1. 정의
유사한 속성을 갖는 데이터들을 묶어 전체 데이터를 몇 개의 군집으로 나누는 것
Classification과 차이점
- Classification
- 소속 집단의 정보를 알고 있는 상태
- Label이 있는 데이터를 나누는 방법
- Clustering
- 비지도 학습
- 소속 집단의 정보를 모르는 상태
- Label이 없는 데이터를 나누는 방법
2. 계층적 군집화 - 군집 분석의 종류
개체들을 가까운 집단부터 묶어 나가는 방식
- 유사한개체들이 결합되는 dendrogram 생성
거리를 기반으로 군집
- 유클리드 거리
- 맨하탄 거리
- 표쥰화 거리
- 민콥스키 거리
계층적 군집화의 종류는 클러스터 간 거리 측정 방법에 따라 달라진다.
최단 연결법

최장 연결법

평균 연결법

중심 연결법

3. 비계층적 군집화 - 군집 분석의 종류
전체 데이터를 확인하고 특정한 기준으로 데이터를 동시에 구분한다.
K-Means
- 주어진 데이터를 K개의 군집으로 묶는 방법
-
특징
- 각 군집은 하나의 중심을 가짐
- 각 데이터는 가장 가까운 중심에 할당
- 사전에 군집의 수, K가 정해져야 한다.
-
성능에 끼치는 영향
- 초기 중심점 설정
- K의 개수
-
K의 개수를 정하는 수식

-
장점
- 적용하기 쉽다.
- 단점
- 서로 다른 크기의 군집을 잘 못찾는다.
- 서로 다른 밀도의 군집을 잘 못찾는다.
- 지역적 패턴이 존재하는 군집을 잘 못찾는다.
DBSCAN
점 P에서부터 거리가 e (epsilon)내에 m(minPts)개 이상 있으면 하나의 군집으로 인식
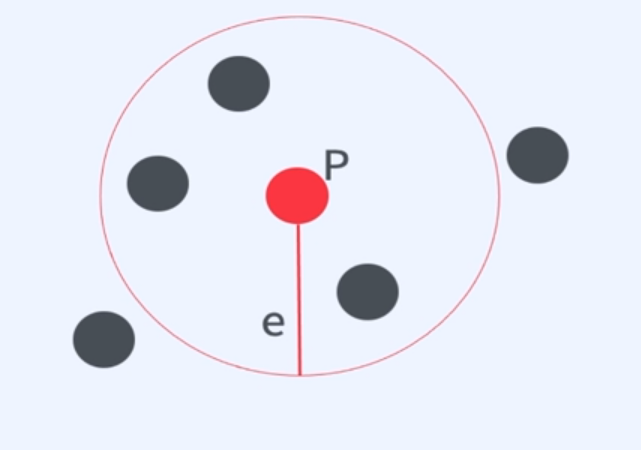
- 학습 방법
- Core Point
- 거리 eps 내에 데이터가 (자신포함) minPts개 이상 있는 포인트
- Border Points
- Core Points를 이웃으로 갖고 있지만 eps 이내에 데이터가 minPts개 보다 적은 포인트
- Noise Points
- Core Points를 이웃으로 갖고 있지 않고 eps 이내에 데이터가 minPts개 보다 적은 포인트
- 설정해야 할 모수
- minPts
- Cross Validation과 같은 방법으로 구해야 한다.
- eps
- K-dist Graph를 사용한다.
4. 군집화 평가
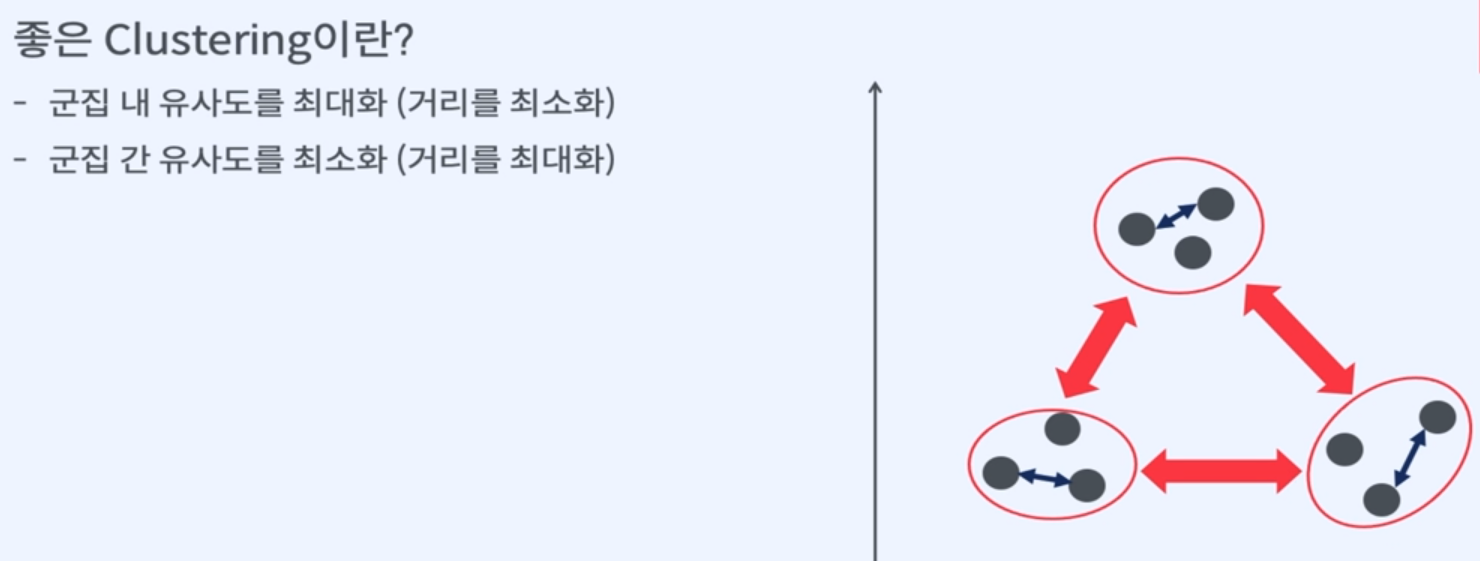
내부 평가
군집된 결과 그 자체를 놓고 평가
-
Dunn Index

-
실루엣

외부 평가
군집화에 사용되지 않는 데이터로 평가
