1. 학습 방법과 모델
모델 기반 학습 ( Model-Based Learning )
데이터로부터 모델을 생성하여 분류/ 예측 진행
- Linear Regression, Logistic Regression
사례 기반 학습 ( Instance-Based Learning )
모델 없이 인접 데이터를 분류 / 예측에 사용
모델을 미리 만들지 않고 새로운 데이터가 들어오면 계산 시작 ( Lazy Learning )
- KNN, Naive Bayes
2. 정의
k 개의 가까운 이웃을 찾는다
학습 데이터 중 k개의 가장 가까운 사례를 사용하여 분류 및 수치 예측
분류 방법
- 새로운 데이터 입력 받음
- 모든 데이터들과의 거리 계산
- 가장 가까운 K 개의 데이터를 선택
- K개의 데이터의 클래스 확인
- 다수의 클래스를 새로운 데이터의 클래스로 예측
최적의 K를 찾아야 한다.
- K가 적을 수록 overfitting, 많을 수록 underfitting
3. 최적의 k 값 설정
Cross Validation
- 교차 검증을 통해 성능이 좋은 K를 선택
4. 거리의 종류
Euclidean Distance
- 두 점 사이의 최단 거리
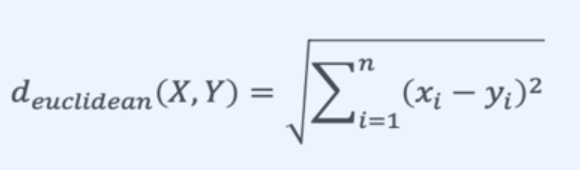
Manhattan Distance

4. 장단점
장점
- 학습과정이 없다
- 결과를 이해하기 쉽다
단점
- 데이터가 많을 수록 시간이 오래 걸린다.
- 지나치게 데이터에 의존적이다.
