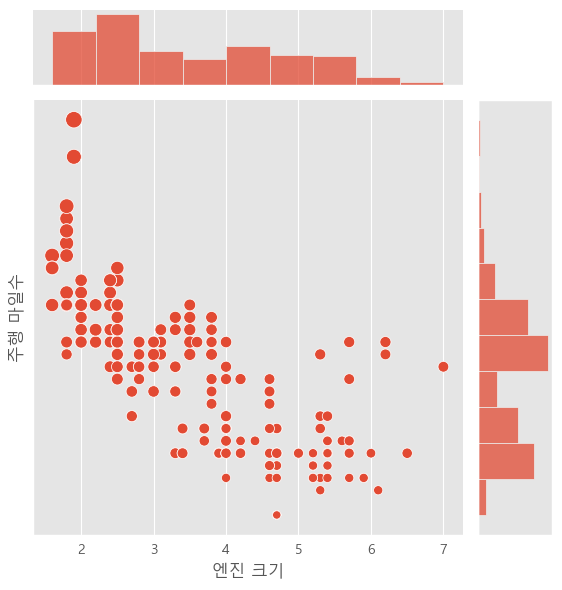
제조사에 따라 산점도의 색상 구분이 되지 않았습니다. hue= 파라미터로 가능하지만, hue를 사용하면 의도한 것처럼 산점도에만 파라미터가 적용되지 않습니다.

Matplotlib에서처럼 산점도에만 색상 구분을 적용하려면 결국 Seaborn에서도 JointGrid를 이용해야 하고 코드가 복잡해집니다. 아래와 같이 Matplotlib에서와 같은 형태로 구현이 가능하긴 하지만 Jointplot의 장점이라 할 수 있는 코드의 간결성은 사라집니다.
# JointGrid 생성
g = sns.JointGrid(data=mpg, x='displ', y='hwy')
# 메인 산점도에 hue 적용
sns.scatterplot(data=mpg, x='displ', y='hwy', hue='manufacturer', s=mpg['cty']*4, ax=g.ax_joint)
# 상단 히스토그램 추가
g.ax_marg_x.hist(mpg['displ'], color='lightpink', bins=15, align='mid')
# 오른쪽 히스토그램 추가
g.ax_marg_y.hist(mpg['hwy'], color='lightblue', bins=15, orientation='horizontal', align='mid')
# 추가 설정
g.ax_joint.set_xlabel('엔진 크기')
g.ax_joint.set_ylabel('주행 마일수')
# 오른쪽 히스토그램에 레이블 추가
ax_right_twin = g.ax_marg_y.twinx()
g.ax_marg_y.set_yticks([])
ax_right_twin.set_yticks([])
g.ax_joint.tick_params(left=False, bottom=False)
g.ax_marg_x.tick_params(bottom=False)
g.ax_marg_y.tick_params(left=False)
# 범례 제거
g.ax_joint.legend().remove()
plt.show()

결론: Matplotlib vs Seaborn
이번 포스트에서는 Matplotlib과 Seaborn을 사용하여 복잡한 데이터 시각화를 구현하는 두 가지 접근 방법을 탐색해보았습니다. 각각의 방법은 데이터 시각화의 목적과 데이터 분석가의 선호에 따라 그 유용성이 달라질 수 있습니다.
Matplotlib의 GridSpec
- 장점: 높은 수준의 사용자 정의가 가능하여, 복잡하고 세밀한 그래프 레이아웃을 구현할 수 있습니다.
- 단점: 코드가 상대적으로 복잡하고 길어질 수 있습니다.
Seaborn의 jointplot
- 장점: 간결하고 효율적인 코드로 빠르게 복합 그래프를 생성할 수 있습니다.
- 단점: Matplotlib만큼의 세밀한 사용자 정의는 제한적일 수 있습니다.
