1. 웹 스크래핑의 개요 및 Selenium의 필요성
웹 스크래핑은 웹 페이지에서 데이터를 추출하는 자동화된 방법입니다. 일반적으로 웹 스크래핑은 정적인 HTML 콘텐츠를 대상으로 하며, 지난 포스트에서 살펴보았다시피 BeautifulSoup은 매우 효과적으로 웹 스크래핑 작업을 수행했습니다. BeautifulSoup는 웹 페이지의 HTML을 파싱하고, 태그를 기반으로 필요한 정보를 추출하는 데 사용됩니다.
그러나 많은 웹사이트는 사용자의 행동에 반응하여 동적으로 콘텐츠를 로드하는 웹 페이지를 생성합니다. 웹페이지의 전체 내용이 웹 브라우저에 의해 실행되고 렌더링 된 후에야 비로소 접근이 가능해집니다. requests 라이브러리와 BeautifulSoup으로는 동적으로 생성되는 웹 페이지의 내용에 접근하기 어렵습니다. 이때 Selenium이 필요하게 됩니다.
Selenium은 실제 웹 브라우저를 파이썬 코드를 이용해 자동화하여 웹사이트와 상호작용할 수 있게 해줍니다. 이를 통해, 브라우저가 JavaScript를 실행시키고 동적으로 콘텐츠를 로드할 때까지 기다린 다음, 필요한 데이터를 추출할 수 있습니다.
특히, 사용자와의 상호작용을 통해 (예를 들어, 드롭다운 메뉴에서 옵션을 선택하거나, 스크롤 다운하여 추가 콘텐츠를 로드하는 경우 등) Selenium은 필수적인 도구가 됩니다.
여기선, Selenium을 사용해 opinet.co.kr에서 주유소 정보를 스크랩하는 코드를 통해 Selenium의 사용법에 대해 정리해보도록 하겠습니다. 포스트의 내용은 '제로베이스 데이터스쿨'의 강의를 참고하였습니다.
2. Selenium의 핵심 컴포넌트와 개념 설명
Selenium을 사용할 때 이해해야 할 몇 가지 주요 개념이 있습니다.
WebDriver
WebDriver는 브라우저를 제어하기 위한 핵심 도구입니다. 각 브라우저마다 특정 WebDriver가 존재하며 (예: Chrome은 ChromeDriver, Firefox는 GeckoDriver 등), 이를 통해 Selenium이 해당 브라우저를 제어할 수 있게 됩니다. 여기선 Chrome을 사용하겠습니다.
WebElement
WebElement는 웹 페이지의 HTML 요소를 나타냅니다. Selenium은 이러한 WebElement를 찾고, 데이터를 추출하거나, 요소에 대한 다양한 작업(클릭, 텍스트 입력 등)을 수행할 수 있습니다. 이러한 요소들은 find_element 메소드를 사용해 찾을 수 있습니다.
By Class
By 클래스는 WebElement를 찾는 다양한 방법들을 제공합니다. 예를 들어, ID, 클래스 이름, 태그 이름, CSS 선택자, XPath 등이 있으며, 이를 통해 원하는 요소를 효과적으로 탐색할 수 있습니다. By 클래스는 앞서 말한 find_element와 함께 사용됩니다.
ActionChains
ActionChains는 복잡한 사용자 제스처를 자동화하기 위한 Selenium의 유틸리티입니다. 예를 들어, 마우스를 움직이거나, 드래그 앤 드롭, 마우스 오버(호버) 같은 연속적인 작업을 구현할 수 있습니다.
WebDriverWait 및 Expected Conditions
동적 웹페이지에서는 특정 요소가 로드되거나, 어떤 상태에 도달할 때까지 기다려야 할 필요가 있습니다. WebDriverWait와 expected_conditions를 사용하면, 특정 조건이 만족될 때까지 명시적으로 대기할 수 있으며, 이를 통해 원하는 요소와 상호작용할 수 있습니다.
tqdm 라이브러리
tqdm은 작업의 진행 상태를 시각적으로 표시하는 데 사용되며, 반복 작업의 진행률을 프로그레스 바로 쉽게 나타낼 수 있습니다. 웹 스크래핑이나 Selenium에 필수적인 것은 아니지만, 작업의 진행 정도를 알기 위해 사용합니다.
3. 웹 스크래핑 작업 설명
앞서 언급했듯 여기선 Selenium을 사용하여 한국의 주유소 정보 포털인 'Opinet'에서 서울시 구별 주유소 정보를 스크래핑하고, 관련 데이터를 엑셀 파일로 다운로드하는 자동화 과정을 구현합니다. 다음은 코드의 작동 과정을 간략하게 설명한 것입니다.
- WebDriver 인스턴스 초기화: Chrome WebDriver를 사용해 브라우저를 구동합니다.
- 웹사이트 접근: 주유소 정보 포털인 'Opinet'의 메인 페이지로 이동합니다.
-
브라우저 창 최대화: 최적의 스크래핑을 위해 브라우저 창을 최대화합니다.
-
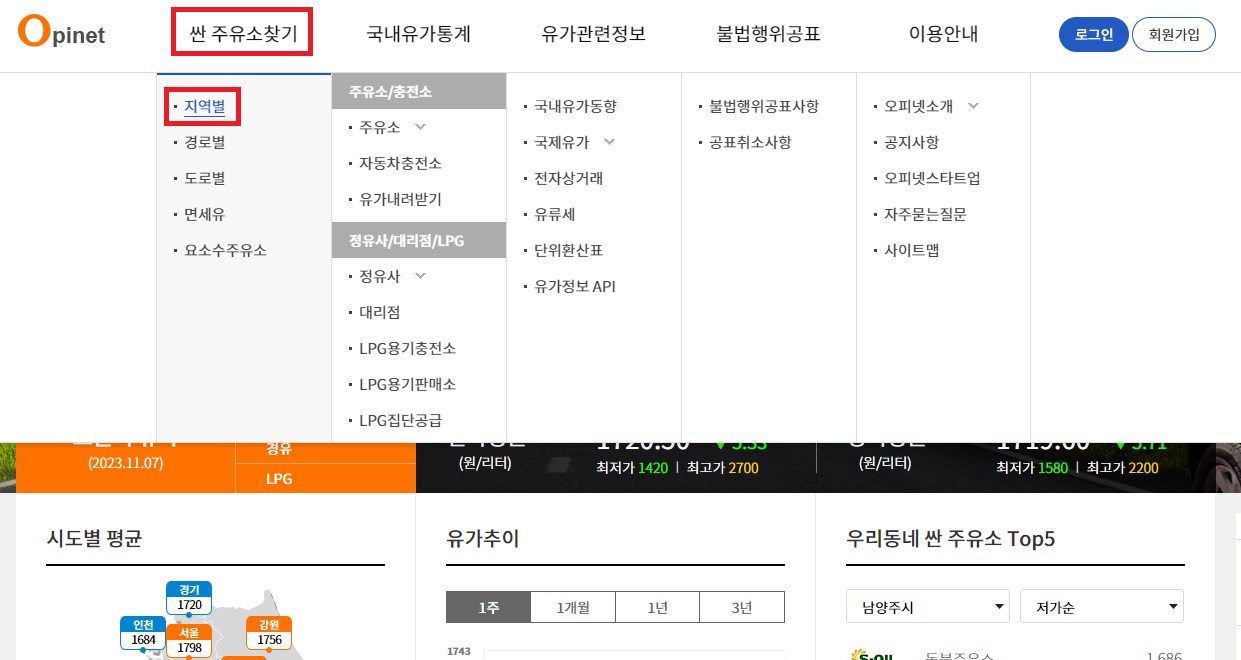
메뉴 탐색: 마우스 오버를 통해 상위 메뉴에 접근하고, 서브 메뉴를 클릭하여 주유소 정보 조회 페이지로 이동합니다.
-
지역 선택: 드롭다운 메뉴에서 서울시에 해당하는 옵션을 선택합니다.

-
구 선택 및 정보 다운로드: 서울시 내 각 구를 순회하면서, 해당 구의 주유소 정보가 담긴 엑셀 파일을 다운로드합니다.

-
진행 상태 표시:
tqdm라이브러리를 사용하여 각 구별 데이터 다운로드 진행 상태를 표시합니다. -
작업 종료: 모든 작업이 완료되면 브라우저를 닫습니다.
여기선 동적 웹페이지의 상호작용 요소에 대응하기 위해 Selenium의 ActionChains, WebDriverWait같은 기능을 사용하였습니다. 각 구의 정보를 추출하기 전에 해당 구가 선택되기를 기다리는 것처럼, 동적인 콘텐츠의 로드를 기다리는 명시적 대기 로직이 포함되어 있습니다.
4. 코드 분석
이제 실제로 Selenium을 사용하여 주유소 정보를 스크래핑하는 파이썬 코드를 살펴보겠습니다. 주석을 통해 단계별로 각 코드가 수행하는 작업을 설명하고 있습니다.
# 필요한 라이브러리를 가져옵니다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
from tqdm.notebook import tqdm
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 스크래핑할 웹사이트의 URL을 설정합니다.
url = 'https://www.opinet.co.kr/user/main/mainView.do'
# Chrome WebDriver 인스턴스를 생성하고, Opinet 웹사이트를 엽니다.
driver = webdriver.Chrome('../driver/chromedriver.exe')
driver.get(url)
# 브라우저 창을 최대화합니다.
driver.maximize_window()
# 상위 메뉴 '싼 주유소 찾기' 메뉴에 마우스를 올려놓고, '지역별'을 클릭합니다.
first_tag = driver.find_element(By.CSS_SELECTOR, '#header > div > ul > li:nth-child(1)')
second_tag = driver.find_element(By.CSS_SELECTOR, '#header > div > ul > li:nth-child(1) > ul > li:nth-child(1)')
action = ActionChains(driver)
action.move_to_element(first_tag).move_to_element(second_tag).click().perform()
# '시/도' 드롭다운 메뉴에서 서울특별시를 선택합니다.
sido_list_raw = driver.find_element(By.ID, 'SIDO_NM0')
sido_list = sido_list_raw.find_elements(By.TAG_NAME, 'option')
sido_names = [option.get_attribute('value') for option in sido_list if option.get_attribute('value')]
sido_list_raw.send_keys(sido_names[0])
# '시/군/구' 드롭다운 메뉴를 찾아서 구 이름들을 추출합니다.
gu_list_raw = driver.find_element(By.ID, 'SIGUNGU_NM0')
gu_list = gu_list_raw.find_elements(By.TAG_NAME, 'option')
gu_names = [option.get_attribute('value') for option in gu_list if option.get_attribute('value')]
# 추출한 구 이름들을 사용하여 각 구별로 주유소 정보 엑셀 파일을 다운로드합니다.
for gu in tqdm(gu_names):
gu_list_raw = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'SIGUNGU_NM0'))
)
gu_list_raw.send_keys(gu)
time.sleep(1)
excel_download = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#templ_list0 > div:nth-child(7) > div'))
)
excel_download.click()
# 모든 작업을 마친 후, WebDriver 세션을 종료하고 브라우저를 닫습니다.
driver.quit()이 코드는 Opinet 웹사이트에 접속하여 서울시에 있는 주유소 정보를 구별로 엑셀 파일로 다운로드하는 자동화 스크립트입니다. 각 단계는 웹 페이지의 요소에 접근하고, 필요한 작업(예: 클릭, 값 선택 등)을 수행하는 코드로 구성되어 있습니다. 막대그래플 통해 진행 상황을 시각적으로 표시하기 위해 tqdm 라이브러리를 사용했습니다.
for문 안에서 사용된 코드들은 더 자세히 살펴보도록 하겠습니다.
for gu in tqdm(gu_names):
gu_list_raw = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.ID, 'SIGUNGU_NM0'))
)
gu_list_raw.send_keys(gu)
time.sleep(1)
excel_download = WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#templ_list0 > div:nth-child(7) > div'))
)
excel_download.click()-
WebDriverWait(driver, 10).until(...): 이 코드는 최대 10초간 대기하며,until메서드에 제공된 조건이 참이 될 때까지 (즉, 조건이 만족될 때까지) 기다립니다. 이는 네트워크 지연, 로드 지연 등으로 인해 요소가 즉시 사용 가능하지 않을 때 유용합니다. 처음에 WebDriverWait를 사용하지 않았을 땐 코드에서 명시한 요소를 찾지 못해 에러가 발생하거나, 미처 페이지를 로드하기 전에 다음 코드를 실행해 엑셀 파일을 다운로드 하지 못하는 경우가 있었습니다. -
EC.element_to_be_clickable(...):expected_conditions모듈의element_to_be_clickable메서드는 인자로 전달된 요소가 클릭 가능한 상태, 즉 사용자가 실제로 클릭할 수 있고 활성화된 상태일 때까지 기다리라는 조건입니다. 요소가 화면에 표시되지 않거나 비활성화 상태라면 클릭 가능하다고 할 수 없습니다. 이 메서드는 요소가 클릭 가능한 상태가 되는 순간을 캡처하고, 이후에 클릭을 수행할 수 있도록 합니다. -
send_keys(gu):send_keys메서드는 파라미터로 받은 값을 입력 필드에 전송합니다. 이 경우에는 사용자가 드롭다운 메뉴에서 선택할 수 있는 서울시 내의 각 구를 나타내는 값입니다. -
time.sleep(1): 간단한 일시 정지로, 1초 동안 스크립트를 대기시킵니다. 이는 요소가 로드되는 것을 기다리거나, 네트워크 지연 등을 고려하여 사용되기도 합니다. 그러나time.sleep은 보통WebDriverWait와 같은 명시적 대기를 권장하는 Selenium 접근 방식보다는 덜 선호됩니다. 여기선, 일부 구에 대한 엑셀 파일을 다운로드 하지 못하는 경우가 발생해time.sleep(1)코드를 추가해 페이지가 로드 되는 시간을 충분히 확보하였습니다. -
excel_download.click(): 이전에 클릭 가능 상태가 되기를 기다렸던 요소를 실제로 클릭하는 동작을 수행합니다. 이 클릭은 해당 구의 주유소 정보가 담긴 엑셀 파일을 다운로드하는 버튼에 해당합니다.
핵심은 페이지의 각 요소가 사용자 상호작용을 위해 준비된 상태인지를 보장하고, 그에 따라 다음 동작을 수행하도록 하는 것입니다. 웹 페이지가 서버 응답을 기다리거나 추가 데이터를 로드하는 동안, 코드가 더 이상 실행되지 않고 해당 요소들이 실제로 사용자와 상호작용할 수 있을 때까지 기다립니다. 이러한 조건이 만족되지 않으면 에러가 발생하거나, 의도했던 작업의 일부를 건너 뛰는 등 결과의 신뢰성에 문제가 발생할 수 있습니다.
지난 4개의 포스트를 통해 웹스크래핑 공부를 위해 urllib, requests, BeautifulSoup, Selenium 라이브러리를 하나씩 살펴보며 정리해 보았습니다.
